近日,DeepSeek 团队工程师在 GitHub 上向他们的核心推理加速库 FlashMLA 推送了一系列更新。有趣的是,在这批提交的代码中,一个此前从未公开亮相的模型标识——“MODEL1”——意外地浮出水面,迅速在开发者社区中引发了诸多猜测与讨论。
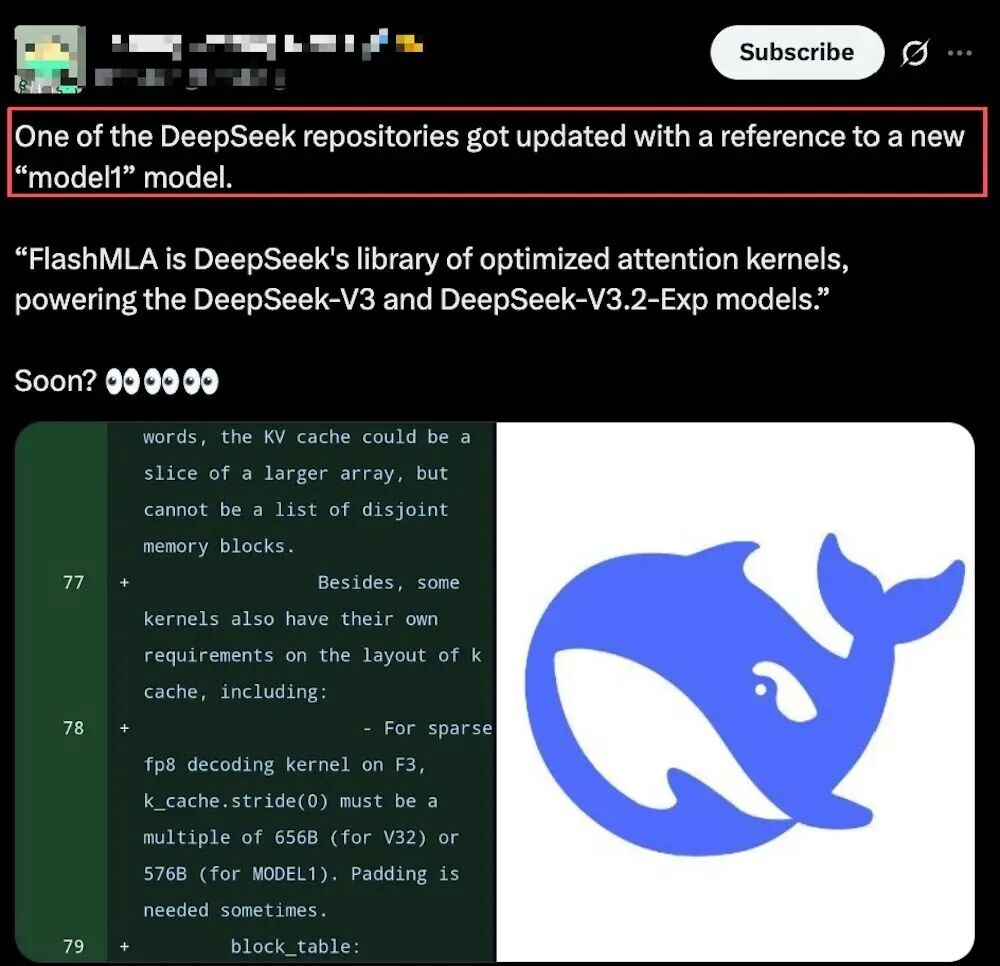
通过分析相关代码的上下文,“MODEL1”很可能代表着一个不同于现有 DeepSeek-V3.2(文中代码常简写为 V32)架构的全新模型。
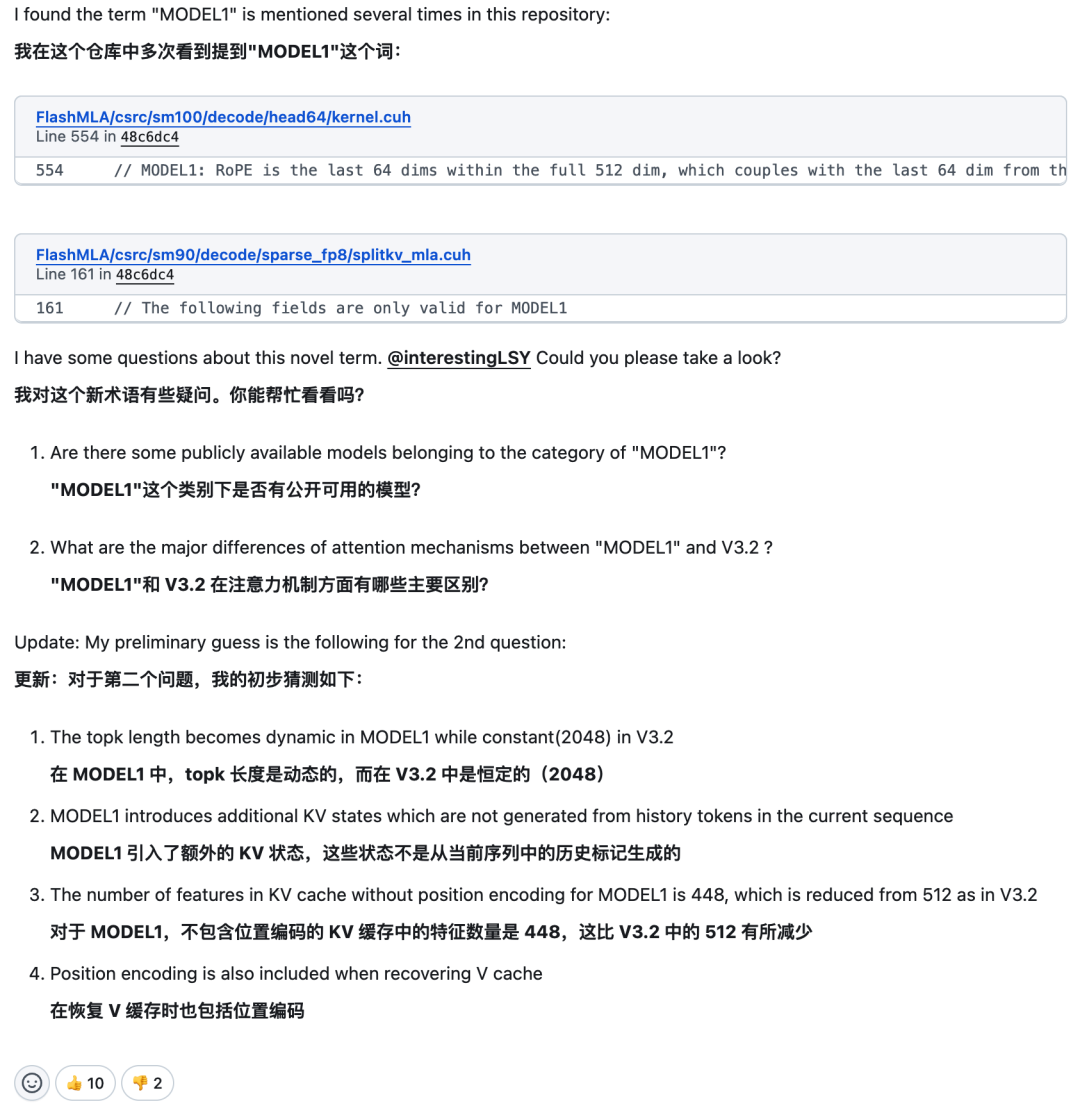
技术细节上的差异主要体现在键值缓存(KV Cache)的布局、对稀疏性的处理方式,以及对 FP8 数据格式解码的支持等多个方面。例如,在同一个内核函数中,针对“V32”和“MODEL1”模型,其 KV 缓存所需的填充和对齐要求都存在明确区分。这些差异似乎暗示,新架构可能针对内存利用效率和计算性能进行了更深度的定制化设计。
不少社区开发者根据这些线索展开推测:有人认为“MODEL1”可能就是传闻中正在内测的 DeepSeek V3 终极版本(甚至可能是 V4 模型),也有人猜测它或许是一个完全独立于现有 V 系列的全新模型线。
据悉,DeepSeek 工程师们这次的更新范围不小,涉及 114 个文件,其中有多达 28 处地方提到了“MODEL1”这个神秘的标识符。它经常与已知的“V32”模型被并列提及,用以区分不同的配置或实现路径。
