昨天,智谱 AI 公开了其 GLM-5 的技术报告,长达 40 页,副标题是“from Vibe Coding to Agentic Engineering”。

论文链接:https://arxiv.org/abs/2602.15763
“Vibe Coding”是什么?大概就是你对 AI 说“帮我写个贪吃蛇游戏”,它就给你生成代码。而“Agentic Engineering”则更进一步,当你指出“这个系统有个 bug”,AI 能够自行定位问题、修改代码并运行测试,全程无需你插手。
从“辅助编码”到“独立完成工程任务”,这种转变对模型的训练提出了截然不同的要求。这份技术报告揭示了智谱团队如何应对这些挑战,我们来深入解读一下。
一、先看成绩单:GLM-5 的实力如何?
GLM-5 发布后,硅谷顶级风投机构 a16z 发布了一组数据,显示开源大模型与顶级闭源模型之间的能力差距正在快速缩小。
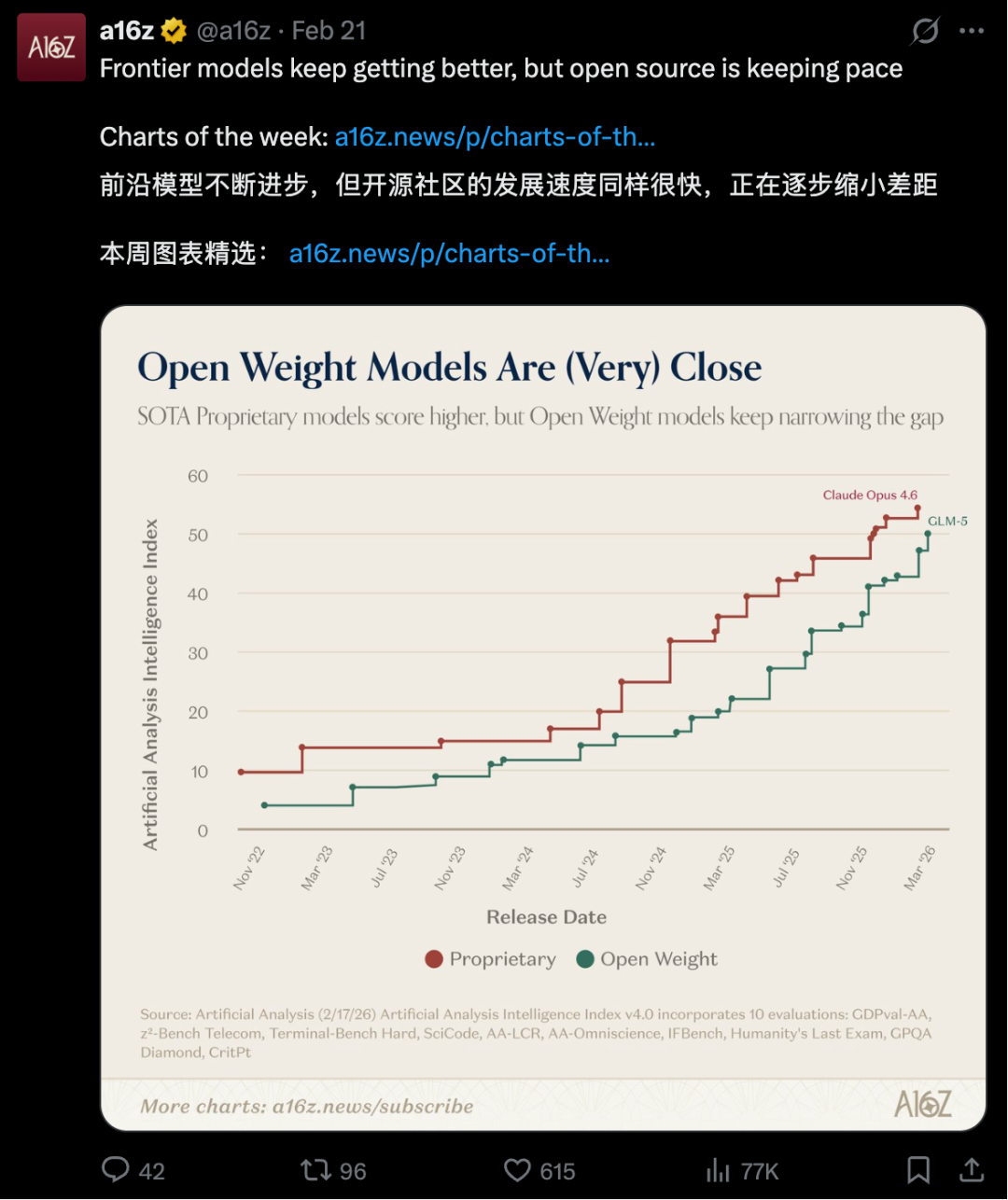
图中,与顶级闭源模型 Claude Opus 4.6 正面对标的,正是 GLM-5。
具体到各个评测,GLM-5 的表现同样亮眼:
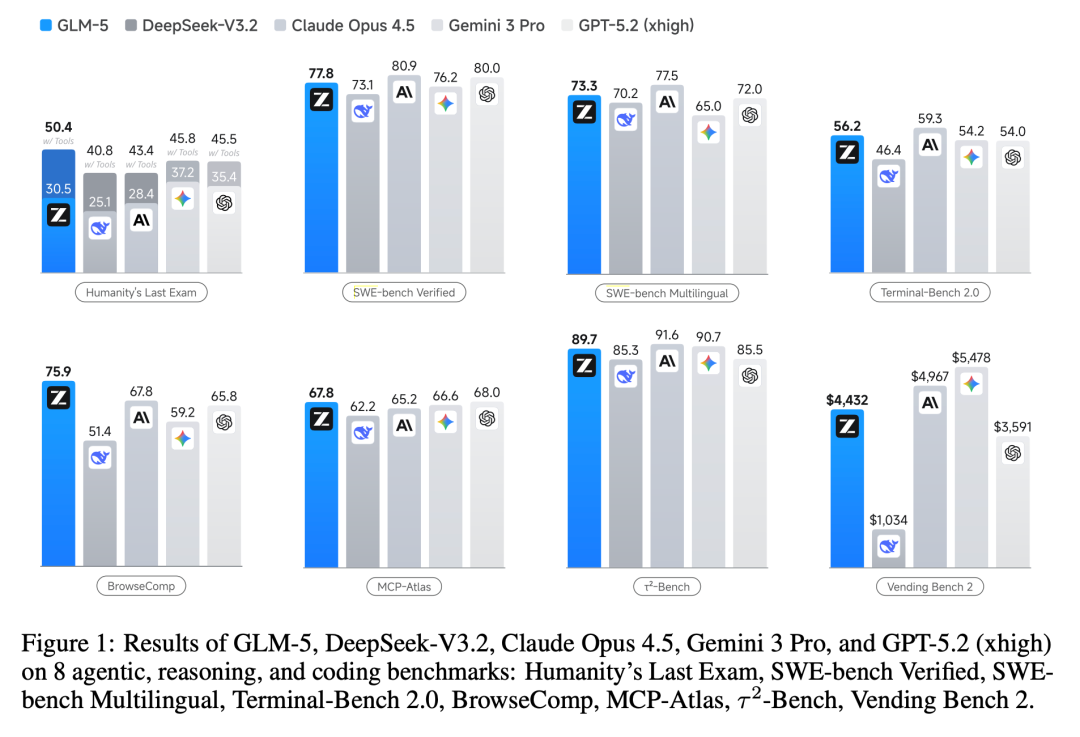
- SWE-bench Verified 达到 77.8%,在开源模型中排名第一。这项测试要求模型修复真实 GitHub 仓库中的 Bug。面对一个数万行代码的项目,模型需要完成查找问题、理解上下文、编写修复方案、并通过所有测试的全流程。
