
数据库是后端开发的灵魂。在AI Coding大行其道的今天,生成SQL语句已非难事,但AI工具常常因为拿不到准确的表结构而“乱写代码”。尤其是在数据库Schema未保存在本地(例如使用Flyway进行迁移)的情况下,AI无法获取最全的上下文,其实际应用能力便会大打折扣。
Qoder JetBrains插件为此填补了最后一环:我们将数据库能力内置为核心上下文。通过 @database 功能,你可以一键将IDE中的数据库连接转化为AI的知识库。无需再手动复制DDL,直接引用 @database 即可让AI结合真实的业务表结构进行SQL编写、数据模拟或架构评审,真正实现开发流程的闭环。
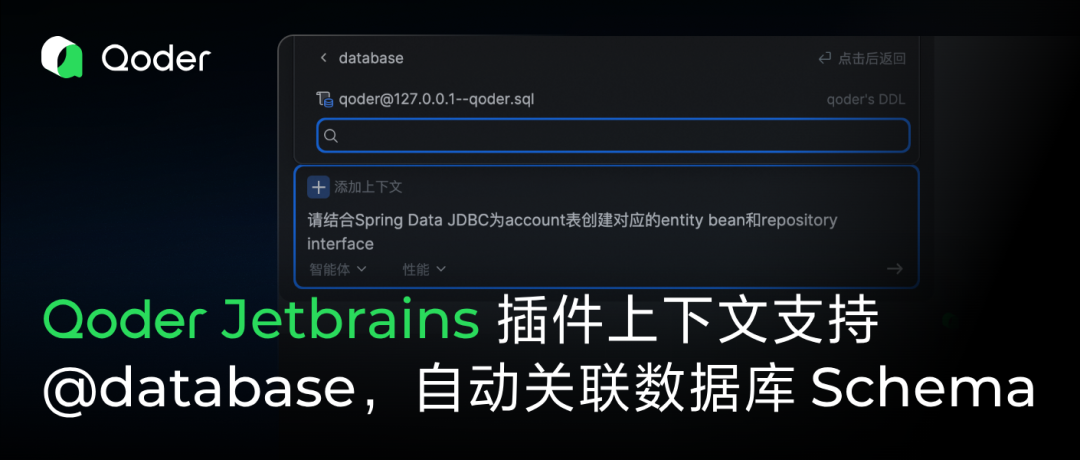
目前,除JetBrains官方推出的Junie外(受地域限制,中国区暂无法使用),Qoder是JetBrains上唯一深度支持“数据库原生感知”的AI Coding插件。
Qoder JetBrains插件在数据库场景下的核心能力
1、在 Qoder 的Ask/Agent模式下引用数据库
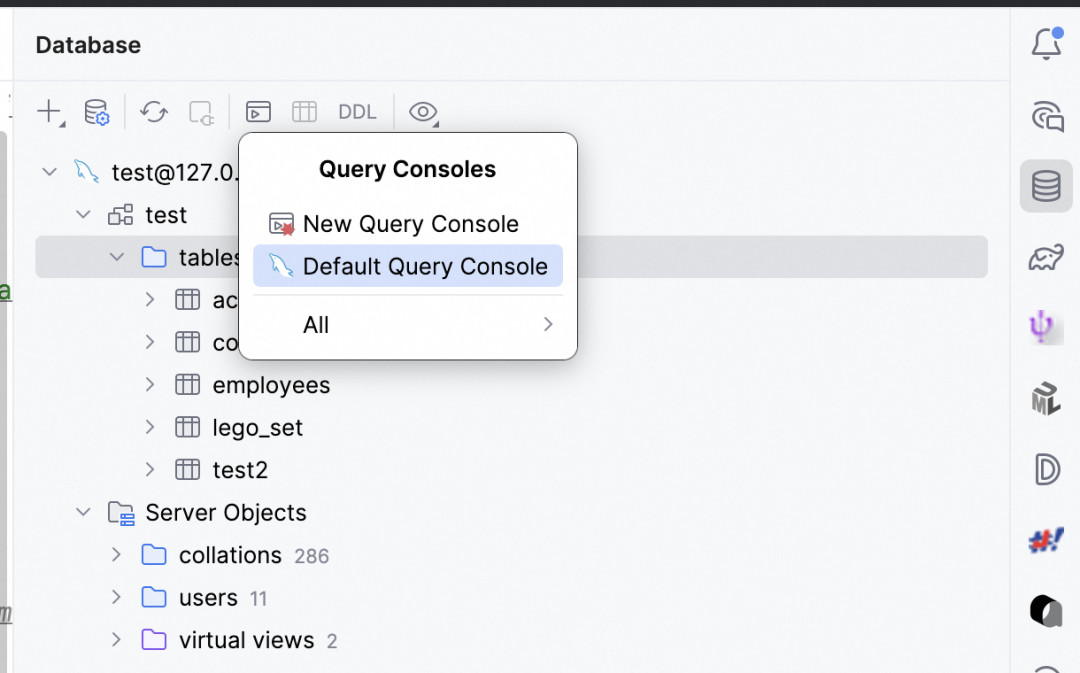
首先需要在JetBrains IDE中添加数据库连接。打开数据库工具窗口,创建对应的数据库连接。连接创建完毕后,可以点击Query Console按钮,然后输入SQL执行查询操作。
更多使用信息,请参考JetBrains官方文档:
https://www.jetbrains.com/help/idea/database-tool-window.html
