日志在系统开发和运维过程中扮演着极其重要的角色。无论是定位线上问题、分析异常行为,还是复盘一次生产事故,日志往往是还原现场、定位问题的首要依据。很多时候,系统“看不见”的地方,最终只能通过日志来一探究竟。
门面模式:SLF4J
日志框架能够帮助我们快速定位错误并进行有效的故障排查。你可能听说过一些与日志框架相关的名词,比如 slf4j、log4j、logback和 JDK Logging ,但它们之间到底是什么关系可能会让人感到困惑。
SLF4J 是一个日志框架的简单门面,它提供了一个统一的日志接口,使得开发者可以在应用中使用统一的 API。SLF4J 本身并不提供日志的实现,而是通过与其他日志框架(如 Log4j、Logback 等)结合使用,来实现日志记录的功能。
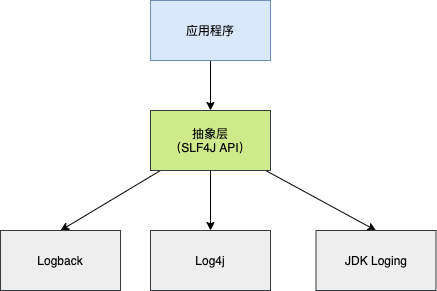
图中,Logback、Log4j 都是具体的日志框架,每种框架都有自己单独的 API。如果直接使用这些 API,就会大大增加应用程序代码与特定日志框架的耦合性。
为了解决这个问题,就是在日志框架和应用程序之间架设一个沟通的桥梁——门面。对于应用程序来说,无论底层的日志框架如何变化,都不需要有任何感知。只要门面服务做得足够好,随意更换另外一个日志框架,应用程序无需修改任何一行代码。
在短信平台 SDK 模块里,我们并没有直接依赖具体的日志框架,而是仅仅依赖 SLF4J。
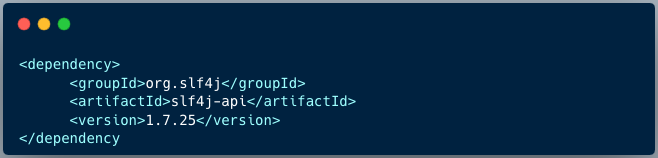
SDK 中需要打印日志的类会定义日志对象 Logger:
private final static Logger logger = LoggerFactory.getLogger(SmsSenderClient.class);
下图是代码简化图,Logger 对象定义了不同级别的日志输出方式。
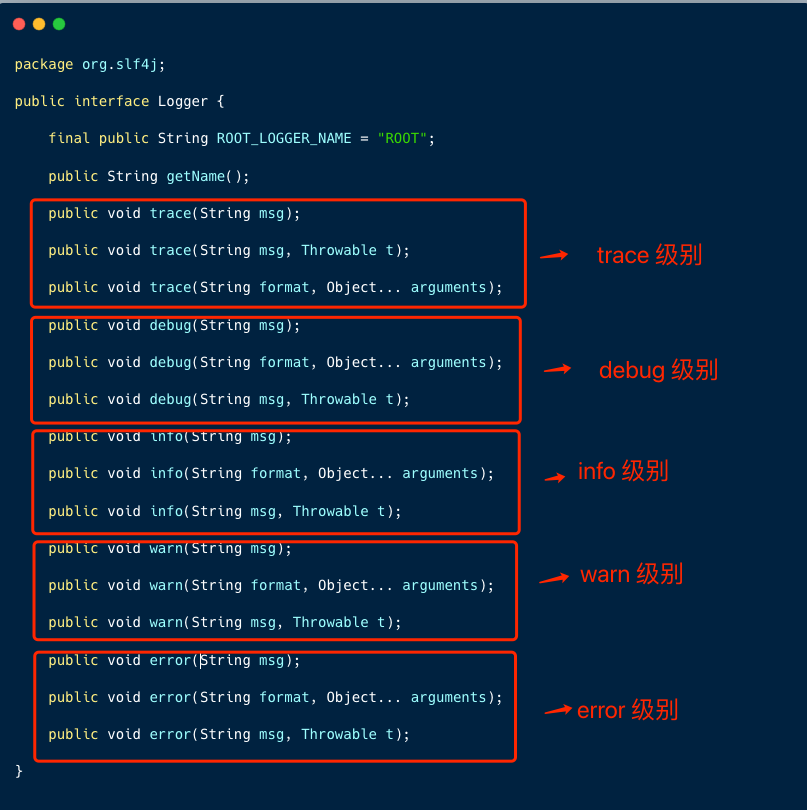
在业务应用中,我们一般使用 debug(调试)、info(信息)、warn(警告)、error(错误)这几个级别,等级由低到高。
