比起算力规模,那些在工程一线沉淀的系统决策,才是模型性能的胜负手。
大模型的演进往往给外界一种“算力即一切”的错觉。但对于真正的一线研发团队而言,决定模型最终性能的,往往是那些隐藏在海量参数背后的系统工程决策。
那么,全球最顶尖的 AI 实验室究竟在使用怎样的技术路线?
本文系统梳理了 OpenAI (gpt-oss-120b)、DeepSeek (DeepSeek-R1)、Hugging Face (SmolLM3)、Moonshot (Kimi K2)、Prime Intellect (Intellect 3) 等 7 家前沿实验室的开源模型报告。
我们将视线从理论推演拉回工程一线,还原那些极少在论文里披露的实操细节:
顶尖团队在架构选型时,是如何向显存作出妥协的?引入新优化器时,又该如何解决跨节点的通信瓶颈?多阶段数据配比的干预时机应当如何锚定?
以及,在迈入纯强化学习的深水区时,系统要如何防范模型伪造逻辑来骗取奖励?
在算力分配上,前沿实验室确立了务实的消融实验准则:对边缘选项进行完美测试,与对核心变量进行草率测试一样,都会造成算力的严重浪费。
而在基准评估方面,单调性、低噪声、高于随机水平与排名一致性,构成了筛选可靠测试集的四个核心标尺。
架构底座与注意力机制
算力受限或追求绝对稳定时,优先采用 Dense 架构作为基底,配合 GQA 和 RoPE/RNOPE,这是目前最稳健的选择。
MoE 架构在推理端具备效率优势,但系统高度依赖全局视角的负载均衡与路由策略。衡量专家划分维度的核心指标是粒度,严格定义为 experts_per_token = total_experts / num_activated_experts。
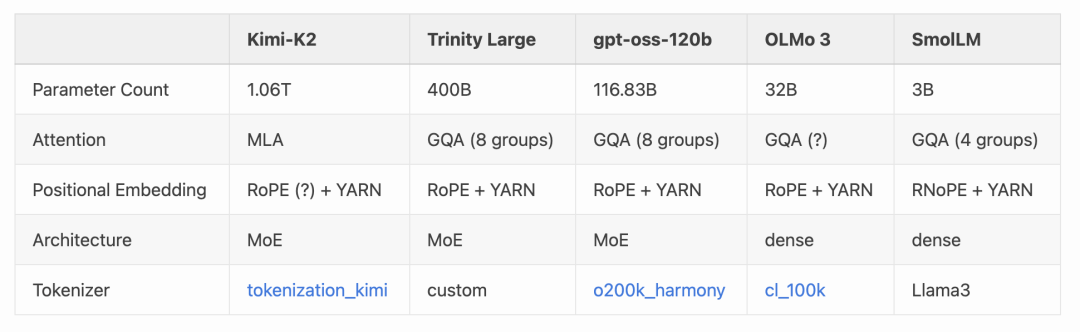
表1. 各前沿模型的架构参数概览
采用小分组(如 2、4 或 8 组)的 GQA 在相同规模下通常优于 MHA 和 MQA。MHA 会产生庞大的 KV Cache,MQA 虽靠共享 KV 值节省了显存,却不可避免地造成了注意力容量泄漏。
MLA 成功将 KV Cache 压缩 4 到 8 倍,保持与 MQA 相当性能的同时大幅缩减显存,代价则是工程实现复杂度显著增加。
门控注意力对缩放点积输出施加逐元素门控机制,有效缓解了注意力下沉现象。
门控向量计算为 g = σ(x * W_g) * W_g′,对应头的输出更新为 Attention_i(x) * g_i(x)。这一机制抑制了导致训练失稳的异常激增激活值,在处理长序列时效果明显。
序列打包极易引发跨文档注意力泄漏,文档掩码(Document Masking)成为标准的纠偏方案。这项技术在小规模短上下文任务中收益有限,但在上下文窗口从 4k 跃升至 64k 的扩展期发挥了关键作用。
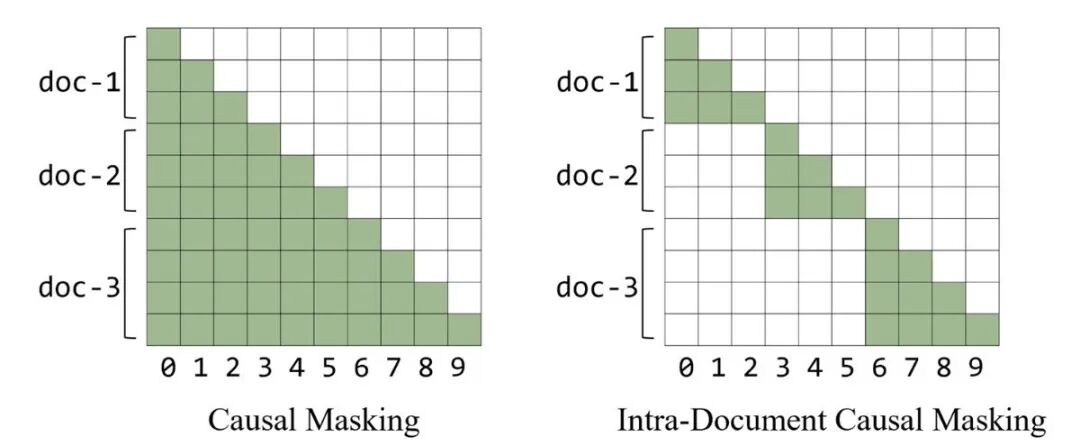
图1. Causal Masking 与 Intra-Document Masking 结构对比
输入与输出 Embedding 矩阵是否共享,深刻影响了参数分配格局。在较小规模模型中,独立 Embedding 占据了高达 20% 的参数量。
理论推演表明,高频词汇在共享权重时会同时接收双端梯度,容易主导表征学习。
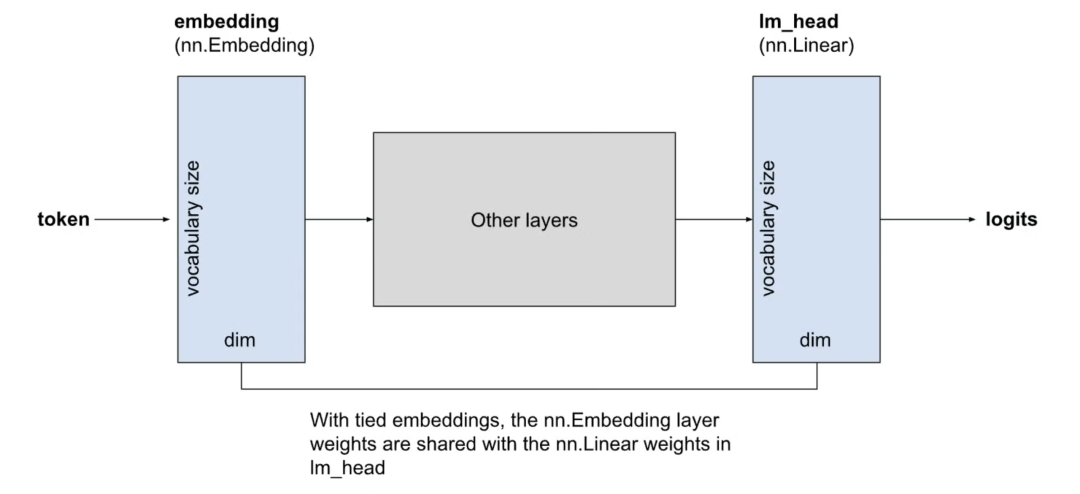
图2:Untied Embedding 与 Tied Embedding 的架构对比