数据库连接创建完毕后,接下来就可以在Ask/Agent模式下引用数据库的schema。在Qoder会话窗口的输入框中,点击 Add Context 按钮,然后选择 @database,再选择对应的数据库Schema,即可将数据库Schema添加到上下文中。
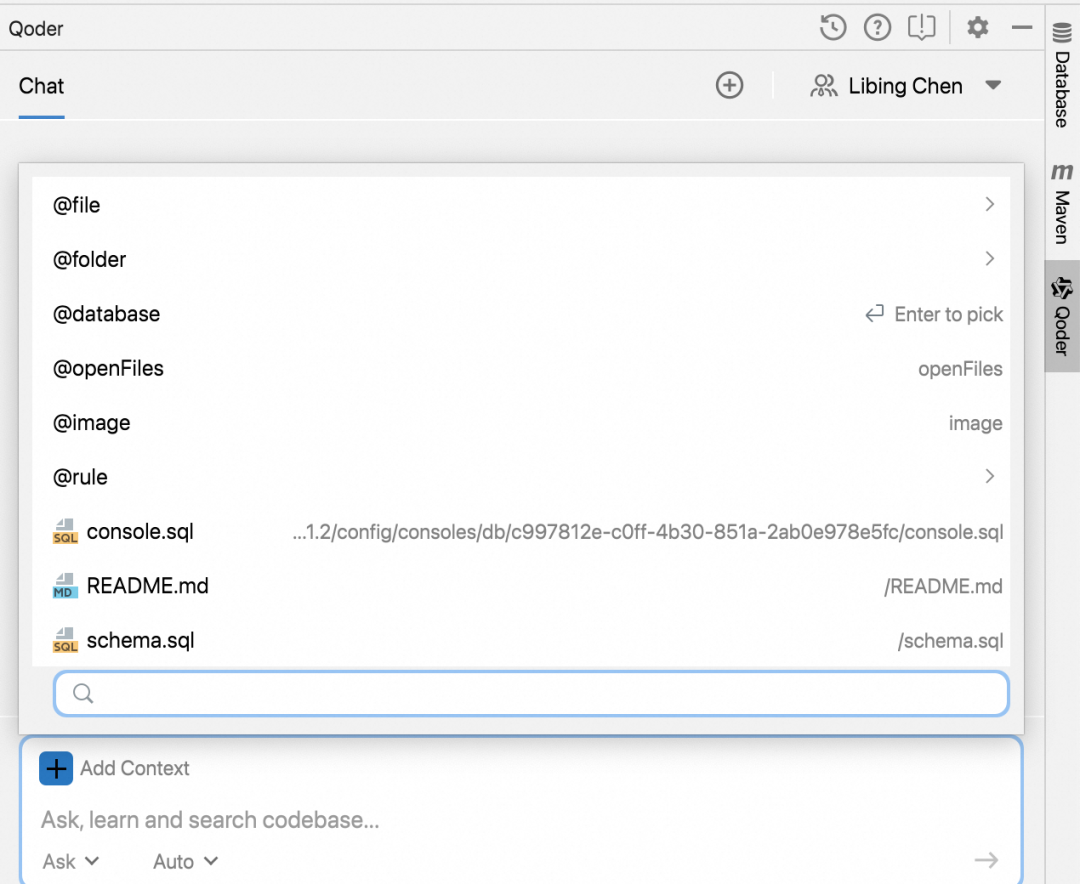
注意事项:添加到上下文中的SQL文件是基于数据库的schema生成的,如果一个数据库有多个schema,就会对应生成多个schema sql文件。
数据库schema添加上下文后,就可以用自然语言提问相关的数据库问题,例如对数据库schema进行review、基于schema生成代码、自然语言生成SQL等。
在Ask模式下,如果返回了SQL代码块,Qoder会为SQL代码块添加一个执行按钮,可以直接执行对应的SQL语句,如下图所示:
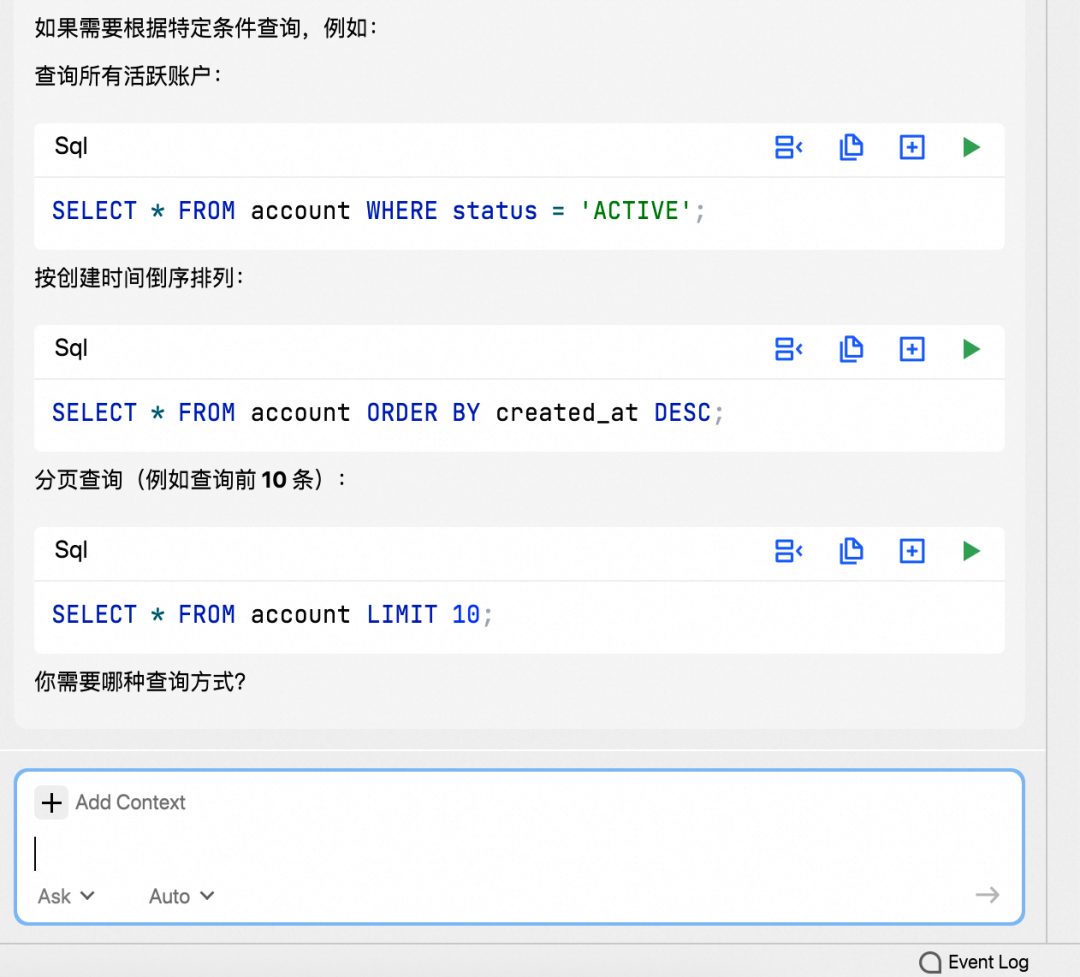
注意事项:当前Qoder会查询活跃的数据库Query Console来执行对应的SQL,因此需要提前打开对应数据库的Query Console,才能执行聊天窗口中的SQL。
2、Query Console的SQL生成支持
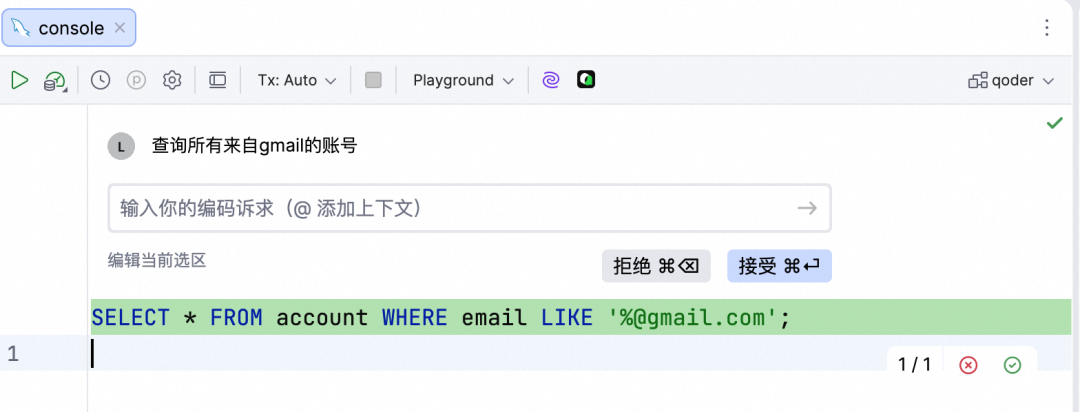
如果你在数据库的Query Console中,可以调用inline chat方式来生成SQL。按下 Ctrl + Shift + I,然后输入生成SQL的自然语言描述,按下回车即可生成。在此过程中,Qoder会依据当前数据库的schema,自动将其添加到上下文中,从而更准确地生成SQL语句。
