在正式讲解之前,先通过一个实际演示了解大文件上传的完整流程。下面演示的是上传1GB压缩包的过程,支持分片上传、断点续传、暂停和恢复功能。
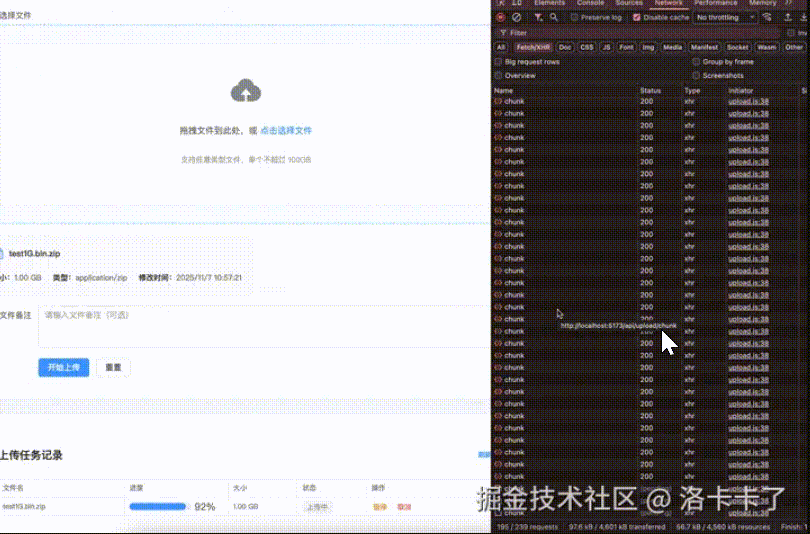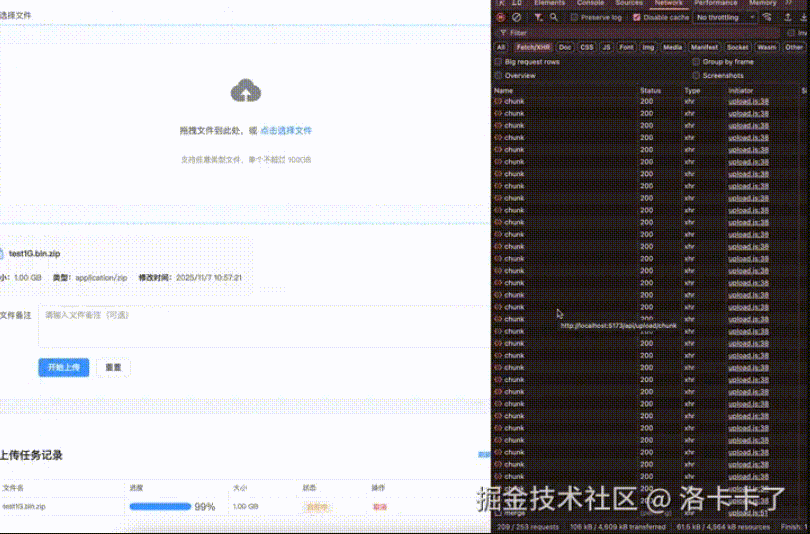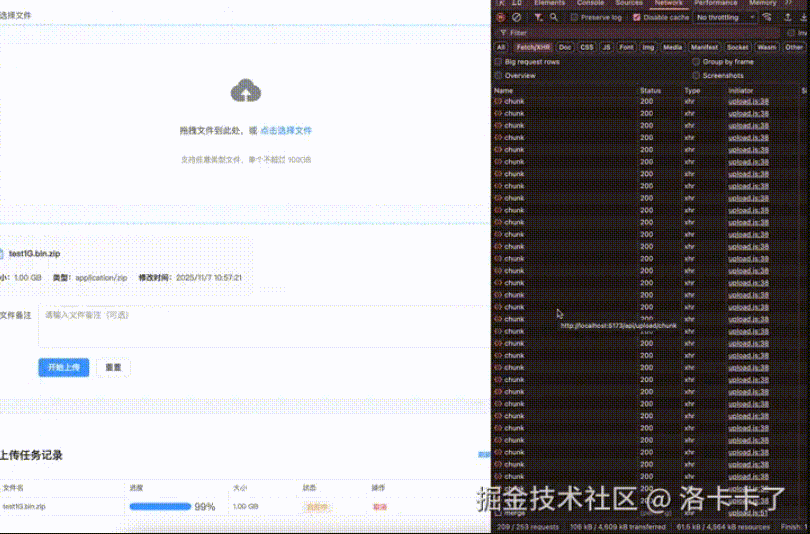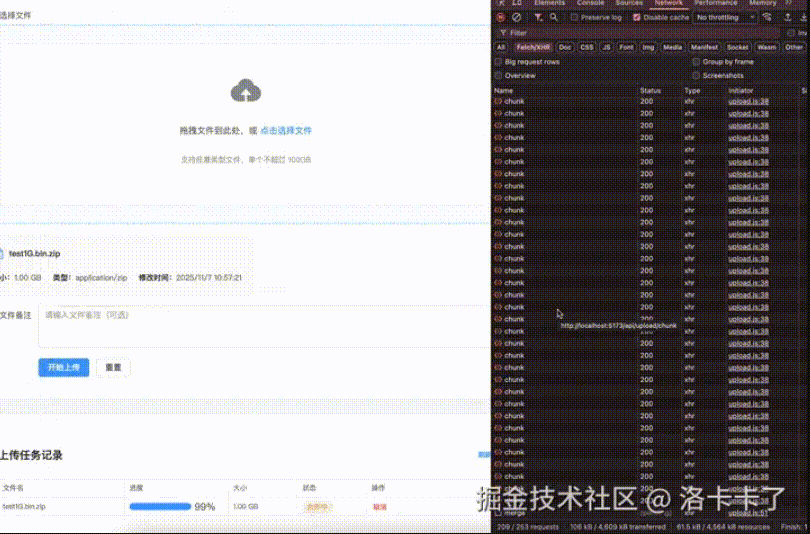
在常规SaaS系统中,文件上传功能通常设计得较为简单:前端进行分片上传,后端合并分片后存储到OSS或服务器路径,最后返回URL地址。这种方案在大多数场景下确实适用,但在私有化部署项目中却面临全新挑战。
业务场景特殊性
近期在政企内部系统项目中,需要处理AI大模型客服问答功能的文档上传需求。客户需将内部文档、手册、规范等资料打包上传至服务器,用于后续的向量化、知识检索和模型训练。这类场景具有以下特征:
- 文件数量多:动辄数百上千份(Word、PDF、PPT、Markdown等格式)
- 文件体积大:压缩包通常达到几GB甚至几十GB
- 上传环境复杂:内网或局域网环境,部分完全断网
- 安全要求高:文件涉及保密资料,不能经过云端OSS
- 审计需求:需记录上传人、时间、存储位置等完整信息
- 后续处理:需要自动解压、文本解析、拆页、向量化后存入Milvus或pgvector
若继续采用"SaaS简单上传+云存储"方案,将面临诸多问题:
- 上传中断后刷新页面需重传整个文件包
- 集群部署时分片分布在不同机器无法合并
- 多人同时上传可能发生文件覆盖或路径冲突
- 缺乏上传记录和用户追踪机制
- 无法满足政企审计、合规和保密要求
常规项目中的上传方案
回顾常规Web项目,特别是SaaS系统和后台管理系统,后端通常只提供单个/upload接口。前端获取文件后直接调用该接口,后端保存文件并返回URL即完成流程。
在某些项目中,前端甚至不将文件传递给业务服务,而是通过云存储SDK(如阿里云OSS、腾讯云COS、七牛云等)直接上传到云端,获取文件地址后再回传给后端保存。
这种模式在SaaS系统或轻量级业务中非常普遍,主要基于以下考量:
- 文件体积小:多为几MB的图片、PDF或Excel文件
- 云存储稳定:具备完整的上传、下载、访问SDK支持
- 公网部署环境:无需考虑局域网或内网断网问题
- 安全要求低:文件内容不涉及涉密数据
- 用户体验优先:直传云端是最便捷的方案
这种"单upload接口"或"前端直传OSS"模式面向的是通用型SaaS场景,在绝大多数互联网业务中既高效又便捷。但一旦切换到政企、私有化部署或AI训练平台环境,问题的核心就转变为文件上传后的可控性、可追溯性和安全性。
前端大文件上传技术方案
在重新设计后端接口前,先梳理前端常见的大文件上传方案。近年来前端技术在此领域已相当成熟,主流方案围绕几个核心点展开:秒传检测、分片上传、断点续传、并发控制和进度展示。
前端获取文件后,首先计算文件哈希值(如MD5),用于秒传检测:如果服务器已存在相同文件,可直接跳过上传环节,节省时间和带宽资源。
接下来是分片上传环节。面对大文件时,前端将文件拆分为固定大小的数据块(通常5MB或10MB),逐片上传。这种方式避免了单次传输大文件导致的浏览器卡顿或网络中断问题。
断点续传功能通过记录已上传分片状态实现。当上传过程因网络中断或页面刷新而中断时,下次只需继续上传未完成的分片,无需重新传输整个文件包。
在性能优化方面,前端实施并发控制策略。例如同时上传3-5个分片,完成一个立即补充下一个,整体速度显著优于单线程串行上传。
最后是进度展示功能。通过监听每个分片的上传状态,前端可实时计算整体进度,为用户提供上传百分比或进度条反馈,提升操作体验。
基于这种相对标准的前端逻辑,我们构建了更贴合企业私有化环境的上传接口控制体系,明确前后端职责划分:前端负责切片、控制与恢复;后端负责存储、校验与合并。
后端接口架构设计
为配合前端标准上传流程,将后端接口拆分为多个独立阶段:秒传检查、初始化任务、上传分片、合并文件、暂停任务、取消任务、任务列表。每个接口职责单一,便于后期扩展维护。