Hugging Face 1.2B 模型的真实消融实验表明:权重共享在削减 18% 参数量的前提下,依然维持了极具竞争力的性能指标。
同等参数规模的非共享变体表现反而欠佳,不仅训练损失升高,下游评估指标也出现全面下滑。
长文本是对位置编码和注意力模式的严格考验。RoPE 利用旋转角度编码相对位置,公式为 (x′, x′_j) = (x_i cos(mθ_i) - x_j sin(mθ_i), x_j cos(mθ_i) + x_i sin(mθ_i))。
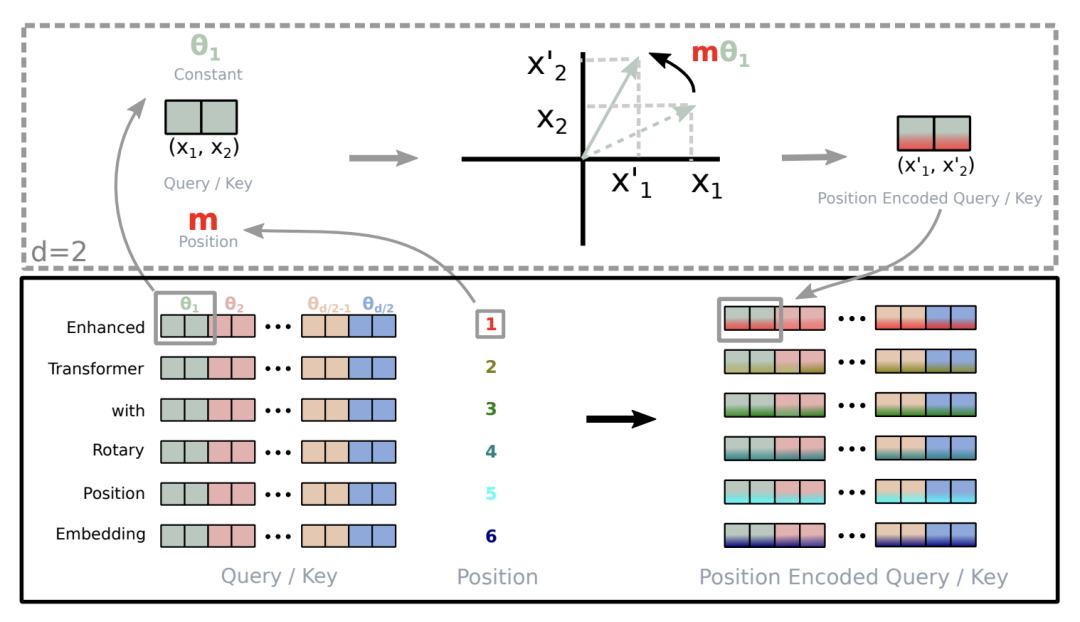
图3:RoPE 拆分 Query/Key 向量并按位置比例旋转的机制解析
序列长度一旦增加,基础频率必须同步上调。
YaRN 方案主导了超长上下文扩展,gpt-oss-120b 借此将 Dense 层的上下文延伸至 131k 词元。
RNOPE 采用交替应用 RoPE 与 NoPE 的策略,保留局部感知能力的同时,提升了长程信息检索的泛化性。
为了控制长上下文的计算复杂度,业界跑出了多种局部与全局交替的注意力变体。
滑动窗口注意力限制词元仅关注过去 w 个位置,Gemma 3 将其与全局注意力隔层交替运行。
双块注意力允许块内正常交互并对跨块查询施加相对位置上限约束,Qwen-2.5 凭借此机制支撑起百万级上下文。
局部与全局交替策略平衡了计算效率与依赖捕获,训练突发损失波动时,适时提高全局层比例能促使模型迅速回稳。
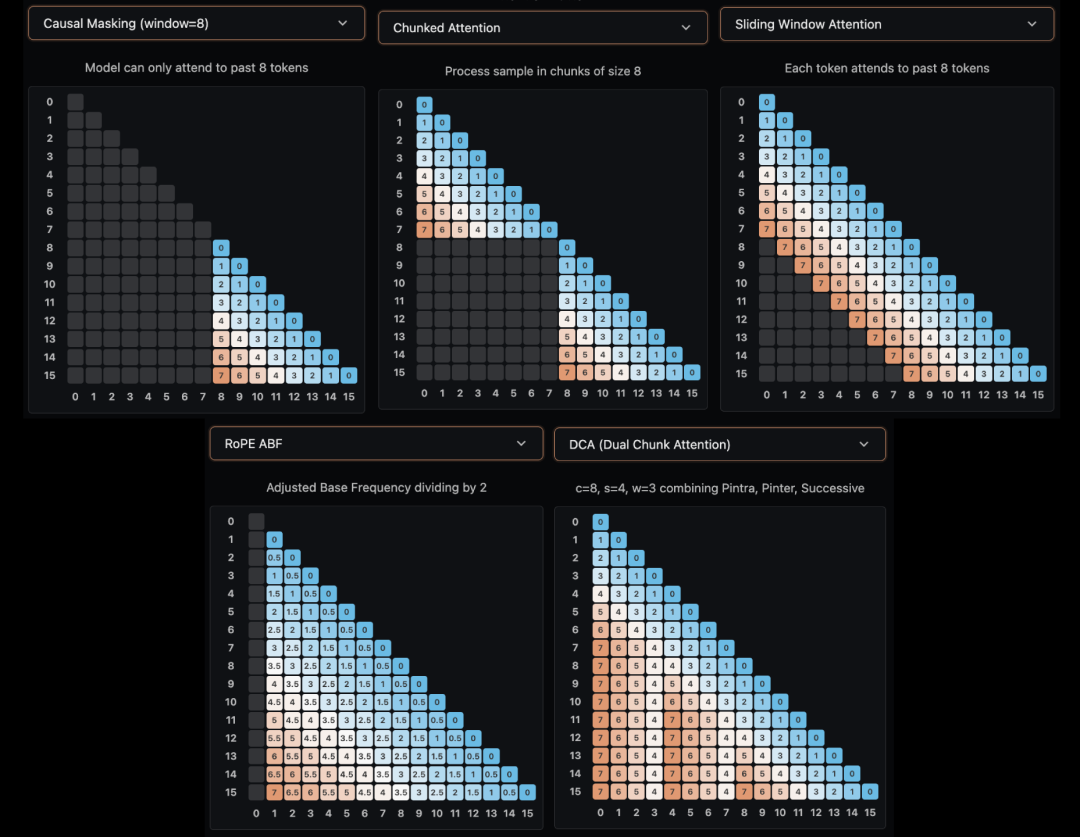
图4:五种常见的注意力机制类型对比
MoE 推理端的效率杠杆,建立在精密的路由策略与负载均衡之上。
细粒度设计在控制显存消耗的同时,提供了更灵活的路由组合空间。共享专家作为常驻组件集中处理基础且高频的表征模式,有效释放常规专家的能力,使其向垂直特征深度优化。
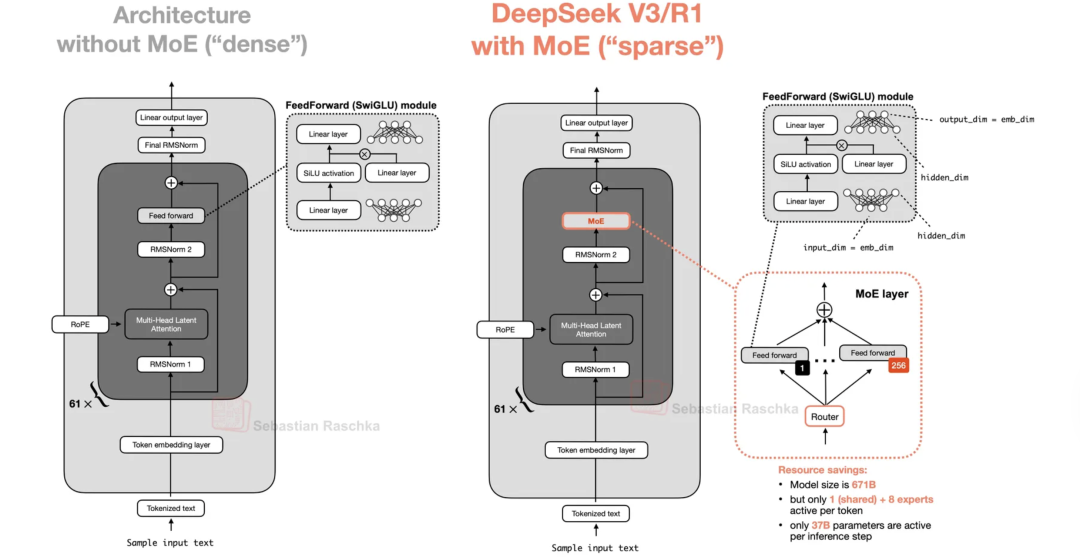
图5:Dense 架构与 MoE 架构工作流对比
负载失衡极易引发学习容量坍塌,业界演化出三条技术路线。
基于损失的负载均衡依托公式 L_balance = λ * Σ_i Σ_j r_i^j log(r_i^j / p_i^j),监控全局统计数据,促使平均路由概率 p_i^j 与实际选中比例 m_i^j(定义为 m_i^j = g_i^j / b)的乘积趋于一致。
无辅助损失方案切断干扰性梯度的注入,转而在亲和度得分上叠加偏置向量 b_i,更新规则锁定 b_i ← b_i - η * (m_i - τ_i) 并捆绑重中心化操作。
SMEBU 针对符号函数引发的步长震荡,引入软截断 f(x)=min(1, max(-1, x)) 函数计算归一化违规度量 v_i^j = f((m_i^j - τ_i) / ε)。
为实现重中心化,其偏置更新量定义为 b_i ← b_i - η * (Σ_j v_i^j)。
SMEBU 同步引入类似 SGD 的动量缓冲区,动量更新为 m_i ← β * m_i + (1-β) * v_i,平滑噪声并维稳偏置项的迭代轨迹。
赋予 Transformer 类似 RNN 的线性复杂度,已成为突破长文本瓶颈的前沿方向。其数学内核在于剥离注意力机制的 Softmax 算子,重组点积结合律:softmax((QK^T) / √d) * V ≈ (Q * (K^T * V)) / √d。
定义历史状态汇总矩阵 S_t = Σ_{τ=1}^{t} K_τ^T * V_τ,网络被重构为标准的递归状态更新形式:O_t = Q_t * S_{t-1}。