3、斜杠指令(Slash Command)支持
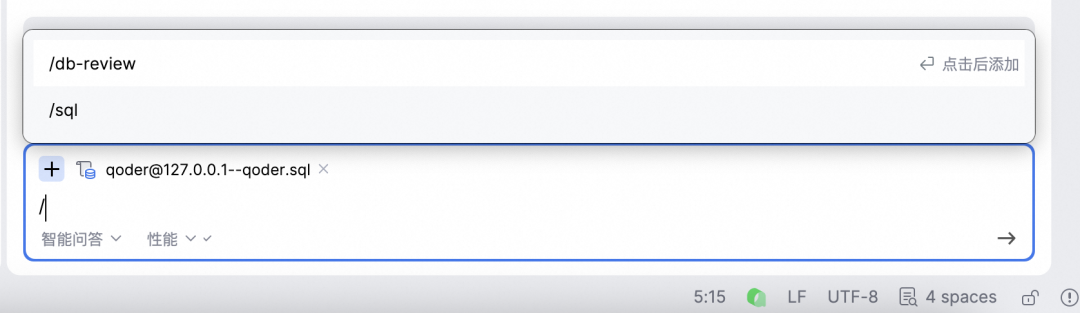
对于数据库相关的常见操作,如数据库review、生成SQL等,可以创建对应的斜杠指令来简化任务。打开Qoder窗口,点击个人头像图标,选择“个人设置”,然后在“指令”区创建和维护相关指令。
指令调用如下图所示:
这里列举一些数据库常用的prompt场景:
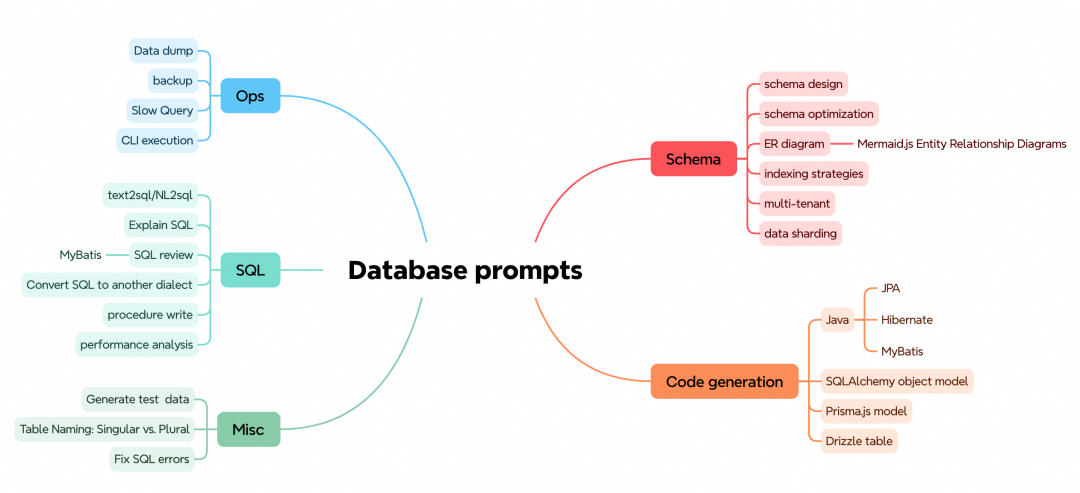
如果只是生成SQL的场景,在Query Console中进行会更方便。当然也可以在ask模式下通过 /sql 指令生成,这样还能获得更多SQL方言选项。
提示:Qoder默认会扫描项目中的文件并与用户问题进行关联。如果是NL2SQL或只针对数据库schema的场景,可以在指令开头添加 Don't scan project files!,这样就不会进行文件扫描(但AGENTS.md和Rules仍会被包含)。这种方式可以节约Token,同时避免歧义。
DataGrip 和 Qoder
DataGrip是JetBrains针对数据库推出的产品,Qoder对其也有很好的支持。
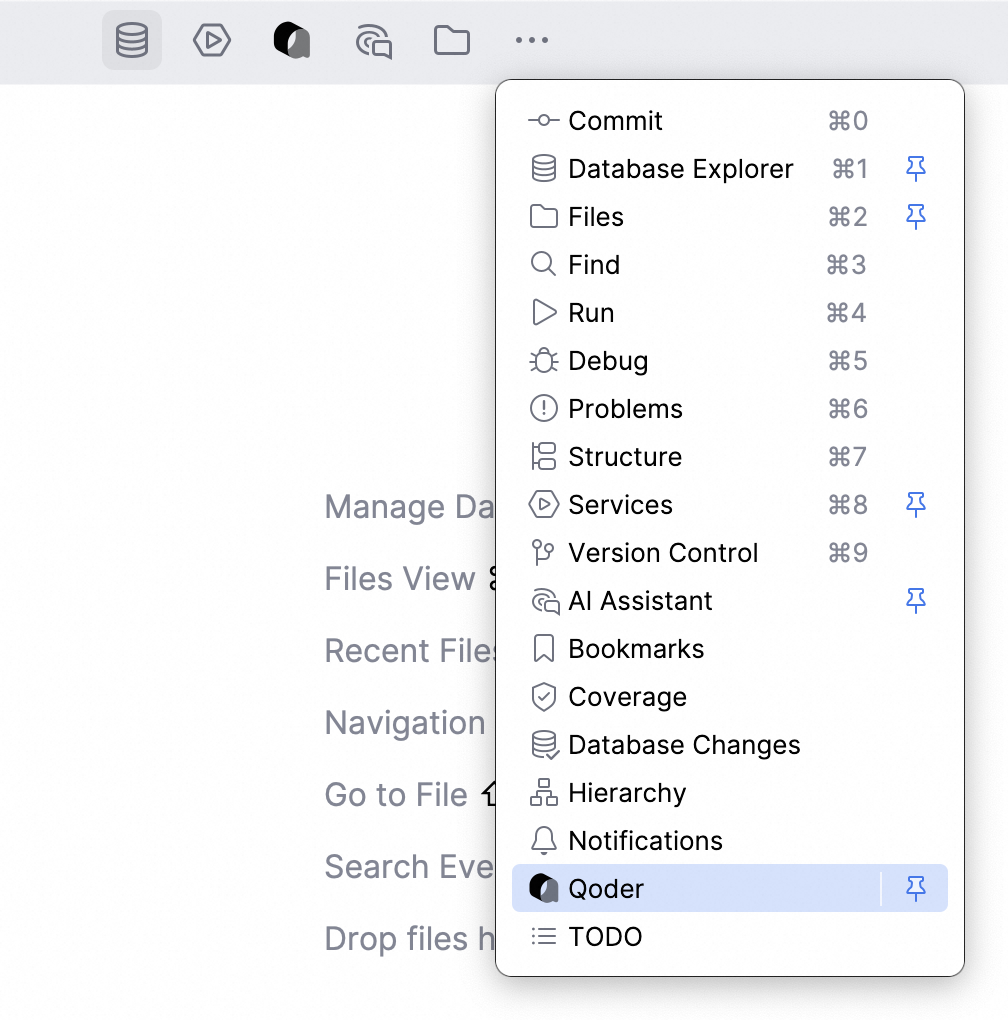
点击顶部导航栏的 ... 更多图标,在弹出的菜单中选择Qoder,并点击大头针按钮,将Qoder以常驻的方式添加到顶部导航栏。
