为什么是“再聊”呢?因为关于聚簇索引这个话题,我之前已经写过相关的文章,但总觉得意犹未尽,一些关键细节和实战思考还有待深入。今天,我们就来把这块硬骨头啃得更透彻一些。
1. 什么是聚簇索引
数据库的索引可以从不同维度进行分类,聚簇索引(Clustered Index)便是其中重要的一种。有时候你也会看到有人称之为“聚集索引”,与之相对的概念则是“非聚簇索引”或“二级索引”。
严格来说,聚簇索引并非一种独立的索引类型,而是一种数据的存储方式。在 MySQL 的 InnoDB 存储引擎中,所谓的聚簇索引,其实就是将索引和数据行存放在同一棵 B+Tree 中:数据行就存放在叶子节点里,而“聚簇”二字,形象地描述了键值(索引)与对应的数据行紧密“簇拥”在一起的物理状态。
假设我们有以下数据表:
| id(主键) |
username |
age |
address |
gender |
| 1 |
ab |
99 |
深圳 |
男 |
| 2 |
ac |
98 |
广州 |
男 |
| 3 |
af |
88 |
北京 |
女 |
| 4 |
bc |
80 |
上海 |
女 |
| 5 |
bg |
85 |
重庆 |
女 |
| 6 |
bw |
95 |
天津 |
男 |
| 7 |
bw |
99 |
海口 |
女 |
| 8 |
cc |
92 |
武汉 |
男 |
| 9 |
ck |
90 |
深圳 |
男 |
| 10 |
cx |
93 |
深圳 |
男 |
那么,它的聚簇索引结构大致如下图所示:
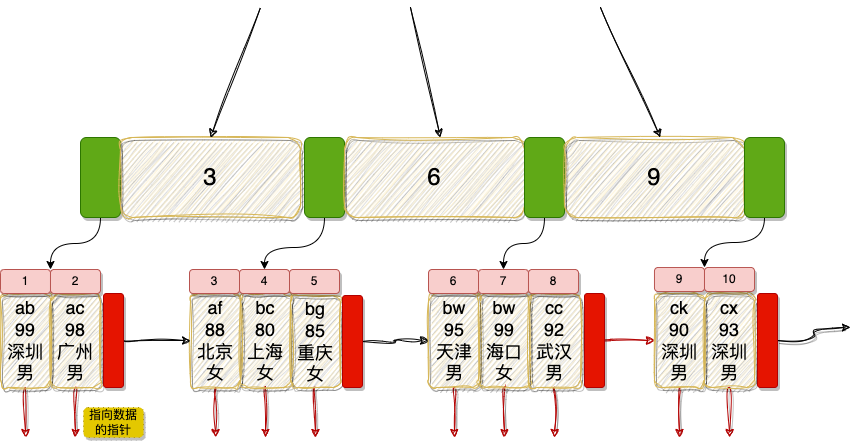
可以看到,叶子节点中同时保存了主键值(索引)和完整的数据行,而非叶子节点(枝节点)则仅存放主键值(索引)用于导航。
请思考一个问题:MySQL 表中的数据在磁盘上显然只能保存一份,不可能存两份。因此,在一个表中,有且仅有一个聚簇索引。
2. 聚簇索引和主键
不少开发者容易混淆这两个概念,甚至将它们直接划等号,这是一个需要澄清的误区。
在某些数据库系统中,允许开发者自由指定哪个索引作为聚簇索引。但在 MySQL 的 InnoDB 引擎中,规则是确定的:
- 如果表定义了主键(PRIMARY KEY),那么主键就是聚簇索引。
- 如果没有主键,则选择第一个唯一且非空(UNIQUE NOT NULL)的索引作为聚簇索引。
- 如果连这样的索引都没有,InnoDB 会隐式地创建一个名为
GEN_CLUST_INDEX的隐藏主键(通常是自增的 row id)来充当聚簇索引。
小提示:虽然存在隐式主键的机制,但强烈建议主动为表定义主键。因为隐式主键是全局自增的,所有插入操作都可能竞争这个自增锁,极易形成性能热点。
基于以上规则,我们可以清晰地理清两者的关系:
- 聚簇索引不一定是主键索引(在无主键但有无索引的场景下)。
- 主键索引一定是聚簇索引(在 InnoDB 引擎中)。
3. 聚簇索引的优缺点
优点
- 数据聚集存储:可以将逻辑上相关的数据物理上存放在一起。例如,一个用户订单表,如果使用
(用户ID, 订单ID)作为复合主键(聚簇索引),那么同一用户的所有订单记录在磁盘上大概率是相邻的。查询某个用户的所有订单时,磁盘 I/O 次数会显著减少,速度更快。
- 避免回表,访问高效:由于索引和数据在同一棵 B+Tree 上,通过聚簇索引查找数据是“直达”的。相比之下,通过非聚簇索引(二级索引)查询时,需要先查到主键值,再“回表”到聚簇索引中查找数据行,多了一次索引树的查找。
- 覆盖索引优势:承接第一点的例子,如果查询只需获取
用户ID和订单ID,那么查询甚至不需要访问叶子节点中的数据行,直接在枝节点或部分叶子节点中就能拿到结果,效率极高。
缺点
- 对全内存操作场景优势减弱:聚簇索引的核心优势在于减少磁盘 I/O。如果应用的数据全集都能装入内存,直接在内存中操作,那么聚簇索引在物理存储上的优化带来的收益就不那么明显了。
- 插入性能受主键顺序影响:如果主键是顺序递增的(如自增ID),新数据只需追加到 B+Tree 末尾,效率很高。但如果主键是随机的(如 UUID),新数据可能插入到中间某个位置,这就可能引发页分裂——为了给新数据腾出空间,需要移动大量现有数据,甚至分配新的数据页。页分裂不仅降低插入速度,还会导致数据页留有碎片,浪费存储空间。
- 二级索引查询需要回表:这是由存储结构决定的“硬伤”。二级索引的叶子节点存储的是主键值,而非完整数据行。因此,通过二级索引查询时,必然要经历“查二级索引 -> 得到主键 -> 回表查聚簇索引”的过程,需要扫描两棵索引树。
4. 最佳实践与思考
基于以上分析,我们在设计表时应当扬长避短。一个明确的建议是:主键尽量避免使用 UUID 这类随机值。原因有二:
- 插入效率低:如前面所述,随机插入易导致页分裂。
- 占用空间大,影响二级索引:UUID 通常长达 36 字节,远大于
bigint(8字节)。在二级索引的叶子节点中,存储的是主键值。主键值越大,单个叶子节点能存储的索引条目就越少,这会导致 B+Tree 变得更高更“瘦”。树越高,查询时需要进行的 I/O 次数就越多,性能自然下降。
那么,使用自增主键就是“银弹”吗?很多经验告诉我们,技术世界里“没有银弹”。自增主键同样有其局限性,具体是什么,我们留待下回分解。欢迎在 云栈社区 继续关注后续的技术探讨。 |  发表于 2026-3-12 06:55:19
|
查看: 145|
回复: 0
发表于 2026-3-12 06:55:19
|
查看: 145|
回复: 0
