一、概述
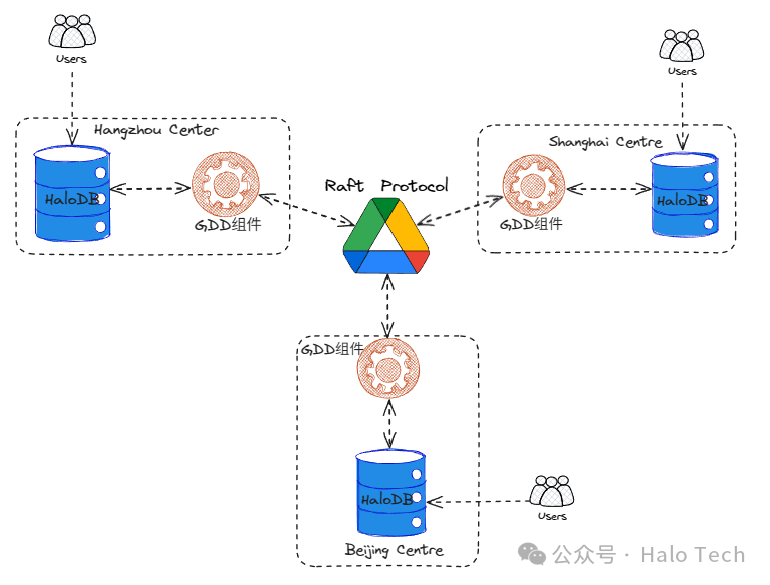
在 GDD (Global Distributed Database) 同步架构中,所有参与节点均支持读写请求,以多主模式运行。这种架构从根本上解决了传统高可用架构中常见的单点故障风险、数据同步延迟、写性能瓶颈以及扩展性有限等关键问题。它通过在高可用性、容错性、负载均衡、性能优化、可扩展性、地理分布及数据冗余等方面的全面提升,成功突破了传统架构的局限性。
| 特性 |
优势 |
解决的问题 |
| 高可用性与容错性 |
多节点同时活跃,单点故障不影响整体服务,减少停机时间 |
单点故障,主节点宕机导致业务中断 |
| 负载均衡与性能优化 |
读写操作可分散到多个节点,避免单点过载,提升并发处理能力 |
主节点易成为性能瓶颈,尤其是高写入场景 |
| 可扩展性与横向扩展 |
动态添加节点,轻松应对数据增长,扩展不影响现有业务 |
传统主从架构扩展受限,主节点性能制约整体吞吐量 |
| 地理分布与数据冗余 |
全球多节点部署,降低访问延迟,提升灾难恢复能力 |
传统架构跨地域访问延迟高,数据冗余策略不够灵活 |
| 资源利用率低 |
每个节点都可以进行读写操作,提高了资源利用率 |
传统架构中从节点在正常情况下主要负责读操作,资源利用率可能较低 |
| 数据一致性 |
自动冲突解决,确保数据一致性 |
数据一致性依赖主从同步,可能有延迟 |
二、架构
三、进程
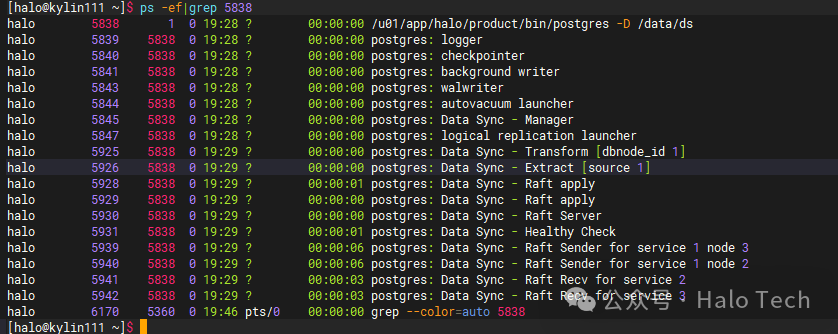
同步的核心原理是:将业务数据库实例的 WAL 日志拉取到本地,由 DS 扩展基于元信息进行解码,然后将解码后的 SQL 以事务块为单位回放到其他节点。
| 进程 |
作用 |
| Data Sync - Manager |
管理进程,控制各个ds进程的启动与状态管理 |
| 启动同步后的进程 |
|
| Data Sync - Raft Server |
接收各个raft节点的投票信息 |
| Data Sync - Raft Sender |
raft日志发送进程,将本地解码进程产生的raft日志发送到其他DS组件 |
| Data Sync - Raft Recv |
raft日志接收进程,负责从其他节点接收raft日志 |
| Data Sync - Raft apply |
数据回放进程,读取raft日志中的数据信息,并将数据应用到业务库中 |
| Data Sync - Healthy Check |
