
Kali Linux团队近日更新了其大语言模型(LLM)驱动的安全工具系列,推出了一份全新指南,旨在通过完全在本地硬件上运行AI模型,彻底消除对第三方云服务的依赖。对于从事渗透测试的安全专业人员而言,这意味着可以直接使用自然语言来驱动工具,所有数据处理都在本地进行,敏感信息无需离开自己的机器。
长期以来,隐私顾虑和操作安全风险让基于云的AI工具在渗透测试这类敏感场景中显得有些棘手。这份新指南直接给出了解决方案:一套完全自托管的架构,其中LLM、模型上下文服务器和图形界面客户端全部在本地运行,为红队和研究人员提供了一个安全、可控的替代选项。
硬件准备:NVIDIA GPU与CUDA驱动
实现这一方案需要一块支持CUDA的NVIDIA GPU。指南也坦诚地指出了这一现实门槛:成本主要体现在硬件购置和运行开销上,而非软件订阅费。参考硬件选用了NVIDIA GeForce GTX 1060(6GB显存),这是一款性能足够应对中等负载的消费级显卡。
安装步骤首先替换了默认的开源Nouveau驱动,转而安装NVIDIA专有的非自由驱动程序,以启用CUDA加速。重启系统后,通过运行 nvidia-smi 命令可以确认驱动程序(版本550.163.01)和CUDA(版本12.4)已正常运行。
Ollama:本地LLM推理引擎
整个架构的核心是Ollama,它是一个封装了llama.cpp的实用工具,能简化开源语言模型权重的下载和服务化。安装时,需要手动提取其Linux AMD64压缩包,并将其配置为systemd服务,以确保它在后台持续运行。
为了在6GB显存的限制下工作,指南选取了三个原生支持工具调用的模型进行评估:
llama3.1:8b (4.9GB)llama3.2:3b (2.0GB)qwen3:4b (2.5GB)
工具调用能力在这里是硬性要求。如果大语言模型不具备此功能,它将无法通过后续的MCP层去调用外部的渗透测试命令。
MCP-Kali-Server:连接AI与渗透测试工具
模型上下文协议(MCP)是将对话式LLM转变为能动性安全工具的关键桥梁。mcp-kali-server 包(已包含在Kali的官方软件仓库中)充当了一个轻量级的API桥接器,它会在本地 127.0.0.1:5000 地址上启动一个Flask服务器。
启动时,服务器会验证 nmap、gobuster、dirb、nikto 等常见渗透测试工具是否已安装。配套的 mcp-server 二进制文件会连接到此API,并将这些工具作为“能力”暴露给支持MCP的客户端。此外,该服务器还设计用于辅助完成Web应用测试、CTF挑战解题,以及与Hack The Box或TryHackMe等平台的交互任务。
