在日常的渗透测试中,我们常会遇到一片空白的页面,这让许多测试者感到无从下手。其实,这种“空白”往往只是表象,背后可能隐藏着未被发现的管理后台、API接口甚至是安全漏洞。本文旨在打破这种困境,总结了几种实用思路,帮助你将看似无用的“空白页”转变为发现漏洞的突破口,打开渗透测试的新视角。如果你想深入学习更多安全/渗透/逆向的实战技巧,不妨保持探索。
一、目录扫描
使用 dirsearch、Tscan 等自动化目录扫描工具是基础且高效的方法。这些工具能够系统地遍历网站目录结构,尝试访问可能存在的隐藏目录或文件。
常见目标路径:
- 目录:
/admin, /login, /api, /test
- 文件:
robots.txt, .git/, .env, web.config
案例
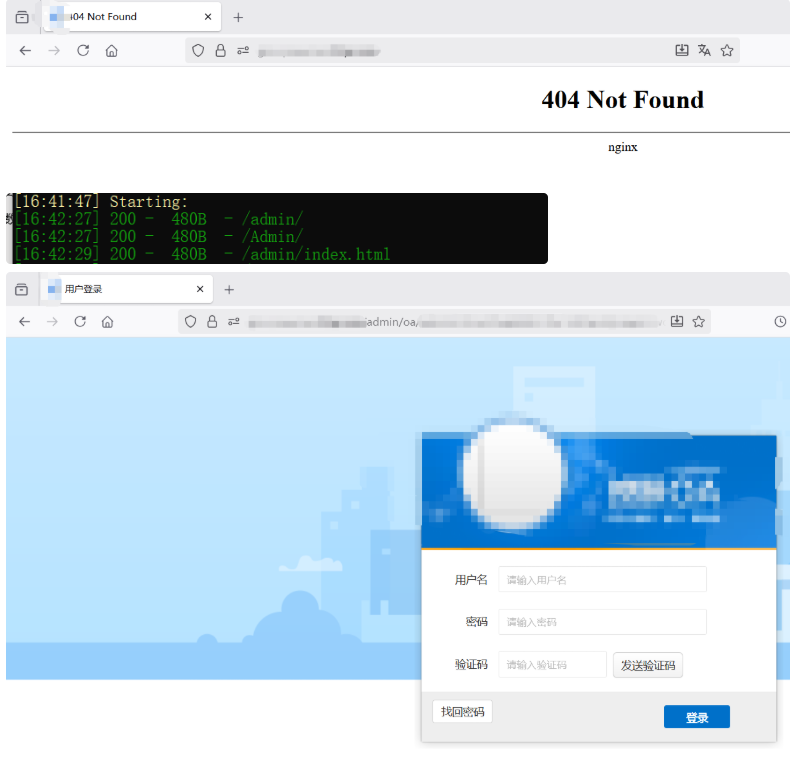
直接访问某网站时返回 404 错误,但通过 dirsearch 扫描发现存在 /admin 路径。拼接该路径后成功访问到后台管理登录界面。
二、指纹识别
利用指纹识别工具(如 ehole、Tscan 等)探测目标网站所使用的技术栈、中间件、开发框架或特定 CMS。识别出特定系统或框架后,便可针对性地搜索其公开漏洞(Nday)或进行代码审计,大幅提升测试效率。
案例
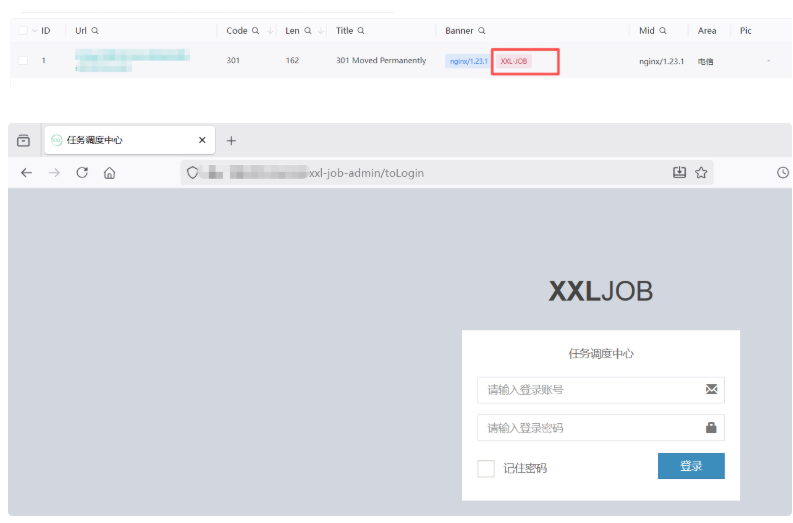
通过 Tscan 的 Web 指纹识别功能识别出某网站使用 XXL-JOB 任务调度系统。随后拼接其常见的后台管理地址 /xxl-job-admin/toLogin 进行访问,成功定位到登录入口。