模型需要具备主动遗忘过期上下文的能力,学习门控机制 g_t 随之引入,状态更新升级为 S_t = g_t ⊙ S_{t-1} + K_t^T * V_t。
大模型压缩效率的核心逻辑往往隐藏在分词器设计里。
处理数学和代码域时,为防止模型死记硬背数字并有效提升算术模式的识别,多数方案(如 Llama3)直接采用单数字拆分 (Single-digit splitting),甚至将 1-999 直接编码为独立词元。
词表大小的权衡至关重要:超大词表(如 100k+)能更高效地压缩文本,虽然增加了 Embedding 层的参数负担,但其带来的 KV Cache 缩减与前向传播算力结余,在巨型模型中收益更为明显。
分词器的效率评估依赖两大标尺:一是词元拆分率 (Fertility),即编码一个单词耗费的平均词元数;二是连续词比例 (Proportion of continued words),即单词被强制拆分的频率,两者数值通常被控制在尽可能低的水平。
训练稳定性与优化器演进
注意力 Logit 极易在训练中异常放大。
早期的 z-loss 试图在交叉熵损失中加入 log(Σ_i exp(l_i))^2 来惩罚过大的 Softmax 分母,但 1B 规模的消融实验证明其对训练和评估均无显著收益。
主流方案全面转向 Logit Softcapping(如 Gemma 2)。系统利用平滑的 tanh 函数,将 Logit 严格限制在指定区间:l_capped = c * tanh(l / c)。
在 Gemma 2 的配置中,注意力层截断阈值设定为 50.0,最终层为 30.0。代价同样存在:该操作打破了融合核函数的标准注意力假设,导致训练阶段与 Flash Attention 底层不兼容,工程团队通常需要将训练退回 eager 模式执行。
QK-norm 曾被用来压制 Logit,但它的归一化操作直接抹除了 Query-Key 点积的幅度信息。这会导致无关词元权重异常放大,关键词元被严重削弱,从而损害模型的长文本能力。
Arcee 在 Trinity Large 中引入深度缩放的 Sandwich Norm,在注意力或 MLP 模块前后双向施加 RMSNorm。
为抵消极深网络激活值的逐层累加,后置归一化增益系数被初始化为 sqrt(0.5)。
移除 Embedding 层的权重衰减已是维稳共识。权重衰减持续压低 Embedding 范数,而在 LayerNorm 的雅可比矩阵中存在与输入范数成反比的项。
过小的 Embedding 范数会引发异常膨胀的梯度,进而影响网络浅层。去除权重衰减消除了这一隐患,系统在前向传播中直接通过 x ← x * (scale / ||x||) 缩放,将 Embedding 幅度精准锚定。
在参数初始化流派上,业界常利用 μP(最大更新参数化)来保持不同宽度下的训练动态一致,或使用 TruncDNormal(截断正态分布,通常限制在 [-a, a])来防范极端值。
网络深宽比(Width vs Height)的权衡同样残酷:同等参数下“更深”的模型在语言建模上表现更好,但大模型为了追求更快的推理速度(充分利用现代架构的并行化),往往会妥协选择“更宽”的架构。
激活函数的选型也有分歧:尽管多数前沿模型(含 gpt-oss-120b)使用 SwiGLU,但也存在 Gemma 2 使用 GeGLU,以及 Nvidia 坚持使用 relu² 的特例。
AdamW 凭借逐参数自适应学习率依然是业界标配。提升样本效率极限的任务则交给了 Muon 优化器。