- BrowseComp 取得 75.9% 的分数,在所有模型中位列最高。该任务要求模型自主决定搜索关键词、点击哪些链接、从多个网页中提取信息,并综合得出最终答案。
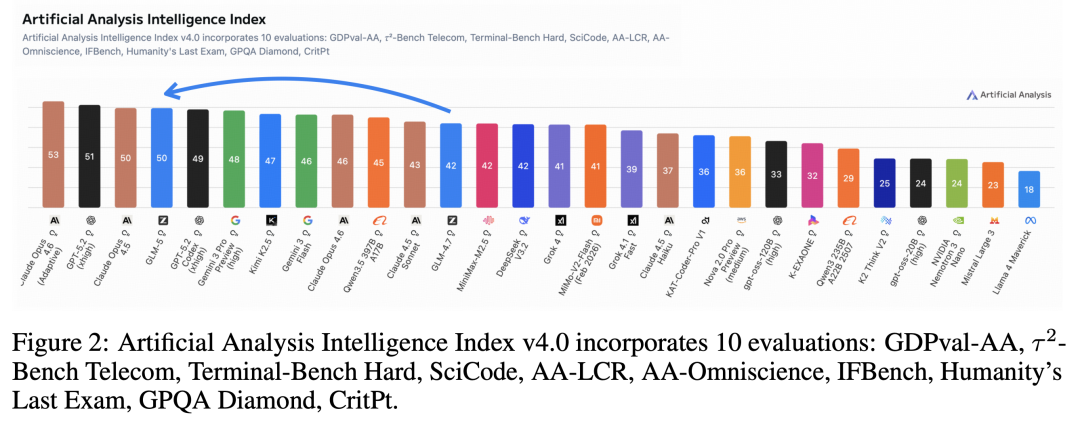
- Artificial Analysis Intelligence Index 得分 50 分,这是开源模型首次达到这一水平。
这些数据清晰地指向一个结论:GLM-5 是专为 Agent(智能体)场景优化的。无论是来自 a16z 的数据背书,还是 LMArena 上的真实用户投票,都表明 GLM-5 在编码和代理能力上已跻身全球第一梯队。
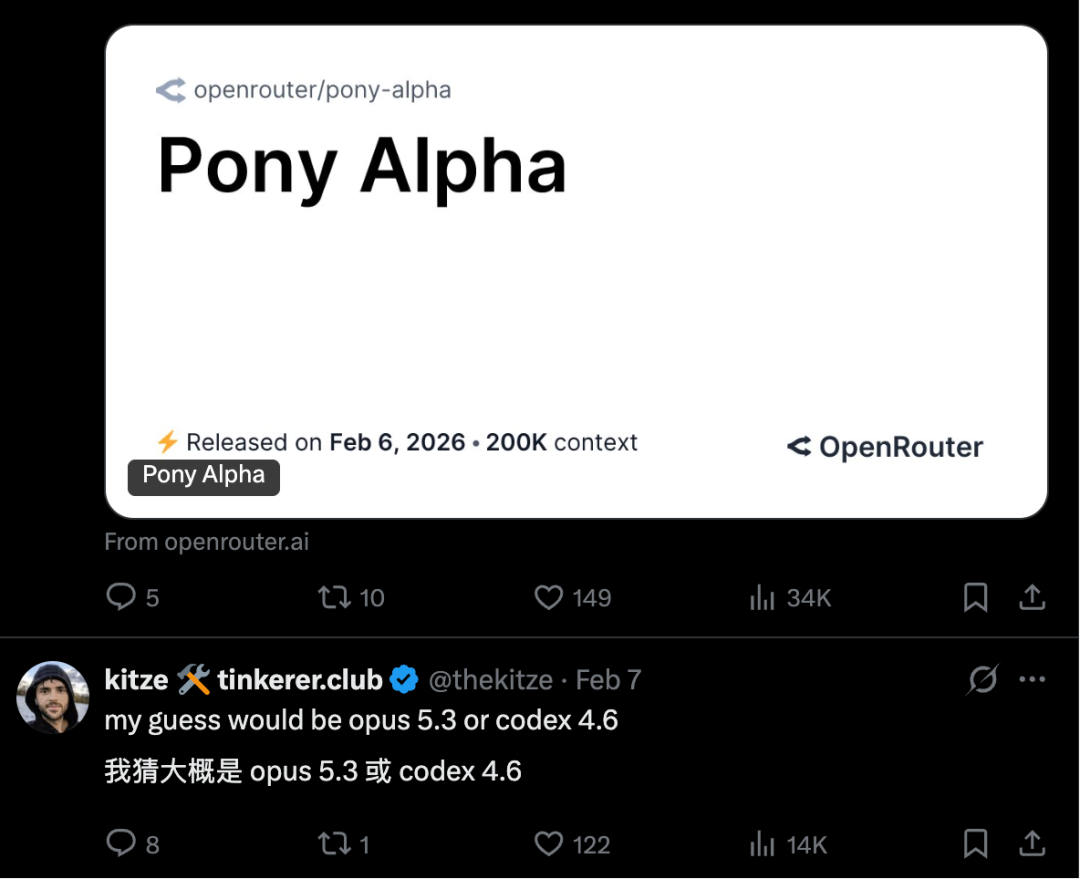
值得一提的是,GLM-5 在发布前曾以“Pony Alpha”的代号进行匿名盲测,被许多海外技术大 V 误认为是 Claude 或 Grok 的新模型。此外,GLM-5 从发布之初就原生适配了华为昇腾、摩尔线程等七大国产芯片平台,完成了从内核到框架的深度优化。
数据看完,问题随之而来:要训练出这样真正能“干活”的智能体,首先需要解决哪些根本性难题?
二、时间维度:如何提升 Agentic RL 的训练效率?
Agentic RL 为什么难训练?
