企业级多智能体系统面临的最大瓶颈,往往不是单个 Agent 能力不足,而是负责分发任务的“路由器”过于简单。传统的 Router 通常只能进行简单的单选分类,面对复杂的业务场景和模糊指令时,很容易出现“瞎指挥”的情况。在企业运维这个关键的决策十字路口,我们迫切需要一个更智能、更灵活的“交通指挥官”。
过去一年,Multi-Agent 架构正迅速成为企业 AI 的新基建。开发者们忙着打造更强大的 SQLAgent、更高效的检索 Agent,但整个系统的“交通枢纽”——任务分配环节——却变得越来越拥堵。
想象中多个 Agent 游刃有余、自动协同的场景并未完全实现。究其原因,传统 Router 的智能上限太低,其有限的决策能力很难跟上日益增长和复杂的 Agent 队伍。未来的企业 AI 系统,Agent 数量会更多,能力边界也会更模糊,系统必须进化出“承认不确定性并协作解决”的核心能力。
近期,腾讯云正式开源了 TCAR。这是一个参数量仅 4B,但学会了“先想清楚,再选择”的智能路由模型。它专为解决跨域、冲突和模糊问题而生,为企业 AI 应用提供了 Reasoning-centric Routing 结合 Multi-Agent Collaboration 的基础范式。
为什么传统 Router 在企业运维场景里“玩不转”了?
我们可以通过几个典型场景来直观感受传统路由的困境:
1. 选择困难症
不同 Agent 可能都能解决同一个问题,但传统 Router 通常是单标签分类,只能硬性选择一个,无法给出最优或复合型的解决方案。
2. 无视新人
新业务上线、新 Agent 加入是常态,但传统 Router 对这些“新同事”完全不了解,需要重新训练模型,无法快速将合适的工作分配给新力量。
3. 模糊指令
用户的问题描述往往模糊不清。例如,一句“网站访问慢”,传统 Router 很难判断问题究竟出在 CDN、对象存储还是底层网络,导致任务分发失准。
4. 一条道走到黑
传统 Router 的决策过程缺乏可解释性,像一个黑盒。一旦路由错误,后续再强大的 Agent 也无力回天,因为任务从一开始就交给了错误的对象。
总结来说,传统 Router 面对复杂多变的企业AI运维场景有三大硬伤:搞不定跨域问题、解不了任务冲突、跟不上业务变化。
TCAR 的解法:像人类专家一样“先想后做”
TCAR 的核心思路直指要害,但在以往的 Router 设计中却常被忽视——将路由过程从直接预测输出标签,转变为先推理分析,再选择 Agent 集合。
这意味着,Router 的角色发生了根本性转变:从一个被动的任务转接系统,升级为一个具备主动推理能力的“决策者”。它的工作从简单的“单项选择”变成了复杂的“撰写分析报告 + 组建专项任务组”;职能从“挑选队列最前面的员工”,转变为“在专家库中组建最合适的攻坚团队”。
TCAR 就像一个拥有顶尖专家资源、高度智能且能自我决策的“项目经理”。
能力一:Reason-then-Select(拒绝黑盒,把思考过程写出来)
TCAR 在最终输出 Agent 选择之前,会先生成一段自然语言推理链。这段文字会明确说明:当前问题可能涉及哪些技术栈、不同候选 Agent 的职责边界是什么、为什么需要多个 Agent 协作执行是合理的。
这让路由决策不再是黑盒,变得可解释、可调试,并能基于这些推理持续优化对 Agent 的能力描述。
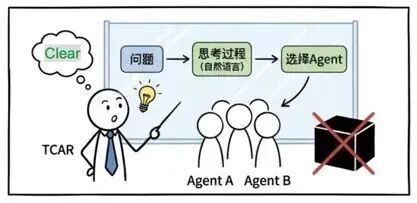
能力二:从单挑到团战
TCAR 的路由结果不再是传统的 one-hot 向量(只选一个),而是一个 Agent 子集。这一步直接解决了企业系统中最棘手的 Agent 能力冲突问题:它不强行将复杂问题压缩成单一决策,而是保留合理的不确定性,并将协作解决的任务交给后续环节。当然,这建立在模型对指令具备足够聪明的理解能力之上。

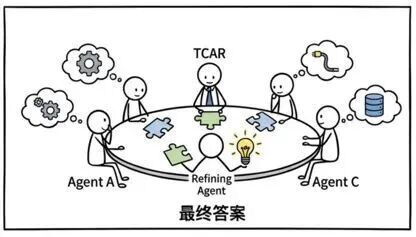
能力三:专家会诊,择优输出
当 TCAR 筛选出多个候选 Agent 后,每个 Agent 会独立给出自己的专业答案。随后,一个专门的 Refining Agent 会负责对比这些答案、消除歧义、进行融合,最终输出一个完整且一致的最佳答案。这套“会诊”模式在处理故障排查等复杂问题上效果尤为突出。
覆盖全面、命中精准,硬核且强大
TCAR 并非简单的 Prompt 工程产物。为了赋予它上述核心能力,研发团队做了两项关键工作:
1. 两阶段训练 + 模型融合
采用两阶段训练策略,兼顾模型的推理能力和选择精度。
- 阶段一:监督微调 - 教会模型进行结构化推理,并学会输出合理的 Agent 集合。训练后通过 Slerp 方法融合多个模型。
- 阶段二:强化学习 - 重点优化模型“选得对不对”,使用 DAPO 等方法进行精细调教。
2. 专为多 Agent 设计的奖励函数
将路由视为一个集合预测问题,设计了专门的奖励函数,在覆盖率和精确度之间取得平衡。
- R1 奖励:类似于精确率,评估选出的 Agent 中有多少是真正相关的(防止选一堆无关角色)。
- R2 奖励:类似于召回率,评估是否漏掉了关键的 Agent(防止遗漏核心主力)。
- 长度惩罚:防止模型为了求稳而选择所有 Agent,鼓励精炼的集合。
最终,在 CLINC150、HWU64 等多个数据集的评测中,TCAR 在企业高冲突数据上全面超越了当前的主流大模型路由方案。它在高歧义、跨域问题中表现更稳定,4B 的参数量也保证了推理速度快、成本低。更重要的是,下游“多 Agent + Refining Agent”协作模式的整体任务成功率得到了显著提升。
腾讯云此次开源提供了完整的落地范式,包括:TCAR 路由模型(4B)、Prompt 规范(用于 Router 和 Refining Agent)、详细的训练方法与实验细节,以及一套可直接部署的多 Agent 路由框架。开发者可以访问 开源实战 板块获取更多相关资源和讨论。
相关资源链接:
 发表于 2026-1-20 19:25:31
|
查看: 372|
回复: 0
发表于 2026-1-20 19:25:31
|
查看: 372|
回复: 0