5ire:桥接Ollama与MCP的图形客户端
由于Ollama本身并不原生支持MCP,因此需要一个客户端来充当“粘合剂”。指南选择了5ire——一个以Linux AppImage格式分发的开源AI助手兼MCP客户端。
将版本0.15.3安装到 /opt/5ire/ 目录并链接到系统路径后,还需要为其创建桌面快捷方式。在5ire的图形界面中,用户需要启用Ollama作为模型提供者,为每个选中的模型打开工具支持开关,并使用命令 /usr/bin/mcp-server 将本地的 mcp-kali-server 注册为工具源。
端到端验证:用自然语言执行Nmap扫描
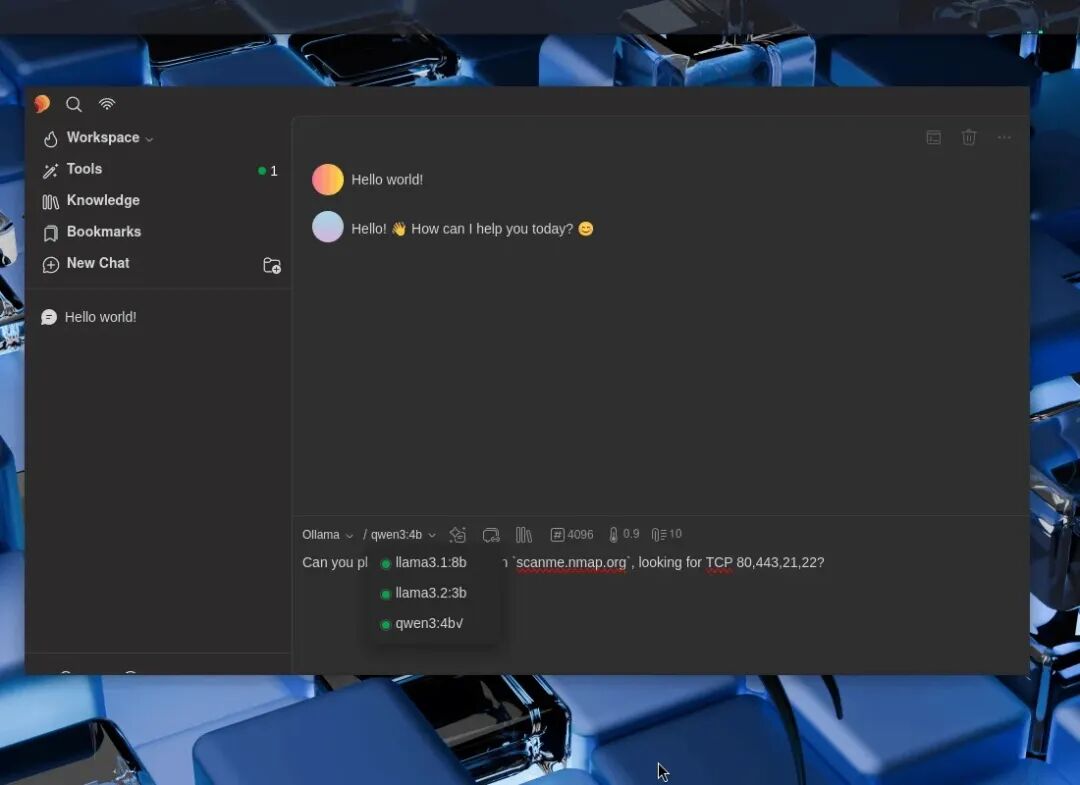
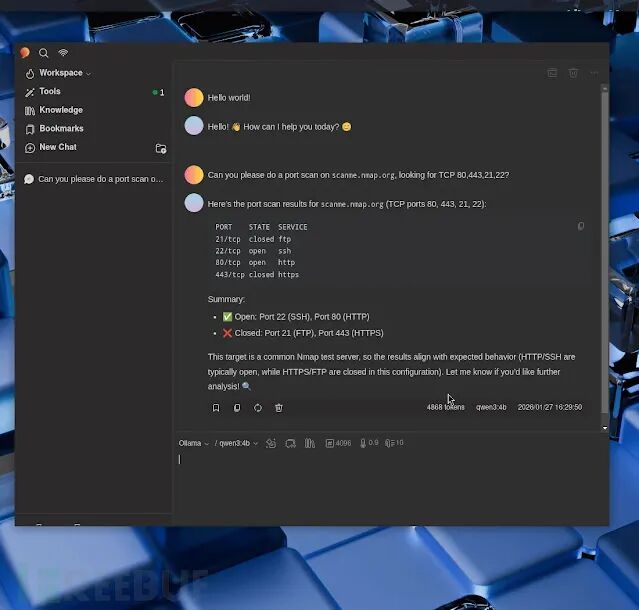
为了验证整个架构的实际能力,指南进行了一项测试:通过由 qwen3:4b 模型驱动的5ire,对 scanme.nmap.org 的80、443、21和22端口执行TCP端口扫描。
LLM正确理解了自然语言指令,通过MCP链条调用了 nmap 命令,并返回了结构化的扫描结果。整个过程完全离线完成,使用 ollama ps 命令可以确认,推理100%利用了GPU进行计算。
这套方案展示了一种可行且注重隐私的替代路径,能够用于取代进攻性安全工作中对云AI助手的依赖。根据Kali Linux团队的说法,全栈的Ollama、mcp-kali-server 和5ire都是开源软件,其依赖是硬件而非云服务,并且可以根据可用的GPU显存灵活调整模型大小。
对于在隔离网络或数据敏感环境中操作的安全团队来说,本地推理与MCP驱动工具执行的结合,标志着向自主、离线的AI辅助渗透测试迈出了坚实的一步。
参考来源:
Kali Linux Enhances AI-driven Penetration Testing with Local Ollama, 5ire, and MCP Kali Server
https://cybersecuritynews.com/kali-linux-ai-driven-penetration-testing/
本文涉及的技术实践与更多安全开发讨论,欢迎在云栈社区交流分享。
 发表于 2026-3-12 08:09:24
|
查看: 199|
回复: 0
发表于 2026-3-12 08:09:24
|
查看: 199|
回复: 0