传统的强化学习训练数学推理或代码生成任务时,流程很快:模型输出答案,判题系统立刻给出分数反馈,整个过程通常在 GPU 集群内部几秒内完成。
但 Agent 任务截然不同。假设任务是修复一个 Bug,模型可能需要先浏览整个代码库以定位相关文件,理解代码逻辑,编写修改方案,运行测试套件,分析测试结果,如果失败还要继续迭代修改。
这就导致了严重的资源浪费:昂贵的训练用 GPU 大部分时间在“等待”。它们需要等待 Agent 执行完漫长的外部任务、等待数据返回后,才能继续训练。传统的同步强化学习框架在这种场景下效率极低。单纯增加 GPU 数量并不能解决问题,因为瓶颈不在计算能力,而在于外部环境的响应速度。
Slime 框架:解耦生成与训练
GLM-5 团队的解决方案是 Slime,其核心思想是让任务生成(Rollout)和模型训练完全独立、异步运行。
Slime 框架分为两部分:
- Rollout 集群:专门负责执行具体的 Agent 任务。这些服务器各自独立运行,每台处理一个或多个任务。任务完成后,会将完整的交互轨迹(模型的每一步操作、环境的每一次反馈)打包发送出去。
- 训练集群:专门负责更新模型参数。一旦收到来自 Rollout 集群的轨迹数据,就立即开始训练,无需等待新任务执行完毕。
关键在于:两边互不等待。Rollout 集群持续不断地产生数据,训练集群则持续不断地消化这些数据进行学习。
但这种异步设计带来了两个新问题。