三、Icon搜索
网站的 icon(图标)文件通常位于根目录下,路径多为 /favicon.ico。每个图标的哈希值(如 MD5)是相对唯一的。将目标网站的图标下载下来,利用网络空间测绘引擎(如 Fofa、Hunter)的图标哈希搜索功能,可以发现互联网上使用相同图标的其他站点或同一套系统的不同入口,从而扩大资产发现面。
案例
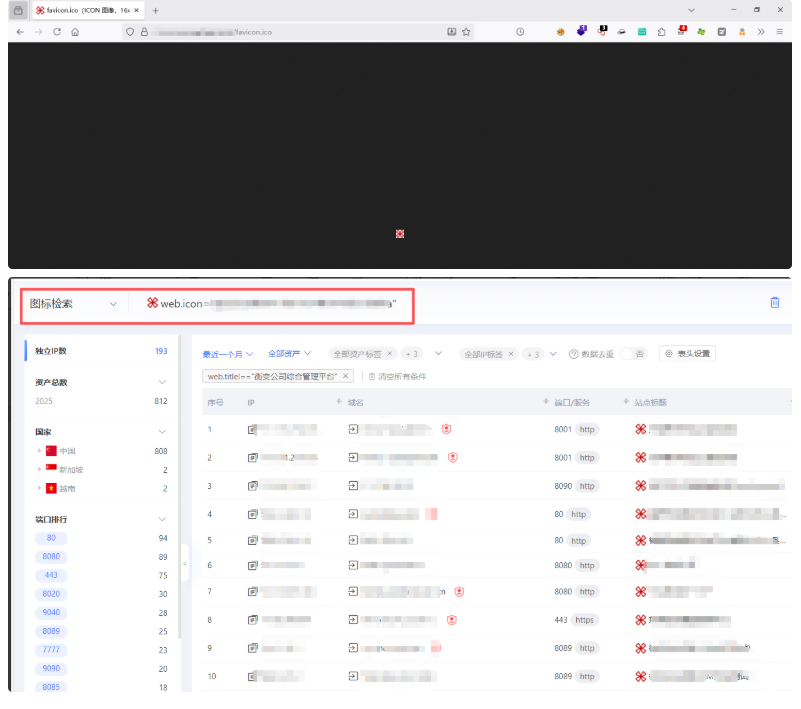
下载目标网站的 favicon.ico 文件,计算其哈希值并放入 Hunter 进行搜索。结果发现了多个使用相同图标的资产,其中包含一些未在明面上暴露的子系统或测试环境。
四、域名拼接
某些站点的部署结构可能基于其域名逻辑。分析目标的域名,尝试将子域名或其关键部分作为路径拼接到主域名后进行访问。这种方法常用于发现基于域名划分的测试、预发布或特定功能页面。
案例
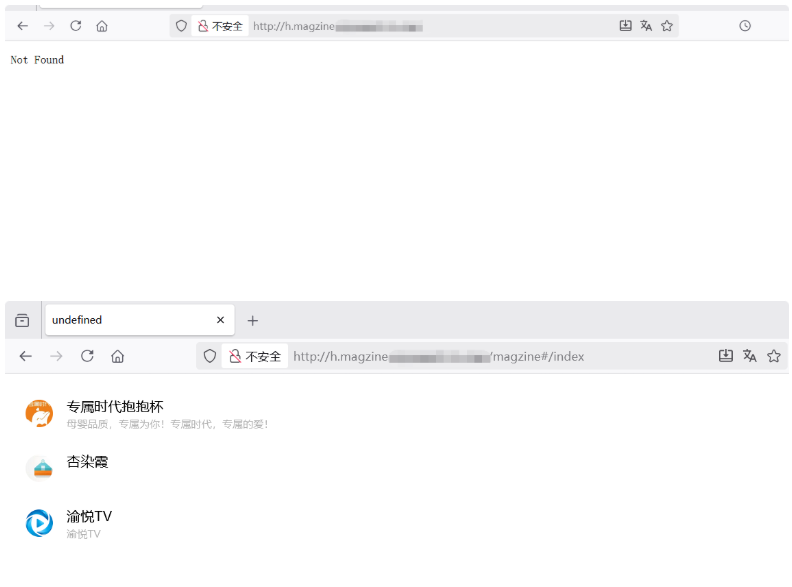
目标域名为 h.magzine.example.com。尝试将子域名中的关键词 magzine 作为路径拼接到主域名,访问 example.com/magzine,成功发现一个隐藏的功能页面。
五、路由拼接
对于采用 Vue.js、React 等前端框架的网站,其页面路由通常由前端 JavaScript 管理。通过分析网站加载的 JS 文件(如 app.js、main.js),搜索 path:、routes 等关键字,可以找出前端定义的所有路由路径。这些路径可能对应着未在页面上直接显示的功能模块。
案例
