在 AI 浪潮席卷的今天,有人唱衰关系型数据库,认为 MySQL 正走向边缘。但事实果真如此吗?作为 MySQL 的重要分支,AliSQL 自诞生以来始终默默支撑着阿里巴巴集团核心业务的高并发、高可用需求。它从未消失,只是需要新的技术活力。
2026年,AliSQL 社区的一群开发者开始为其注入创新血液。他们所做的第一件大事,便是系统性地将列式存储引擎 DuckDB 深度集成到 MySQL 中。这不仅是对“MySQL 只擅长 TP”这一行业共识的突破性回应,更是一次兼具工程魄力与架构远见的创新——在完全保持 MySQL 协议、语法及运维体系兼容的前提下,以轻量、高效、零侵入的方式,为 MySQL 注入了强大的 OLAP 分析能力。
MySQL的插件式存储引擎架构
MySQL 的核心创新之一在于其插件式存储引擎架构,这种设计允许通过不同存储引擎来扩展能力,以支持多样化的业务场景。
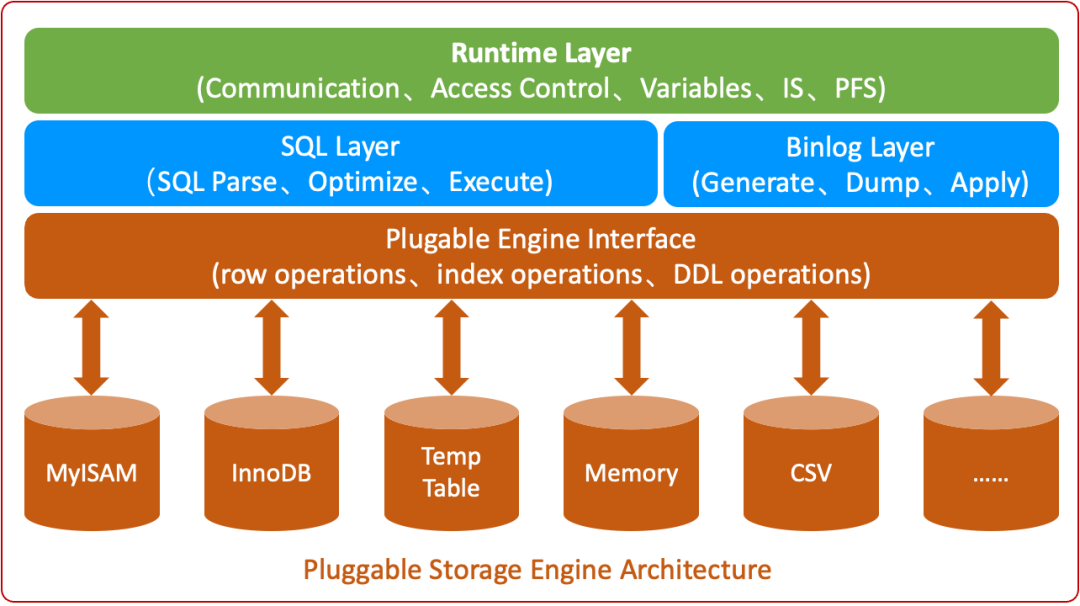
MySQL 的插件式存储引擎架构主要划分为四层:
- 运行层 (Runtime Layer):负责通讯、访问控制、系统变量、信息模式等运行时任务。
- SQL层 (SQL Layer):负责 SQL 的解析、优化和执行。
- Binlog层 (Binlog Layer):负责 Binlog 的生成、转储和应用。