第一个是 Token 对齐问题。 Rollout 集群使用的模型版本可能与训练集群的当前版本不同。例如,Rollout 用 v1.3 版模型生成的数据,等数据传送到训练集群时,模型可能已经更新到了 v1.5。如果直接将 v1.3 版本的 Token 序列交给 v1.5 版本训练,可能会因为分词器不一致或新增特殊 Token 而出错。
对此,Slime 引入了一个 TITO(Token-In-Token-Out)网关。无论收到哪个模型版本生成的 Token,都先将其还原为原始文本,然后再使用当前训练版本的分词器重新进行编码。
第二个是离策略(Off-policy)训练的稳定性问题。 由于生成数据的模型(行为策略)与正在训练的模型(目标策略)不是同一版本,训练集群接收的是“旧策略”产生的数据。直接用这些数据训练新策略,若处理不当,会导致训练不稳定甚至崩溃。
Slime 采用 “双侧重要性采样” 来控制影响:在 Token 级别和样本级别都进行重要性加权。这样既能充分利用历史数据,又能防止极端样本将训练过程带偏。同时,Slime 还会记录每条数据的生成版本,自动丢弃过于陈旧的样本;并识别那些因环境故障(而非模型能力不足)导致的失败样本,避免噪声数据干扰。
训练效率问题是所有从事 Agent RL 研究的团队都会遇到的共性挑战。目前,整个 Slime 框架已经开源,其他团队可以直接在此基础上进行后续探索。
三、空间维度:如何应对 Agent 的超长上下文?
