想象一下,你正在玩《我的世界》,你和朋友一起挖矿、盖房子、打怪。传统的AI“世界模型”就像一个只能看单人游戏录像的“单机玩家”。它能根据你的操作预测你接下来会看到什么,但完全不知道你朋友在干什么,更无法模拟出当朋友在你面前放个方块时,你的视角里应该如何正确出现这个方块。
现实世界是多智能体的,要构建真正能模拟复杂交互的环境,AI必须学会“联机”。这不,纽约大学的研究者们就把这个“联机版”的世界模型给造出来了,取了个响亮的名字——Solaris。
简单来说,给它几个起始画面和两位玩家未来的一连串操作指令,它就能像播放电影一样,生成出两个视角同步、世界状态一致的未来视频。下面就是它的“作品”展示:
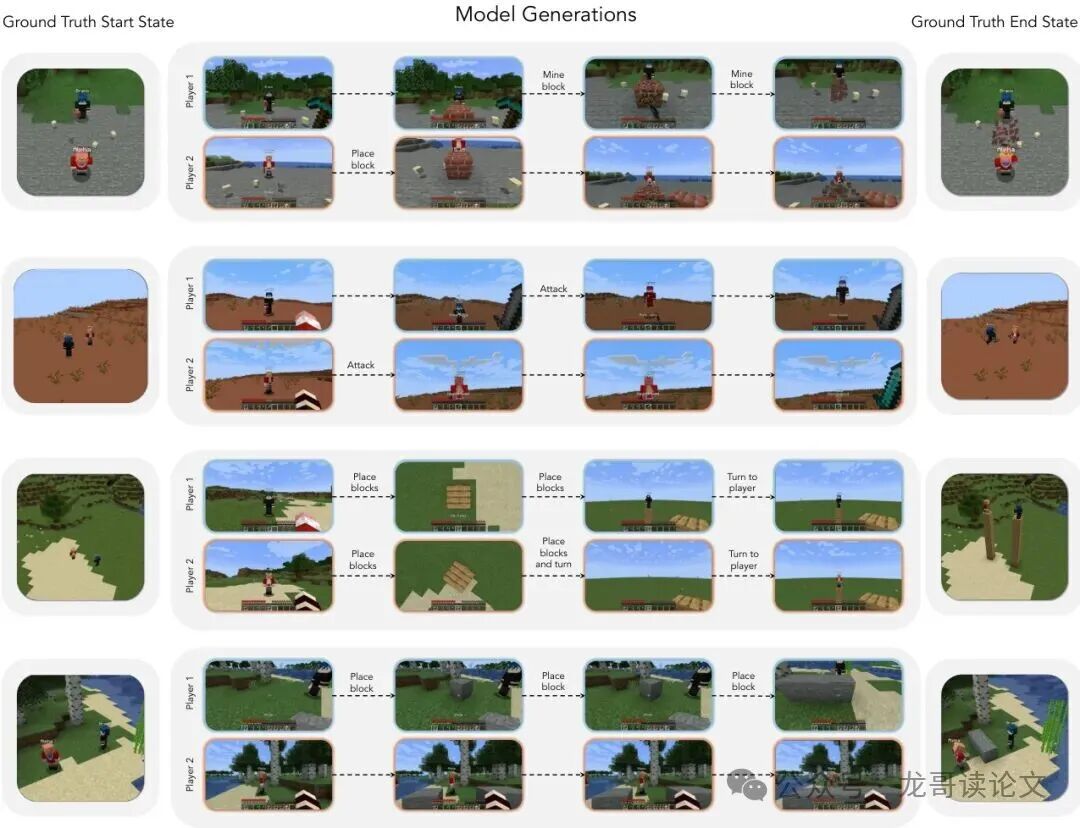
图1:模型生成的视频样本。模型输入每位玩家的起始帧和动作序列,生成动作驱动的视频。此处显示的动作描述是跨越许多帧的细粒度动作序列的摘要。第三人称的真实情况可视化并未提供给模型。
为了实现这个目标,这篇论文可不只是提出了一个新模型,它还顺带造了一整个“生态系统”:自动化的数据采集框架、大规模的多玩家数据集、新的训练技巧,并且全部开源。
打破单机视角:多玩家世界模型为何是下一站
首先得搞明白啥是视频世界模型。你可以把它想象成一个能做梦的AI。给它看一段过去的游戏画面(观察),再告诉它你接下来想干嘛(动作),它就能在脑子里“模拟”出未来可能看到的画面。这个能力对训练AI智能体至关重要,比如让AI先在虚拟环境里“脑内预演”无数次,再在现实世界中行动,既安全又高效。
但目前的模型大多只能模拟单一视角。这在多人场景下就出问题了:玩家A挖了个坑,这个坑必须在玩家B的视角里同步出现,位置、光影、纹理都得对得上。这不仅仅是生成两个独立的视频,而是要求模型内部有一个统一、一致的世界状态表征。
为什么选《我的世界》?因为它是个完美的“压力测试场”:
- 视角一致性难题:3D开放世界,有遮挡,有复杂地形,不同视角看同一个物体差别巨大。
- 动态与记忆:世界会被改变(挖坑、盖房),模型需要长期记住这些变化。
