之前基于 MySQL 5.7 的系列文章已经不能满足最新的技术变化。随着 MySQL 8 的普及,其内核在索引等核心机制上也有不少演进。索引作为数据库性能调优的重中之重,也是面试中频繁被问及的知识点。今天,我们就从最基础的索引数据结构入手,理清其底层原理与工作方式。
1. 什么是索引
谈到索引,最经典的比喻就是查字典。当你想知道某个字的释义时,绝不会一页一页翻找,而是先根据拼音或部首索引定位到具体页数。数据库中的索引作用完全一样,它是一种帮助数据库系统高效获取数据的数据结构。
我们常把索引称作 index 或 key。在数据量不大时,索引的作用可能不明显,容易被忽略。然而,一旦数据量攀升至百万、千万级别,一个设计优良的索引与全表扫描的性能差距将是天壤之别。在众多 SQL 优化手段中,正确地使用索引往往能带来最显著的性能提升。
这里可能会有个疑问:许多索引优化策略是针对传统机械硬盘(HDD)的特性设计的,而现在服务器普遍使用固态硬盘(SSD)。在 SSD 上,这些优化还有必要吗?答案是肯定的。索引优化的核心逻辑并未改变,只不过 SSD 的随机读写性能远超 HDD,因此索引设计不当所造成的性能损失,在 SSD 上可能不像在 HDD 上那么触目惊心,但影响依然存在。
2. 索引的数据结构
2.1 B+Tree 与 B-Tree 的核心差异
MySQL 采用插件式的存储引擎架构,索引是在存储引擎层实现的。这意味着不同的存储引擎,其索引的工作方式乃至数据结构都可能不同。本文我们聚焦于最常用的 InnoDB 存储引擎。
InnoDB 的索引数据结构是 B+Tree。为了更直观地理解其优势,我们通过与 B-Tree 的对比来阐述。
假设我们有如下用户数据表,并为 username 和 age 字段建立了一个联合索引:
| username |
age |
address |
gender |
| ab |
99 |
深圳 |
男 |
| ac |
98 |
广州 |
男 |
| af |
88 |
北京 |
女 |
| bc |
80 |
上海 |
女 |
| bg |
85 |
重庆 |
女 |
| bw |
95 |
天津 |
男 |
| bw |
99 |
海口 |
女 |
| cc |
92 |
武汉 |
男 |
| ck |
90 |
深圳 |
男 |
| cx |
93 |
深圳 |
男 |
基于此数据构建的 B-Tree 和 B+Tree 结构示意图如下:
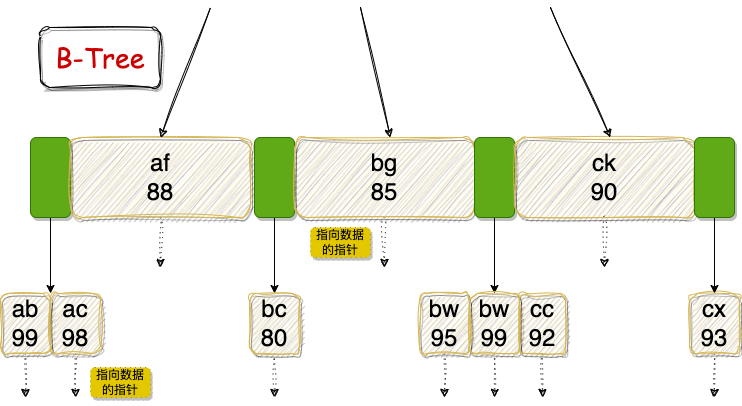
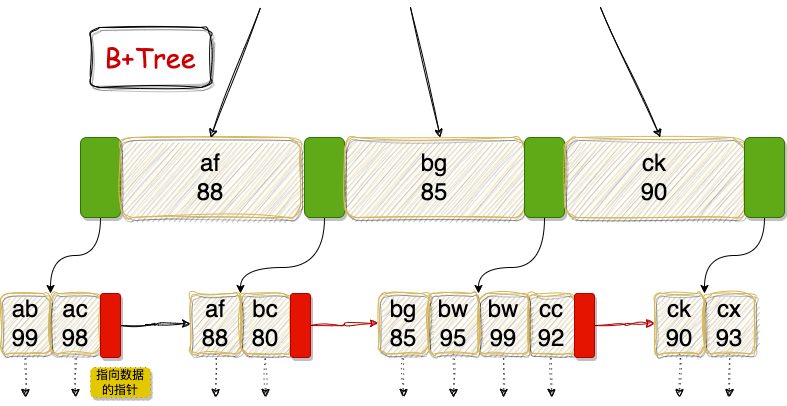
看懂这两张图,你就理解了 InnoDB 索引 80% 的精髓。我们来详细解读其中的关键点:
- 多路平衡查找树:两者都不是二叉树,而是多叉树,这保证了树的平衡与较低的高度。
- 节点构成:
- 绿色方块:指向下一个子节点的指针。
- 红色方块(仅B+Tree有):指向下一个叶子节点的指针。
- 带阴影矩形:索引关键字数据(如
(af,88))。
- 数据存储位置:
- B+Tree:非叶子节点只存储索引关键字和指针,所有完整的索引数据(或数据记录指针)都存放在叶子节点。因此,每次查询都必须走到叶子节点,查询路径长度稳定,性能可预测。