Slime 框架解决了训练的时间效率问题,但 Agent 任务还有另一个显著特点:上下文极长。
修复一个 Bug 可能需要阅读几十个代码文件,进行一次深度搜索可能要浏览几十个网页。这些内容加起来,上下文长度很容易超过 10 万 Token。而标准注意力机制的计算复杂度是 O(L²),当序列长度 L 达到 20 万时,计算量将大到难以承受。
1. 选择重要的 Token:引入稀疏注意力
为了降低计算成本,GLM-5 采用了由 DeepSeek 提出的 DSA(Dynamic Sparse Attention) 技术。其核心思路是使用一个轻量级的“索引器”来动态判断上下文序列中哪些 Token 最重要,然后只对这些选出的重要 Token 进行完整的注意力计算。
报告指出,DSA 能将长序列的注意力计算成本降低 1.5 到 2 倍。对于 20 万 Token 的上下文,可以用一半的计算资源完成相同的工作。
2. 稳定性优先:确定性与速度的权衡
然而,在实际应用 DSA 进行强化学习训练时,GLM-5 团队遇到了新问题:训练变得不稳定。
问题出在 DSA 用于筛选关键 Token 的 top-k 算子实现上。如果使用经过 CUDA 深度优化的 top-k 实现,速度虽快,但输出是非确定性的——即同样的输入,每次运行可能选出不同的关键 Token 集合。
这在模型推理阶段问题不大,但在强化学习训练中却是致命的。因为强化学习需要精确计算新旧策略的概率比值,如果同样的输入每次产生不同的中间表示,概率计算就会对不上,训练几步后模型性能就会急剧下降。
GLM-5 团队的解决方法是换用 PyTorch 原生的 torch.topk 实现。这个版本比 CUDA 优化版稍慢,但它的输出是确定性的——保证同样的输入每次选出的 Token 完全一致。改用确定性 top-k 后,强化学习训练才得以稳定进行。
这个选择很有意思:为了保障训练稳定性,他们选择牺牲一部分推理速度。但这个权衡是值得的,因为训练通常是一次性的大规模投入,而推理是持续的消耗。更重要的是,这一发现揭示了一个关键点:许多为推理阶段优化的技术,未必能直接套用在训练阶段。
同时,为了进一步稳定训练,GLM-5 在强化学习训练时 冻结了 DSA 索引器的参数,只更新模型主体部分的参数。这样既加快了训练速度,也避免了索引器在训练过程中出现不稳定的学习行为。