健康检查进程,监控各个ds节点状态,适时发起竞选 |
| Data Sync - Extract [source 1] |
拉取日志进程,负责从业务库拉取WAL日志文件 |
| Data Sync - Transform [dbnode_id 1] |
解码进程,负责解码接收到的WAL日志,并将解码结果转存为raft日志 |
四、GDD安装部署
4.1 部署
以3台服务器为例,每台服务器上部署一个DB节点(业务数据库)和一个DS节点(数据同步节点)。
| 服务器 |
DB_PORT |
DS_PORT |
| 192.168.10.111 |
1921 |
1999 |
| 192.168.10.112 |
1921 |
1999 |
| 192.168.10.113 |
1921 |
1999 |
4.2 初始化DB、DS数据库实例
在每台服务器上分别执行以下命令,初始化数据库数据目录。
pg_ctl init -D /data/db
pg_ctl init -D /data/ds
4.3 DB业务库配置参数及白名单
以下配置需要在3台服务器的DB节点上分别执行。
#postgresql.conf文件配置
pg_conf=/data/db/postgresql.conf
cat <<EOF >>${pg_conf}
port=1921
wal_level = logical # 支持同步的前提
wal_keep_size = 1000 # 单位为MB
EOF
#pg_hba.conf文件配置
#DB需配置DS库的连接权限
pg_hba_conf=/data/db/pg_hba.conf
cat <<EOF >>${pg_hba_conf}
host all all 0/0 md5
host replication all 0/0 md5
EOF
配置完成后,需要重启DB数据库服务。
由于当前版本仅支持数据同步(DML),DDL同步暂不支持,因此需要提前在三台DB库中手动创建测试表结构。
create schema sc;
create table sc.t_txn (
id numeric primary key,
val varchar(30)
);
4.4 DS同步节点配置参数及白名单
以下配置需要在3台服务器的DS节点上分别执行。
#postgresql.conf文件配置
pg_conf=/data/ds/postgresql.conf
cat <<EOF>>${pg_conf}
port=1999
data_sync.raft_mode = 'on' #是否运行raft模式
