Kubernetes(简称K8s)作为云原生技术的核心,正成为云计算发展的关键推动力。它是一个开源的容器编排平台,旨在自动化容器化应用程序的部署、扩展和管理。该项目最初由Google开源,目前由云原生计算基金会(CNCF)进行维护。
从工程实践的视角来看,Kubernetes 主要致力于解决以下几个核心问题:
- 容器调度问题:在拥有多个节点和大量容器时,如何实现资源的合理分配与自动调度。
- 应用生命周期管理:实现应用的自动化部署、升级、回滚、重启和销毁。
- 高可用与自愈能力:当节点故障或容器异常时,系统能够自动进行迁移与恢复,保障服务连续性。
- 弹性伸缩:根据业务负载自动扩容或缩容应用实例,实现资源的动态优化。
Kubernetes 核心架构
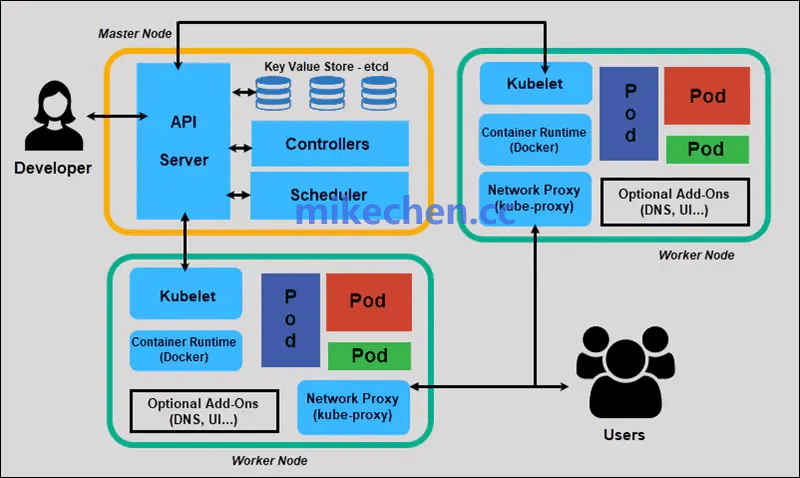
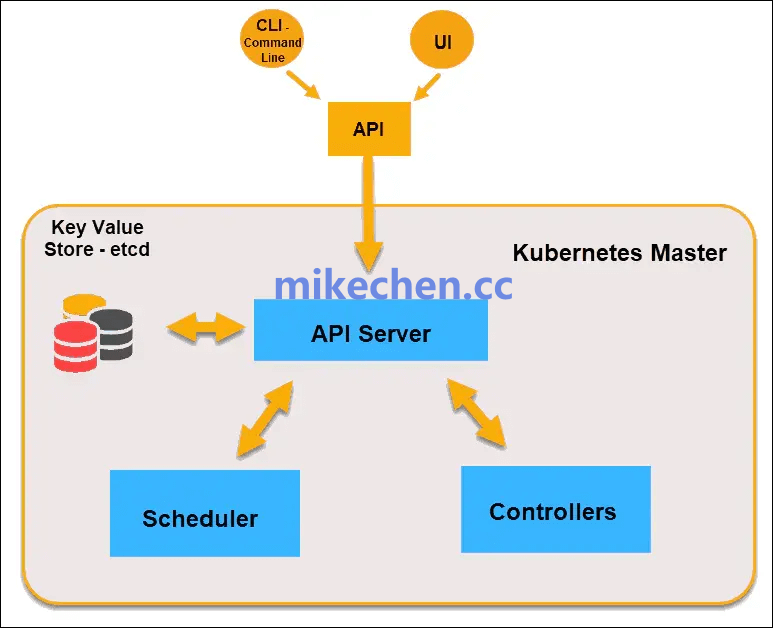
Kubernetes 采用了经典的主从式分布式架构,主要分为控制平面(Control Plane) 与节点(Node) 两大部分。
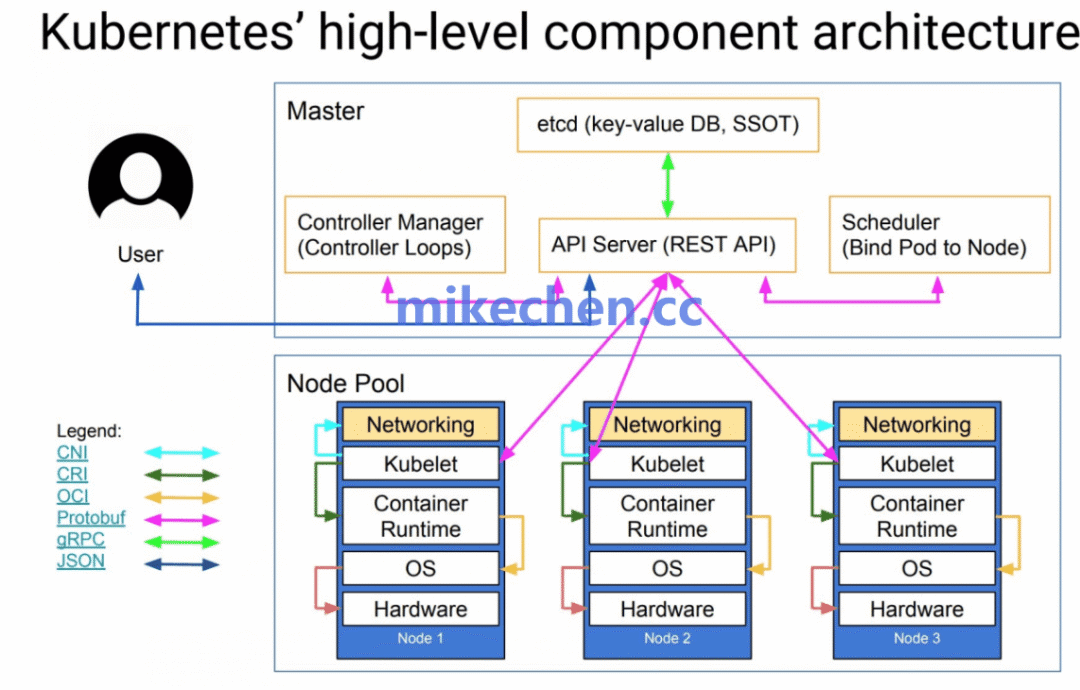
K8s 采用 Master / Worker(控制平面 / 数据平面) 架构。
┌───────────────────┐
│ Control Plane │
│ API Server │
│ Scheduler │
│ Controller Manager│
│ etcd │
└─────────▲─────────┘
│
┌─────────┴─────────┐
│ Worker Node │
│ kubelet │
│ kube-proxy │
│ Container Runtime │
│ Pods │
└───────────────────┘
- 控制平面:负责集群的全局管理与决策,通常运行在一个或多个主节点(Master Node)上。其关键组件包括 API Server、etcd、Controller Manager 与 Scheduler。