- 存储引擎层 (Storage Engine Layer):负责数据的存储和访问。
MySQL 在 SQL 计算层与数据存储层之间定义了一套标准的数据访问接口。SQL 层通过此接口进行数据的增删改查,而存储引擎则可作为独立组件实现“热插拔”式集成。
目前 MySQL 中常用的存储引擎包括:
- MyISAM:MySQL 早期使用的引擎,因不支持事务已被 InnoDB 取代,但在 MySQL 5.7 及之前版本中仍是系统表的存储引擎。
- InnoDB:MySQL 的默认存储引擎。因其对事务的完整支持及优秀的性能表现,已逐步取代 MyISAM,成为最广泛使用的引擎。
- CSV:CSV 文件引擎,用于存储 MySQL 慢查询日志和通用日志。
- Memory:内存表存储引擎,也可作为 SQL 执行时内部临时表的存储引擎。
- TempTable:MySQL 8.0 引入的引擎,专用于存储内部临时表。
InnoDB 引擎的引入是 MySQL 插件式架构的一个重要里程碑。随着互联网业务,尤其是电商、社交的兴起,对事务和并发的要求越来越高,InnoDB 凭借其对 ACID 事务的支持和出色的并发性能,极大地拓展了 MySQL 的能力边界,使其成为最流行的开源 OLTP 数据库。