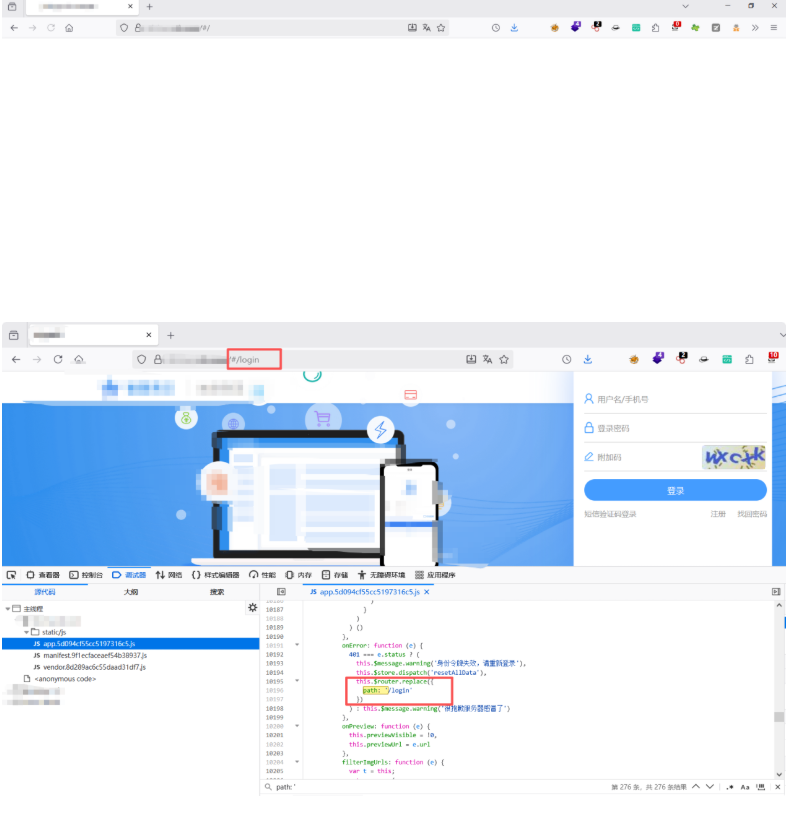
目标网站首页为空白。检查其引用的 JS 文件,全局搜索 path: 关键字,发现前端定义的路由路径包括 /login。随后在原 URL 后直接拼接 #/login 进行访问,成功跳转到隐藏的登录页面。
六、JS文件接口提取
前端 JS 文件中常常硬编码了大量的 API 接口地址、甚至是 API 密钥等敏感信息。使用 findsomething 等工具可以从 JS 文件中自动提取出所有的接口端点(Endpoint)。获取这些接口列表后,重点测试它们是否存在未授权访问、越权操作等安全漏洞,往往能有意外收获。
案例
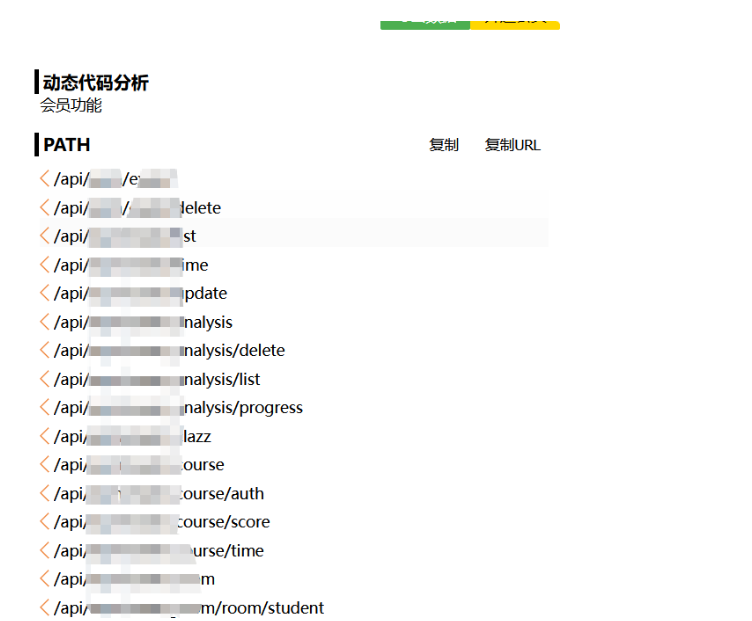
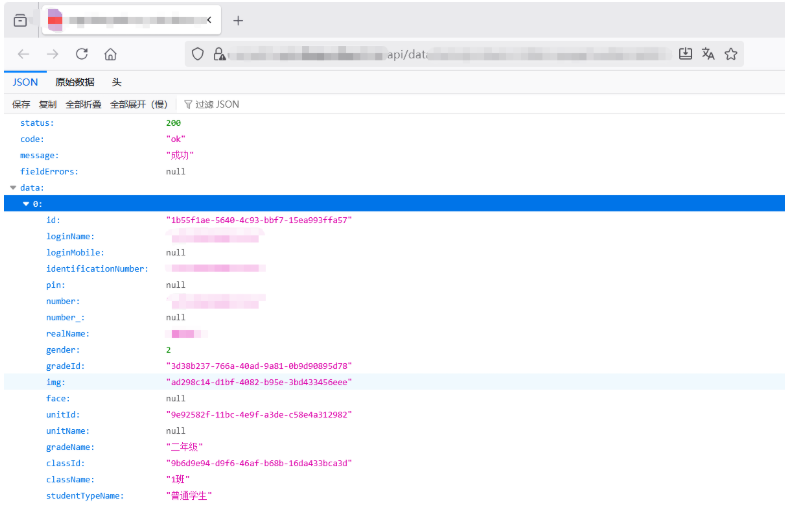
通过工具提取出目标网站 JS 文件中的所有 API 接口,得到一个清晰的列表。随后对其中一个数据列表接口进行测试,发现其未实施有效的身份验证,可以直接未授权访问并获取大量敏感数据。
七、历史记录与泄露信息搜索
通过搜索网站的历史信息,如旧页面快照、备份文件、代码仓库的提交记录等,往往能发现已被删除或隐藏的资产、配置文件甚至敏感数据。常见的方法包括使用特定的谷歌搜索语法(Google Dork)和在 GitHub 等代码托管平台进行信息收集。
常见的谷歌语法示例:
site:限定在特定网站或域名搜索。例如 site:example.com
inurl:搜索URL中包含特定关键词的页面。例如 inurl:login 或 inurl:.bash_history