这个发现颇具价值。DSA 技术本身由 DeepSeek 提出,但如何在其核心的Transformer架构基础上,于强化学习的复杂场景下有效应用 DSA,GLM-5 团队通过实践摸索出了答案。
3. 更智能的上下文管理:保留关键信息
降低了计算成本、保证了训练稳定,接下来要解决的是:如何高效利用超长上下文?GLM-5 为模型设计了三种不同的“思考”模式:
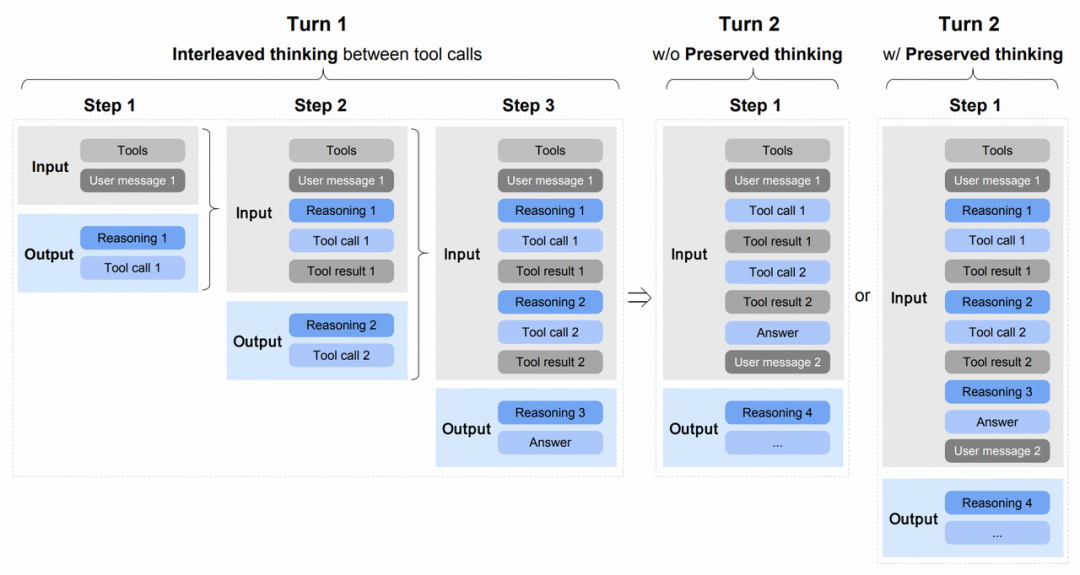
- 交错思考:每轮调用工具前都进行简短的思考。
- 保留思考:只在第一轮进行深度思考,后续轮次直接基于之前的思考执行动作。
- 轮次级思考:每轮都进行独立思考,上一轮的思考内容会被清除。
实验发现,在 SWE-bench 这类需要多轮交互的任务上,轮次级思考比交错思考的效果高出约 2 个百分点。原因在于,SWE-bench 任务中,过多的中间思考内容会占用宝贵的上下文空间,挤掉真正需要的代码和测试结果信息。
在浏览搜索任务上,GLM-5 采用了 “Keep-recent-k”策略:当交互历史超过一定长度后,只保留最近 k 轮的工具调用具体内容(实验中 k=5)。这一策略将 BrowseComp 任务的分数从 55.3% 提升到了 62.0%。他们进一步引入了 “混合层次管理”:如果总上下文超过 32K,就完全清空工具调用历史重新开始,但在新的上下文中继续应用 Keep-recent-k 策略。最终,他们在 BrowseComp 上取得了 75.9% 的最高分。
其核心思想很明确:长上下文并非越长越好,关键在于如何在有限的空间内,保留最核心、最关键的信息。
四、GLM-5 的完整训练方案全景
解决了训练效率和长上下文两大核心难题,我们再把视角拉高,看看 GLM-5 是如何构建一套完整的训练体系来打造真正实用的智能体。
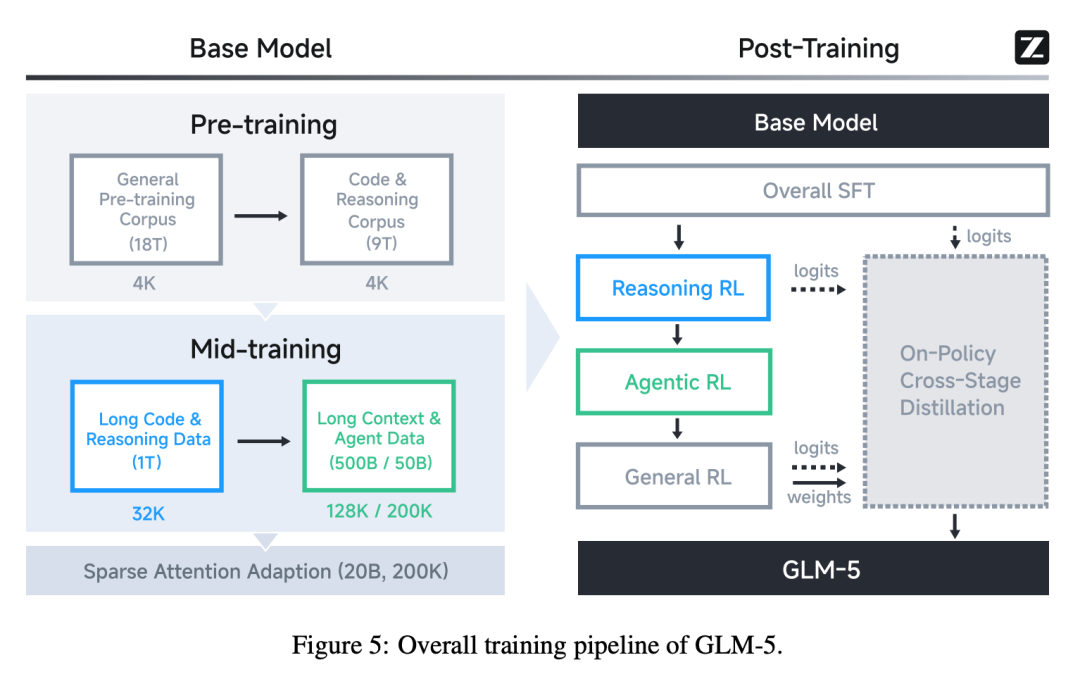
1. 分层训练,能力逐步叠加
GLM-5 的强化学习训练分为三个阶段,循序渐进:
- Reasoning RL:训练基础推理能力,使用数学题、科学问题、算法竞赛等有明确标准答案的任务。
- Agentic RL:训练智能体能力,使用真实的软件工程任务、终端操作、多步骤搜索任务。这个阶段就运用了前面介绍的 Slime 框架。
- General RL:训练通用对话能力,使用开放式对话、创意写作、角色扮演等任务。
这个顺序至关重要。推理能力是根基,智能体能力建立在良好的推理之上,而对话能力最容易被“遗忘”所以放在最后。Reasoning → Agentic → General,GLM-5 对模型能力进行了清晰的分层构建。