我们开发测试时一般输出 DEBUG 级别的日志,便于调试;而在生产环境,通常会配置为只输出 INFO 级别甚至只输出 ERROR 级别的日志,以减少日志量并关注核心问题。
Spring Boot 与 Logback
Spring Boot 默认集成的日志框架是 SLF4J + Logback。官方推荐优先使用带有 -spring 后缀的文件名作为日志配置文件(如使用 logback-spring.xml,而不是 logback.xml),并将 XML 文件放在 src/main/resources 目录下。
下图是一个基础的 Logback 配置文件示例:
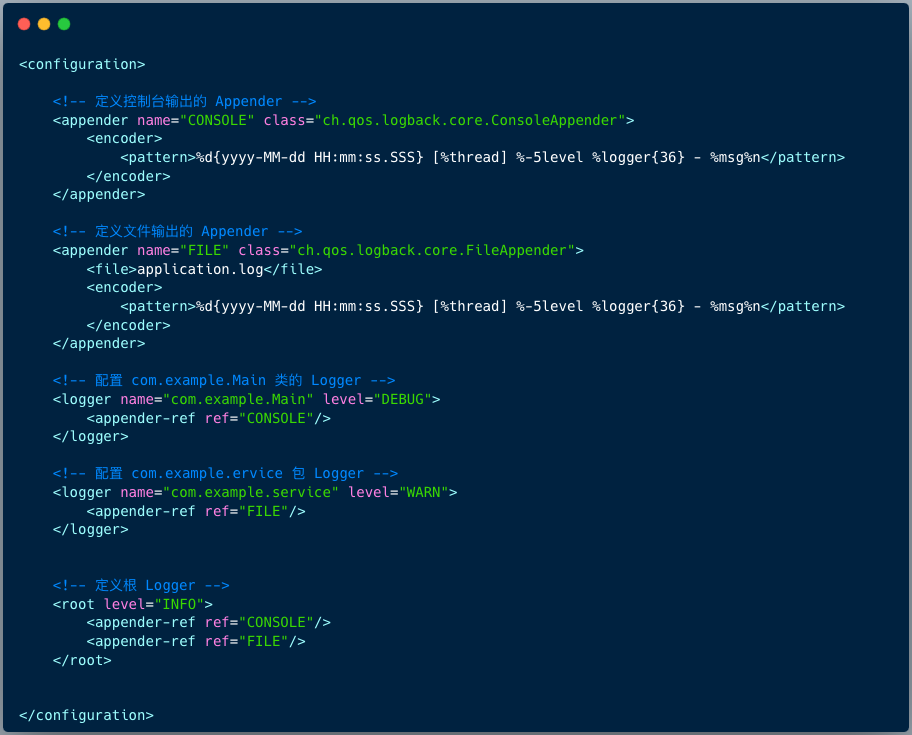
在 Logback 日志框架的配置中,有三个核心元素:appender、logger 和 root。
1. Appender(输出器):用于指定日志输出目的地的组件。上面的配置定义了两个输出器,一个用于控制台输出(CONSOLE),另一个用于文件输出(FILE)。
2. Logger(记录器):用于记录日志事件的组件,负责接收应用程序中产生的日志事件并将它们传送到相应的 Appender。
- 对于
com.example.Main 类,将其日志级别设置为 DEBUG,这意味着只有 DEBUG 级别及以上的日志事件才会被记录,并且仅会输出到控制台。
- 对于
com.example.service 包,将其日志级别设置为 WARN。只有 WARN 级别及以上的日志事件才会被记录,并且仅会输出到文件。
3. Root(根Logger):这是所有日志记录器树结构的根节点。我们将根 Logger 的日志级别设置为 INFO,并将其绑定到 CONSOLE 和 FILE 两个输出器。这意味着所有未特别指定 Logger 的日志事件都将遵循此配置。
Logback 配置实战参考
下图是一个短信服务实际使用的 Logback 配置文件:
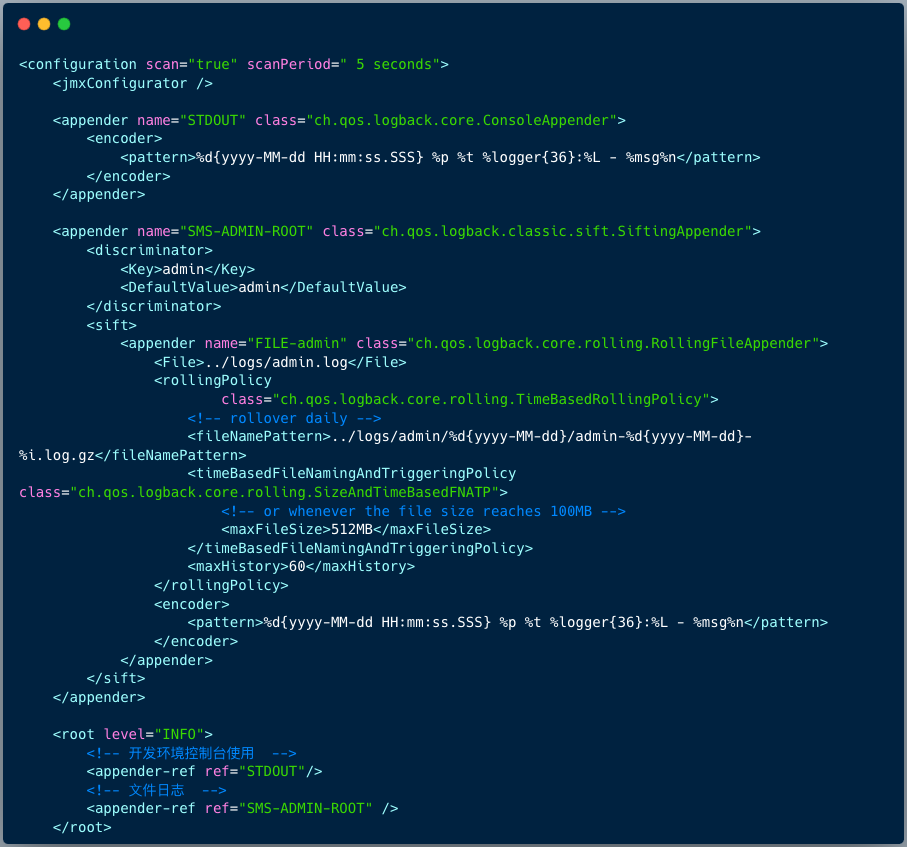
这个配置中有两个关键点值得关注:
1. 日志格式