- B-Tree:非叶子节点也可能存储指向具体数据的指针。这意味着某些查询可能在分支节点就命中(如图中的
af),导致查询效率不稳定。
- 树高与IO效率:
- B+Tree:由于非叶子节点不存实际数据,在同样大小的磁盘页(如16KB)里能容纳更多的关键字和指针,从而树的扇出更大,高度更低。搜索时需要的磁盘IO次数更少,效率更高。
- B-Tree:非叶子节点存数据指针,占用空间,导致扇出较小,相同数据量下树更高,搜索IO更多。
- 范围查询与顺序访问:
- B+Tree:叶子节点按关键字顺序排列,并通过指针串联成链表。进行范围查询(如
username BETWEEN ‘ac’ AND ‘bc’)时,找到起始点后,顺着指针遍历即可,效率极高。
- B-Tree:没有叶子节点的链表指针,范围查询可能需要多次回溯到父节点,效率较低。
- 排序支持:
- B+Tree:所有数据都在有序的叶子节点上,对排序操作友好。
- B-Tree:数据分散在各层,排序支持不如B+Tree。
- 数据划分原则:
- B+Tree:左闭右开。例如节点
(af,88),小于它的在左子树,大于等于它的在右子树。
- 全表扫描:
- B+Tree:只需线性遍历叶子节点链表即可,速度快。
- B-Tree:需要对树进行层序遍历,更慢。
- 指针指向:叶子节点的指针,如果这是聚簇索引,则指向完整的表记录;如果是二级索引(非聚簇索引),则指向主键值。通过二级索引查询时,先找到主键,再回主键索引查找完整记录,这个过程称为回表。
简单比喻:MySQL的数据存储,就像是把所有数据用链表串起来,然后在这条链表之上架设了一棵多路平衡查找树。沿着链表逐个查找就是全表扫描;从树根开始查找,就是使用索引。
2.2 树高能承载多少数据?一个经典计算
一个经典面试题:一个3层的B+Tree能存储多少条数据?
这需要了解InnoDB的磁盘操作单元。它不以扇区(512B)或文件系统块(4KB)为单位,而是以页(Page) 为单位,默认大小为 16KB。这意味着,即使你只想读1字节,InnoDB也会把整个16KB的数据页加载到内存中。
我们可以验证这个页大小:
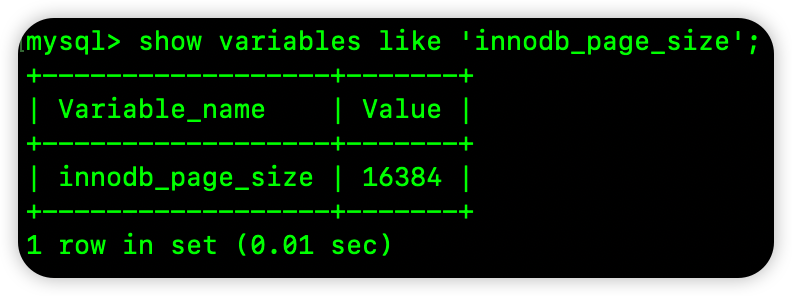
16384/1024 = 16,确认是16KB。
现在我们来估算:
- 叶子节点:假设一条记录大小为1KB,那么一个数据页(叶子节点)能存
16KB / 1KB = 16 条记录。
- 非叶子节点:存储的是“主键值+指针”。假设主键为
bigint(8字节),指针6字节,粗略估算(忽略页头等元信息):
16KB / (8+6)字节 ≈ 1170 个关键字指针对。
- 三层B+Tree容量:
- 根节点有 1170 个指针,指向1170个第二层节点。
- 每个第二层节点也有1170个指针,指向1170个叶子节点。
- 总记录数 ≈
1170 * 1170 * 16 ≈ 2190万 条。
因此,一个3-4层的B+Tree就能轻松支撑千万级数据存储。通过主键查询,最多仅需3-4次磁盘IO,效率极高。
2.3 哪些查询能用上索引?
