来源 | 量子位
为什么现有上下文压缩方法在高压缩率下集体“翻车”?当模型把32K长文本压到1K,为何性能会断崖式下跌?
长文本压缩中容易保留大量“高度相似却重复”的内容,陷入“信息内卷”:看似保留了相关片段,实则堆砌了语义雷同的冗余token,反而会误导模型生成错误答案。
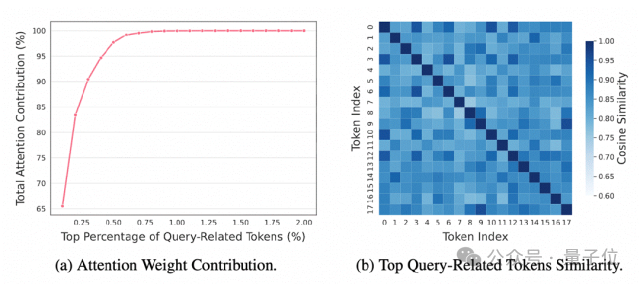
来自阿里巴巴未来生活实验室的研究团队发现,这背后是压缩目标的根本错位:现有方法只关注“相关性”,却忽略了“多样性”。当多个高度相似的token同时被保留,它们非但不能叠加信息量,反而会相互干扰(相关不等于正确),让模型在高度相似的冗余信息中迷失方向。
为破解这一困局,研究团队提出一个颠覆性观点:高质量的压缩,需要同时优化“与查询的相关性”和“信息单元间的多样性”。基于此,他们推出创新框架COMI(COarse-to-fine context compression via Marginal Information Gain),通过“边际信息增益”指标与粗到细压缩策略,在32倍高压缩率下仍能精准保留多样化的关键证据链。这项研究已被ICLR 2026接收。
压缩的“智能标尺”:边际信息增益(MIG)
研究团队发现,现有压缩方法存在一个盲区:过度依赖相关性会导致冗余堆积,而忽略了token间语义相似性引发的“信息内卷”。为此,他们引入了边际信息增益(MIG) 指标,将压缩决策从“单维度相关性”升级为“相关性-冗余性”的双维度权衡:
MIG = 本单元与查询的相关性 - 与其他单元的最大相似度
这个指标就像为每个token配备了一张“信息价值计分卡”:它既奖励与问题高度相关的片段,又惩罚与已选内容高度重复的片段。通过MIG,压缩过程能更智能地筛选出真正独特且关键的信息。
粗到细自适应压缩,让每比特都“物有所值”
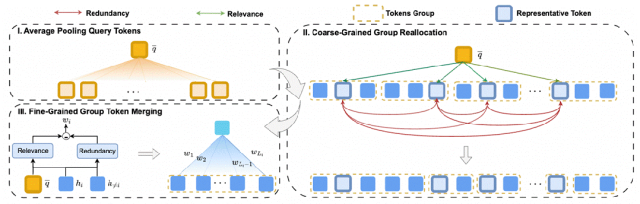
有了智能标尺,如何实现精准压缩?COMI采用了一种两阶段策略,犹如经验丰富的编辑“先谋篇布局,再精雕细琢”:
第一阶段:粗粒度组重分配——动态调配“压缩预算”
COMI先将长文本划分为等长片段。与传统均匀压缩不同,它会基于各组间的MIG值动态调整每个片段的压缩率:信息密度高、冗余度低的片段(例如包含关键证据的段落)会获得更宽松的压缩预算;而信息稀疏或高度重复的区域则会被大幅压缩。这种自适应的预算分配,确保了有限的压缩资源能精准投向“高价值信息区”。
第二阶段:细粒度令牌融合——加权融合避免“信息稀释”
在每个片段内部,COMI会根据令牌级别的MIG进行加权融合。高MIG的令牌(相关且独特)在融合中占据主导权重,而低MIG的令牌(冗余重复)则会被自然稀释。这一机制有效避免了传统平均池化可能导致的“关键细节被平滑掉”的问题,使得压缩后的表示既紧凑又富含多样化的信息。