一、/upload/check —— 秒传检查
作为流程第一步,用于检测文件是否已存在。前端计算完文件全局MD5后调用此接口,若数据库中存在相同哈希文件,直接返回"已存在"状态,前端跳过上传环节。
请求示例:
POST /api/upload/check
{
"fileHash": "md5_abc123def456",
"fileName": "training-docs.zip",
"fileSize": 5342245120
}
返回示例:
{
"success": true,
"data": {
"exists": false
}
}
当exists = true时,表示服务端已存在该文件,直接执行秒传成功逻辑。
伪代码示例:
@PostMapping("/check")
public Result<?> checkFile(@RequestBody Map<String, Object> body) {
// 1. 校验fileHash参数是否为空
// 2. 查询file_info表是否已有该文件
// 3. 如果文件已存在,直接返回秒传成功(exists = true)
// 4. 如果文件不存在,查询upload_task表中是否有未完成任务
}
二、/upload/init —— 初始化上传任务
当文件不存在时,需初始化新上传任务。此接口创建upload_task记录,返回唯一uploadId,前端使用该标识符管理整个上传过程。
请求示例:
POST /api/upload/init
{
"fileHash": "md5_abc123def456",
"fileName": "training-docs.zip",
"totalChunks": 320,
"chunkSize": 5242880
}
返回示例:
{
"success": true,
"data": {
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b",
"uploadedChunks": []
}
}
uploadedChunks字段支持断点续传,返回已上传分片索引数组。
伪代码示例:
@PostMapping("/init")
public Result<UploadInitResponse> initUpload(@RequestBody UploadInitRequest request) {
// 1. 检查是否已有同fileHash任务,若有则返回旧任务信息
// 2. 创建新的upload_task记录,生成uploadId
// 3. 初始化分片数量、大小、状态等信息
// 4. 返回uploadId与已上传分片索引列表
}
三、/upload/chunk —— 上传单个分片
这是调用频率最高的接口。每个分片单独上传,服务端保存为临时文件并写入upload_chunk表。上传成功后更新upload_task进度信息。
请求示例(表单上传):
POST /api/upload/chunk
Content-Type: multipart/form-data
formData:
uploadId: b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b
chunkIndex: 0
chunkSize: 5242880
chunkHash: md5_001
file: (二进制分片数据)
返回示例:
{
"success": true,
"data": {
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b",
"chunkIndex": 0,
"chunkSize": 5242880
}
}
伪代码示例:
@PostMapping(value = "/chunk", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public Result<?> uploadChunk(@ModelAttribute UploadChunkRequest req) {