然而,随着 MySQL 的广泛应用,基于 TP 数据的分析型查询需求日益增长。InnoDB 的架构天然为 OLTP 设计,在分析型查询场景下效率较低,这大大限制了 MySQL 的应用场景。时至今日,MySQL 一直欠缺一个高效的分析型查询引擎,而 DuckDB 的出现让我们看到了新的可能性。
DuckDB简介
DuckDB 是一个为在线分析处理(OLAP)和数据分析工作负载而设计的开源嵌入式数据库。因其轻量、高性能、零配置和易集成的特性,正迅速成为数据科学、BI 工具和嵌入式分析场景中的热门选择。DuckDB 主要有以下特点:
- 卓越的查询性能:单机 DuckDB 的分析查询性能不仅远超 InnoDB,甚至优于 ClickHouse 等同类 OLAP 数据库。
- 优秀的压缩比:采用列式存储,并根据数据类型自动选择合适的压缩算法,拥有非常高的数据压缩率。
- 嵌入式设计:作为一个嵌入式数据库系统,天然适合被集成到其他应用中,如 MySQL。
- 插件化设计:DuckDB 自身也采用插件式设计,方便进行第三方功能开发和扩展。
- 友好的 License:DuckDB 采用 MIT 许可证,允许任何形式的使用其源代码,包括商业用途。
基于以上优点,我们认为 DuckDB 非常适合成为 MySQL 的 AP 存储引擎。因此,我们将其深度集成到了 AliSQL 中。
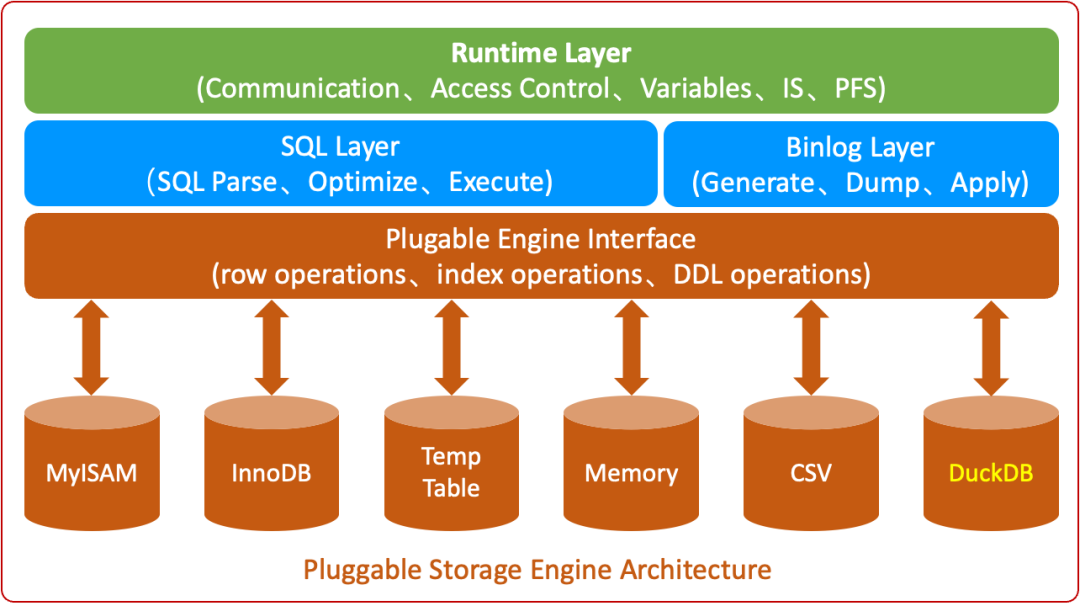
