在MySQL中对查询结果进行排序,我们通常会使用 ORDER BY 子句。这看似简单的操作,其底层实现却有两种不同的路径,性能差异显著。一种是通过文件排序(filesort),另一种则是利用索引本身的顺序,即索引排序。显然,如果我们能利用好数据库索引,让排序操作“事半功倍”,无疑是性能优化的上佳之选。
1. 排序的两种方式
总的来说,MySQL实现排序有两种思路:
- filesort(文件排序):这个名字可能有些误导,它不一定涉及磁盘文件。当待排序的数据量较小时,MySQL会直接在内存中完成排序;只有当内存不足以容纳所有数据时,才会使用磁盘临时文件。
- 索引排序:InnoDB存储引擎的索引是基于B+Tree结构组织的,树中的数据本身就是有序的。如果查询能够按索引的顺序来读取数据,那么天然就是排好序的,从而避免了额外的排序开销。
理想情况下,我们应该尽力通过第二种方式来完成排序。但这里有一个关键前提:查询应当避免回表。如果查询需要回表(即需要根据索引中的主键值再去主键索引中查找其他不在联合索引中的字段),由于回表操作很可能是随机IO,其性能损耗可能会抵消甚至超过索引排序带来的收益。因此,是否需要回表,是评估索引排序是否高效的重要因素。
2. 索引排序的生效条件
索引排序并非在任何 ORDER BY 场景下都能生效,它需要满足严格的条件。为了便于理解,我们以下表结构为例:
CREATE TABLE `user` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`age` int DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`gender` varchar(2) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `user_prop_index` (`username`,`age`,`address`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
