在数据库相关的面试或性能优化讨论中,“回表”是一个高频词汇。理解回表不仅有助于写出更高效的 SQL 语句,也是深入理解 MySQL 索引机制的关键一步。
1. 索引结构
要搞明白回表,首先得了解 MySQL 中索引存储的数据结构——B+Tree。为了更好地理解 B+Tree,我们可以先看下它与 B-Tree 的区别。
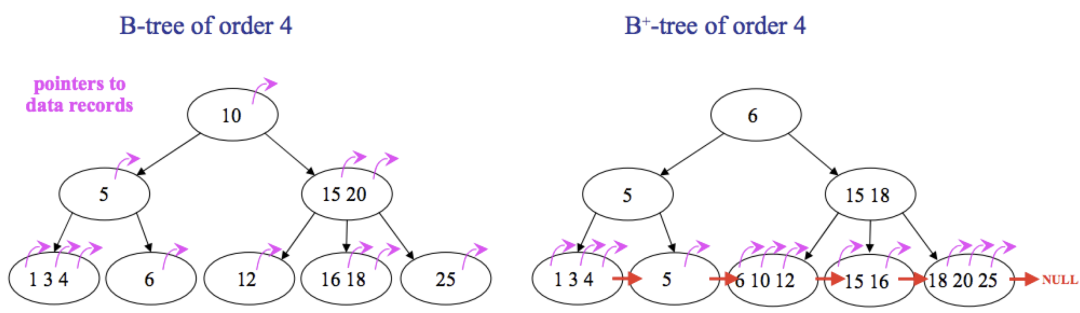
上图清晰地展示了 B-Tree 与 B+Tree 的核心差异:
- 数据指针位置:在 B-Tree 中,所有节点(包括非叶子节点)都可能带有指向具体数据记录的指针;而在 B+Tree 中,只有叶子节点才存储指向具体数据记录的指针。
- 叶子节点连接:B-Tree 的叶子节点之间是独立的;B+Tree 的所有叶子节点通过指针连接成一个有序链表。
- 查询稳定性:B-Tree 可能在非叶子层就定位到数据,导致查询效率不稳定;B+Tree 必须走到叶子节点才能获取数据,因此每次查询的路径长度是稳定的,性能更可预测。
基于这些特性,B+Tree 带来了两大优势:
- 更高的扇出,更低的树高:因为非叶子节点仅存储索引键值和指向下一级节点的指针,不存储数据记录本身,所以单个节点能容纳更多的索引项。这意味着相同数据量下,B+Tree 的高度更低,查询所需的磁盘 I/O 次数更少。
- 高效的范围查询:叶子节点间的链表结构使得范围扫描(例如
WHERE id > 100)变得非常高效,只需在叶子层顺序遍历即可。而在 B-Tree 中,范围查询可能需要在不同层级的节点间来回跳转。
那么,一个 B+Tree 究竟能存多少数据呢?以 InnoDB 存储引擎的聚簇索引为例(数据页默认大小为 16KB),我们可以做个简单估算:
假设一条数据记录大小为 1KB,那么一个叶子页大约可存储 16 条数据。
非叶子节点存储的是主键值(假设是 8 字节的 bigint)和下级页的指针(6 字节)。粗略计算,一个非叶子页能存储约 16*1024/(8+6) ≈ 1170 个指针。
因此,一个三层高的 B+Tree 大约能存储 1170 * 1170 * 16 ≈ 2190万 条记录。
在 InnoDB 中,B+Tree 的高度通常为 2 到 4 层,足以支撑千万级数据量的高效查询。这就是大多数情况下,通过主键索引查询只需要几次 I/O 操作就能定位到数据的原因。深入理解这个存储模型是后续讨论的基础,更多关于架构与存储的讨论可以在 云栈社区 的 后端 & 架构 板块找到同行交流。
2. 两类索引与回表
MySQL 的索引从物理存储角度可以分为两类:聚簇索引(Clustered Index)和二级索引(Secondary Index,也称非聚簇索引或辅助索引)。
- 聚簇索引:通常就是我们所说的主键索引。其 B+Tree 的叶子节点存储的是完整的行数据。
- 二级索引:除主键索引外的其他索引。其 B+Tree 的叶子节点存储的不是完整数据,而是该行对应的主键值。
这个根本区别导致了不同的查询路径:
- 通过主键查询:执行