DuckDB 引擎的定位是实现轻量级的单机分析能力。目前,基于 DuckDB 引擎的 RDS MySQL DuckDB 只读实例已经上线。未来,我们还将上线支持主备高可用的 RDS MySQL DuckDB 主实例,用户可通过 DTS 等工具将异构数据汇聚至此,实现统一的数据分析查询。
RDS MySQL DuckDB只读实例的架构
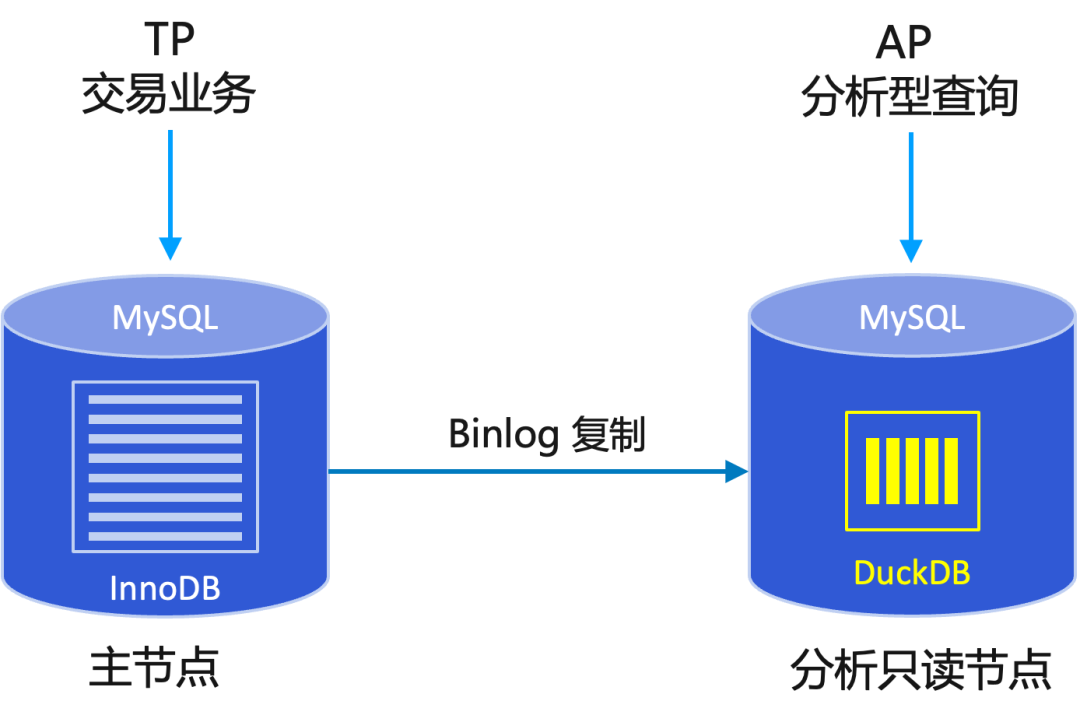
DuckDB 分析只读实例采用读写分离架构,将分析型业务与主库的 TP 业务分离,互不影响。与普通只读实例一样,它通过 Binlog 复制机制从主库同步数据。DuckDB 分析只读节点拥有以下优势:
- 高性能分析查询:基于 DuckDB 的列式存储和向量化执行引擎,分析型查询性能相比 InnoDB 提升高达 200 倍。
- 存储成本低:凭借 DuckDB 的高压缩率,只读实例的存储空间通常只有主库存储空间的 20%。
- 100% 兼容MySQL语法:DuckDB 作为引擎集成,用户查询仍使用原生 MySQL 语法,无需额外学习成本。
- 无额外管理成本:实例仍然是标准的 RDS MySQL,管理、运维、监控方式与普通实例完全一致。
- 一键创建:可一键创建 DuckDB 只读实例,数据自动从 InnoDB 格式转换并同步至 DuckDB,无需额外操作。
DuckDB 引擎的实现