- 随机性与可控性:天气、怪物是随机的,而玩家动作是可控的,模型得能区分这二者。
- 无限复杂度:通过合成与建造,可以创造出几乎任何结构。
要在这样的环境里搞多玩家建模,第一步就卡住了:没有现成的大规模、高质量多玩家数据。总不能真雇两个人玩上几千小时吧?
SolarisEngine揭秘:如何自动化采集海量多玩家游戏数据
于是,研究团队自己动手,丰衣足食,打造了SolarisEngine。这是一个为规模化采集程序化多玩家《我的世界》游戏数据而生的框架。它的核心目标:让AI机器人像人一样合作玩耍,并同步录制下画面和精细操作。
他们比较了现有的各种《我的世界》AI框架,发现要么没有视觉输出,要么无法进行精细的多玩家协同控制。SolarisEngine是首个集大成的解决方案。

表1:Minecraft AI框架对比。不同于之前的系统,SolarisEngine支持可控制的多玩家游戏数据收集,并提供真实的Minecraft图形。
整个系统的架构非常巧妙,可以看下图:
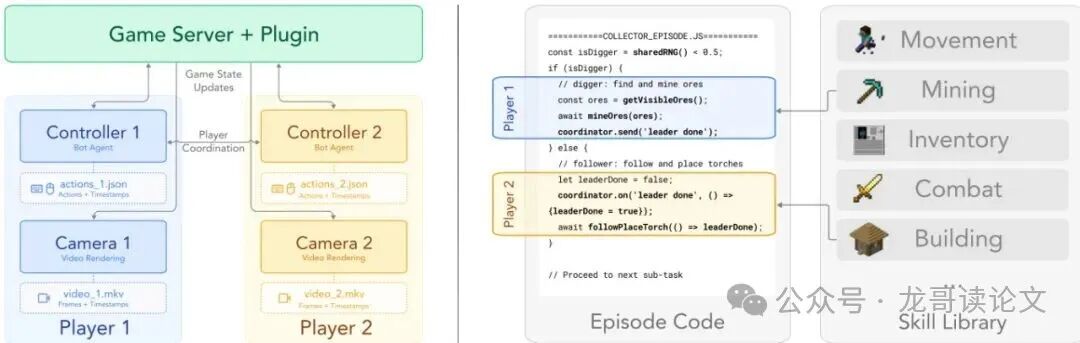
图2:SolarisEngine概览。(左)基于Docker的容器化游戏服务器、摄像机和控制器机器人的编排。摄像机通过自定义服务器插件镜像控制器的状态和动作;控制器是运行情景代码并记录低级动作的Mineflayer机器人。(右)情景从共享库中组合可重用的技能基元。图中展示了简化的“收集者”情景代码。
1. 分工合作的双胞胎机器人:每个玩家由一对“机器人”实现。
- 控制器:一个使用Mineflayer(一个JS库)的“大脑”。它运行高级的、可编程的情景代码,并将这些高级指令分解成低级的键盘鼠标操作序列记录下来。
- 摄像机:一个运行在无头模式下的官方Minecraft客户端,负责GPU渲染出高清游戏画面。通过一个自定义的服务器插件,摄像机完全同步控制器的位置、视角甚至动画。
2. 模块化情景库:研究者编写了一个可复用的技能库,比如“移动到某点”、“放置方块”、“攻击怪物”。将这些技能像乐高一样组合,就形成了丰富的多玩家合作情景。这些情景代码驱动控制器机器人产生拟人化且多样的游戏行为。