Muon 将整个权重矩阵视为单一几何客体,利用 Newton-Schulz5 迭代(其核心为五阶多项式 x * (5 - 10*x^2 + x^4) / 2)逼近矩阵的符号函数,对奇异值执行正交归一化。
这一机制消除了轴向对齐偏差,大批次数据训练时收敛效率优于 AdamW。
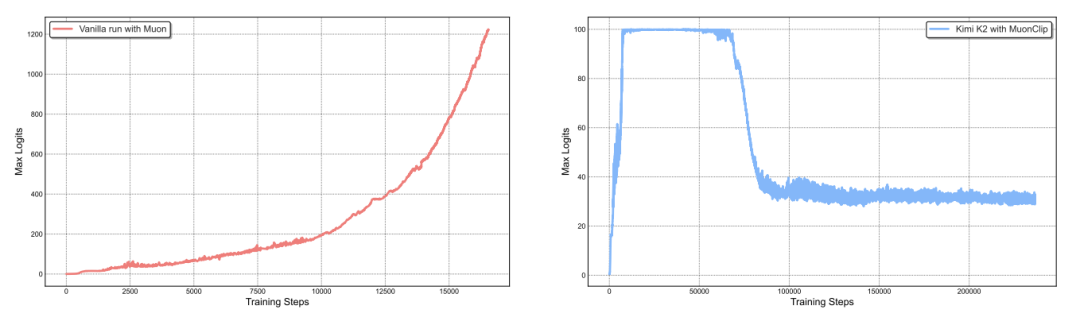
图6:MoE 训练中 Logit 发散(左)与引入 MuonClip 后的稳定曲线(右)对比
Muon 的 Newton-Schulz 迭代依赖完整的梯度张量,与 FSDP 的底层分片逻辑存在冲突。
Prime 团队引入基于 All-to-all 集体通信的批量置换策略,让每个 GPU 节点短暂接管矩阵完整梯度,集中执行 Muon 运算后再退回分片状态。
由于大量张量在内存中连续打包,工程端需要执行精细的张量填充对齐。
Arcee 实施了混合优化策略,隐藏层全面启用 Muon,Embedding 层和输出投影层则留给 AdamW 以保障稳定性。
针对 MoE 模型易发的注意力 Logit 发散,Kimi K2 提出了 MuonClip。系统设立了基于每头最大输入值的阈值 T_i。
为适配复杂的 MLA 架构,Kimi 动用单头裁剪系数 c_i = min(1, T_i / ||q_i||),精准缩放头特异性组件 q_i 和 k_i(乘数为 sqrt(c_i))与头特异性旋转位置组件 θ_i(乘数为 sqrt(c_i))。
为维持与 Adam 的 RMS 缩放行为同频,Muon 更新幅度被严格控制在 δW = -η * (∇W / (||∇W|| + ε))。
学习率调度正经历从余弦退火向 WSD 策略的转向。余弦退火周期与总训练步数深度绑定,遭遇架构或数据消融实验时,整个训练必须重新开始。
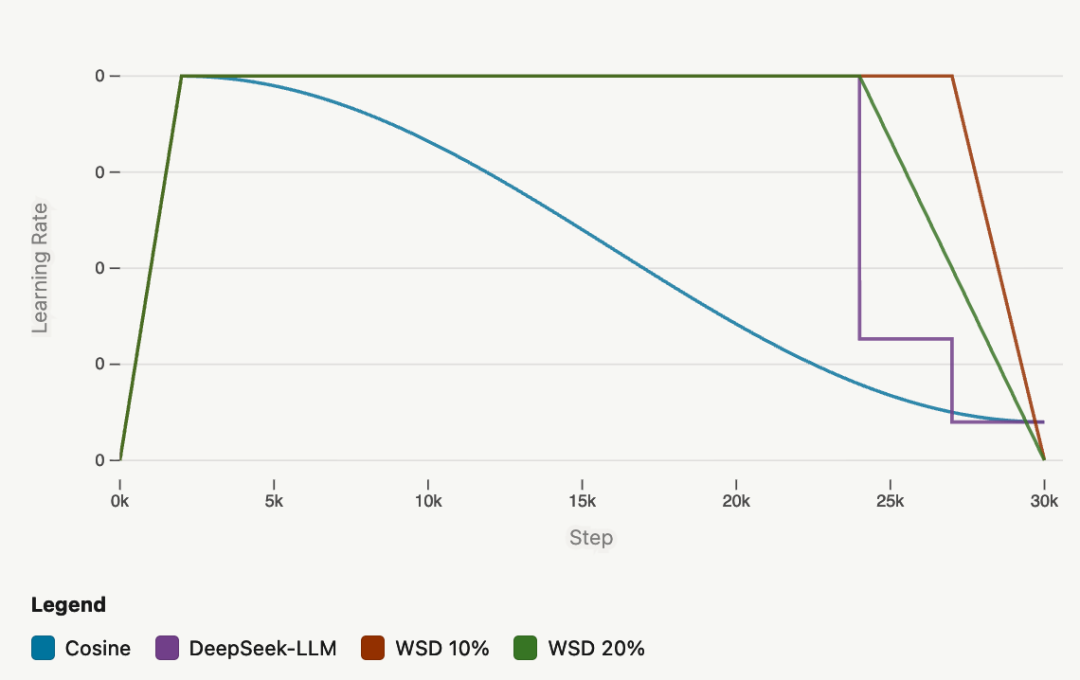
图7:三种主流学习率调度策略的退火曲线
WSD 将前 80%-90% 进程锁定在恒定高学习率平台期,仅在最后 10%-20% 进行线性衰减。
平台期内,指标数据倾向于跑不过(underperform)余弦退火;一旦切入衰减期,验证损失和评估指标会呈现出垂直跃升。这种设定允许团队在消融实验中复用平台期的 Checkpoint,仅需改变衰减期步数便能快速验证变量。
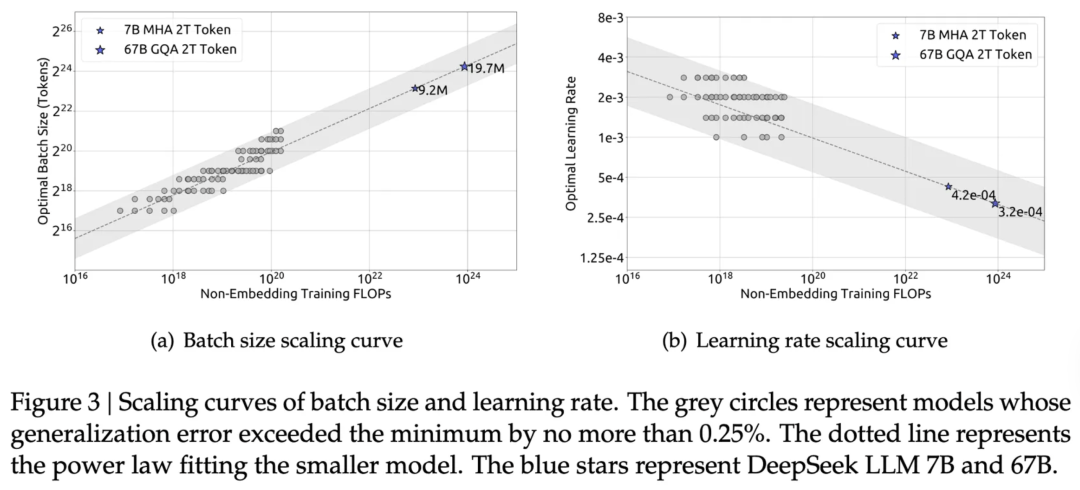
图8:批次大小与最优学习率的缩放法则拟合曲线
在衡量整体计算预算时,Scaling Laws 提供了基石公式 L(N, D) = E + A / N^α + B / D^β(其中 C 为 FLOPs,N 为参数量,D 为训练词元数)进行算力估算。
具体到微观调度,批次大小与最优学习率被数学定律 η_opt ∝ sqrt(B) 紧密耦合。批次大小扩大 k 倍,学习率必须同步放大 sqrt(k) 倍。
训练初期模型梯度范数极高,适合用小批次高频更新进行控制;步入稳定期后模型对大批次的包容度增加,实施批次预热将最大化算力利用率。
采用序列打包提升吞吐量时,容易引发批次内数据高度同质化与序列长度震荡。
Arcee 引入随机顺序文档缓冲区机制,标记化后文档被填入巨大缓冲区。系统操控随机游走的读取头跨越多个文档提取 Token 片段重组有效序列,从物理层面消除了批次内的强关联。
预训练与 Mid-training 的动态演进