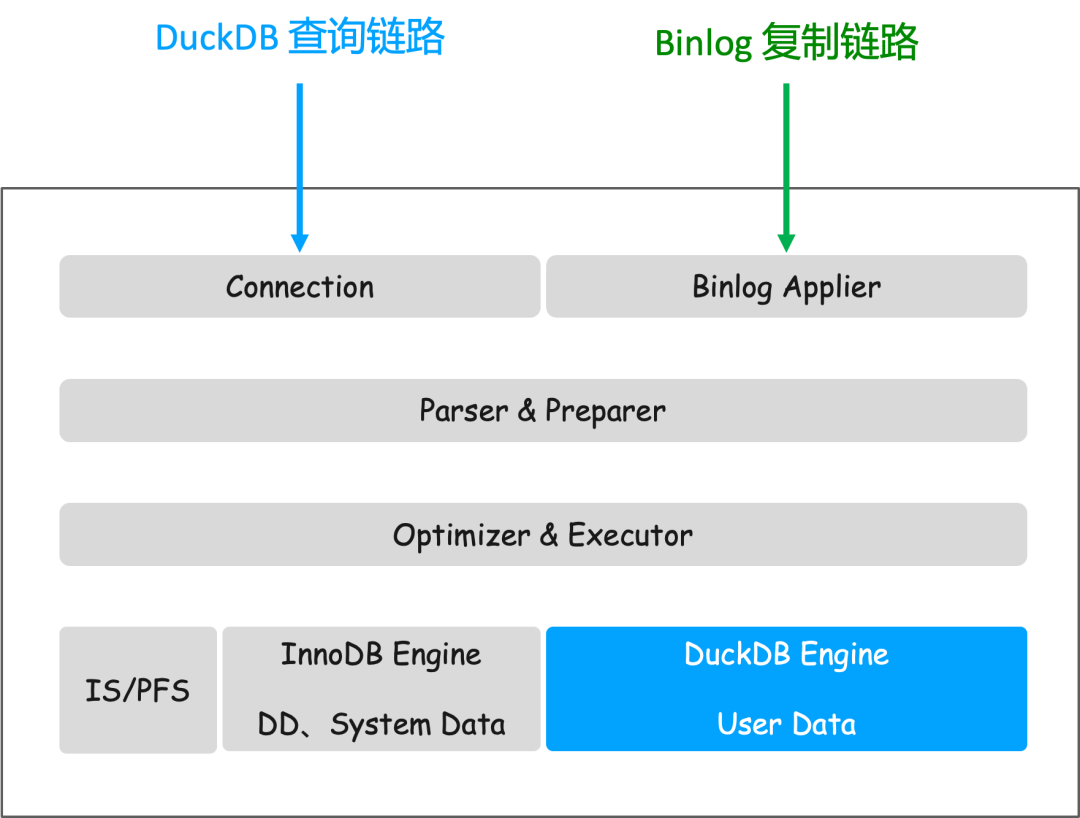
DuckDB 只读实例的功能可分为查询链路和 Binlog 复制链路。查询链路处理用户的分析查询请求,Binlog 复制链路则负责从主实例同步数据变更。
查询链路
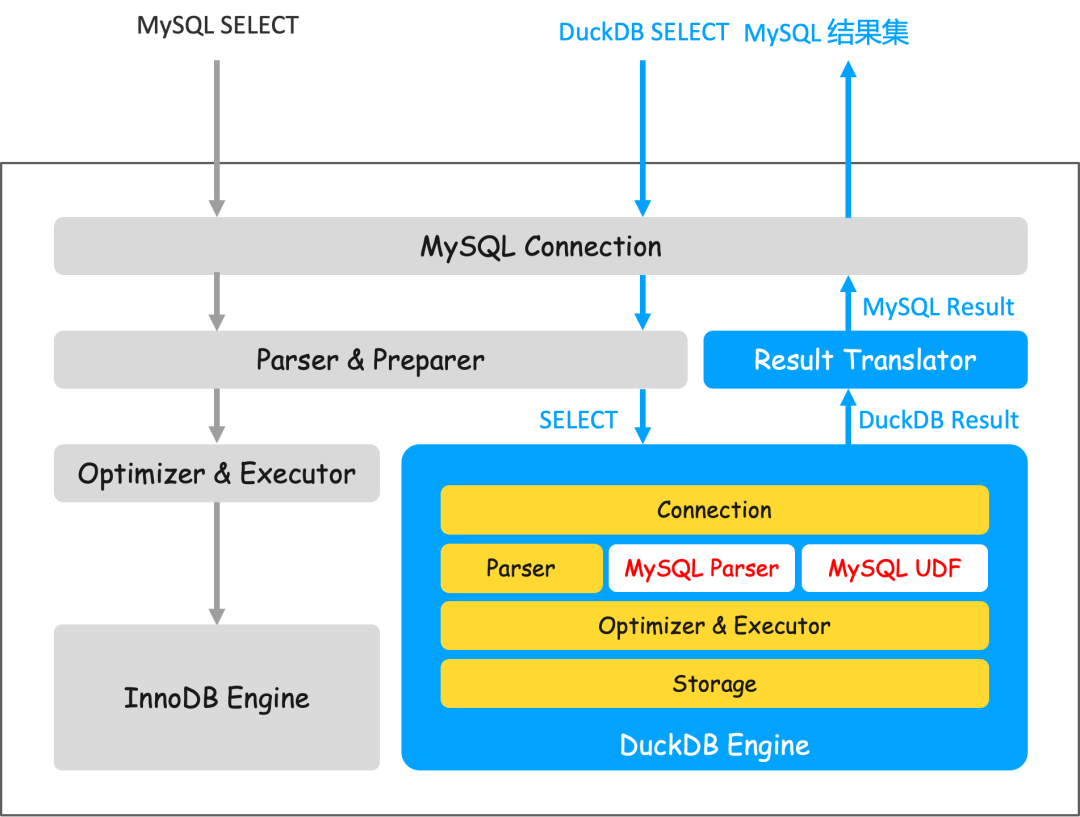
查询执行流程如上图所示。在该架构中,InnoDB 仅用于保存元数据和系统信息(如账号、权限、配置等),而所有的用户数据都存储在 DuckDB 引擎中。
用户通过 MySQL 客户端连接到实例。查询到达后,MySQL Server 层首先进行解析和预处理,然后将 SQL 语句下发至 DuckDB 引擎执行。DuckDB 执行完毕后,将结果返回给 Server 层,Server 层再将结果集转换为标准的 MySQL 结果集格式返回给客户端。
查询链路的核心工作是确保兼容性。DuckDB 与 MySQL 在数据类型上基本兼容,但在语法和内置函数支持上存在较大差异。为此,我们扩展了 DuckDB 的语法解析器以兼容 MySQL 特有语法,并重写、新增了大量函数,使常见的 MySQL 函数都能准确运行。经过自动化兼容性测试平台约 17 万条 SQL 测试,显示兼容率达到了 99%。
Binlog复制链路
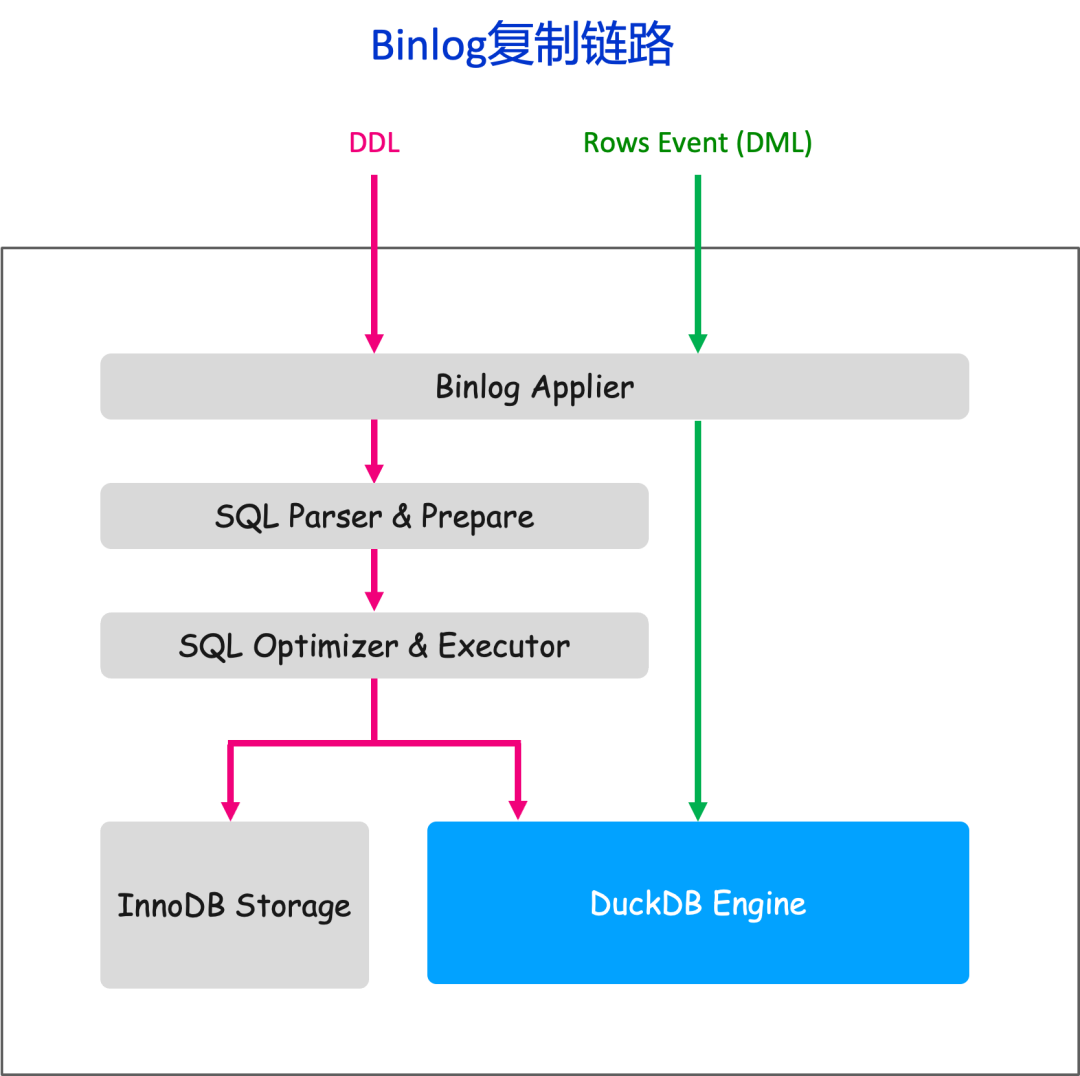