3. 工业化生产流水线:整个系统被打包在Docker容器中。通过Python脚本和Docker Compose进行编排,可以同时启动多个这样的“游戏单元”,7x24小时不间断地、自动化地收集数据。系统还内置了错误检测和恢复机制。
最终,他们用这个“印钞机”产出了一个包含1264万帧(两位玩家各632万帧) 的大型多玩家训练数据集。数据涵盖了建造、战斗、移动、采矿四大类情景,动作空间也覆盖了完整的Minecraft操作。
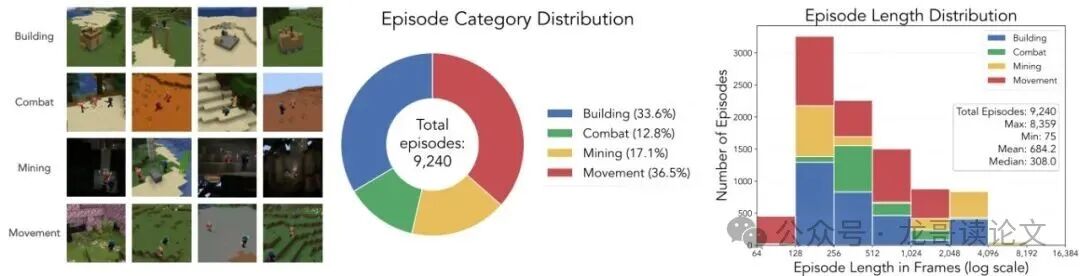
图3:训练数据集统计。(左)数据集包含四种不同的情景类别。(中)共有9240个情景,总计1264万帧。(右)情景长度分布。

图4:训练数据集中的情景演示。展示了3个不同训练情景在不同时间点录制的帧。
模型架构巧思:当单玩家DiT学会“左右互搏”
Solaris模型的骨架基于一个强大的单玩家可控视频生成模型——Matrix Game 2.0。它本身是一个视频Diffusion Transformer(DiT),已经在包括《我的世界》在内的多个游戏数据上训练过。
为了让这个“单机高手”变成“联机大神”,研究者只做了几个关键而精巧的改动:
1. 输入重塑:把两个玩家的视频“拼”起来
原本的模型输入是 (批次,时间,高度,宽度,通道)。现在,他们增加了一个“玩家”维度,变成 (批次,玩家,时间,高度,宽度,通道)。简单理解,就是把两个玩家的视频帧,在“玩家”这个维度上堆叠起来,形成一个更大的张量输入模型。
2. 核心交流层:共享的自注意力(Self-Attention)
这是实现视角一致性的关键。在DiT的每个模块中,都有一个自注意力层。研究者修改了这一层,使其能够跨玩家进行信息交互。
具体做法是:将所有玩家的所有视频帧的token展平成一个长的序列,然后送入一个共享的自注意力模块进行计算。在这个模块里,玩家A的某个token可以关注到玩家B的任意token。