data_sync.raft_port = '5433' #raft服务端口号
#data_sync.pipeline_apply = on #默认为off。开启后会提升回放速度,但会占用一部分业务数据库内存
shared_preload_libraries = 'data_sync'
wal_level = logical
wal_keep_size = 1000
max_worker_processes = 128 #ds同步所有的进程包含在内,如超过128同步可能报错
EOF
#pg_hba.conf文件配置
#DS库需配置其他DS库的连接权限,不需要配置流复制权限
pg_hba_conf=/data/ds/pg_hba.conf
cat <<EOF >>${pg_hba_conf}
host all all 0/0 md5
EOF
以上配置完成后,需重启DS同步节点实例。
4.5 创建ds.toml配置文件
ds.toml 文件需要放在 ds_cli 命令所在的相同路径下,通常只需在其中一台服务器上创建即可(除非计划在其他服务器上也运行 ds_cli)。
cat << EOF >>/u01/app/halo/product/bin/ds.toml
#配置文件ds.toml
DS_APP_PATH="/u01/app/halo/product/bin" #ds程序目录
DS_RUN_PATH="/data/ds" #ds运行数据目录
M_SSH_PORT="22" #各个节点的ssh端口
M_USER="halo" #操作系统用户名称
# DS节点配置
DS_NODE = [
{ nodeid = "ds_node1", host = "192.168.10.111", port = 1999, user = "dbadmin", password = "123456", raft_port = 5433},
{ nodeid = "ds_node2", host = "192.168.10.112", port = 1999, user = "dbadmin", password = "123456", raft_port = 5433},
{ nodeid = "ds_node3", host = "192.168.10.113", port = 1999, user = "dbadmin", password = "123456", raft_port = 5433}
]
# 数据库节点配置
DB_NODE = [