幂等回放
由于 DuckDB 不支持两阶段提交,无法利用其来保证 Binlog GTID 与数据之间的一致性,也无法保证 DDL 操作中 InnoDB 元数据与 DuckDB 数据的一致性。因此,我们对事务提交和 Binlog 回放过程进行了改造,确保了实例在异常宕机重启后仍能保持数据一致性。
DML回放优化
DuckDB 本身的设计有利于大事务的批量执行,频繁的小事务执行效率较低,容易导致复制延迟。为此,我们对 Binlog 回放进行了优化,采用了攒批(Batch)的方式进行事务重放。优化后,回放能力可达 30 万行/秒。在 Sysbench 压力测试中,能够实现零复制延迟,其回放性能甚至超过了 InnoDB。

并行Copy DDL
MySQL 中有一小部分 DDL(如修改列顺序)是 DuckDB 原生不支持的。为了保证复制的正常进行,我们实现了 Copy DDL 机制。对于 DuckDB 原生支持的 DDL,采用 Inplace/Instant 方式执行;当遇到不支持的 DDL 时,则采用 Copy DDL 方式创建新表并替换原表。
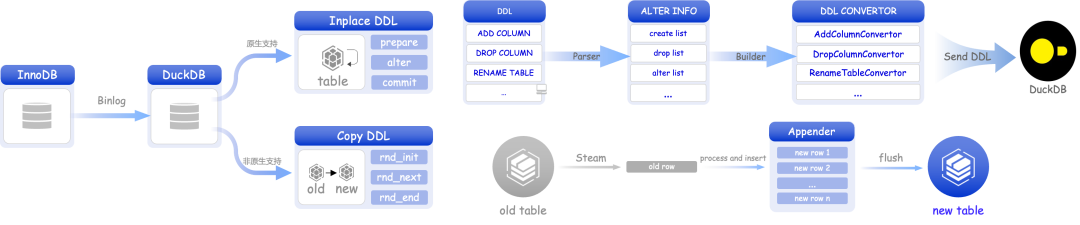
Copy DDL 采用多线程并行执行,使执行时间缩短了 7 倍。
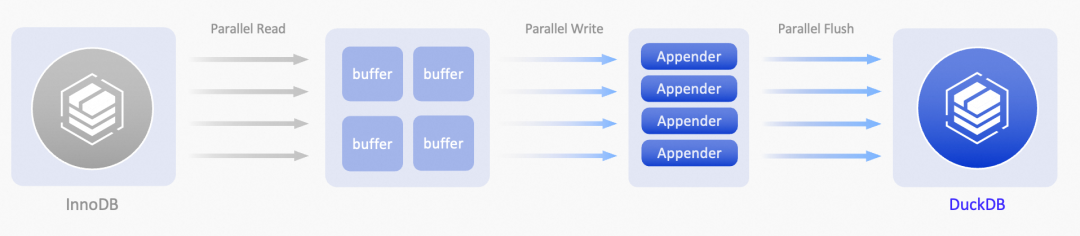