我们定义了两个 Appender,分别输出到控制台和文件,它们使用了统一的日志格式:
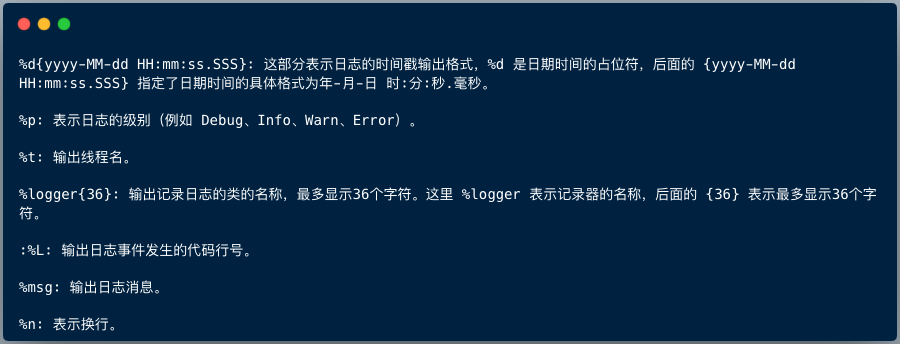
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %p %t %logger{36}:%L - %msg%n</pattern>
这个格式中各个占位符的含义如下:
服务启动后,输出的日志格式如下图所示:

从启动日志中,我们可以清晰地看到线程名、类名以及代码行号,这在定位复杂问题时非常有用。
2. 备份历史文件
由于本地磁盘容量有限,我们不可能永久保存所有日志文件。笔者曾遇到过因 Log4j 日志文件写满磁盘,导致 Tomcat 所有线程阻塞的场景。通过 jstack 命令定位,发现线程阻塞在 Log4j 写日志的代码上。
因此,合理的配置文件的保留策略至关重要。我们可以设置当日志文件大小达到指定阈值,或按天生成新日志文件时进行滚动备份,并只保留最近一定数量的历史文件。
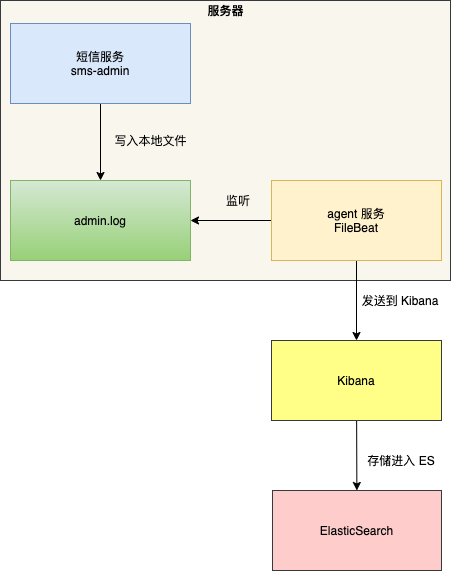
有同学可能会问:那全量的日志数据去哪查呢?我们可以在服务器上部署 Filebeat 等日志采集代理,将日志实时发送到 Elasticsearch 或其他存储系统进行集中管理和分析。
日志打印规范
掌握了框架和配置,日常开发中遵循良好的日志打印习惯同样重要。
1. 打印关键方法的入参和出参
核心接口及关键方法的入参和返回值,都建议打印日志。这对于追踪数据流向、复现问题场景至关重要。
2. 日志级别判断
这一条主要针对 debug 和 trace 这类低级别日志。为了避免在线上环境(日志级别为 INFO 或更高)中,仍然执行日志消息的字符串拼接操作(造成不必要的性能浪费),应先进行级别判断:
User user = new User(666L, "xxxx", "xxxx");
if (log.isDebugEnabled()) {
log.debug("userId is: {}", user.getId());
}