{ nodeid = "db_node1", host = "192.168.10.111", port = 1921, user = "dbadmin", password = "123456", ds_node = "ds_node1" },
{ nodeid = "db_node2", host = "192.168.10.112", port = 1921, user = "dbadmin", password = "123456", ds_node = "ds_node2" },
{ nodeid = "db_node3", host = "192.168.10.113", port = 1921, user = "dbadmin", password = "123456", ds_node = "ds_node3" }
]
# dbring 配置 - 使用数组格式而不是表格格式
DBRING = [
{ name = "dbring1", ring = [{ node = "db_node1", dbname = "postgres" }, { node = "db_node2", dbname = "postgres" }, { node = "db_node3", dbname = "postgres" }] }
]
# TABLE 配置
TABLE = [
{ ring = "dbring1", schema = "sc", tablename = "t_txn", source = "db_node1" }
]
EOF
4.6 初始化DS节点
在创建了 ds.toml 文件的服务器上执行初始化命令。初始化过程会在所有DS实例中创建 datasync 数据库,并在该库中安装 data_sync 扩展,该扩展包含了节点服务状态表、同步状态函数等核心对象。
[halo@kylin111 bin]$ ds_cli --install --config ds.toml
❇️: 在节点 ds_node1 上安装DS扩展...
数据库 datasync 在节点 ds_node1 上已存在
✅ 成功: 在节点 ds_node1 的datasync数据库成功安装DS扩展 data_sync
数据库 datasync 在节点 ds_node2 上已存在
✅ 成功: 在节点 ds_node2 的datasync数据库成功安装DS扩展 data_sync
数据库 datasync 在节点 ds_node3 上已存在
✅ 成功: 在节点 ds_node3 的datasync数据库成功安装DS扩展 data_sync