该表有一个联合索引 user_prop_index,包含 username, age, address 三个字段。假设表中数据如下:
| id(主键) |
username |
age |
address |
gender |
| 1 |
ab |
99 |
深圳 |
男 |
| 2 |
bw |
95 |
天津 |
男 |
| 3 |
cx |
93 |
深圳 |
男 |
| 4 |
bc |
80 |
上海 |
女 |
| 5 |
bg |
85 |
重庆 |
女 |
| 6 |
ac |
98 |
广州 |
男 |
| 7 |
bw |
99 |
海口 |
女 |
| 8 |
ck |
90 |
深圳 |
男 |
| 9 |
cc |
92 |
武汉 |
男 |
| 10 |
af |
88 |
北京 |
女 |
该联合索引的B+Tree结构示意图如下(数据已简化):
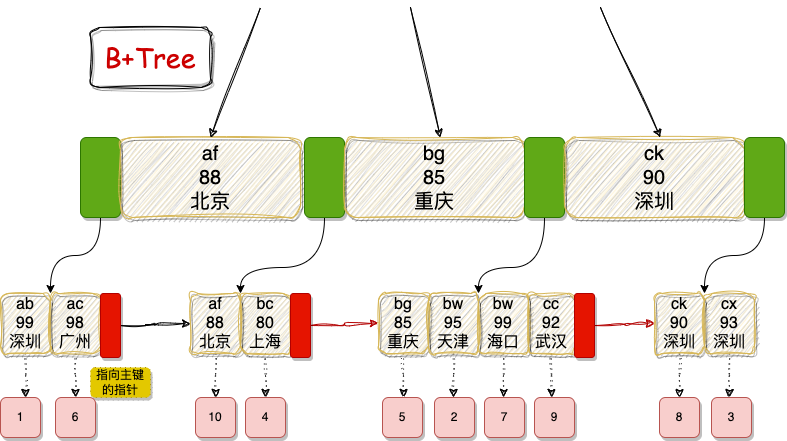
核心结论:只有当 ORDER BY 子句中字段的顺序和方向(升序ASC或降序DESC)与索引定义完全一致,并且该索引满足查询条件时,MySQL才能使用索引进行排序。对于联合索引,ORDER BY 子句同样需要满足最左前缀匹配原则。
下面我们通过一系列案例来具体分析。
2.1 案例一:单字段排序,且字段为索引最左列
select address from user order by username;
查询的 address 字段在联合索引中,排序字段 username 是索引的最左列。索引树本身就是按照 username 升序组织的,因此可以直接利用索引顺序返回结果。