为了让模型区分不同玩家的信息,他们做了两件事:一是为每个token加上可学习的玩家ID嵌入;二是对每个玩家单独应用位置编码,确保空间位置信息只在玩家内部有意义。
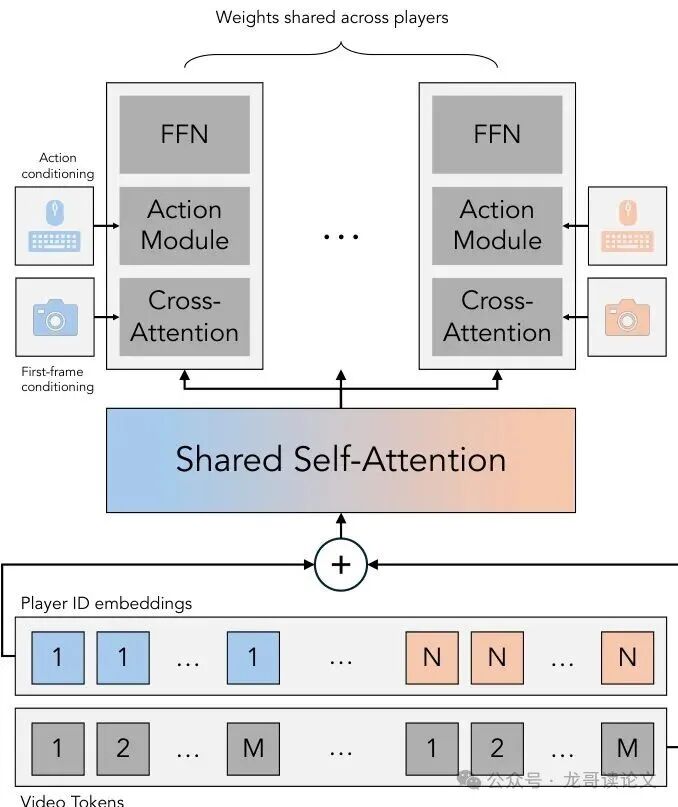
图5:修改后的DiT模块通过沿序列维度的视觉交织实现多玩家建模。多玩家信息通过共享的自注意力模块进行交换。其他模块与Matrix Game 2.0相同,并独立应用于每个玩家。
3. 独立处理模块:各玩各的,但又心连心
除了共享的自注意力层,DiT模块中的其他部分则保持独立,分别应用于每个玩家。动作条件模块也是独立处理每个玩家的动作序列后,再将结果合并。
这种设计哲学很妙:在需要全局协调的地方(自注意力)让他们充分交流,在局部处理的地方又让他们保持独立,既实现了信息互通,又保留了处理效率。
四阶段训练法:从单机到联机的平滑过渡
有了架构和数据,直接上手训练多玩家模型依然困难。研究者设计了一个四阶段渐进式训练流水线,让模型从易到难,平滑过渡。
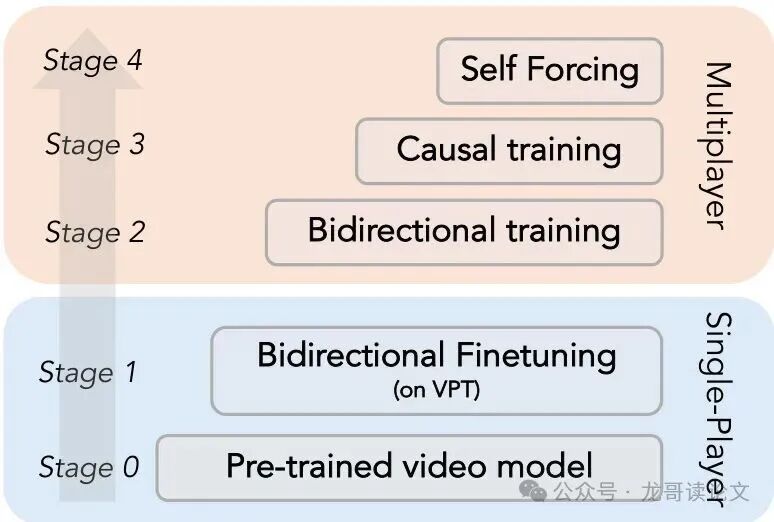
图6:完整的训练流程概览。从一个预训练好的双向视频扩散模型开始,我们首先用单玩家数据对其进行微调,然后用多玩家数据微调。接着我们使用因果掩码对其进行微调,最后使用自强迫训练来实现稳定的长视野自回归生成。
-
阶段1:单玩家双向训练
用大规模的单人人类游戏数据(VPT数据集) 微调Matrix Game 2.0,并扩展其动作空间。这一步是让模型打好《我的世界》游戏理解和动作控制的基础。
-
阶段2:多玩家双向训练
将上一步的模型加载进来,应用架构修改,然后在自采的多玩家数据上进行训练。此时模型能看到完整的未来帧,学习目标是生成高质量、视角一致的多玩家视频。这个模型将作为后续阶段的“教师”。
-
阶段3:多玩家因果训练
从阶段2中途的检查点分叉,训练一个因果模型。因果模型在训练时只能看到过去和当前的信息,这才是最终能用于自回归生成的模型。这个模型将作为“学生”。
-