✅ 成功: DS扩展安装成功
❇️: 开始初始化DS系统...
✅ 成功: DS系统初始化成功
4.7 启动同步服务
启动同步服务,可以通过查看DS库的日志来观察启动过程。
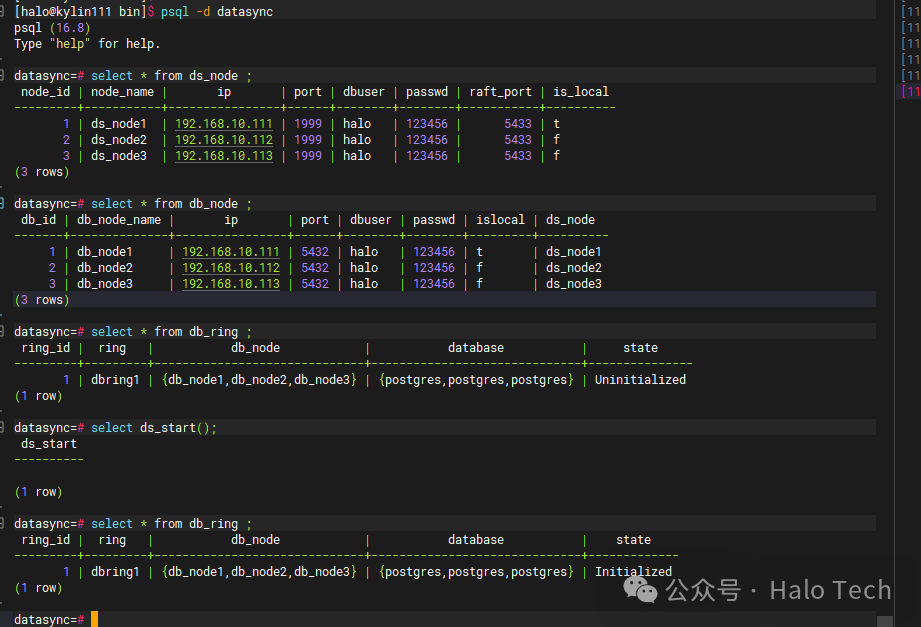
[halo@kylin111 bin]$ psql -d datasync -p 1999
datasync=# select ds.ds_start();
ds_start
----------
(1 row)
datasync=# select * from ds.db_ring ;
ring_id | ring | db_node | database | state
---------+---------+------------------------------+------------------------------+-------------
1 | dbring1 | {db_node1,db_node2,db_node3} | {postgres,postgres,postgres} | Initialized
(1 row)
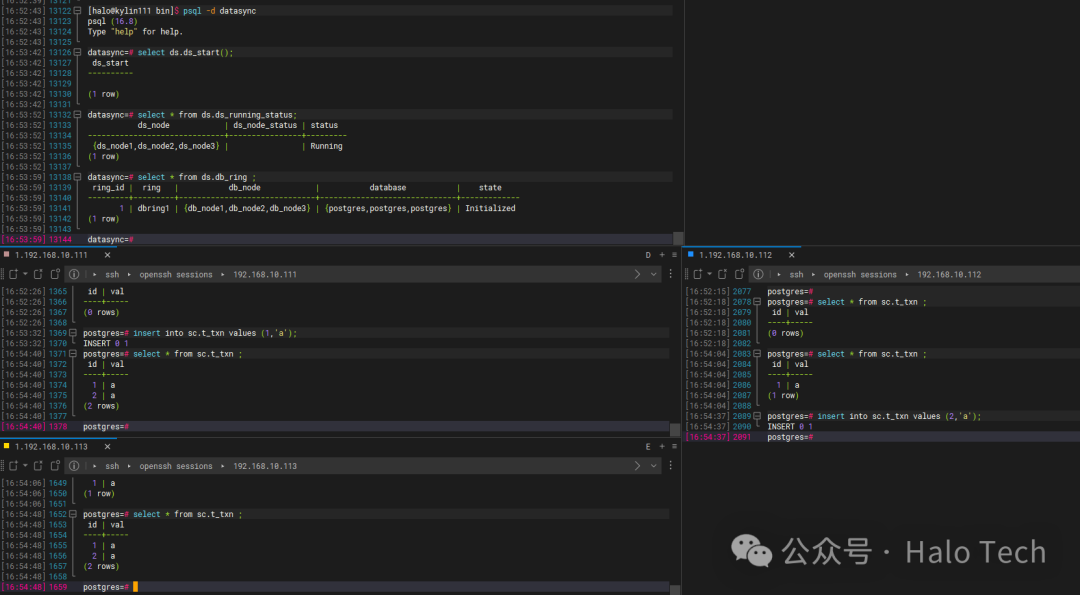
4.8 验证同步
在配置的DB业务库对应表中执行写入操作,验证数据是否成功同步到其他节点。
4.9 启动同步后,为现有表添加同步
如果同步服务启动后,需要将已有的新表纳入同步范围,可以使用命令行工具进行注册。
ds_cli --register-table --ring dbring1 --schema sc --tablename test
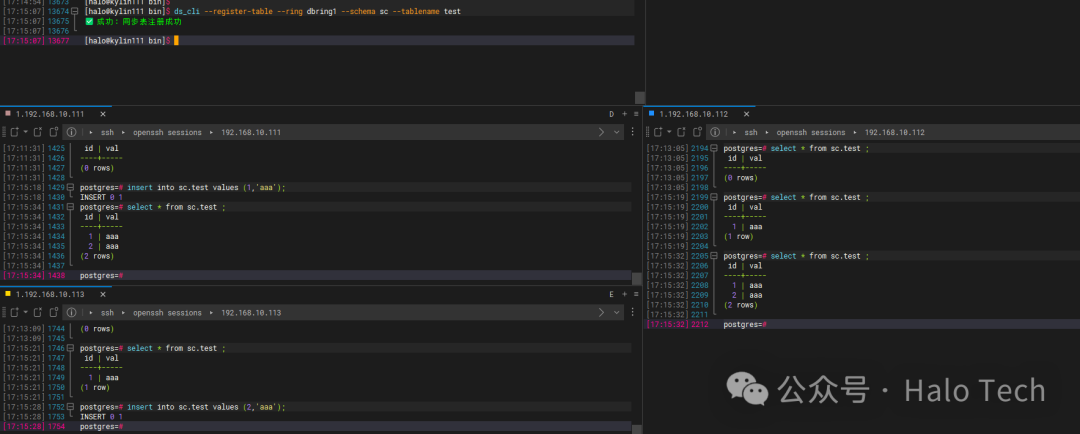
4.10 启动同步后,创建新表再添加同步
也可以在启动同步后创建新表,然后通过SQL函数将其注册为同步表。
psql -d datasync
SELECT DS.DS_SYNC_RING_METADATA('dbring1');
SELECT DS.DS_REGISTER_TABLE('dbring1','sc','t222');
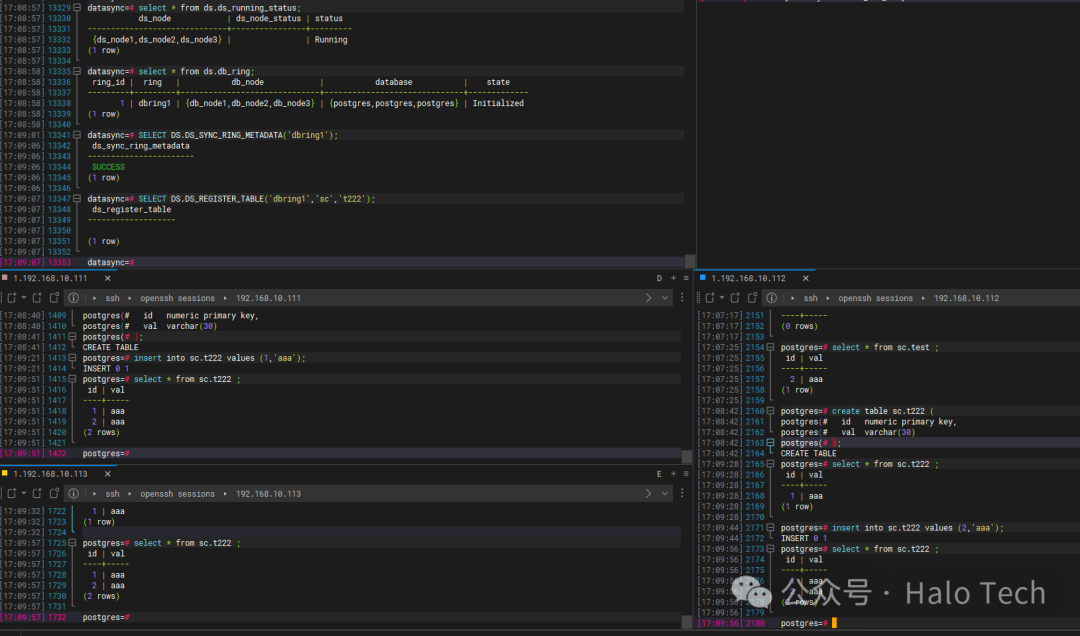
4.11 停止同步服务
当需要维护或停止同步时,可以执行停止操作。
[halo@kylin111 ~]$ psql -d datasync
psql (16.8)
Type "help" for help.