// 1. 校验任务状态,禁止上传已取消或已完成任务
// 2. 检查本地目录(或云端存储桶)是否存在,不存在则创建
// 3. 接收当前分片文件并写入临时路径
// 4. 写入upload_chunk表,标记状态为"已上传"
// 5. 更新upload_task的uploaded_chunks数量
}
四、/upload/merge —— 合并分片
当前端确认所有分片上传完成后调用此接口。后端检查分片完整性后按索引顺序合并,删除临时分片文件,更新upload_task状态为"完成"。若启用云存储,此步骤可直接将合并后文件上传至OSS。
请求示例:
POST /api/upload/merge
{
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b",
"fileHash": "md5_abc123def456"
}
返回示例:
{
"success": true,
"message": "文件合并成功",
"data": {
"storagePath": "/data/uploads/training-docs.zip"
}
}
伪代码示例:
@PostMapping("/merge")
public Result<?> mergeFile(@RequestBody UploadMergeRequest req) {
// 1. 检查upload_task状态是否允许合并
// 2. 校验所有分片是否都上传完成
// 3. 如果是本地存储:按chunk_index顺序流式合并文件
// 4. 如果是云存储:调用云端分片合并API(如OSS、COS)
// 5. 校验文件hash完整性,更新任务状态为COMPLETED
// 6. 将最终文件信息写入file_info表
}
五、/upload/pause —— 暂停任务
用于上传过程中手动暂停任务。前端在网络波动或用户主动操作时调用,后端更新任务状态为"已暂停",记录当前已上传分片数。
请求示例:
POST /api/upload/pause
{
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b"
}
返回示例:
{
"success": true,
"message": "任务已暂停"
}
伪代码示例:
@PostMapping("/pause")
public Result<Void> pauseUpload(@RequestBody UploadPauseRequest req) {
// 1. 查找对应的upload_task
// 2. 更新任务状态为"已暂停"
// 3. 返回任务状态确认信息
}
六、/upload/cancel —— 取消任务
用户放弃上传时调用此接口。后端将任务状态标记为"已取消",清理对应临时分片文件,避免磁盘空间浪费。
请求示例:
POST /api/upload/cancel
{
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b"
}
返回示例:
{
"success": true,
"message": "任务已取消"
}
伪代码示例:
@PostMapping("/cancel")
public Result<?> cancelUpload(@RequestBody UploadCancelRequest req) {
// 1. 查找对应的upload_task
// 2. 更新任务状态为"已取消"
// 3. 删除或标记已上传分片文件为待清理
// 4. 返回操作结果
}
七、/upload/list —— 查询任务列表
用于管理后台查看上传任务整体情况,展示文件名、大小、进度、状态、上传人等信息,便于追踪和审计。
请求示例:
GET /api/upload/list
返回示例:
{
"success": true,
"data": [
{
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b",
"fileName": "training-docs.zip",
"status": "COMPLETED",