阶段4:自强迫训练
这是提升长序列生成质量的关键。简单来说,就是让“学生”模型(因果)根据“教师”模型(双向)的指导来学习。流程:先用学生模型自回归地生成一段视频。然后,把这段生成视频(作为“历史”)和真实的未来动作一起输入给强大的教师模型,让教师模型生成一个高质量的“修正版”未来视频。最后,用这个“修正版”作为目标,去监督训练学生模型。
但是,这里有个大问题:学生自回归生成时,只能看到有限的过去几帧,而教师模型理论上能看到很长的上下文。如何让一个“目光短浅”的学生,接受一个“高瞻远瞩”的教师的指导?
检查点自强迫:让长序列生成不再“爆内存”
为了让学生能利用长上下文教师,需要在生成过程中使用滑动窗口。但朴素的自强迫方法在这里会遭遇严重的内存瓶颈。因为每次滑动窗口生成都需要保存中间的计算图用于反向传播,窗口重叠会导致大量冗余张量被保留,内存消耗巨大。
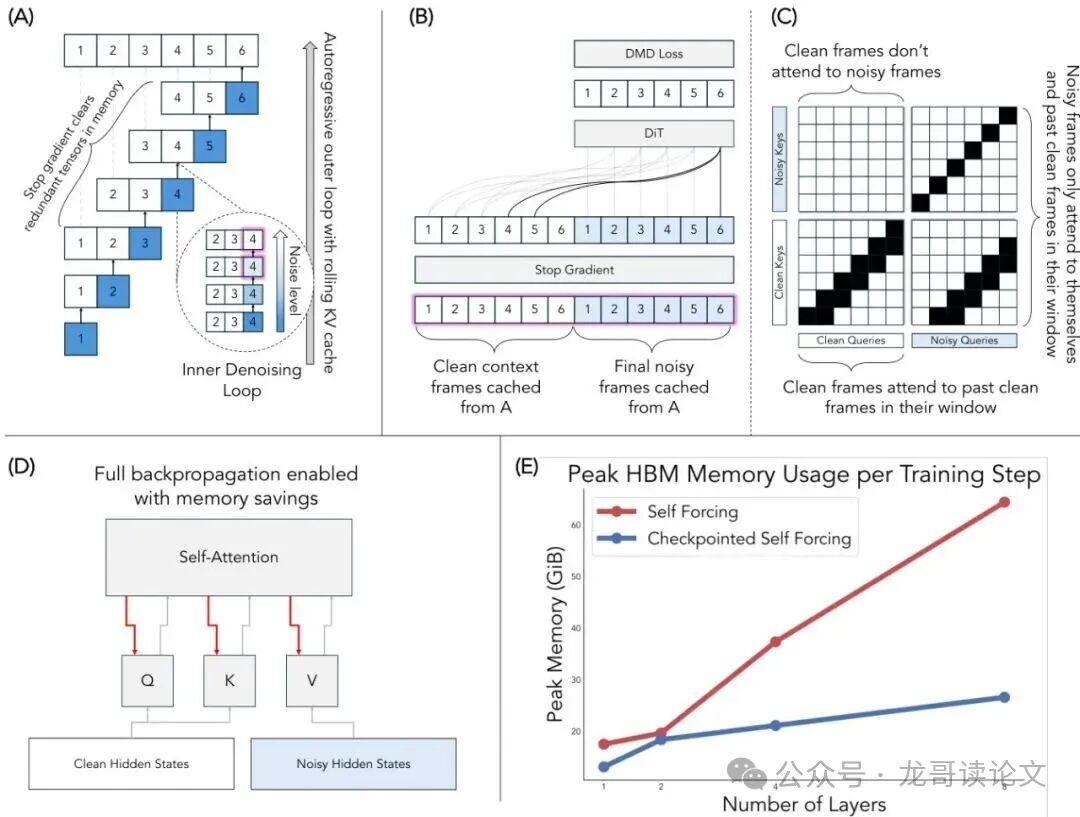
图7:检查点自强迫概览。(A)使用滑动窗口KV缓存生成视频。朴素的反向传播内存消耗巨大。(B)我们的重计算步骤并行模拟每一帧的最后一步去噪。(C)注意力掩码示意图。(D)利用内存节省启用通过KV层的反向传播。(E)在不同深度下,朴素方法和检查点自强迫的峰值内存比较。
为此,论文提出了检查点自强迫,灵感来源于训练中的梯度检查点技术。核心思想是:将“生成”和“学习”解耦。
第一步(前向传播,不保留梯度):让学生模型完整地、自回归地生成整个长视频,并缓存两个东西:1)每一步生成的清晰帧(作为历史上下文);2)去噪过程中某一步的带噪声的中间状态。
第二步(重计算,保留梯度):利用缓存的数据,在一个并行的前向传播中,模拟整个自回归生成过程的最后一步去噪。具体做法是,将缓存的所有清晰帧(历史)和所有带噪声的中间帧(待预测的未来)拼接成一个长序列,然后通过一个精心设计的“教师强迫”注意力掩码,强制每个噪声帧只关注它前面一个滑动窗口内的清晰历史帧。这样,就一次性、并行地计算出了所有帧的最终预测结果,并且这个计算过程是可导的。