神经网络存在“灾难性遗忘”的特性:学习新任务时可能会部分遗忘旧任务。如果先训练对话再训练编程,编码能力可能会退化。为了缓解这一问题,GLM-5 采用了 “跨阶段蒸馏”。例如,在第二阶段(Agentic RL)训练时,将第一阶段(Reasoning RL)训练出的最佳模型作为“教师模型”,让正在训练的模型在学习新能力的同时,通过模仿来保持原有的推理能力。
效果是显著的。如果不进行蒸馏,从 Agentic RL 进入 General RL 阶段后,模型在 SWE-bench 上的分数会从 77.8% 下降到 73.2%。而实施了跨阶段蒸馏后,分数基本保持不变。
2. 构建海量、高质量、可验证的训练环境
这套分层训练体系能够运转,其背后是大量精心设计的、可自动验证的训练环境。
- 软件工程任务环境:团队收集了大量真实的 GitHub Issue 和对应的 Pull Request,并利用 RepoLaunch 框架自动构建可执行环境。该流程会自动分析项目依赖、生成安装脚本、提取测试命令,甚至使用一个 LLM 来生成日志解析函数以判断测试是否通过。最终构建了超过 1 万个可验证的代码修复环境,覆盖 9 种编程语言。
- 终端任务环境:设计了三阶段数据合成流程:1) 用 LLM 生成任务草稿;2) 构建 Agent 将其实例化为具体的 Docker 环境和测试脚本;3) 精炼 Agent 检查并优化任务。最终产生了数千个可验证的终端操作任务,Docker 环境构建成功率超过 90%。
- 搜索任务环境:从早期搜索智能体的真实交互轨迹中收集了超过 200 万个高质量网页,并使用 LLM 从中提取实体关系以构建知识图谱。然后从图谱中选取低频实体作为种子,扩展其多跳邻域,从而生成需要多步推理才能回答的问题。生成的问题还会经过三轮严格筛选,剔除过于简单、过于困难或答案不唯一的题目。
这些可验证的环境是 Agent 强化学习训练的基石。没有它们,就无法为模型的每一步动作提供自动、准确的奖励信号。投入海量资源构建这上万个环境,体现了工程实践的深度。
3. 高效优化基座模型:让先进技术协同工作
训练体系搭好了,环境也齐备了,但还有一个重要前提:基座模型本身必须足够强大。GLM-5 在预训练阶段进行了两项关键的工程优化,让原本可能存在冲突的先进技术能够协同工作。