下面这段来自 FlashMLA/csrc/sm90/decode/sparse_fp8/splitkv_mla.cuh 文件的代码片段就是一个直观的例子,它展示了根据模型类型(V32 或 MODEL1)来定义不同常量的逻辑:
```c++
static constexpr int QUANT_TILE_SIZE = MODEL_TYPE == ModelType::V32 ? 128 : 64;
static constexpr int NUM_SCALES = MODEL_TYPE == ModelType::V32 ? 4 : 8; // For MODEL1: 7 fp8_e4m3 + 1 padding
static constexpr int NUM_THREADS = 128*3;
static constexpr int BLOCK_M = 64;
static constexpr int TOPK_BLOCK_SIZE = 64;
static constexpr int NUM_K_BUFS = 2;
// 不同的模式(包括 fp8/bf16、稀疏性和模型版本,即 V3.2 或 MODEL1)具有不同的 KV 缓存布局。详见下文注释。
// - 对于 F3 架构上的 sparse fp8 解码内核,k_cache.stride(0) 必须是 656B(对于 V32)或 576B(对于 MODEL1)的倍数。有时需要填充。
相关更新 commit 链接:https://github.com/deepseek-ai/FlashMLA/commit/082094b793fcc7452977d0a71a00e266a2e3061e
事件随后出现了一个有趣的插曲。一位细心的开发者在浏览代码后,在 FlashMLA 仓库的 Issues 区创建了一个帖子,针对“MODEL1”提出了几个非常具体且专业的技术问题,包括该模型是否已有公开版本,以及其与 V3.2 在注意力机制上的主要区别等。
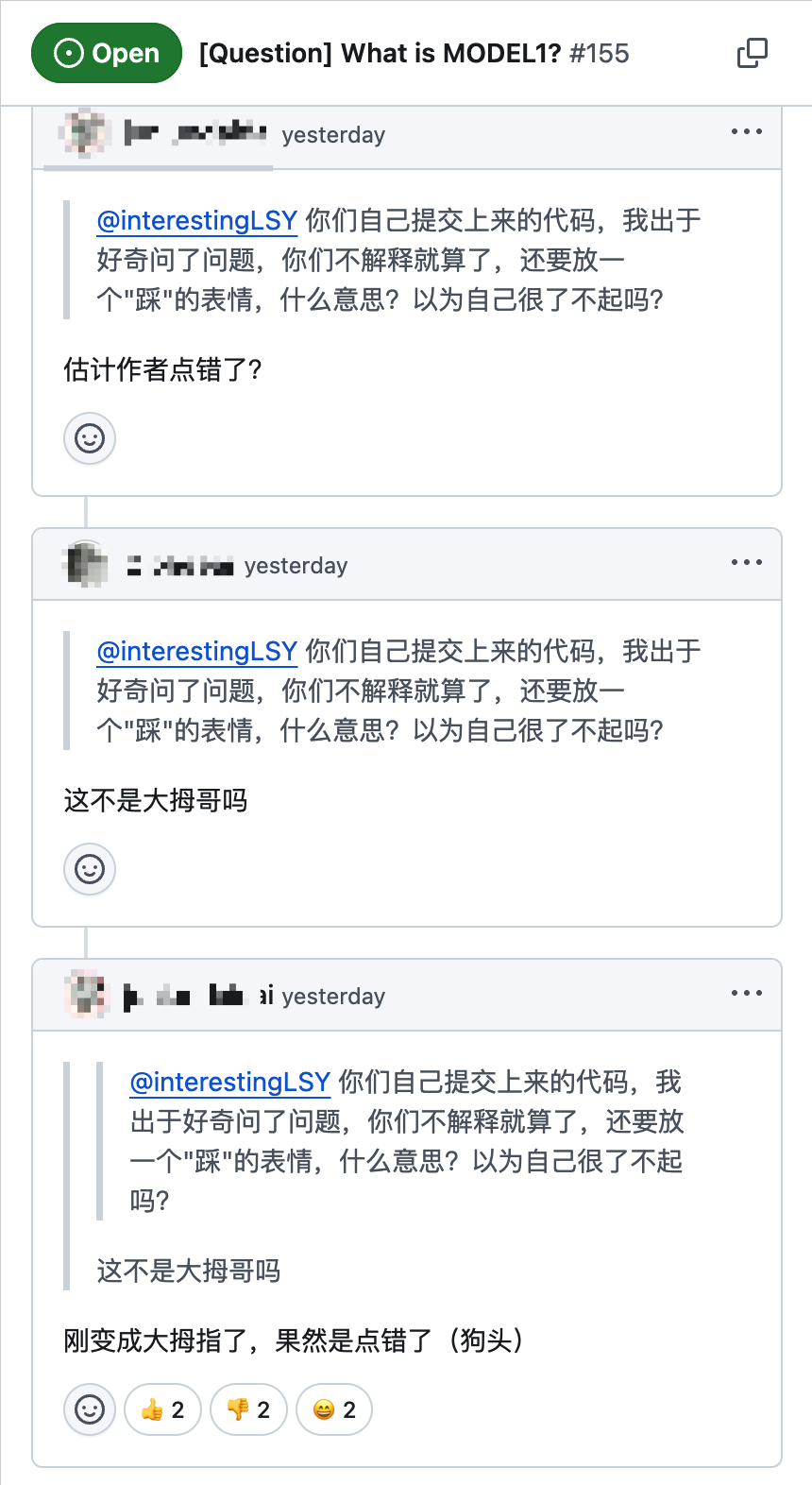
然而,令这位提问者感到意外的是,他的问题很快收到了一个来自 DeepSeek 官方工程师账户的“点踩”反应。这个举动让提问的开发者有些“破防”,直接在评论区追问:“你们自己提交上来的代码,我出于好奇问了问题,你们不解释就算了,还要放一个‘踩’的表情,什么意思?以为自己很了不起吗?”
不过,这个略带火药味的互动很快出现了反转。或许是发现了手误,那位工程师随后将“踩”更改为“赞”。其他围观者也纷纷留言调侃:“估计作者点错了?”“刚变成大拇指了,果然是点错了(狗头)”。
这一小段戏剧性的互动,连同“MODEL1”这个技术悬念,在 [开源社区](https://yunpan.plus/f/39-1) 里迅速传播开来。大家一边猜测新模型的真面目,一边也乐于讨论代码仓库里这种充满人情味的“手误”瞬间。毕竟,在硬核的技术世界之外,这些小小的插曲也让开发者之间的互动显得更加鲜活有趣。
相关讨论 Issue 链接:https://github.com/deepseek-ai/FlashMLA/issues/155
|  发表于 2026-1-24 13:20:25
|
查看: 170|
回复: 0
发表于 2026-1-24 13:20:25
|
查看: 170|
回复: 0