第三步(计算损失):用教师模型根据真实动作和缓存的历史清晰帧,生成高质量的未来帧作为“金标准”。然后用这个“金标准”与第二步中学生模型并行预测出的结果计算损失,进行反向传播。
这个方法将内存复杂度从 *O(L_t L_s) 降低到了 O(L_t)**,使得用长上下文教师来训练学生成为可能,并且实验证明还能让梯度流经更多的模型参数,进一步提升生成质量。
经过这一系列精心的设计、海量数据的喂养和分阶段的训练,最终得到的Solaris模型表现如何?
实验结果:在Minecraft中实现逼真的多智能体协同与对抗
研究者设计了一套针对多玩家能力的评估基准。除了传统的FID指标,他们还创新性地使用VLM(视觉语言模型)作为裁判,让VLM看生成的视频并回答关于任务完成情况的问题,以此衡量生成视频的语义正确性。
定性效果惊人。在长序列生成(224帧)的对比中,Solaris能保持稳定的战斗画面和复杂的、纹理真实的地形。而作为对比的基线方法则出现了严重的画面退化、纹理扁平化和玩家身体复制等诡异现象。

图9:定性比较。我们的模型Solaris能够为长视野(此处为224帧)生成稳定且连贯的帧。与基线不同,它保持了真实的战斗玩法,并显示了保持真实纹理的复杂地形。
更令人印象深刻的是模型学会的复杂游戏动态和状态跟踪能力:

图10:习得能力的定性示例。各行说明:(1)细粒度状态跟踪,特别是放置方块后的物品栏计数器同步;(2)全局环境一致性,通过同时开始下雨来展示;(3)物品栏激活物品同步、火把放置和生成准确的挖掘动画;(4)复杂地形上连贯的玩家对战。
这些例子表明,Solaris不仅仅是在“画”两个看起来合理的视频,它内部确实建立了一个共享的、可推理的世界状态模型。它能理解“放置一个方块会减少物品栏中该方块的数量”,并且这个数量变化在两个玩家的视角里是逻辑同步的;它能模拟全局天气事件(下雨)对两个视角的同时影响;甚至能生成正确的工具使用动画。
深度剖析与问题解答
下面是对于可能的一些问题的解答:
1. 这篇论文里的“世界模型”和我们常说的“大语言模型”有啥关系?