DuckDB只读实例的性能
测试环境
- ECS 实例:32 CPU,128G 内存
- 存储:ESSD PL1 云盘,500GB
测试基准
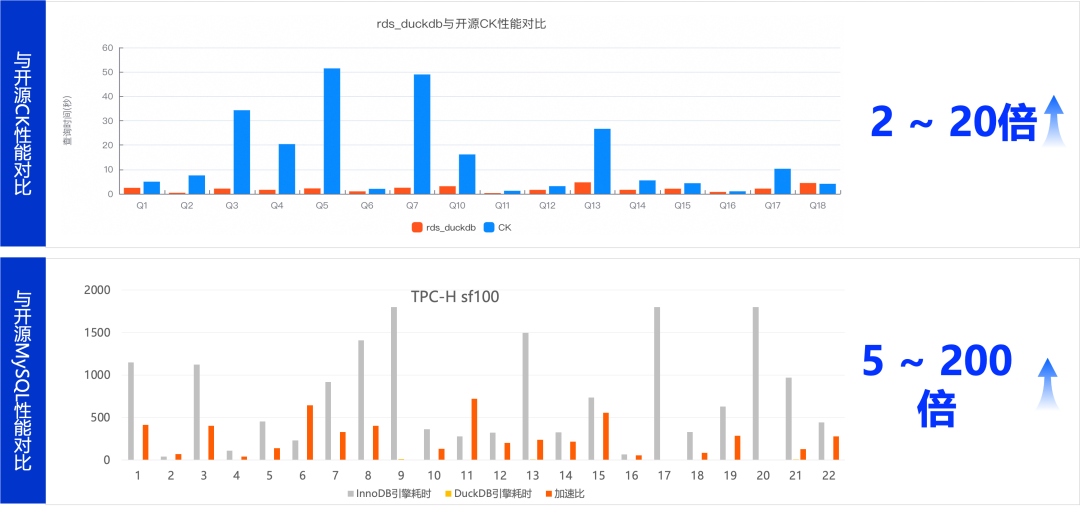
从上图性能对比可以看出,在 TPC-H SF100 场景下,DuckDB 引擎的查询性能相比 InnoDB 引擎有 5 到 200 倍的提升。
结语
通过将 DuckDB 深度集成到 AliSQL 中,我们成功打造了兼具高性能与高兼容性的 MySQL 分析型实例。这一创新不仅弥补了 MySQL 长期以来在 OLAP 场景下的能力短板,也开创了一种全新的“HTAP 轻量化”实现路径——无需复杂的分布式架构,即可在单机中获得强大的实时分析能力。
DuckDB 引擎的引入,使得用户可以在不改变现有应用架构的前提下,轻松获得高达数百倍的分析查询性能提升。更重要的是,用户依然使用熟悉的 MySQL 协议和 SQL 语法,无需学习新工具或改造应用程序。一键创建、自动同步、无缝切换,真正做到了“分析能力即服务”。欢迎访问云栈社区了解更多数据库与大数据技术的前沿实践与深度讨论。
 发表于 2026-1-24 13:26:34
|
查看: 274|
回复: 0
发表于 2026-1-24 13:26:34
|
查看: 274|
回复: 0