"uploadedChunks": 320,
"totalChunks": 320,
"uploader": "admin",
"createdAt": "2025-10-20 14:30:12"
}
]
}
伪代码示例:
@GetMapping("/list")
public Result<List<UploadTaskSummary>> listUploadTasks() {
// 1. 查询所有上传任务
// 2. 按创建时间或状态排序
// 3. 返回任务摘要信息
}
接口调用时序
完整上传过程调用顺序如下:
1. /upload/check → 秒传检测
2. /upload/init → 初始化上传任务
3. /upload/chunk → 循环上传所有分片
4. /upload/merge → 所有分片完成后合并
可选控制接口:/upload/pause、/upload/cancel用于任务控制,/upload/list用于任务追踪与审计。
接口调用示意图
下图展示前端、后端、数据库在整个上传过程中的交互关系:
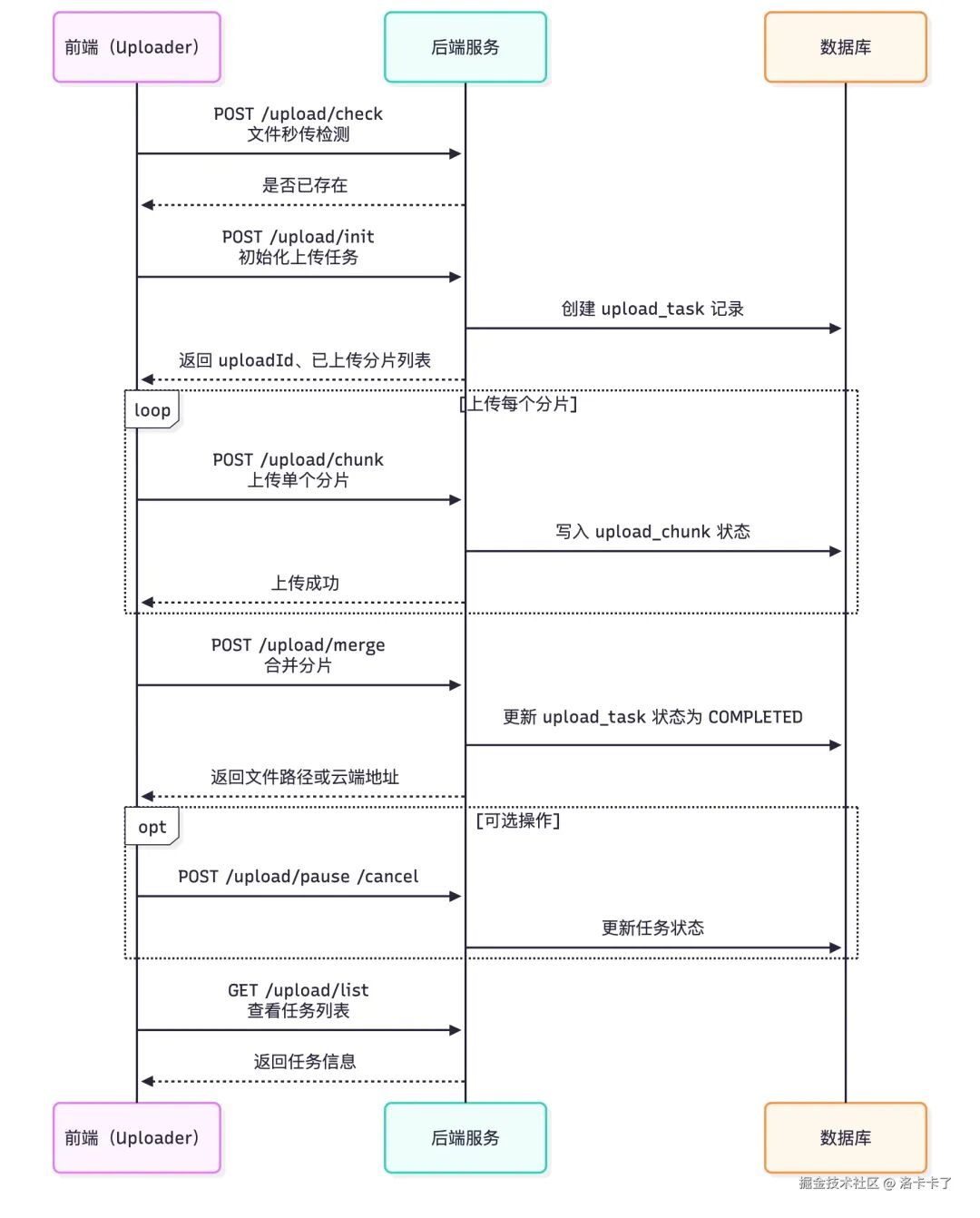
这种设计具有以下优势:
- 逻辑衔接顺畅:接口职责明确,图示总结清晰
- 视觉节奏平衡:图文结合缓解阅读疲劳
- 承上启下:既总结接口流程,又自然引出数据库设计
这套接口设计全面覆盖企业级项目中的大文件上传需求。接下来探讨支撑这些接口的Java后端架构设计。
数据库架构设计
为实现稳定的上传服务,后端需要记录任务状态、分片信息和文件存储路径的数据库结构。上传操作通常持续数分钟至数小时,需确保任务状态可追踪、可恢复,并支持集群部署环境。
设计三张核心表:upload_task(上传任务表)、upload_chunk(分片表)、file_info(文件信息表),分别管理任务、分片和最终文件的数据关系。
一、upload_task —— 上传任务表
作为上传过程的"总账",每个文件上传任务在此生成记录,保存任务的全局信息,包括文件名、大小、上传进度、状态和存储方式等。
CREATE TABLE `upload_task` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`upload_id` varchar(64) NOT NULL COMMENT '任务唯一ID(UUID)',
`file_hash` varchar(64) NOT NULL COMMENT '文件哈希(用于秒传与断点续传)',
`file_name` varchar(255) NOT NULL COMMENT '文件名称',
`file_size` bigint(20) NOT NULL COMMENT '文件总大小(字节)',
`chunk_size` bigint(20) NOT NULL COMMENT '每个分片大小(字节)',
`total_chunks` int(11) NOT NULL COMMENT '分片总数',
`uploaded_chunks` int(11) DEFAULT '0' COMMENT '已上传分片数量',
`status` tinyint(4) DEFAULT '0' COMMENT '任务状态:0-待上传 1-上传中 2-合并中 3-完成 4-取消 5-失败 6-已合并 7-已暂停',
`storage_type` varchar(32) DEFAULT 'local' COMMENT '存储类型:local/oss/cos/minio/s3等',
`storage_url` varchar(512) DEFAULT NULL COMMENT '文件最终存储地址(云端或本地路径)',
`local_path` varchar(512) DEFAULT NULL COMMENT '本地临时文件或合并文件路径',
`remark` varchar(255) DEFAULT NULL COMMENT '备注信息',
`uploader` varchar(64) DEFAULT NULL COMMENT '上传人',
