上一篇文章中我们提出了缓存行(Cache Line)的概念,那么这些缓存行在CPU缓存内部是如何组织和管理的呢?这正是本文要探讨的核心——CPU缓存的组织形式。
缓存行的基本结构
在深入探讨组织形式之前,我们先明确一个缓存行的基本构成。一个典型的缓存行包含以下几个部分:
- Tag(标签):用于标识该缓存行数据来自主内存(SDRAM)中的哪个地址区块。
- Valid Bit(有效位):标识该缓存行中的数据是否有效。
- Dirty Bit(脏位):标识该缓存行中的数据是否被修改过,与主内存不一致。
- Data(数据):实际存储的数据块。
为了更好地理解,可以参考下面的缓存行格式示意图:

假设内存地址为32位,每个缓存行大小为64字节,那么地址中用于在行内定位具体字节的偏移量(Offset)就需要6位(2^6=64)。剩下的高26位地址就用作Tag。当CPU需要访问数据时,它利用地址的一部分(后面会详细说明)找到可能存放目标数据的缓存行,然后比对Tag。若匹配且有效位为真,则命中缓存。
三种主流的缓存组织形式
既然缓存行需要被快速查找,它们是如何在有限的缓存空间里摆放的呢?如果摆放完全无序,那么每次查找都需要与所有缓存行的Tag进行比较。这种“满大街找”的方式在硬件上可以通过内容可寻址存储器(CAM)实现,但它需要大量并行的比较器电路,导致芯片面积大、功耗高,并不高效。
因此,现代CPU缓存普遍采用有规则的摆放方式,主要分为三种:全相联(Fully Associative)、直接相联(Direct Mapped)和组相联(Set Associative)。
全相联(Fully Associative)
这是最“自由”的一种形式。主内存中的任意一个数据块可以被放置到缓存中的任意一个空闲行里。正如前文所述,其优点是空间利用率高、冲突概率最低,但缺点也显而易见:查找时需要比对所有行的Tag,硬件成本(比较器数量)和功耗都极高。因此,全相联缓存通常只用于容量非常小的特殊缓存(如TLB)。
直接相联(Direct Mapped)
为了降低硬件复杂度,直接相联缓存引入了一个严格的映射规则。我们可以把主内存想象成被分割成若干个大小相等的“区”,缓存也被分成同样数量的“组”。一个内存数据块只能被放入缓存中唯一对应的那个组里。
让我们通过一个示意图来理解。假设内存被分成4个区(或称为4个Set),每个区有4个块。缓存大小正好是4行。那么,来自内存“红色区”的块,只能放入缓存的“红色行”。
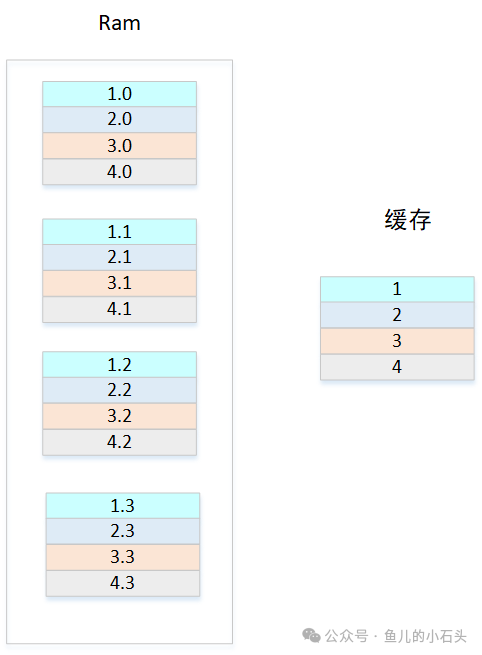
在这种架构下,一个完整的内存地址被划分成三个部分:
- Tag:高位地址,用于在确定的组内唯一标识数据块。
- Index(索引):中间若干位,用于选择缓存中的哪一个组(Set)。