架构调优的算力收益接近上限时,决定模型最终性能的关键依然是数据。构建训练集面临着严峻的权衡,过度追求高质量数据将导致样本重复利用,从而损害泛化能力。
混合策略需要融合不同质量层级数据以构建梯度分布。去重与污染检测是评估客观性的绝对底线。
OpenAI 构建 gpt-oss-120b 时,在预训练底层部署了严格的过滤机制,有效剔除生化环核等危险知识。
静态数据分布无法最大化模型的学习效率。多阶段训练秉持着明确逻辑:将最高质量、最侧重逻辑推理的数据延迟至训练末期注入,以此直接塑造模型最终的输出行为。
特定领域基准测试指标停滞,通常是注入该领域高质量数据的明确信号。干预时机与混合比例的关键决策,交由大规模模型真实消融实验裁决。
SmolLM3 运行至 7T 词元节点截取检查点,进行退火消融以评估注入新数据集的合适时机。第一阶段严格执行 75/12/10/3 切分比,分别覆盖英文网页、多语言网页、代码和数学数据。
英文语料配比中,FineWeb-Edu 与 DCLM 的混合比被固定在 60/40 或 50/50。
常规代码语料未能提升英文基准,团队将 Stack-Edu 数据延后至后期注入。向新数据平滑过渡时,基线混合物与新数据集的比例被设定为 40/60。
Token 效用衡量着单位词元对学习信号的真实贡献。
Kimi K2 针对知识语料,利用视角多样化的提示词进行重写,辅以分块自回归生成与保真度核验,主训练轮次中同一语料的重述次数严格控制在两次以内。
数学数据被系统性拆解,重组为学习笔记风格并执行跨语言翻译,以扩展表征多样性。
Hermes 4 依靠 Embedding 达成 0.7 余弦相似度完成语义清洗后,引入基于图的合成生成器 DataForge。
系统在有向无环图中进行随机游走执行结构体映射转换,利用大语言模型深度优先搜索生成子领域分类,构建出覆盖长尾数据匮乏区的全景数据集。
Mid-training 是针对性弥补领域能力短板、拉升有效上下文窗口的关键阶段。
SmolLM3 采用从 4k 稳步过渡至 32k、64k 直至 128k 的逐级攀升策略。扩展至 64k 期间,模型利用 RoPE ABF 将基础频率拔高至 2M 和 5M,过高频率会严重损害短上下文任务成绩。
向 128k 冲刺时,从 64k 检查点切换 YaRN 展现出了更为出色的性能表现。
Kimi K2 在 4k 序列完成 400B 词元训练后,切入 32k 长度继续消耗 60B 词元,最终同样通过 YaRN 突破 128k。
利用更强模型的推理词元进行特征蒸馏,成了这一阶段有效的加速手段。
Phi-4-Mini-Reasoning 利用 DeepSeek-R1 高质量推理词元进行特征蒸馏后,AIM24 成绩实现了 3 倍增长,MATH-500 提升 11 分。
能力演进必须在严苛基准体系下接受检验。
四大核心矩阵重点考察:
- GPQA Diamond 与 SimpleQA 检验专业知识;
- AIME 与 MATH-500 衡量深层数学推理;
- LiveCodeBench 及 SWE-bench Verified 检验算法能力;
- Global MMLU 测试跨语种潜能。
长文本评估涵盖 RULER、HELMET、MRCR 和 GraphWalks;指令遵循能力交由 IFEval 筛查,复杂多轮指令使用 IFBench、Multi-IF 和 MultiChallenge。
对齐与主观评估依靠 LLM-as-judge 的 AlpacaEval 和 MixEval。复杂工具调用交由 TAU-Bench 承接,并使用 GSMPlus 等扰动测试防范过拟合。