mysql> explain select address from user order by username\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user
partitions: NULL
type: index
possible_keys: NULL
key: user_prop_index
key_len: 2051
ref: NULL
rows: 10
filtered: 100.00
Extra: Using index
执行计划中的 type: index 和 Extra: Using index 表明MySQL使用了索引扫描(索引全扫描)来避免排序。
2.2 案例二:多字段排序,但排序方向不一致
select address from user order by username asc,age desc
虽然排序字段 username, age 都是索引列且顺序匹配,但排序方向不一致(一个ASC,一个DESC)。索引树在存储时,username 相同时 age 是按升序存储的,无法满足 age 降序的需求。
mysql> explain select address from user order by username asc,age desc\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user
partitions: NULL
type: index
possible_keys: NULL
key: user_prop_index
key_len: 2051
ref: NULL
rows: 10
filtered: 100.00
Extra: Using index; Using filesort
Extra: Using filesort 说明MySQL不得不进行额外的文件排序。
2.3 案例三:单字段降序排序
select address from user order by username desc
在MySQL 5.7中,索引默认是升序存储的,但优化器可以进行反向扫描(Backward index scan)来满足降序需求。
在MySQL 8.0中,支持在定义索引时指定降序字段(DESC),优化器可以更高效地进行正向扫描。
MySQL 5.7执行计划:
mysql> explain select address from user order by username desc\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user
partitions: NULL
type: index
possible_keys: NULL
key: user_prop_index
key_len: 2051
ref: NULL
rows: 10
filtered: 100.00
Extra: Using index
MySQL 8.0执行计划:
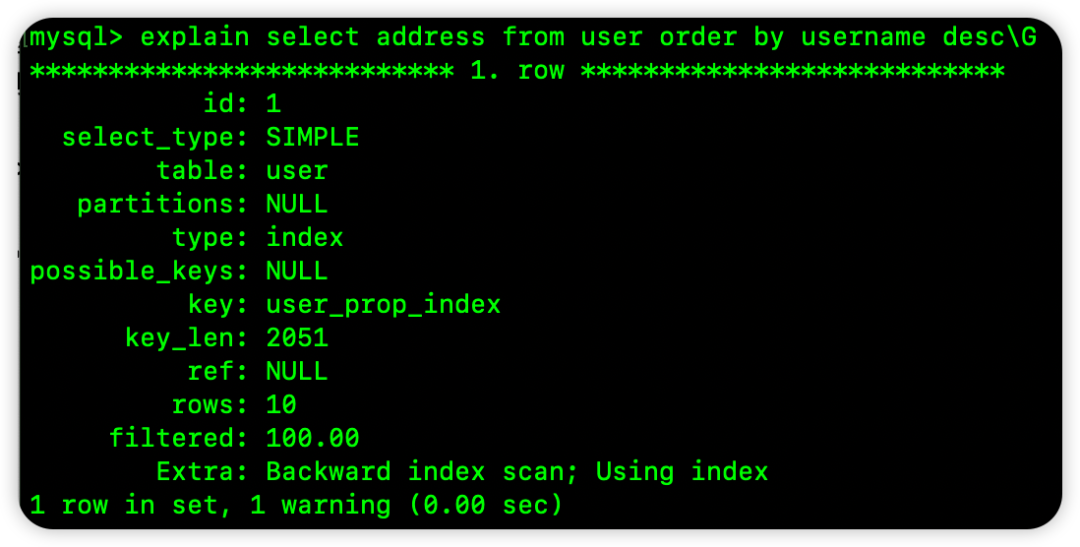
可以看到 Extra: Backward index scan; Using index,明确指出了使用了反向索引扫描。
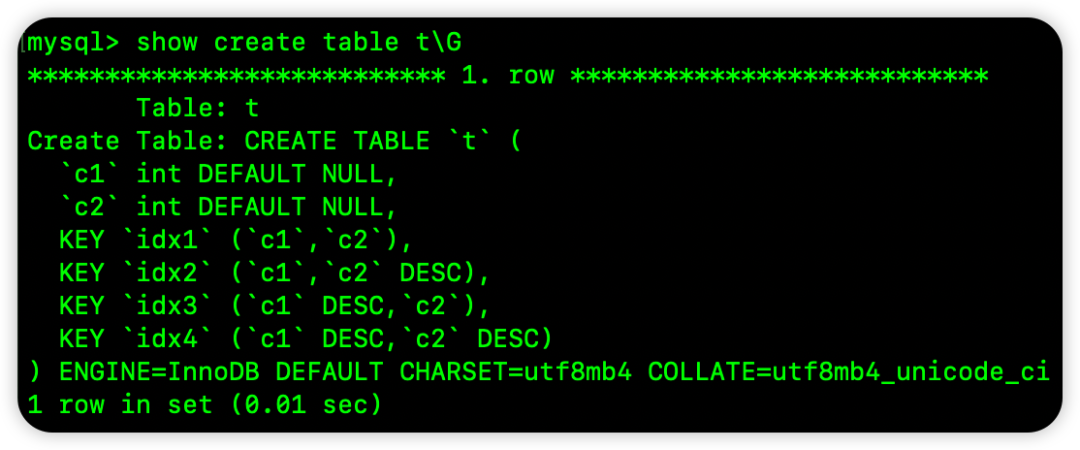
为了说明MySQL 8.0对降序索引的支持,请看下面的表定义对比:
MySQL 5.7中,索引定义的方向被忽略:
mysql> show create table t\G
*************************** 1. row ***************************
Table: t
Create Table: CREATE TABLE `t` (
`c1` int(11) DEFAULT NULL,
`c2` int(11) DEFAULT NULL,
KEY `idx1` (`c1`,`c2`),