- 节点平面:由若干工作节点(Worker Node)组成,负责实际运行容器化的工作负载。每个节点上运行着 kubelet、容器运行时(如 containerd、Docker)以及 kube-proxy 等组件。
- etcd:作为分布式键值存储,它保存了整个集群的所有状态数据,提供了强一致性保证,是整个系统的权威数据源。
Kubernetes 核心组件详解
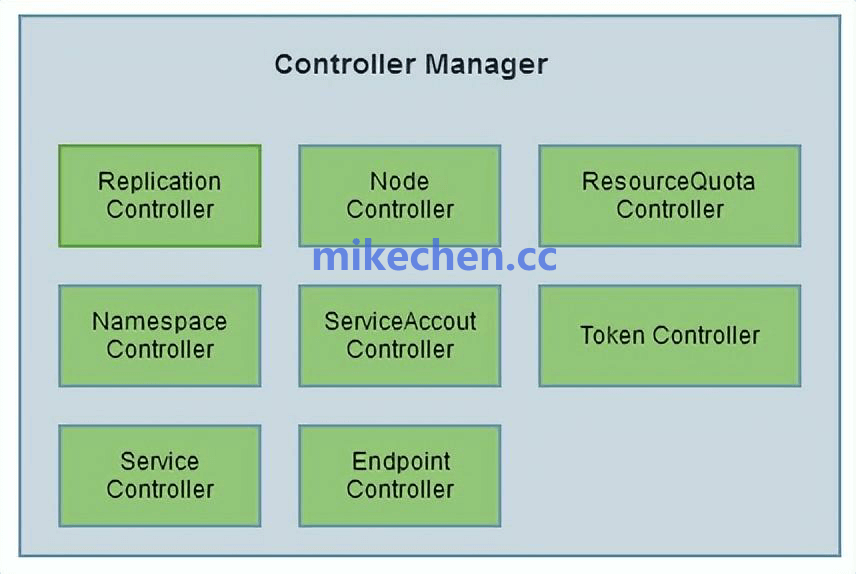
控制平面组件
- kube-apiserver:集群统一的 API 入口。所有内部组件和外部用户的请求都必须通过 API Server,它负责进行认证、授权与审计,并与 etcd 交互以持久化资源对象的状态。
- etcd:一个高可用的分布式键值存储,用于持久化存储 Kubernetes 集群的所有配置数据和状态信息。
- kube-scheduler:负责为新创建的 Pod 分配合适的节点。调度器基于 Pod 的资源需求、节点亲和性/反亲和性策略、污点和容忍度等约束条件做出决策。
- kube-controller-manager:运行着多种控制器,例如 Deployment Controller、ReplicaSet Controller、Node Controller 等。这些控制器通过控制循环不断监视集群状态,并与期望状态进行比对和调整,确保系统始终运行在预期轨道上。
节点组件
- kubelet:运行在每个工作节点上的代理。它负责管理节点上 Pod 的生命周期,包括 Pod 的创建、启动、停止,并向 API Server 报告节点和 Pod 的状态。
- kube-proxy:维护节点上的网络规则,实现了 Kubernetes Service 概念的负载均衡与服务发现。它确保 Pod 之间以及来自外部的网络通信能够正确路由。
- 容器运行时:负责实际拉取容器镜像、启动和停止容器进程的软件。常见的运行时包括 containerd、CRI-O 等,早期也广泛使用 Docker(通过 CRI 接口)。
Kubernetes 工作流程解析