后训练范式跃迁:SFT与RL算法的深度交汇
SFT 构筑了模型行为规范的基线。数据打包环节,Hermes 4 采用首次适应递减算法进行序列打包,实现了超过 99.9% 的批次效率。
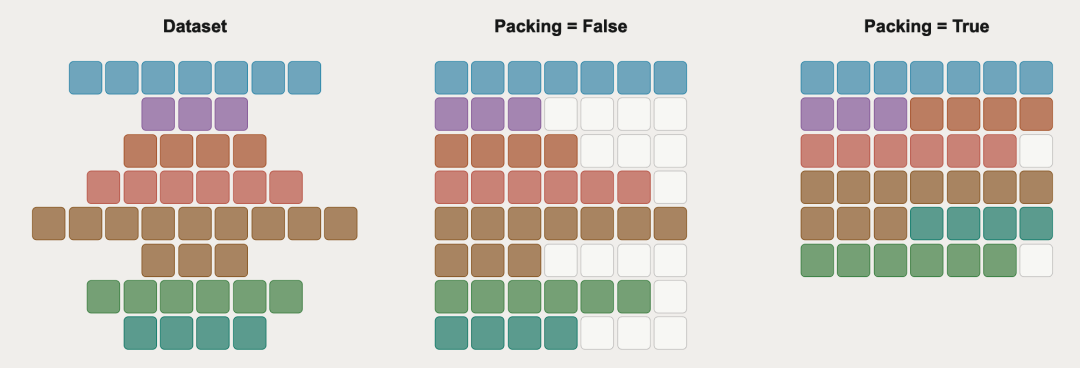
图9:Sequence Packing 在批次内存块利用率上的对比
数据打包(Packing)能显著提升吞吐量,但会改变原本的训练节奏。特别是数据量偏小时,有效批次大小拉大到 128 时,IFEval 指标会下降 10%;超过 32 时便会出现平均性能的衰减。
SFT 阶段的学习率必须控制,SmolLM3 采用比预训练小 20 倍的配置 (1e-6) 以平衡思考与非思考模式。
面对超大词表,Cute Cross-Entropy (CCE) 内核成为显存优化的有效工具,它不在全局内存中实例化完整的 Logit 矩阵,仅计算正确词元的 Logit。
SonicMoE 等专用内核则实现了更高效的计算利用率。多轮训练的收益依然明确,LiveCodeBench v4 成绩在迈入第三轮时实现了显著提升。
偏好优化 (PO) 凭借少量数据突破模仿学习的上限。
ORPO 将优势率整合进交叉熵损失,免除了参考模型的计算开销。
APO-zero 提升正样本概率并压制负样本,在分布外泛化测试中表现最优;遭遇劣质正样本时,APO-down 会同步下调正负样本概率。
KTO 摒弃了成对比较,仅凭单一输出的期望标签与参考点进行更新。
正则化系数的设定需要谨慎,数值过大将抹除 SFT 积累的能力;如果将数据集扩展至 10 万对以上,长链条思考能力通常会出现明显衰退。
蒙特卡洛树搜索曾被应用于测试时计算。词元生成空间的指数级膨胀,让最大扩展限制容易诱发局部最优陷阱,细粒度价值模型的训练面临挑战。
过程奖励模型同样存在局限:通用推理边界模糊,绝对难度难以定义,模型容易学会伪造空壳逻辑框架来骗取奖励。
PPO 的逐词元 KL 惩罚机制对长链条响应产生了隐性压制,阻碍了多步逻辑推演的展开。
GRPO 借此成为推理任务的优选方案,在 MATH 评估中表现优于 PPO。
混合推理模型在 RL 阶段容易通过拉长思维链来获取奖励,因此引入严格的长度惩罚机制成为必要。
通过设定软硬双重阈值参数化惩罚机制,一旦跨越硬阈值,系统直接施加 -1 惩罚(收益清零)。
SmolLM3 将惩罚区间严格控制在 2.5k 至 3k 词元,在这场性能与长度的权衡中保持了稳定。
Kimi K2 从其前代 K1.5 继承了核心的强化学习目标函数,引入了类似 KL 散度的正则化项以保障学习的稳定性:L_RL = E[R(y)] - β * KL[π_θ(y|x) || π_ref(y|x)]。
此外,为了防止模型在强化学习中发生灾难性遗忘,系统引入了高质量样本的 PTX(预训练交叉熵)损失。
同时,Kimi K2 专门构建了自我批判机制,Critic 模型融合多重特征对 Actor 生成轨迹执行客观的成对排序与打分。
在平衡探索与利用方面,温度衰减(Temperature decay)机制至关重要。训练初期采用高温度以生成多样化响应并跳出局部最优,后期则按计划衰减温度,以保障模型输出的可靠性与一致性。
DeepSeek-R1-Zero 展现了无 SFT 冷启动的纯 RL 潜力,其核心密码在于极其稳定的超参设定:运行 10.4k 步,批次大小设为 512,每 400 步替换一次参考策略,学习率保持 3e-6,且 KL 系数设定为 0.001。