filetype:搜索特定文件类型。例如 filetype:sql、filetype:log、filetype:bak
intitle:搜索标题中包含特定关键词的页面。例如 intitle:"index of"
GitHub 信息收集:
可以使用 GitDorker 等自动化工具。它利用 GitHub 搜索 API 和大量预定义的搜索关键词(Dorks),来挖掘指定目标相关的代码仓库中可能泄露的敏感信息。
使用方法:python GitDorker.py -tf ./tf/TOKENSFILE -d ./Dorks/alldorksv3 -q example.com -o example.com
案例
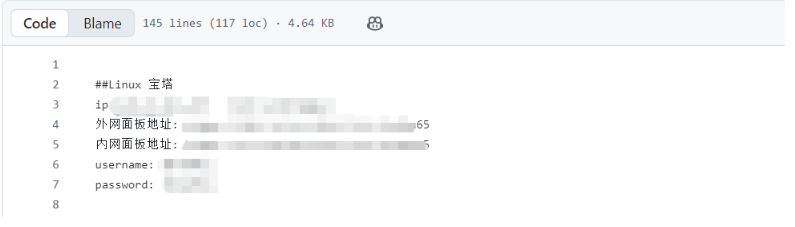
通过 GitDorker 工具对目标进行搜索,成功在某 GitHub 仓库的历史提交记录中发现了包含 Linux 服务器宝塔面板登录信息的配置文件,从而能够接管相关服务器资产。

总结
面对看似空白的页面,关键在于转换思路,从被动观察转为主动探索。本文介绍的七种方法——从基础的目录扫描到深入的历史信息挖掘——共同构成了一套多层次的信息收集策略。在实际的渗透测试中,灵活组合运用这些思路,能有效打破信息壁垒,为后续的漏洞挖掘打下坚实基础。技术的探索永无止境,欢迎各位安全从业者在 云栈社区 交流更多实战心得与技巧。
 发表于 2026-1-24 13:23:44
|
查看: 281|
回复: 0
发表于 2026-1-24 13:23:44
|
查看: 281|
回复: 0