它们都是“基础模型”,但模态和任务不同。大语言模型学习文本的分布和规律。视频世界模型学习视觉物理世界的动态规律。一个理解“文字世界”,一个模拟“视觉世界”。未来,多模态的世界模型可能会将二者结合,让AI既能理解语言指令,又能模拟复杂的物理交互。
2. SolarisEngine搞这么复杂的数据采集系统,直接用人类玩家的录屏不行吗?
对于高质量、可控、大规模的多玩家协作数据,几乎不可能通过录屏获得。首先,协调大量人类玩家进行特定任务成本极高。其次,人类行为有噪音、不可控,不利于模型学习精确的因果关系。最后,自动化系统可以7x24小时运行,快速生成海量、多样、且带有完美对齐的动作标注的数据,这是人类录屏无法比拟的效率优势。
3. 模型如何确保两个玩家视角里发生的事情是一致的?比如A挖的坑,在B的视角里位置要对。
这是本文的核心挑战。关键就在于共享的自注意力机制和在统一的世界状态张量上进行扩散去噪。模型不是独立生成两个视频。在去噪过程中,模型“看到”的是所有玩家所有帧的混合信息。通过跨玩家的注意力,模型可以(隐式地)推算出A的动作在世界坐标系中的位置,然后根据B的视角位置,计算出这个坑在B的相机画面中应该出现在哪个像素位置。所有玩家的画面是在同一个去噪过程中共同被优化的,因此自然趋向于一致。
简评
论文创新性:将视频世界模型从单智能体拓展到多智能体,并系统性解决了数据、架构、训练等一系列问题,思路清晰,贡献扎实。检查点自强迫是针对具体工程难题的巧妙创新。
实验合理度:评估体系设计得比较全面,结合了传统指标和基于VLM的语义评估。对比实验覆盖了不同的架构设计、训练策略,能有效支撑结论。
学术研究价值:价值非常高。它开辟了“多玩家视频世界模型”这个明确的新方向,提供了首个完整的开源工作栈(数据引擎+数据集+模型+评测),极大降低了后续研究者的入门门槛,很可能成为该领域的一个基准工作和灵感来源。
稳定性与泛化:从论文展示的生成样本看,在训练数据分布内的情景下表现稳定。但对于更开放、更复杂的多人交互,其稳定性未知。目前仅在《我的世界》的特定情景中得到验证,架构设计通用,但要泛化到其他场景需要重新收集数据和训练。
硬件与复现:基于大型视频DiT,训练和推理都需要大量计算资源,属于“重型”研究模型。但论文作者将代码、模型权重、数据集全部开源,复现和在此基础上进行研究几乎没有障碍。
主要参考文献
- Savva et al., “Solaris: Building a Multiplayer Video World Model in Minecraft”, arXiv:2602.22208, 2026.
- Baker et al., “Video Pretraining (VPT): Learning to Act by Watching Unlabeled Online Videos”, NeurIPS 2022.
- Peebles & Xie, “Scalable Diffusion Models with Transformers”, ICCV 2023.
- Du et al., “Matrix Game: Controllable Video Generation with Multiple Condition Modalities”, 2024.
本文解读基于公开论文,仅代表个人理解,欢迎理性探讨。想了解更多前沿技术解析,欢迎访问云栈社区与广大开发者交流。
 发表于 2026-3-1 03:35:57
|
查看: 174|
回复: 0
发表于 2026-3-1 03:35:57
|
查看: 174|
回复: 0