为了解决纯 RL 带来的可读性下降问题,DeepSeek-R1 引入了格式规范,要求“在每个回答末尾包含一个摘要 (summary at the end of each response)”。
在推理模型的工程实践中,DeepSeek 团队还总结了两个关键的微观现象。
首先是第一人称视角的演进:纯粹 RL 训练的 DeepSeek-R1-Zero 本能地倾向于使用“我们 (we)”,而在少量长 CoT 数据微调后,最终版本的 DeepSeek-R1 转向使用“我 (I)”。
这被证明更符合人类第一人称直觉思考模式,使得推理过程更为连贯。
其次是贪婪解码陷阱:长输出推理模型遭遇贪婪解码时,重复率上升且缺乏稳定性。其内核在于,模型在学习难度压力下会本能地规避风险,并在时间序列相关错误的偏置引导下,在决策点倾向于退守过往动作,最终陷入循环。
构建真实的 RL 环境是一项高门槛的技术挑战。
Prime 团队依托开源 prime-rl 框架,为 Intellect 3 部署了复杂的验证环境:
- 针对软件工程,引入支持 R2E-Gym、SWE-smith 的脚手架环境,赋予模型 Bash 命令权限直接编辑 GitHub 项目(最高允许 200 轮交互);
- 针对深度研究能力,切入 Web 搜索环境进行轨迹生成。
Kimi K2 为规模化模拟工具调用,基于 ACEBench 收集了 3000 多个真实 MCP 工具,分层生成了 2 万个合成工具,在无需真实环境的条件下成功构建了工具调用流程。
格式遵循方面,Nous 动用 Atropos 验证器,确保 Hermes 4 在 LaTeX 框内正确输出答案,并对 JSON Schema 遵循度执行严格校验。
Pipeline RL 采用运行中权重更新技术,允许系统在生成环节直接使用最新迭代的策略权重。
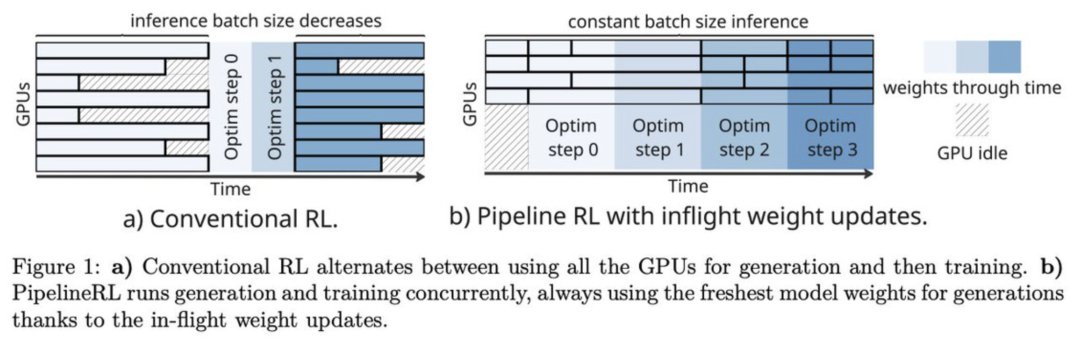
图10:常规 RL 与支持 In-flight 权重更新的 Pipeline RL 对比
对抗离策略偏差,IcePop 构建了带有重要性采样权重 w = π_train(y_i, t|x, y_i;θ) / π_infer(y_i, t|x, y_i;θ_old) 的完整目标函数:J_IcePop(θ) = E_x~D;{y_i}i=1^N~π_infer [1/Σ_i=1^N |y_i| Σ_i=1^N Σ_t=1^|y_i| [M(w;α,βÂ)]]。
系统通过引入重要性采样截断,将重要性权重严格限制在指定的 [α, β] 区间内(通常为 [0.1, 10])。
这种非对称的截断区间在罕见的高熵词元出现时,能够有效保护学习动态,保障了 MoE 训练的平稳运行。
同策略蒸馏提供了一条高性价比的迁移路径,仅对单一采样轨迹请求教师模型打分,运行成本大幅下降。该手段在高效迁移教师能力的同时,有效缓解了模型吸收新知识时的灾难性遗忘。

表2:DeepSeek-R1 蒸馏模型推理基准测试

表3:后训练强化学习算法选择矩阵
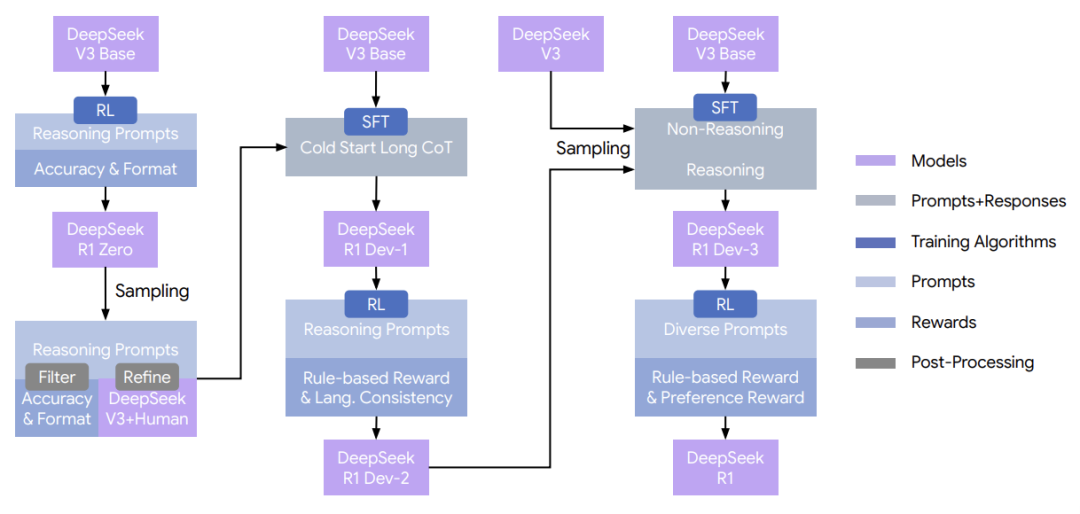
图11:DeepSeek-R1 的多阶段训练流水线结构图
行为对齐与工程实战
模型微观行为的变化,有时仅源于聊天模板中字符的调整。
Nous 团队将 Llama 3 模板中的 assistant 标识符替换为 me 后,Hermes 4 开始展现出明显的第一人称人格特征,机械的元免责声明输出相应减少。
面对虚构提示词,Hermes 4 能够开启角色扮演,在维持设定的同时生成连贯响应。