datasync=# select * from ds.ds_running_status;
ds_node | ds_node_status | status
------------------------------+----------------+---------
{ds_node1,ds_node2,ds_node3} | | Running
(1 row)
datasync=# select ds.ds_stop();
ds_stop
---------
(1 row)
datasync=# select * from ds.ds_running_status;
ds_node | ds_node_status | status
------------------------------+----------------+---------
{ds_node1,ds_node2,ds_node3} | | Stopped
(1 row)
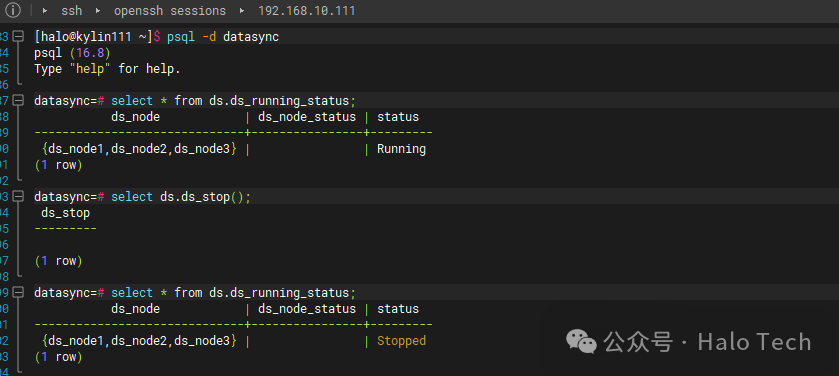
4.12 DS清理还原
此操作用于清理环境,包括:清理DB业务库中的origin表、清理DS数据目录下生成的配置文件、清理datasync库中的扩展和表信息。
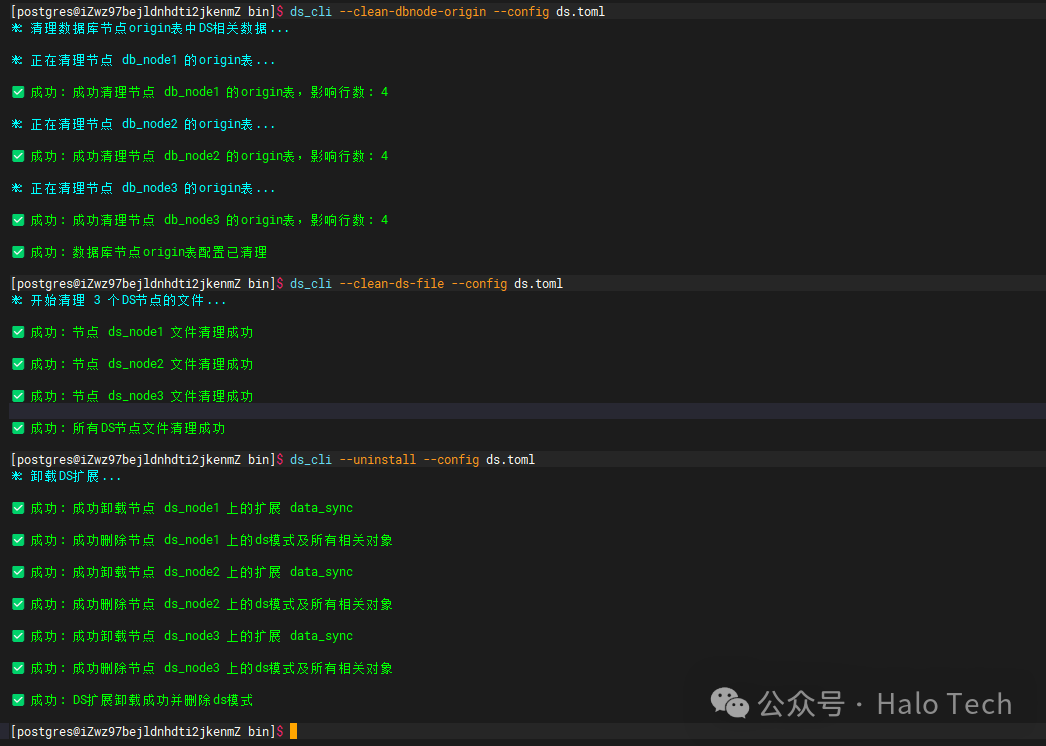
五、常用视图
5.1 DS节点状态相关
查看节点运行状态
datasync=# select * from ds.raft_node_view();
nodeid | node_name | running
--------+-----------+---------
1 | ds_node1 | t
2 | ds_node2 | t
3 | ds_node3 | t
(3 rows)
datasync=# select * from ds.raft_service_view();
serviceid | primary_node_id
-----------+-----------------
1 | 1
2 | 2
3 | 3
(3 rows)
5.2 同步状态相关视图
查询WAL接收速度
datasync=# select * from ds.get_wal_recv_info(1);
wal_speed | recv_lsn
-----------+-----------
0 | 0/154F7D0
(1 row)
Wal_speed: 接收wal的速度,单位byte/srecv_lsn:接收到最新lsn
查询解码速度
datasync=# select * from ds.get_decode_info(1);
decode_speed | decode_lsn | recv_lsn | lsn_gap
--------------+------------+-----------+---------
0 | 0/154F7D0 | 0/154F7D0 | 0
(1 row)
decode_speed: 解码wal的速度,单位byte/sdecode_lsn: 当前解码的lsn位点recv_lsn: 当前接收到的最新lsnlsn_gap: recv_lsn和decode_lsn的差值
查询当前xs位点
datasync=# select ds.get_current_xsln();
get_current_xsln
-------------------
0/D7
(1 row)
查询接收xslsn速度
datasync=# select * from ds.get_xs_recv_info(1);
nodeid | xs_speed | recv_xsln
--------+----------+------------
1 | 0 | 0/1
2 | 0 | 0/276
3 | 0 | 0/205
(3 rows)
nodeid: 节点idxs_speed: 接收解码结果的速度recv_xsln: 当前接收的最新xslsn
查询apply的速度
datasync=# select * from ds.get_xs_apply_info(1);
nodeid | apply_speed | apply_xsln | recv_xsln | xsln_gap