`created_at` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `upload_id` (`upload_id`),
KEY `idx_hash` (`file_hash`),
KEY `idx_status` (`status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='上传任务表(支持多种云存储)';
设计要点:
- upload_id 前端初始化任务后由后端生成的唯一标识
- file_hash 支持秒传逻辑
- status 控制任务生命周期
- storage_type、storage_url 兼容多种存储方案
- uploaded_chunks 支持任务恢复和断点续传
二、upload_chunk —— 分片表
对应每个上传任务的所有分片,每个分片单独记录,用于追踪上传状态。支持断点续传、进度统计和合并前完整性检查。
CREATE TABLE `upload_chunk` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`upload_id` varchar(64) NOT NULL COMMENT '所属上传任务ID',
`chunk_index` int(11) NOT NULL COMMENT '分片索引(从0开始)',
`chunk_size` bigint(20) NOT NULL COMMENT '实际分片大小(字节)',
`chunk_hash` varchar(64) DEFAULT NULL COMMENT '可选:分片hash(用于高级去重)',
`status` tinyint(4) DEFAULT '0' COMMENT '状态:0-待上传 1-已上传 2-已合并',
`local_path` varchar(512) DEFAULT NULL COMMENT '分片本地路径',
`created_at` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_task_chunk` (`upload_id`,`chunk_index`),
KEY `idx_upload_id` (`upload_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='上传分片表';
设计要点:
- upload_id 任务外键,与upload_task对应
- chunk_index 分片顺序,合并时按此排序
- chunk_hash 可选字段,用于完整性校验
- status 控制上传进度
- 唯一索引避免重复插入分片
通过此表实现断点续传:用户重新上传时,后端返回未完成分片索引,前端跳过已上传部分。
三、file_info —— 文件信息表
记录上传完成后的最终文件信息,作为系统文件索引表。文件合并成功并通过校验后,写入此表记录。支持秒传功能,供后续文档解析或向量化任务使用。
CREATE TABLE `file_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`file_hash` varchar(64) NOT NULL COMMENT '文件hash,用于秒传',
`file_name` varchar(255) NOT NULL COMMENT '文件名称',
`file_size` bigint(20) NOT NULL COMMENT '文件大小',
`storage_type` varchar(32) DEFAULT 'local' COMMENT '存储类型:local/oss/cos/minio/s3等',
`storage_url` varchar(512) DEFAULT NULL COMMENT '文件最终存储地址(云端或本地路径)',
`uploader` varchar(64) DEFAULT NULL COMMENT '上传人',
`status` tinyint(4) DEFAULT '1' COMMENT '状态:1-正常,2-删除中,3-已归档',