KEY `idx2` (`c1`,`c2`),
KEY `idx3` (`c1`,`c2`),
KEY `idx4` (`c1`,`c2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
MySQL 8.0中,索引定义的方向被保留:
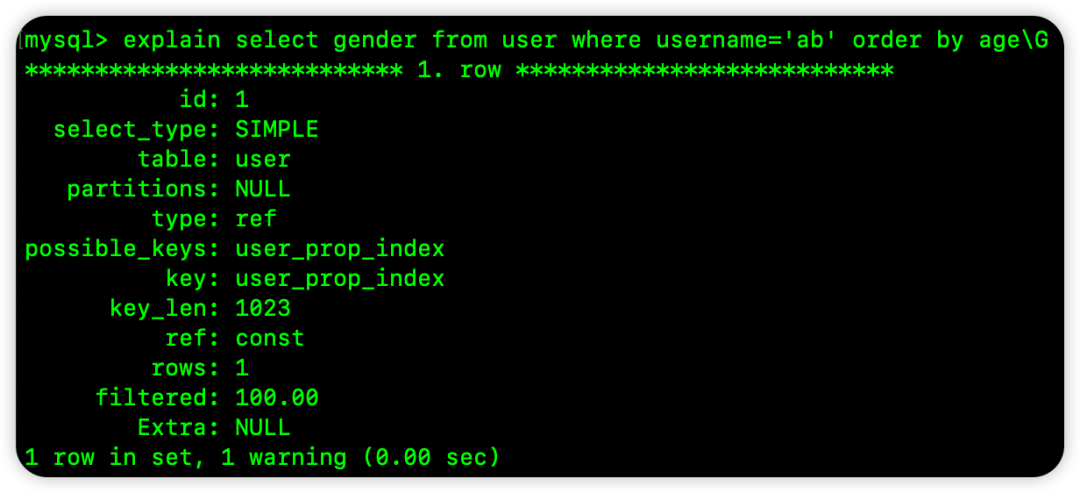
2.4 案例四:等值查询后,按索引后续列排序
select gender from user where username='ab' order by age
WHERE 条件对 username 进行了等值匹配。在索引树中,当 username 固定为 'ab' 时,其下的数据是按照 age 进行有序组织的,因此这个排序可以使用索引。
2.5 案例五:等值查询后,按非连续的索引列排序
select gender from user where username='ab' order by address
虽然 address 也在联合索引中,但当 username 固定后,数据首先按 age 排序,其次才是 address。因此,直接按 address 排序无法利用索引的有序性。
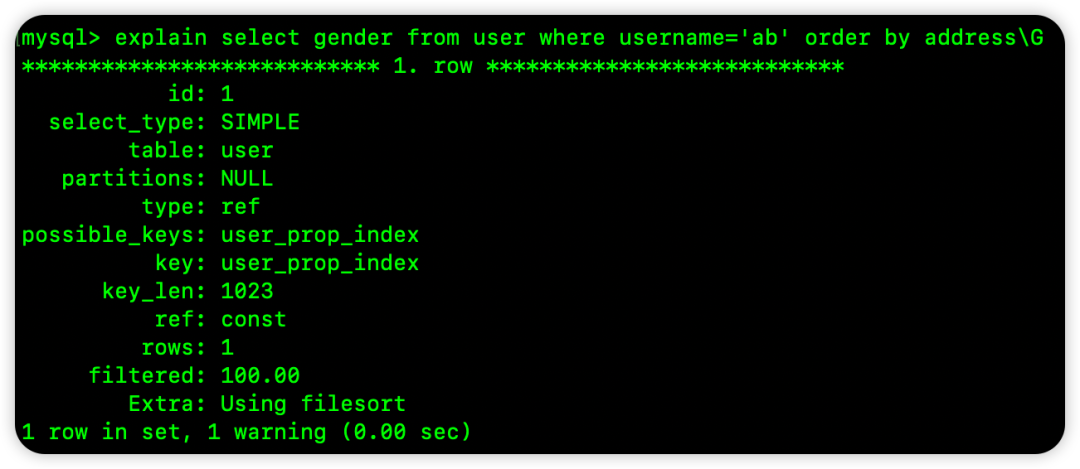
Extra: Using filesort 表明需要额外排序。
2.6 案例六:范围查询后的排序
select gender from user where username like 'a%' order by age
WHERE 条件使用了范围查询(LIKE 'a%')。从索引树中取出满足 username like 'a%' 的所有行时,这些行的 username 是有序的,但每个 username 下的 age 可能有序,整体 age 字段却是无序的,因此无法使用索引排序。
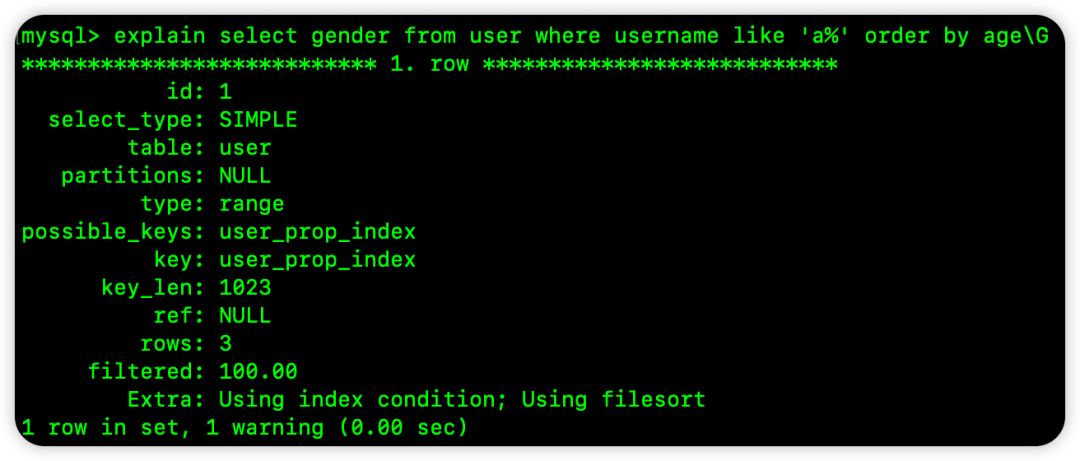