--------+-------------+------------+-----------+----------
1 | 0 | 0/D7 | 0/D7 | 0
2 | 0 | 0/34C | 0/34C | 0
3 | 0 | 0/2DB | 0/2DB | 0
(3 rows)
nodeid: 节点idapply_speed: apply解码结果的速度apply_xsln: 当前apply的位点recv_xsln: 当前接收的最新xslsn位点xsln_gap: recv_xsln和apply_xsln的差值
六、工具
6.1 ds_cli 管理工具
ds_cli 是主要的命令行管理工具,涵盖了安装、初始化、启停、表注册等全生命周期操作。
usage: ds_cli [-h] [--config CONFIG] [--check] [--install] [--uninstall] [--start] [--stop] [--init] [--sql SQL]
[--show-config SHOW_CONFIG] [--clean-dbnode-origin] [--clean-ds-file] [--connect CONNECT] [--restart-dsnode]
[--register-table] [--unregister-table] [--ring RING] [--schema SCHEMA] [--tablename TABLENAME]
DS 命令行管理工具
optional arguments:
-h, --help show this help message and exit
--config CONFIG 配置文件路径 (默认: ds.toml)
--check 检查配置文件有效性
--install 安装DS扩展到默认实例
--uninstall 从默认实例卸载DS扩展
--start 启动DS系统
--stop 停止DS系统
--init 使用配置初始化DS系统
--sql SQL 执行SQL语句
--show-config SHOW_CONFIG 显示配置信息,参数可以是: all, ds, db, dbring, table
--clean-dbnode-origin 清理数据库节点origin表中DS相关数据
--clean-ds-file 清理DS系统文件
--connect CONNECT 指定要操作的实例ID, 结合--sql参数使用
--restart-dsnode 重启所有ds节点
--register-table 注册同步表
--unregister-table 删除同步表
--ring RING 指定DBRING名称
--schema SCHEMA 指定表的schema
--tablename TABLENAME 指定表名
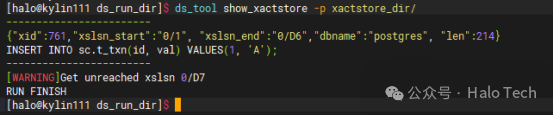
ds_tool 用于分析和诊断,例如查看事务存储内容。
[halo@kylin111 bin]$ ds_tool
--------------------------
USAGE:
ds_tool command options
--------------------------
COMMAND:
show_xactstore
show_duration
OPTION(show_xactstore):
--p the path to show
--s the start xsln
--e the end xsln
OPTION(show_duration):
--p the path to show
--------------------------
ERROR:Wrong command
通过上述实战部署与操作,我们可以看到,基于GDD和PostgreSQL构建的分布式系统能够有效实现多活数据同步,为企业级应用提供了高可用、高性能的数据层解决方案。这种架构尤其适用于对数据一致性、服务可用性和横向扩展有较高要求的场景。
 发表于 2026-1-22 23:14:20
|
查看: 172|
回复: 0
发表于 2026-1-22 23:14:20
|
查看: 172|
回复: 0