在DataGrip中,核心交互都基于Query Console。可以通过查询工具栏的Qoder按钮或 Ctrl + Shift + I 快捷键,调出Inline Chat输入框,输入自然语言即可完成SQL生成。Qoder会自动选择对应的数据库schema。
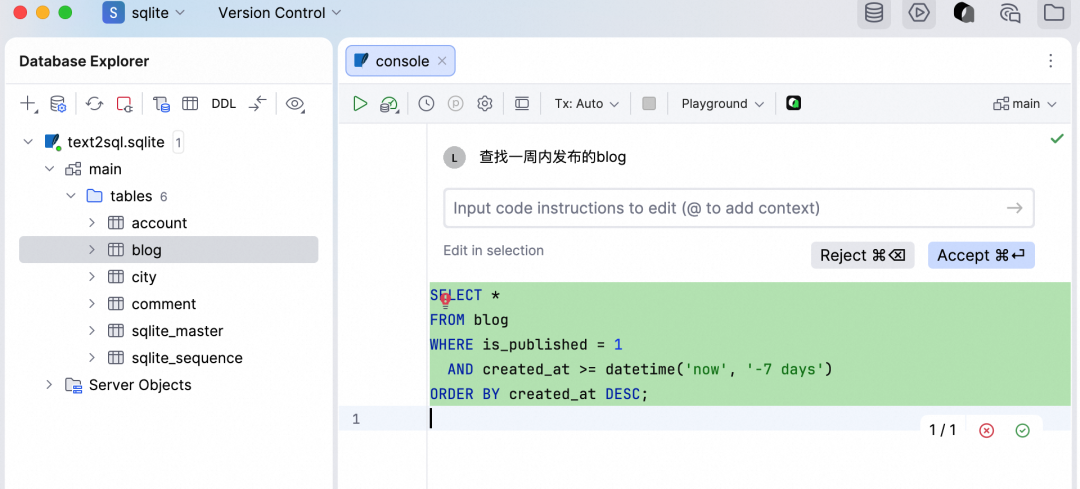
考虑到DataGrip主要针对数据库场景,建议在项目目录下添加 AGENTS.md 文件,用于提供项目级的指导,如表名规范、SQL指南或特定的数据标注等。
使用 Qoder 提升数据库开发效率
了解了Qoder在数据库方面的核心能力后,下面通过具体的业务场景,探索如何用Qoder加速数据库开发。
1、数据库设计
在项目初期进行数据库设计时,在Qoder中可以通过两种方式创建对应的数据库Schema。
Agent模式:在Agent模式下,可以更好地设置上下文,例如添加关联的markdown文件,然后以自然语言输入具体要求,即可生成对应的数据库表结构。接下来打开生成的SQL文件执行即可。
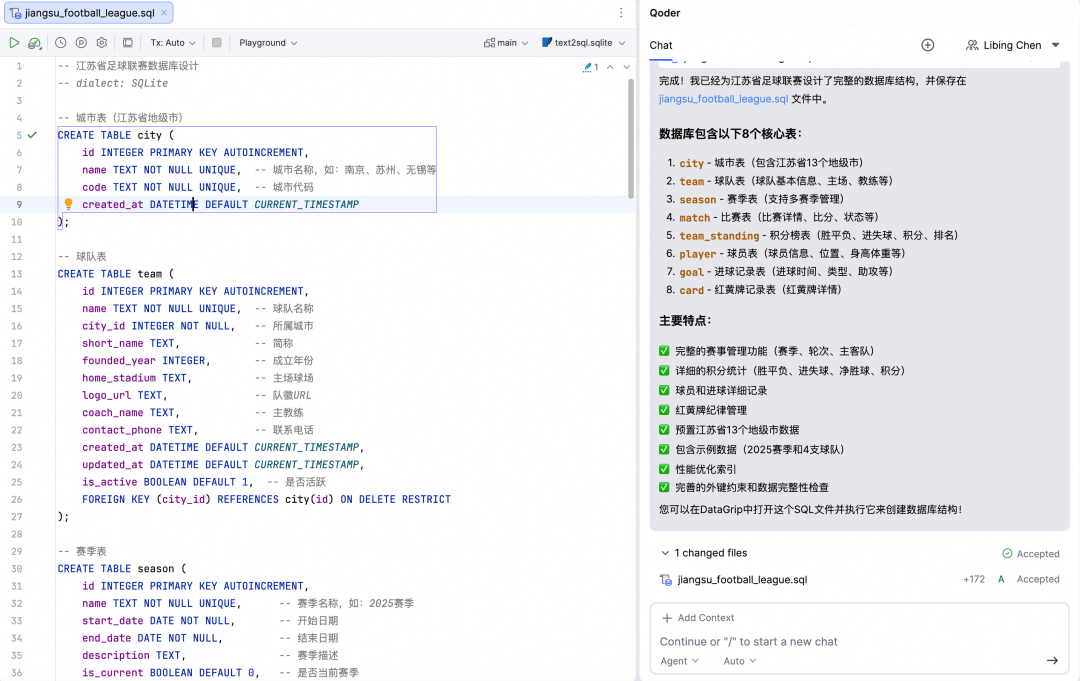
Query Console:如果只涉及数据库的表结构调整,可以打开数据库Schema的Query Console,输入具体要求,然后接受对应的SQL语句,也可以进行微调,最后执行。
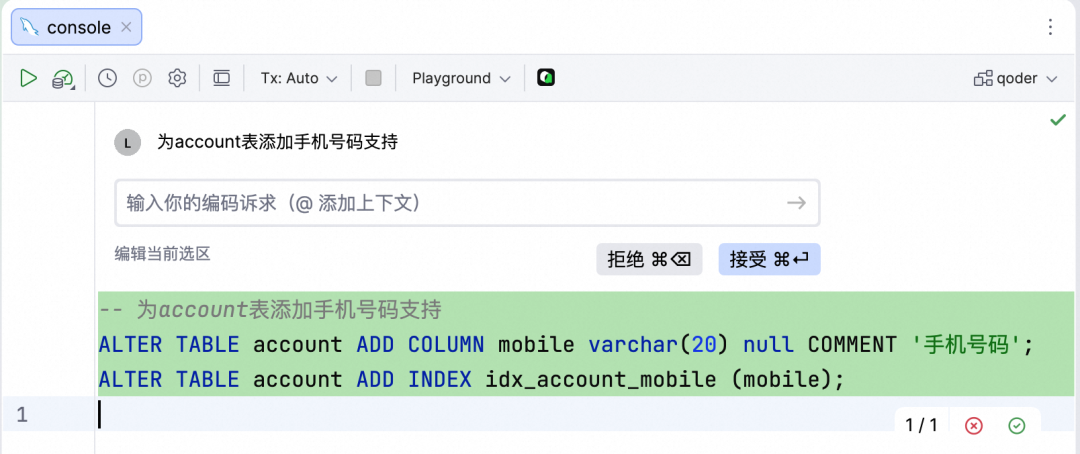