`remark` varchar(255) DEFAULT NULL COMMENT '备注',
`created_at` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `file_hash` (`file_hash`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='已上传文件信息表(支持多云存储)';
设计要点:
- file_hash 全局唯一标识,支持秒传和查重
- storage_url 记录最终可访问路径
- status 支持删除、归档等后续操作
- 与业务系统中的文档解析、知识库构建直接关联
四、表关系架构
三张表的关系可简化为:
upload_task (上传任务)
├── upload_chunk (分片详情)
└── file_info (最终文件)
- upload_task 管理任务生命周期
- upload_chunk 跟踪每个分片上传进度
- file_info 保存最终文件索引,用于秒传与后续AI处理
这种设计确保:
- 上传状态可追踪
- 上传任务可恢复
- 文件信息统一管理
- 多节点部署一致性
状态管理与恢复机制
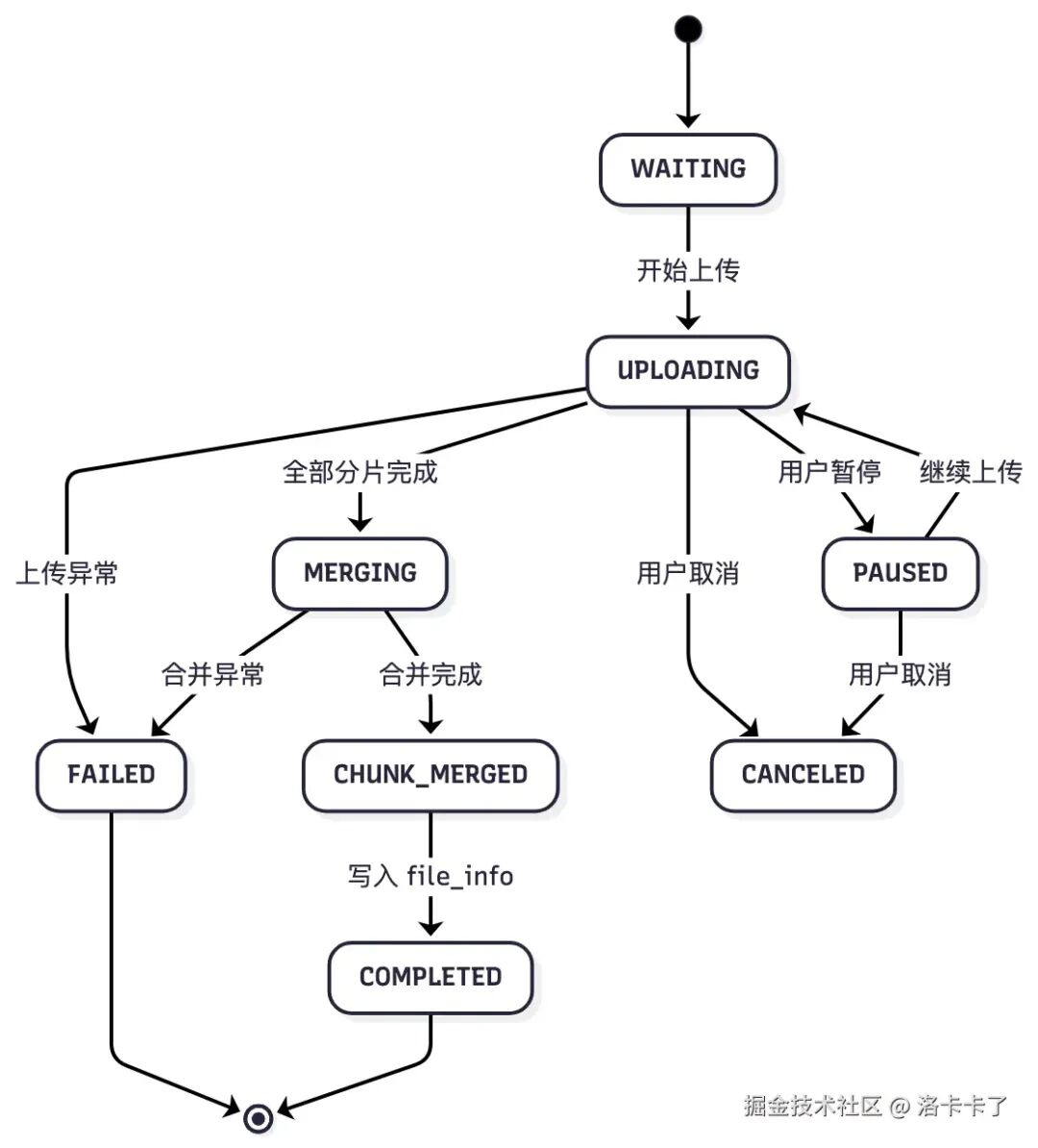
基于三张核心表,上传过程实现状态机化管理。每个上传任务从创建、上传、合并到完成都有明确状态,系统可在任意阶段中断后恢复,无需用户重新操作。
上传任务生命周期划分为关键状态:
WAITING(0, "待上传"),
UPLOADING(1, "上传中"),
MERGING(2, "合并中"),
COMPLETED(3, "已完成"),
CANCELED(4, "已取消"),
FAILED(5, "上传失败"),
CHUNK_MERGED(6, "已合并"),
PAUSED(7, "已暂停");
状态流转详解
WAITING(待上传)
用户发起上传、文件切片尚未传输时的初始状态。系统生成上传任务记录(/upload/init接口),任务仅登记在数据库,未开始数据传输。此时upload_task.status = 0,分片表无数据记录。
UPLOADING(上传中)
第一个分片开始上传时,任务状态更新为"上传中"。每上传一个分片,在upload_chunk表写入记录,并更新任务的uploaded_chunks字段。系统周期性根据分片数量更新进度条,支持任务恢复。
此阶段用户可能暂停、断网、刷新页面或浏览器崩溃,但分片信息已持久化到数据库,可随时通过upload_chunk状态恢复上传。
PAUSED(已暂停)
用户主动暂停上传时,任务状态标记为PAUSED。暂停不删除分片,仅阻止继续发送请求。用户点击"继续上传"时,前端获取未上传分片列表,实现断点续传。此状态通常在用户控制下出现,如网络切换场景。
CANCELED(已取消)
用户彻底放弃上传任务时标记为CANCELED。系统可选择删除临时分片文件或保留等待清理。后台日志记录取消操作的用户、时间和进度信息,用于审计追踪。
MERGING(合并中)
所有分片上传完成后,后端触发文件合并逻辑(调用/upload/merge)。任务状态切换为"MERGING",表示系统执行最终步骤。
合并过程:
- 本地存储:逐个读取分片文件并拼接为完整文件
- 云存储:触发服务端分片合并API(如OSS、MinIO)
大文件合并耗时较长,需单独设置状态标识。
CHUNK_MERGED(已合并)
部分系统将合并成功但未处理状态单独标识,用于文件校验或后处理。实际项目中可跳过此状态,直接进入COMPLETED。
COMPLETED(已完成)
文件合并完成、验证通过、存储路径落地、写入file_info表后,任务彻底完成。此状态下:
- 用户可正常访问文件
- 系统执行后续解析任务(文档拆页、向量化等)
- 文件具备秒传条件
FAILED(上传失败)
上传过程出现异常(网络中断、磁盘写入异常、OSS上传失败等)时标记为FAILED。此状态不自动清理,便于管理员追踪错误原因或人工恢复。失败任务通常允许重新启动,从断点继续上传。