基于B+Tree的结构特性,以下查询模式可以有效利用索引:
- 全值匹配:精确匹配索引中的所有列,如
WHERE username='ac' AND age=98。
- 最左前缀匹配:匹配索引最左的连续列,如
WHERE username='ac'。如果跳过最左列 username 直接查 WHERE age=98,则无法使用该索引,因为 age 在索引中不是全局有序的。
- 前缀匹配:匹配列值的前缀,如
WHERE username LIKE ‘a%’。
- 范围匹配:对最左前缀列进行范围查询,如
WHERE username BETWEEN ‘ab’ AND ‘cc’。
- 前值后范围:精确匹配前面的列,并对后续列进行范围查询,如
WHERE username='bw' AND age BETWEEN 90 AND 99。因为 username 相同时,age 是有序的。
- 覆盖索引:查询的列完全包含在索引中,无需回表,如该联合索引下查询
SELECT age FROM user WHERE username='bw'。
2.4 索引使用的限制
同样,基于其数据结构,索引也有使用限制:
- 最左前缀原则:如果跳过联合索引的第一列,直接使用后面的列作为条件,索引通常失效。
- 范围列右侧的列无法用索引精确查找:例如查询
WHERE username LIKE ‘a%’ AND age=99。在找到所有以 ‘a’ 开头的用户名后,这些记录对应的 age 值并不是有序的(如下图所示),因此 age=99 无法再通过索引快速定位,只能由存储引擎在索引扫描过程中进行过滤(即“索引下推”优化)。
为了说明这一点,假设我们新增两条记录 (ad,80) 和 (ae,88),更完整的B+Tree叶子层示意如下:
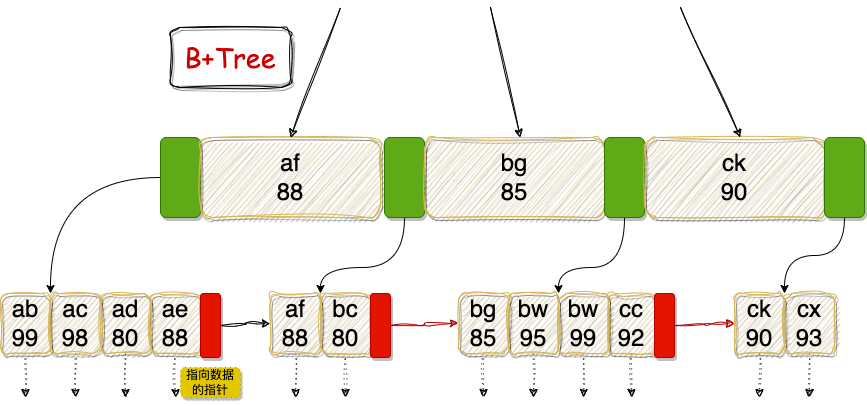
可见,username 以 ‘a’ 开头的记录,其 age 值(88, 98, 80, 88…)是乱序的。
2.5 自适应哈希索引
哈希索引的查询复杂度是O(1),效率极高,但InnoDB默认并不直接支持创建Hash索引。不过,它提供了一种 自适应哈希索引(Adaptive Hash Index, AHI) 机制。
当InnoDB监控到某些索引值被非常频繁地访问时,它会在内存中的B+Tree索引之上,自动为这些热点数据创建一个哈希索引,从而进一步提升点查询的速度。整个过程是自动的,无需DBA干预。
默认情况下AHI是开启的,可通过以下命令查看:
3. 小结
总而言之,合理使用索引能带来三大核心收益:
- 极大减少需要扫描的数据量。
- 帮助服务器避免排序和创建临时表(索引本身有序)。
- 将随机IO变为顺序IO(特别是范围扫描时)。
理解 B+Tree 这一底层数据结构,是掌握 MySQL 乃至其他很多数据库索引优化的基石。希望本文的剖析能帮助你建立起清晰的认知。如果你想深入交流更多关于数据库或系统设计的实战经验,欢迎来 云栈社区 与其他开发者一起探讨。
 发表于 2026-3-12 07:00:32
|
查看: 129|
回复: 0
发表于 2026-3-12 07:00:32
|
查看: 129|
回复: 0