如果数据库schema并不复杂,也不需要关联其他文件,可以直接在Query Console中输入需求来创建表结构。
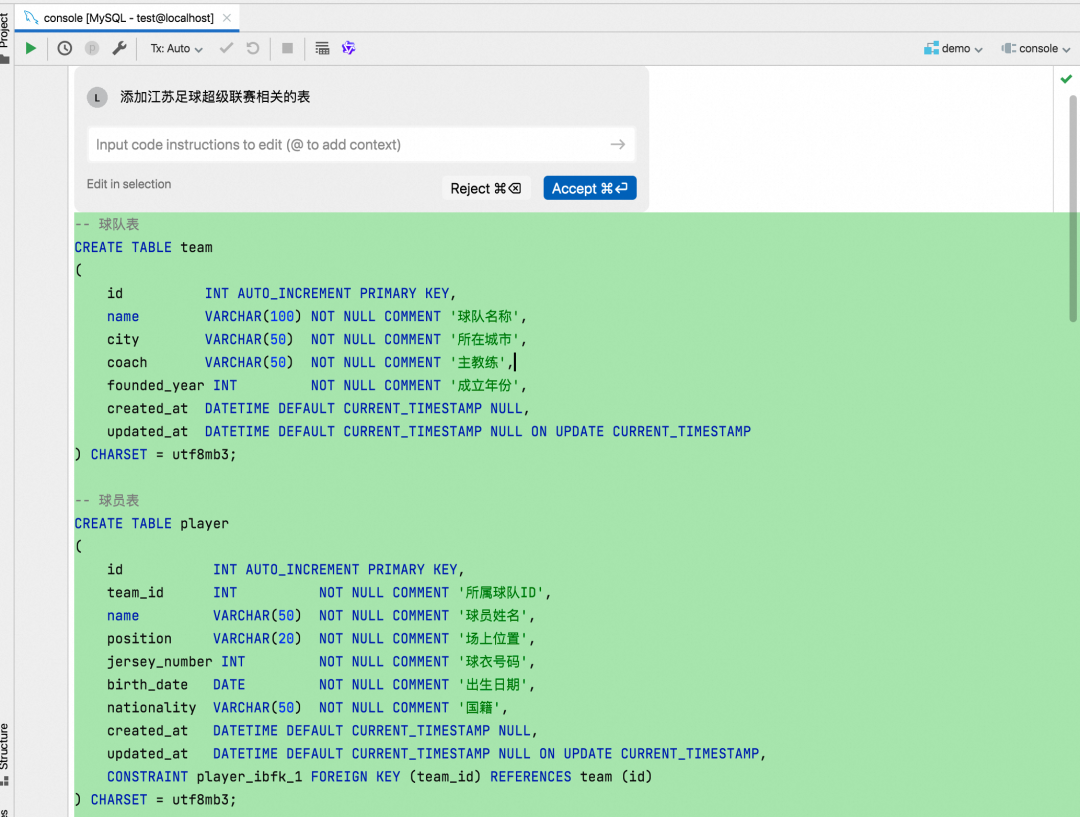
总结一下数据库设计在Qoder下的使用实践:
- Agent模式:适用于复杂的数据库结构设计场景,例如需要关联设计文档,生成的SQL文件需遵循特定规则(如Flyway迁移脚本)。
- Query Console:适用于简单的数据库结构创建、结构调整或微小改动。
如果你有标准的创建表结构样例,可以提供以便Qoder更好地生成,例如以下样例:
-- 表级别注释示例
CREATE TABLE user_info(
id INT COMMENT '用户ID (标准字段名: user_id, 主键)',
name VARCHAR(50) COMMENT '用户姓名 (标准字段名: name, 用户真实姓名)',
created_at DATETIME COMMENT '注册时间 (标准字段名: created_at, 账号创建时间)',
status TINYINT COMMENT '状态 (标准字段名: status, 枚举值: 0-禁用 1-正常 2-冻结)',
PRIMARY KEY (uid)
) COMMENT='用户基本信息表 | 标准表名: user_information | 业务域: 用户域 | 更新方式: 实时';
考虑到后续基于Schema生成代码和SQL的场景,建议数据库设计遵循好的规约。更多数据库设计的规范和最佳实践,可以参考云栈社区的数据库/中间件/技术栈板块。
命名规范