3. 坚持使用 SLF4J 的门面 API
再次强调,请务必使用 SLF4J 提供的 API 来打印日志,这能最大限度地降低应用程序与具体日志实现框架的耦合度。
4. 使用占位符{},而非字符串连接符+
使用占位符性能更高,代码也更优雅。
Object[] paramArray = {newVal, below, above};
logger.debug("Value {} was inserted between {} and {}.", paramArray);
5. 完整打印异常堆栈信息
下面的日志输出方式不规范,丢失了最重要的堆栈信息:
try {
//业务代码处理
} catch (Exception e) {
// 错误
LOG.error('你的程序有异常啦');
}
正确的做法是将异常对象作为最后一个参数传入:
try{
// 业务代码处理
}catch(Exception e){
log.error("你的程序有异常啦",e);
}
另外请注意,仅使用 e.getMessage() 不会记录详细的堆栈信息,只包含基本的错误描述,不利于排查复杂问题。
6. 禁止在线上环境开启 debug
除了业务代码可能产生大量 debug 日志,一些框架本身也可能输出 debug 日志。在线上环境开启 debug 级别,极易导致日志文件急剧膨胀,最终占满磁盘空间,并可能引发 CPU 和磁盘 I/O 瓶颈,直接影响系统稳定性。
7. 避免使用 e.printStackTrace()
使用 e.printStackTrace() 会将堆栈信息直接打印到标准错误输出(通常是控制台),这会与业务代码的日志交错混合在一起,格式不统一,给日志收集和排查带来不便。应始终使用日志框架的 API 来记录异常。
遵循以上这些规范和技巧,能让你打出的日志更具价值,在关键时刻成为定位问题的利器。如果你对更多后端开发与运维实践感兴趣,欢迎在云栈社区交流探讨。
 发表于 2026-1-24 08:08:26
|
查看: 138|
回复: 0
发表于 2026-1-24 08:08:26
|
查看: 138|
回复: 0
