如果你也一拿到需求就想写代码,这篇能帮你省下50%的返工时间。
我们接着讨论答题系统的案例。想象一下这样一个场景:产品经理指着需求文档说用户得能刷题、能模考、能看错题,而开发同学直接就想接口那做个 /submitAnswer。从功能列表直接跳到接口定义,这中间跳过了最重要的一步——建立共识。结果呢?评审会上,前端、后端、测试对一道题的理解完全不同,吵了俩小时。这表面上是沟通问题,本质上其实是方法问题。
今天,我们就用这个答题系统的真实案例,复盘从模糊需求到清晰领域模型的核心三步。目的不是画一张漂亮的类图,而是在写第一行代码前,让所有人对业务到底在发生什么达成一致。
到底在吵什么?
表面上看,我们争论的是技术实现细节。比如,简答题的答案该怎么存?用 TEXT 还是单独拆表?但实际上,争吵的根源是我们对业务概念的认知完全不同:
- 前端同学眼里的答题是:用户点选项 → 点提交 → 跳转下一页。
- 后端同学眼里的答题是:接收请求 → 校验答案 → 计算分数 → 更新数据库。
- 产品同学眼里的答题是:用户学习过程中的一个反馈环节,最终要能分析他的薄弱点。
- 测试同学眼里的答题是:一个能造出各种异常数据(空答案、超时提交)的流程。
如果不在同一个概念模型里对话,后续的设计、开发和测试,注定是鸡同鸭讲。
为什么需要领域模型?
很多团队拿到需求后一上来就画 ER 图(数据表关系图),这相当于直接画地下管线的施工图,却没人知道整栋楼长什么样、住着谁、要干什么。
领域模型(Domain Model)就是那张建筑蓝图。它不关心 MySQL 用 varchar(255) 还是 text,它只回答一个核心问题:在这个业务世界里,有哪些关键角色和物件,它们之间如何互动,来达成业务目标?
一句话说明:ER 图描述数据怎么存,领域模型描述业务怎么跑。先搞清楚业务怎么跑,才能知道数据该怎么存。
从模糊需求到清晰模型:四步实战法
下面,我们就用一个实战可复用的四步法,把那份答题系统的需求,变成一张团队共享的蓝图。
第一步:全局概览,圈定边界
千万别一头扎进细节。首先应该问:系统为谁服务?解决他们的什么核心问题?
快速扫描一遍需求,核心角色就两个:考生 和 管理员。他们的核心目标(用例)很清晰:
- 考生:我要练习、我要模考、我要看我的学习进度。
- 管理员:我要管理题库、我要批阅主观题、我要看数据统计。
这一步的输出:一张高阶用例图(哪怕只是在白板上画两个圈)。目的是让所有人对齐——我们这个系统,主要就伺候好这两类人,干好这几件事。
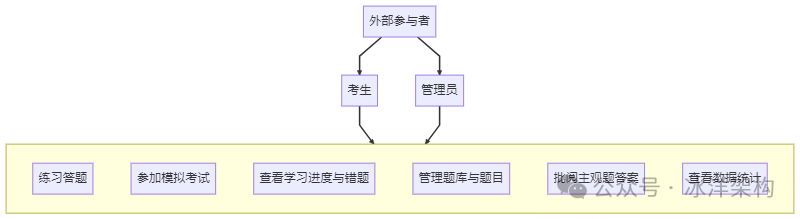
(框里的就是系统的核心边界,之外的(比如支付买课)本次迭代先不管)
第二步:找出业务名词,识别核心实体
这是面向对象分析(OOA)的关键一步。把需求文档当课文,划出所有重要的名词。这些名词很可能就是你的核心领域对象。
我们快速过一下需求,会看到这些高频且关键的名词:
- 题库(支持初级/中级/高级)
- 题目(单选、多选、判断、简答、论文)
- 试卷(模拟考试生成的)
- 答案(用户提交的)
- 批阅(管理员对主观题的评分)
- 用户 和 他的学习进度(错题本、收藏夹、学习日历)
到这一步,可以组织团队一起在白板上把这些名词写出来。你会发现,大家对“题库”和“试卷”是不是一个东西可能就有分歧,正好提前解决。
第三步:理清关系,构建静态骨架
名词有了,那它们之间是什么关系呢?用自然语言把这些关系描述出来,这就是领域逻辑。
带着团队一起讨论,我们可以得出这样的共识:
- 一个题库(如“软考中级软件设计师”)包含多个章节,一个章节又包含多道题目。
- 一张试卷(一次模拟考)由从题库中选出的多道题目组成。
- 一个用户可以做多次练习(产生答题记录)和参加多次模拟考试(产生试卷和成绩)。
- 一次答题(无论是练习还是考试)针对一道题目,产生一个答案记录。
- 如果是主观题答案,可以被一位管理员批阅,产生一条批阅记录(含分数和评语)。
- 用户有自己的学习进度,这聚合了他的所有错题、收藏。
把这些关系用最朴素的连线画出来,领域模型的静态结构(类图雏形)就有了。它的价值不在于多规范,而在于它记录了团队的集体共识。
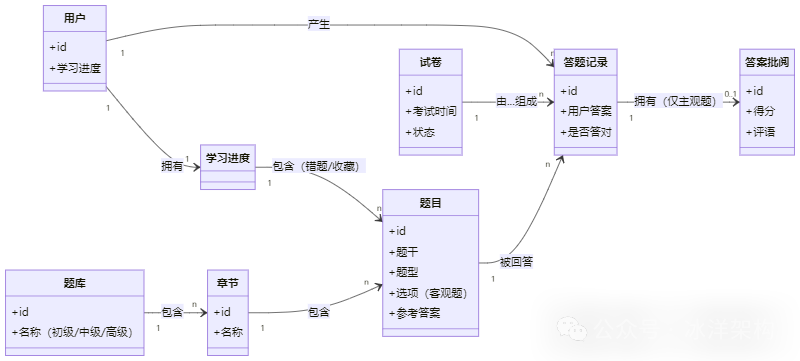
(这张图不包含任何数据库字段,只表达业务概念和关系。注意 答题记录 是连接用户、题目、试卷的核心纽带,这是建模的关键洞察。)
第四步:动态推演,验证模型是否跑得通
静态结构画得再美,也得能跑通业务。选一个最核心的业务流,用你们的模型演一遍。
比如,模拟考生完成一次模拟考试的完整流程:
- 用户发起模考请求。
- 系统按规则组卷,创建一张试卷,并关联多道题目。
- 用户答题,每答一题,就创建一条答题记录,关联用户、试卷和具体的题目,并记录用户答案。
- 如果是客观题,系统当场对比参考答案,更新
答题记录.是否答对 字段。
- 如果是主观题,答题记录先标记为“待批阅”。
- 考试结束,试卷状态变为“已完成”,可以计算客观题总分。
- 后续,管理员在后台看到待批阅的答题记录,进行批阅,创建答案批阅记录并关联到该条答题记录。
- 最终,用户的学习进度中,会自动聚合本次考试的所有错题(通过查询
答题记录 中 是否答错=true 的记录)。
演完你会发现:原来错题本并不需要一个独立的 t_wrong_question 表,它只是从 答题记录 里按条件(用户ID + 是否答错)查询出来的一个视图!这个关键发现可能直接简化了你的数据库设计。
从模型洞察到技术决策
通过上面的推演过程,清晰的领域模型已经开始指导具体的技术决策了:
- 答题的抽象:我们意识到,无论是练习还是模考,核心事件都是“答题”。因此,答题记录 这个模型将成为核心,其上的“试卷”和“练习”只是不同的上下文。这为后续设计统一的答题服务接口提供了坚实依据。
- 主观题处理的明确:主观题批阅是一个独立的、异步的流程,涉及管理员角色。答案批阅 作为一个明确的模型被识别出来,而不是简单作为答题记录的几个字段。这暗示了后台需要独立的批阅功能模块和消息通知机制。
- 进度计算的澄清:学习进度 不是一个需要复杂计算的独立实体,它重度依赖 答题记录。这让我们决定,进度统计可以做成一个定时任务或在查询时动态计算,而不是每次答题都实时更新一个庞大的汇总表,从而提高系统性能。
- 题库与题目的分离:题库 作为一个一级实体出现,并且与 章节、题目 有明确的包含关系。这直接决定了后台管理的功能模块划分和前端练习路径的导航结构,让产品架构更清晰。
总结
今天探讨的核心,不是 UML 的画图技巧,而是一种把业务需求翻译成技术团队通用语言的核心方法。领域建模的最大价值,在画图与讨论的过程中就已经完成了——那就是对齐认知。
一句话总结:一个好的领域模型,是团队用业务语言共同写成的、最具可执行性的“技术合同”。它能让你在动手编码前,看清业务全貌,避免因理解偏差而导致的大量返工。
 发表于 2026-1-21 06:11:33
|
查看: 263|
回复: 0
发表于 2026-1-21 06:11:33
|
查看: 263|
回复: 0