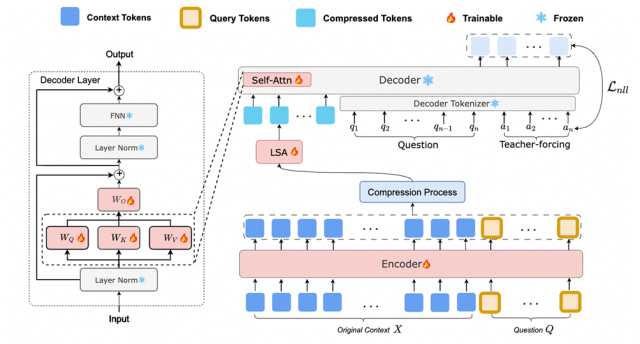
整个框架设计高效,在NaturalQuestions、HotpotQA等五个常见长文本数据集上仅需单次训练,即可适配问答、摘要等多种长上下文任务。
实践出真知:高压缩率下的优越性能与深刻洞察
下游任务表现卓越
在严格的32倍压缩约束下,以Qwen2-7B为基座模型,COMI在NaturalQuestions数据集上取得了49.15的Exact Match(EM)分数,比次优基线方法高出近25个点。即使面对上下文长度高达32K的NarrativeQA数据集,COMI依然能够稳定保留推理链中的关键节点,证明了其在极端压缩场景下的强大鲁棒性。
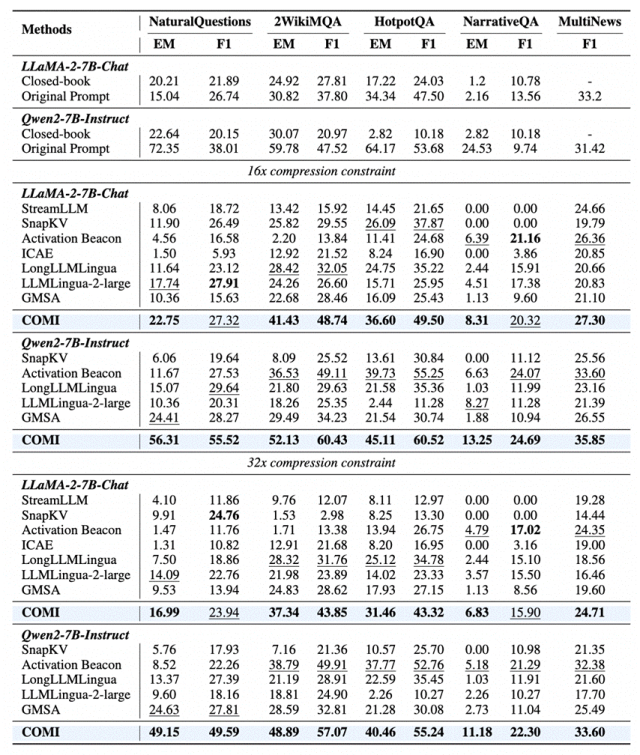
压缩不是“删减”,而是“信息提纯”
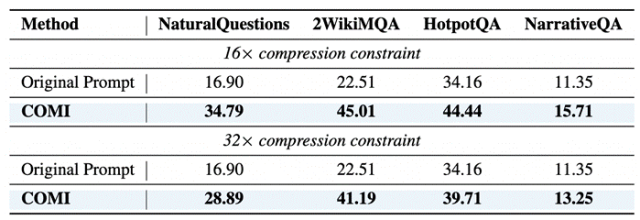
一个反直觉的发现是,COMI甚至能提升原生支持超长上下文模型的性能。例如,对于原生支持256K上下文的Qwen3-4B模型,在NaturalQuestions任务上,经过COMI进行32倍压缩后的输入,反而取得了28.89的F1分数,远超直接输入完整上下文(16.90)。这有力地证明,高质量的压缩不仅仅是“减负”,更是通过消除冗余干扰来实现“信息提纯”,帮助模型更聚焦于核心证据。
效率与效果兼得
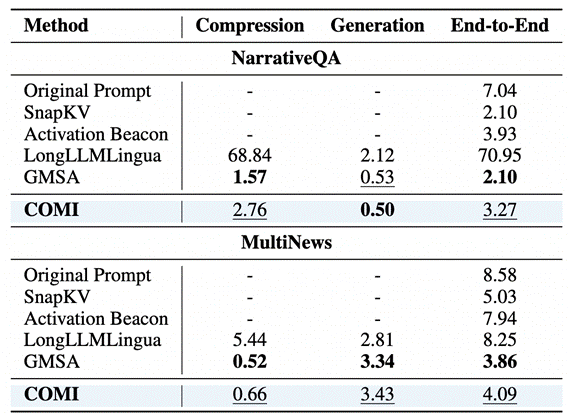
在实现高性能的同时,COMI也兼顾了效率。在32倍压缩设置下,其端到端的推理速度可获得2倍以上的提升。压缩阶段仅引入轻量级开销,例如在NarrativeQA任务中,压缩耗时约2.76秒,而生成答案仅需0.50秒,为实际的工业级部署铺平了道路。
总结
COMI这项工作为长上下文的高效推理提供了一个新的范式。它通过“边际信息增益”这一简洁而深刻的指标,将压缩的核心目标从“保留相关片段”升级为“保留相关且多样化的信息”,从而从根源上破解了高压缩率下的性能瓶颈。其粗到细的自适应压缩策略,则确保了整个过程既能把握全局信息分布,又能保留局部的语义细节。
这项研究揭示,真正的高质量压缩绝非简单的“删减”——它关乎如何让每一比特都承载最大化的、多样化的信息价值。这对于推动大模型走向轻量化与实用化,无疑是关键的一步。
论文信息
对自然语言处理前沿技术与应用感兴趣的开发者,欢迎在云栈社区交流探讨。
 发表于 2026-2-25 08:51:56
|
查看: 157|
回复: 0
发表于 2026-2-25 08:51:56
|
查看: 157|
回复: 0