其一是让 MLA(Multi-Head Latent Attention) 和 Muon 技术配合工作。两者单独使用都能提升性能,但组合时会冲突:MLA 希望将多个注意力头的 Key-Value 状态压缩合并以节省显存和带宽,而 Muon 作为一种参数高效微调方法,需要对每个注意力头进行独立的低秩适配。GLM-5 团队的解决方案是 “Muon Split”:在优化时,先将 MLA 压缩后的表示按注意力头拆分开,让 Muon 对每个头独立进行优化,优化完成后再合并回去。实验表明,这一改动使得 MLA+Muon 的组合达到了与标准 GQA(Grouped-Query Attention)相当的性能,同时保留了 MLA 在显存和速度上的优势。

其二是 参数共享的多 Token 预测。GLM-5 使用了 3 个预测层来同时预测后续多个 Token,但这 3 个层共享同一套参数。这种参数共享机制迫使模型学习更通用的“多步预测”能力。测试显示,在相同的推测解码步数下,GLM-5 的接受长度(Acceptance Length)比 DeepSeek-V3 高出约 8%。
五、写在最后
回到报告的副标题:从 Vibe Coding 到 Agentic Engineering,这一转变究竟意味着什么?
它意味着 AI 大模型训练的扩展范式正在发生转变。
过去,训练一个强大的模型,核心思路往往是“暴力扩展”——追求更大的参数量、更多的训练数据、更长的训练时间。模型训练完成后,发布权重,任务就基本结束了。
而现在,要训练一个真正能用的智能体,核心思路转向了 “聪明扩展” 。通过异步训练架构(Slime)解决时间维度的效率问题,通过稀疏注意力(DSA)解决空间维度的计算问题,再结合能力分层训练、海量可验证环境构建、基座模型协同优化等手段——每一步都是在用更精巧的工程设计和算法创新来解决问题,而非单纯依赖规模的堆砌。
更重要的是,智谱 AI 将包括 Slime 框架在内的这套方案进行了开源。这使得智能体训练不再是少数顶尖实验室的“黑箱”实验,而变成了可以被社区广泛复现、改进乃至超越的公开工程实践。
模型能力的追赶固然重要,但工程范式的开放与共享,才是推动整个人工智能生态持续向前发展的关键动力。对于希望深入理解大模型前沿训练技术的开发者而言,这份详细的技术报告无疑提供了极具价值的参考。
 发表于 2026-2-25 05:57:23
|
查看: 583|
回复: 0
发表于 2026-2-25 05:57:23
|
查看: 583|
回复: 0