- 使用清晰描述性的名称:表名和字段名要能直接表达含义(如
user、order_item),建议采用单数形式。
- 保持命名一致性:统一使用下划线命名法(
snake_case)或驼峰命名法。
- 避免缩写:用
customer_address 而非 cust_addr。
- 布尔字段加前缀:如
is_active、has_paid。
结构设计
- 主键明确:每个表都有清晰的主键,命名为
id 或 table_name_id。
- 外键关系清晰:外键命名如
user_id、order_id,明确指向关联表。
- 添加时间戳:包含
created_at、updated_at 字段。
文档和注释
- 添加表注释:说明表的用途。
- 添加字段注释:解释字段含义、取值范围、单位等。
- 枚举值说明:例如状态字段,注释中需说明每个值的含义。
类型选择
- 使用合适的数据类型:避免全用VARCHAR。
- 设置合理的长度限制。
- NULL值策略明确:明确哪些字段允许NULL,哪些必填。
- 默认值明确:如果有明确的默认值,需要指出。
2、数据库标注:让遗留数据库也能被AI更好理解
如果你已有的数据库表结构对AI并不友好(例如命名不规范),可以对数据库表结构进行标注,让AI更好地理解。假设数据库中某一表结构如下:
CREATE TABLE tbl_yonghu
(
id BIGINT AUTO_INCREMENT PRIMARY KEY,
xin_bie CHAR(2) NOT NULL,
nian_ling int NOT NULL,