通过下图可直观了解上传任务生命周期:
任务恢复实现机制
在此架构下,任务恢复变得自然流畅。前端每次进入上传页面时,传入文件hash,后端通过upload_task和upload_chunk判断:
- 文件是否存在上传任务
- 已上传分片列表
- 任务当前状态
前端仅需补传未完成分片,实现断点续传(Resumable Upload)。集群环境中,因任务与分片状态持久化在数据库,不依赖单台服务器,确保请求分发到任意机器都能保持进度一致性。
中断续传流程
实际使用中,上传中断常见场景包括:大文件上传中途浏览器关闭、网络中断、机器重启甚至更换设备继续操作。若无任务恢复机制,用户需重复传输整个文件,既浪费时间又易出错。
恢复机制核心
断点续传核心逻辑简单明了:任务和分片状态持久化存储。
用户重新选择相同文件时,前端计算文件hash并调用/upload/check接口。后端接收hash后依次查询三张表:
- 查询file_info:若存在记录,返回"文件已存在",实现秒传
- 查询upload_task:若找到对应任务,返回uploadId,表明上传中断
- 查询upload_chunk:统计已上传分片,返回未完成分片索引列表
前端获取这些信息后,从中断点继续传输,避免重复操作。
前端续传流程
前端获取旧uploadId和未完成分片列表后,跳过已上传分片,继续调用/upload/chunk上传剩余部分。上传过程中,每个分片状态实时更新至upload_chunk表,upload_task表的uploaded_chunks同步增加。全部分片上传完成后,任务自动进入MERGING状态。
续传过程本质是基于数据库状态的增量上传,用户无感知,系统自动恢复进度。
状态恢复判断
任务恢复权限基于upload_task.status判断:
| 状态 |
可恢复性 |
说明 |
| WAITING |
可恢复 |
任务刚创建,未开始传输 |
| UPLOADING |
可恢复 |
上传进行中,可继续 |
| PAUSED |
可恢复 |
用户主动暂停,可恢复 |
| FAILED |
可恢复 |
上传失败,可重新尝试 |
| CANCELED |
不可恢复 |
用户主动取消,不再恢复 |
| COMPLETED |
不需要 |
已完成,直接秒传 |
| MERGING |
等待中 |
系统合并中,前端等待 |
此判断逻辑确保任务行为清晰可控。用户暂停后返回可直接恢复,取消任务则不再自动续传。
集群部署兼容性
集群部署环境下,上传中断后续传可能请求到不同机器。因所有任务和分片状态持久化在数据库,不依赖内存或本地文件,即使上次上传在A机器,本次续传到B机器,系统仍能通过数据库记录识别uploadId下的分片状态,确保集群环境无缝续传。
机制优势
整个恢复机制依赖upload_task和upload_chunk两张表。upload_task记录任务总体进度,upload_chunk记录每个分片上传状态。用户重新上传时,系统查询进度状态,前端从断点继续,实现真正意义上的断点续传。
优势包括:
- 上传进度可追踪
- 中断后可恢复
- 支持集群部署
- 不依赖浏览器缓存或Session
只要数据库记录完整,上传进度即可恢复,跨设备、重启系统均不受影响。
文件合并与完整性校验
所有前期准备都是为了最终的文件合并环节。将分片拼接为完整文件并确保内容准确无误,是大文件上传流程中最易出错的阶段。特别是在集群部署环境中,若分片分布在不同机器,合并逻辑需特殊处理。
合并触发机制
前端检测所有分片上传完成后调用/upload/merge接口,通知后端开始合并操作。后端接收请求后验证关键信息:
- uploadId对应任务是否存在
- upload_chunk表中所有分片是否均为"已上传"状态
- 任务状态是否允许合并
验证通过后,任务状态从UPLOADING变更为MERGING,进入文件合并阶段。
本地合并流程
配置本地存储时(cloud.enable = false),所有分片文件保存在服务器临时目录。
合并逻辑:
- 按chunk_index顺序读取每个分片文件
- 流式写入新目标文件(如merge.zip)
- 每合并一个分片更新数据库状态