Extra: Using index condition; Using filesort 中的 Using filesort 说明了这一点。
注意:IN 和 BETWEEN 也属于范围查询,可能导致无法使用索引排序。
2.7 案例七:范围查询,但排序字段与索引顺序匹配
select gender from user where username like 'a%' order by username,age
虽然 WHERE 是范围查询,但排序字段 username, age 恰好是索引的前两列,且顺序一致。从索引中取出满足条件的数据时,其顺序本身就是按照 username, age 排列的,因此可以直接使用。
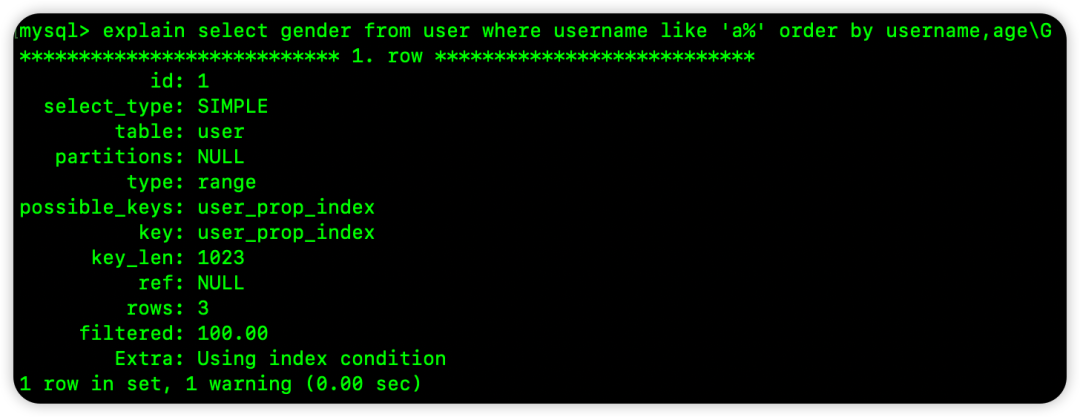
Extra 中只有 Using index condition,没有 Using filesort。
2.8 案例八:排序字段包含非索引列
select gender from user where username like 'a%' order by username,gender
排序字段中包含了不在联合索引中的 gender 列,显然无法利用当前索引完成排序。
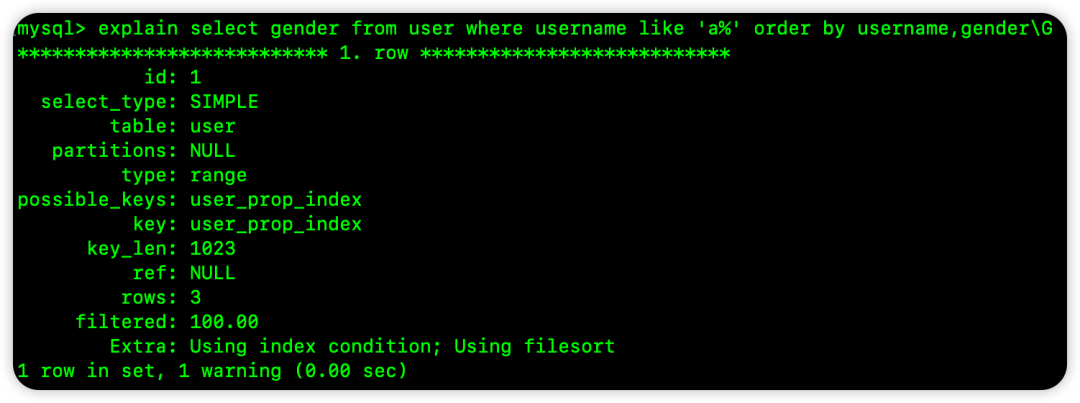
Extra: Using index condition; Using filesort。
总结:判断能否使用索引排序,关键在于审视根据WHERE条件从索引树中定位到的数据集合,其自然顺序是否恰好满足 ORDER BY 的要求。如果是,则能用;否则,就需要进行额外的filesort。
3. 其他特殊情况
3.1 多表连接查询中的排序
在多表连接查询中,如果希望利用索引排序,那么 ORDER BY 子句中的所有字段必须都来自驱动表(即执行计划中的第一张表)。