为了更清晰地理解各个组件如何协同工作,我们可以通过一个典型的应用部署流程来串联它们。
假设我们要部署一个应用,其工作流程大致如下:
- 用户通过
kubectl 工具提交一个描述应用期望状态的 Deployment YAML 配置文件。
- API Server 接收请求,进行校验后,将资源对象的定义信息写入 etcd 存储。
- Deployment Controller(在 Controller Manager 中)监听到 etcd 中出现了新的 Deployment 对象,它会根据配置创建对应的 ReplicaSet 对象,并再次写入 etcd。
- ReplicaSet Controller 监听到新的 ReplicaSet,它的职责是确保指定数量的 Pod 副本在运行。它会创建 Pod 定义,并通过 API Server 写入 etcd。
- Scheduler 监听到 etcd 中出现了处于
Pending 状态的 Pod。它根据调度策略(资源、亲和性等)选择一个最合适的工作节点,并将绑定信息(Pod 与 Node 的映射)更新到 API Server,最终写入 etcd。
- 目标节点上的 kubelet 通过 API Server 监听到了分配给本节点的 Pod。它指示本地的容器运行时拉取所需的镜像,并启动容器。
- kube-proxy 感知到新的 Pod 被创建,它会更新本地的 iptables/IPVS 规则,以确保该 Pod 能够被 Service 正确地负载均衡和访问。
- 至此,应用成功启动并开始对外提供服务。
这个流程完美诠释了 Kubernetes 声明式 API 和控制器模式的精髓:用户只需声明“我想要什么”,系统各组件会自动协作,驱动整个集群达到并维持这个期望状态。
对于希望深入了解云原生和容器编排领域的朋友,可以访问 云栈社区 获取更多相关技术资源与讨论。 |  发表于 2026-1-24 13:14:46
|
查看: 277|
回复: 0
发表于 2026-1-24 13:14:46
|
查看: 277|
回复: 0