- 合并完成后更新任务状态为COMPLETED,记录最终路径
注意事项:
- 写入顺序严格按分片索引,防止内容错乱
- 使用流式写入(Stream)避免内存溢出
合并完成后计算文件MD5,与原始fileHash对比。不一致时标记任务为FAILED,记录异常日志。
云端合并方案
配置云存储(OSS、COS、MinIO等)时,分片文件上传至云端对象存储桶。此场景下无需本地拼接文件,直接调用云服务分片合并API。
以OSS为例:
- 上传阶段调用uploadPart接口
- 合并阶段调用completeMultipartUpload API
- 云端按上传时分片顺序自动合并为完整对象
优势:
- 不占用本地磁盘空间
- 不受单机IO限制
- 云端自动校验分片完整性
云存储场景仅需:
- 通知云服务执行合并
- 成功后记录storage_url到数据库
集群环境解决方案
单机环境下合并简单直接,所有分片位于本地目录。集群部署时,分片请求可能分发到不同节点,导致分片文件分散存储。
三种解决方案:
方案1:共享存储(推荐私有化部署)
所有机器上传目录指向共享路径(NFS、NAS或对象存储挂载至/data/uploads)。无论用户请求分发到哪台机器,分片均写入同一物理目录。合并请求可由任意节点处理,访问完整分片文件。这是企业部署中最稳定通用的方案。
方案2:云存储中转
机器间无共享目录时,分片先上传至云端,合并时调用云服务API。适用于公网SaaS环境,政企内网部署可能受限。
方案3:统一调度节点
自定义合并调度节点,所有分片上传完成后,合并任务分配至指定节点执行。该节点通过HTTP内部传输或RPC从其他机器拉取分片。适合大规模分布式存储场景,实现复杂度较高。
私有化项目通常采用方案1——共享目录+本地合并,兼顾性能与安全性。
完整性校验机制
文件合并完成后执行完整性校验。重新计算合并文件的MD5,与前端原始fileHash对比。一致则合并成功,内容完整;不一致则分片损坏或顺序错误,任务标记为FAILED,记录错误日志。确保后续AI解析或向量化阶段内容准确性。
异步处理优化
演示视频中采用同步执行方式,从前端上传分片到文件合并完成全程等待。虽然演示直观,但实际项目问题显著。
核心问题:耗时过长。1GB文件在稳定网络和服务器性能下仍需数分钟,若前端持续等待响应,可能遭遇接口超时、连接断开或页面刷新等问题。
业务系统中,通常将合并、校验、迁移OSS或解析入库操作改为异步任务。接口仅负责接收分片、登记状态,立即返回"任务已创建"或"上传完成,处理中"提示。后续操作交由后台异步线程、任务队列或调度器执行。
优势:
- 前端体验流畅,无"等待合并"卡顿
- 后端批量处理任务,降低高峰期IO压力
- 任务失败或中断时可重试补偿
- 自然衔接外部存储或AI解析流程
本质上,上传仅是第一步,合并、校验、转存等操作属后台任务。系统设计时分离这些环节,保持接口轻量,确保大文件复杂场景下的系统稳定性。
方案总结
合并与校验阶段是前期分片上传工作的收尾环节。通过以下机制保证稳定性:
- 本地存储:顺序读取+流式写入+hash校验
- 云存储:依赖云端分片合并API
- 集群环境:共享存储或统一调度解决文件分散
- 数据库:实时状态记录,支持追踪审计
文件合并成功、校验通过后,系统将结果写入file_info表,完成完整上传链路闭环。
架构总结
常规项目中文件上传功能通常简单直接,前端传OSS,后端存地址即可。但私有化项目环境要求截然不同,需综合考虑断点续传、任务恢复、集群部署、权限控制和审计追踪等要素。
本套设计通过明确接口职责、状态追踪和恢复机制,有效解决实际业务问题。接口数量稍多但职责清晰,任务状态全程可追踪,上传中断智能恢复,未来可独立抽离为文件系统模块。无论是知识库构建、AI向量化还是文档解析,这套架构都能稳定复用。
许多看似简单的功能在复杂场景下需重新设计,但一旦打通,就能长期稳定服务。大文件上传完整流程的实践经验,为后续类似需求提供了可靠技术基础。

 发表于 2025-12-1 09:12:07
|
查看: 163|
回复: 0
发表于 2025-12-1 09:12:07
|
查看: 163|
回复: 0