以下是一个多表连接查询的例子及其变体,展示了不同 ORDER BY 对索引排序的影响:
-
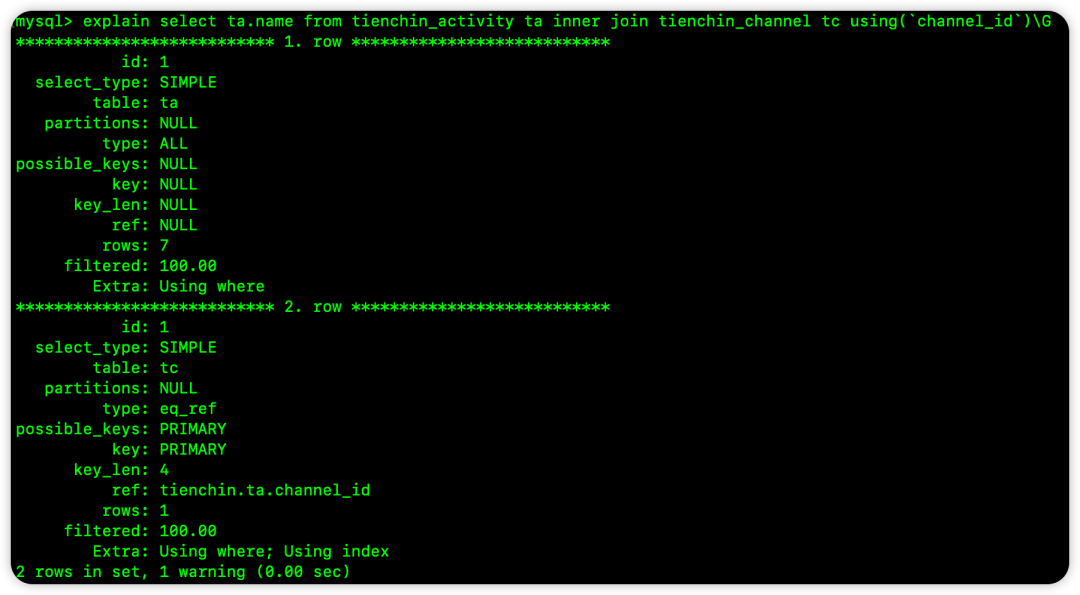
基础查询执行计划,ta 表是驱动表:
-
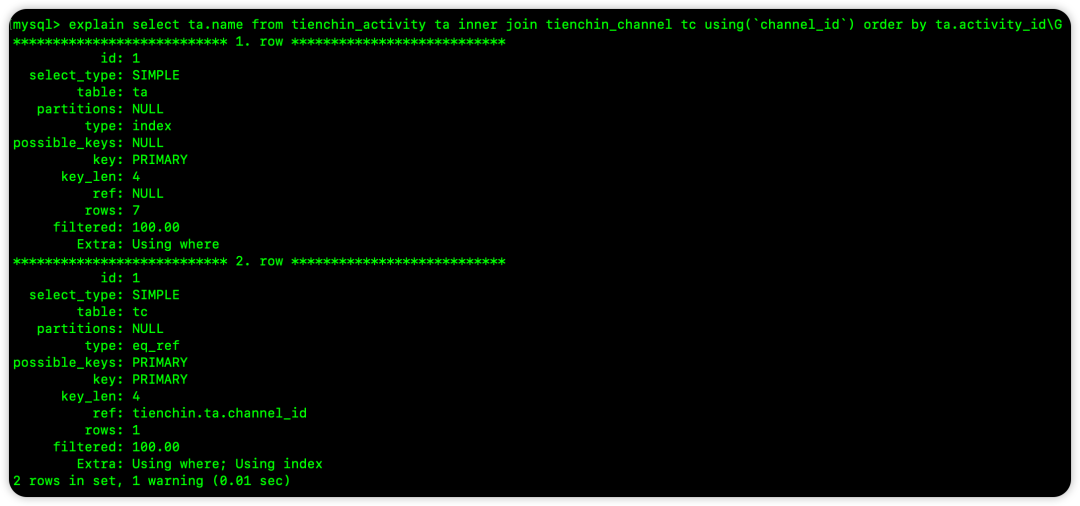
ORDER BY 驱动表(ta)的主键,可以使用索引排序:
-
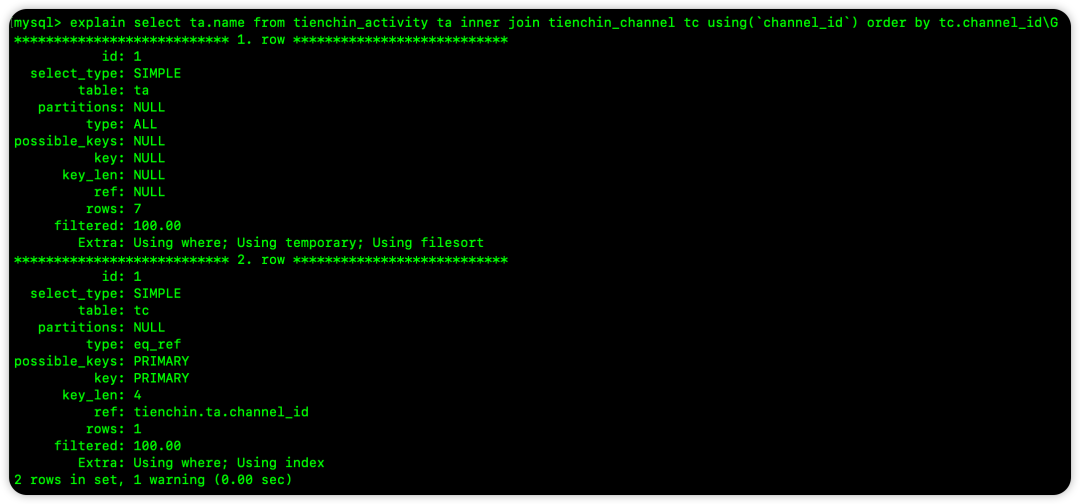
ORDER BY 被驱动表(tc)的字段,无法使用索引排序,且可能出现 Using temporary:
-
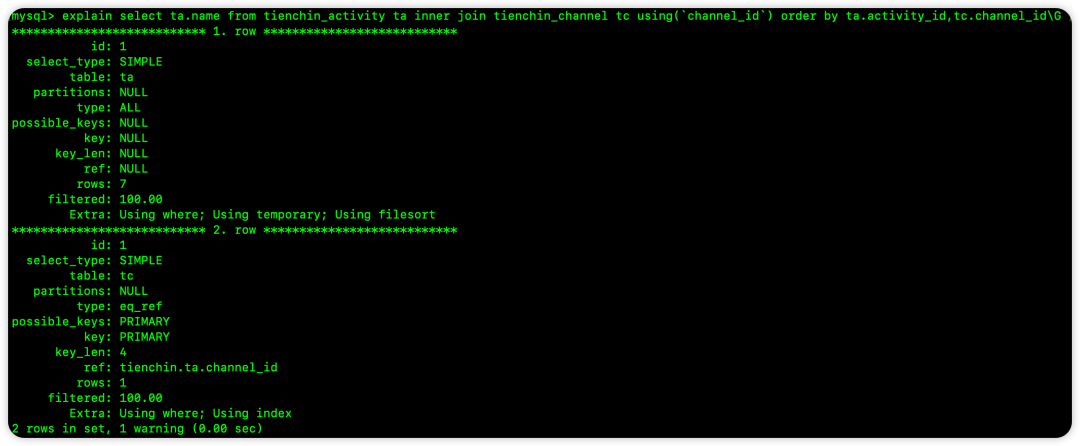
ORDER BY 涉及两张表的字段,同样无法使用索引排序:
3.2 ORDER BY NULL 的作用
在MySQL 8.0之前,使用 GROUP BY 进行分组后,结果集默认会按照分组字段进行排序。如果不需要这个排序,可以通过 ORDER BY NULL 来明确告知优化器跳过排序步骤,从而提高性能。从MySQL 8.0开始,GROUP BY 默认不再进行隐式排序,因此 ORDER BY NULL 就不再是必要的了。
4. 小结
合理地利用索引进行排序是SQL性能优化的重要手段。核心在于让 ORDER BY 子句与索引的定义(字段顺序和排序方向)对齐,并注意查询条件(特别是范围查询)和连接查询对排序路径的影响。通过 EXPLAIN 查看执行计划,关注 type 和 Extra 字段,是判断是否使用了索引排序的直接方法。在实际开发中,结合业务逻辑设计合适的索引,可以显著提升数据库的排序查询性能。
如果你想了解更多数据库相关的深度技术讨论或实战案例,欢迎来到云栈社区与更多开发者一起交流学习。
 发表于 2026-3-12 06:58:17
|
查看: 100|
回复: 0
发表于 2026-3-12 06:58:17
|
查看: 100|
回复: 0