- Offset(偏移):低位地址,用于在缓存行内定位具体字节。
查找过程简化为:先用Index直接定位到唯一的缓存行,然后只需比较该行的Tag即可。这极大地减少了比较器的数量。
但是,直接相联的缺点也很明显——冲突频繁。回到上图,对于缓存的“行1”而言,它只能对应内存中“红色区”的块。如果程序连续访问红色区的1.0、1.1、1.2、1.3这几个块,它们会争抢同一个缓存行,导致频繁的替换(抖动),严重降低命中率。
组相联(Set Associative)
如何既保留直接相联的简单性,又减少冲突呢?答案就是增加“路”(Way)数,形成组相联缓存,这也是目前最主流的组织形式。
我们为每个组(Set)增加一个存储位置,变成多路。继续上面的例子,现在每个Set有2路(Way0 和 Way1)。来自内存“红色区”的块,现在可以放入Set0的Way0或者Way1中,有了两个选择。
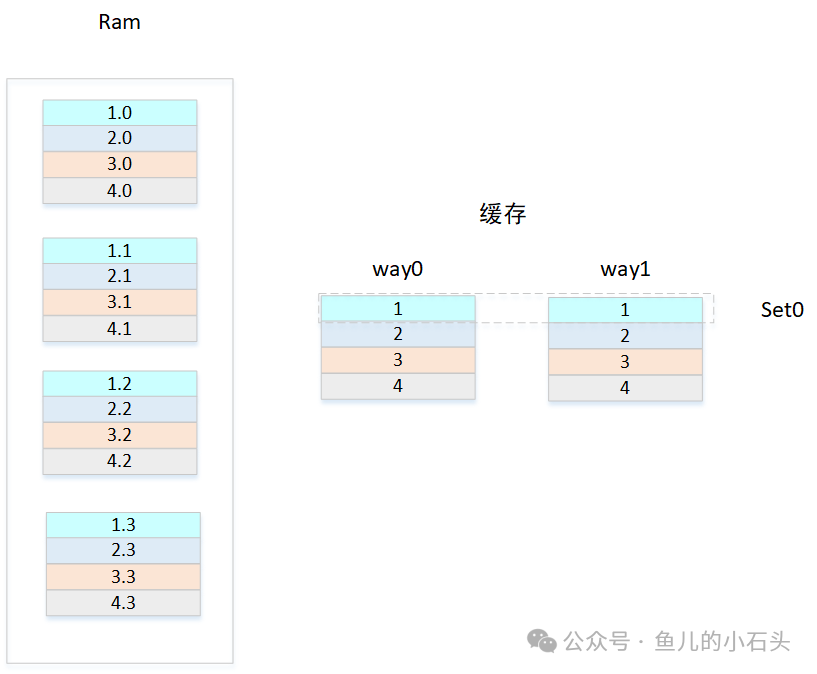
如图所示:
- 组(Set):由Index索引的水平方向单元,决定了内存地址的“分区”数量。
- 路(Way):垂直方向并列的存储体,决定了每个组内可以缓存多少个来自同分区的不同数据块。
组数 = 缓存总大小 / (Way数 × 缓存行大小)。
组相联的工作过程是怎样的呢?
- CPU给出内存地址,首先根据Index位找到对应的组(Set)。
- 并行读取该组内所有路(Way)的Tag。
- 将读取到的Tags与地址中的Tag进行比较。
- 若有匹配(命中),则将该路(Way)对应的Data读出,再根据Offset选取具体字节。
可以看到,Way的数量越多,同一分区数据的缓存能力越强,冲突概率越低,缓存性能越好,但代价是需要更多的比较器和存储电路,成本、功耗和延迟也会相应增加。因此,Way数(如2路、4路、8路、16路)是CPU缓存设计中的一个重要权衡。
性能优化:Tag与Data的访问策略
在组相联缓存中,每次访问都需要先读Tag进行比对,再读Data。这两步可以串行进行,但会增加访问延迟。一个常见的优化策略是预测性并行访问:在读取Tag阵列的同时,根据某种预测策略(如上次命中的Way)提前打开一个Data阵列。如果Tag比对命中,预测的Data可以直接使用;如果预测失败,再读取正确的Data阵列。这需要增加额外的预测电路,但可以有效降低平均访问延迟。
理解CPU缓存的组织形式,是深入理解计算机系统性能优化的基础。如果你想系统性地学习更多计算机底层知识,可以探索我们整理的相关计算机体系结构资料。也欢迎来到云栈社区,与更多开发者交流讨论这些硬核技术细节。
 发表于 2026-1-21 02:10:58
|
查看: 201|
回复: 0
发表于 2026-1-21 02:10:58
|
查看: 201|
回复: 0