经过评估,Hermes 4 的拒绝率保持在较低水平,而受限于严格安全策略的 gpt-oss-120b 拒绝率最高。
应用反过度谄媚提示词后,模型的思维链轨迹发生偏移,它会主动尝试引导交互脱离纯粹的推理正轨,甚至混入情感化表达。
OpenAI 启动 Preparedness 评估框架,全面测试模型能力边界。安全团队构建大学级别网络攻防测试,引入生物风险数据进行对抗性微调,评估复现前沿 AI 研究的潜在风险。
StrongReject 数据集被直接植入安全拒绝评估流水线。指令层级防御确立了严格的优先级:system > developer > user > assistant > tool。
将模型置于指令冲突的测试环境中,gpt-oss-120b 战绩落后于 o4-mini。
对于深层推理模型,幻觉率被重新定义,接纳了“我不知道”等边界情况,九个社会维度的偏见也被纳入核心检验指标。
启动大规模训练前,硬件压力测试与 S3 检查点自动卸载机制必须就位,这是保障存储空间与集群正常运行的关键防线。
Hugging Face 训练 SmolLM3 时遭遇吞吐量从 14k 骤降至 8k tokens/sec/GPU。
网络附加存储的“热保持”缓存驱逐机制在面临 24TB 数据时达到极限,发生海量数据缓存驱逐,导致严重的 I/O 停滞。
小幅吞吐量衰减问题持续存在,追踪发现 Nanotron 数据加载器维护的查找表无限制增长,内存分配失败频发,缺页中断增加。切换至 Tokenizedbytes 数据加载器后,吞吐量问题得以解决。
数据加载器仅按文档顺序连续读取,缺乏离线洗牌机制,会导致批次数据分布严重失衡。同质化梯度回传容易引发损失函数的剧烈波动。离线洗牌重组 Token 序列成了兼顾随机性与读取速度的有效方案。
SmolLM3 权重跨两张 GPU 执行张量并行时,却被初始化了相同的随机种子。并行网络产出高度同质化的激活值与梯度,特征多样性丧失,收敛能力受到严重影响。
vLLM 的多节点数据并行服务暴露出瓶颈:节点数量增加时,吞吐量容易停滞,共享队列成为系统瓶颈。
团队重构架构,抽象出多客户端编排器,每个推理节点被部署为独立服务器,管理专属 vLLM 引擎和 KV Cache。编排器采用轮询机制,将生成请求分发至各个独立客户端,成功打破了吞吐量限制。
OLMo2 的经验表明:n_layers / sqrt(d_model) 的缩放初始化能显著提升启动阶段的存活率。
对包含 32 次以上 1-13 个 Token 跨度重复的劣质文档进行严格过滤,是压制损失尖峰的有效手段。尖峰突发时,跳过问题批次或适度收紧梯度裁剪阈值,能够保障系统持续运转。
结语
从基础架构的颗粒度调整到大规模集群的工程实现,前沿模型的突破建立在无数次严谨的消融实验之上。
无论是复杂的负载均衡博弈,还是强化学习验证法则的探索,这些确立的方法论为人工智能的规模化路线提供了清晰且扎实的技术参考。对这类工程实践的深度复盘,正是云栈社区这样的技术社区所关注和探讨的核心。
参考文献
[1] Alex Wa. (2026). Frontier model training methodologies. https://djdumpling.github.io/2026/01/31/frontier_training.html
 发表于 2026-2-25 08:48:01
|
查看: 173|
回复: 0
发表于 2026-2-25 08:48:01
|
查看: 173|
回复: 0