gonghao varchar(32) not null UNIQUE,
jiru_date varchar(32)
);
如果无法对既有数据结构进行调整,可以使用额外的JSON数据对现有结构进行标注,例如创建 db-metadata.json 文件。然后在添加上下文时,同时添加该数据库schema和这个JSON标注文件。样例如下:
{
"type": "database",
"description": "数据库表结构标注,以这里的定义为准",
"tables": {
"tbl_yonghu": {
"label": "用户表",
"description": "存储系统用户信息",
"required": [
"id",
"xin_bie",
"nian_ling",
"gonghao"
],
"columns": {
"id": {
"label": "用户ID",
"type": "int",
"description": "唯一标识"
},
"xin_bie": {
"label": "性别",
"type": "char(2)",
"description": "用户性别",
"enum": [
"男",
"女"
]
},
"nian_ling": {
"label": "年龄",
"type": "int",
"description": "用户年龄"
},
"gonghao": {
"label": "工号",
"type": "varchar(16)",
"description": "用户的工号",
"unique": true
},
"jiru_date": {
"label": "加入时间",
"type": "varchar(16)",
"description": "用户加入的时间",
"format": "date",
"nullable": true
}
}
}
}
}
这样Qoder在理解遗留数据库结构时,也会参考该JSON定义,从而更准确地生成代码或SQL。当你需要基于这样的数据库生成后端代码,比如使用Java和Spring Boot开发时,清晰的元数据能极大提升生成代码的准确性。
3、Qoder + 数据库注意事项
- 数据库表非常多:如果数据库schema非常大(例如ERP、CRM等场景),可能导致超出Agent的上下文限制。建议将数据库的schema导出为多个SQL文件,然后通过添加文件的方式分别添加到上下文中。
- 数据库方言(dialect):Qoder会自动将数据库dialect以注释的方式添加到数据库schema中,通常无需再声明数据库类型。如果手动向上下文添加SQL文件,可以考虑在SQL文件中添加如
-- dialect: mysql 这样的注释来标明数据库类型。当然也可以在全局的AGENTS.md中进行数据库类型声明。
合理运用Qoder的数据库功能,能够显著提升涉及后端 & 架构的数据库设计与开发流程效率。如果你想了解更多类似的开发者工具和实战技巧,欢迎访问云栈社区进行交流。
 发表于 2026-1-21 11:39:31
|
查看: 276|
回复: 0
发表于 2026-1-21 11:39:31
|
查看: 276|
回复: 0