select * from user where id=100。搜索主键索引的 B+Tree,在叶子节点直接拿到完整数据,查询结束。
- 通过二级索引查询:执行
select * from user where username='javaboy'。这个过程分为两步:
- 第一步:搜索
username 索引的 B+Tree,在叶子节点找到对应的主键值(例如 id=100)。
- 第二步:拿着这个主键值
100,再回到主键索引的 B+Tree 中查找,最终拿到完整的行数据。
这第二次回到主键索引树中查找数据的过程,就叫做“回表”。
显然,通过二级索引查询需要扫描两棵索引树,比直接走主键索引多了一次搜索过程。因此,在查询条件允许的情况下,优先使用主键索引通常效率更高。理解 数据库 中不同索引的工作原理,对性能调优至关重要。
3. 索引覆盖:避免回表的妙招
使用二级索引就一定会发生回表吗?并非如此。
如果查询所需要的数据列,全部包含在二级索引的叶子节点中,那么 MySQL 就不需要回表。这种情况被称为“索引覆盖”或“覆盖索引”(Covering Index)。查询的执行计划中会显示 Using index。
举个例子,假设有一张用户表 user,其结构如下:
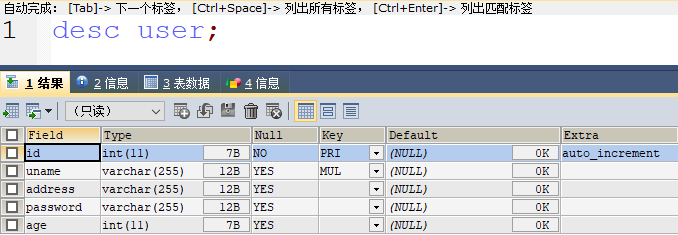
我们在 (uname, address) 上建立了一个复合索引。这个索引的叶子节点会存储主键值以及 uname 和 address 这两个字段的值。
现在执行以下查询:
explain select uname,address from user where uname='javaboy';
其执行计划如下图所示:

可以看到,type 为 ref 表示使用了索引,最关键的是 Extra 列显示了 Using index。这表示该查询只需要扫描 (uname, address) 这个二级索引树就能获得全部所需数据(uname 和 address),无需回表,效率极高。
4. 扩展:为什么建议使用自增主键?
结合前面对索引结构的分析,我们很容易理解为什么数据库设计里经常推荐使用自增主键(如 AUTO_INCREMENT),这主要基于两点技术优势:
- 节省索引空间:二级索引的叶子节点存储的是主键值。使用占用空间小的自增整数(
int 或 bigint)作为主键,可以减小每个二级索引叶子节点的大小,从而在整体上降低 B+Tree 的高度,提升所有基于该二级索引的查询效率。
- 提高插入性能:自增主键的插入总是在当前最大 ID 之后追加,不会导致 B+Tree 中间节点的分裂和大量数据记录的移动,插入操作更快、更平滑。反之,如果使用无序的主键(如 UUID),新数据可能插入到索引中间位置,容易引发页分裂,影响写入性能。
当然,技术选型需服务于业务。如果业务上无法使用自增主键(如分库分表场景需要全局唯一 ID),则需要在满足业务约束的前提下,选择最合适的方案。
希望通过以上的讲解,你对 MySQL 的“回表”机制以及如何利用“索引覆盖”来避免回表有了清晰的认识。理解这些底层原理,是进行有效的 MySQL 性能优化的第一步。想深入研究更多 数据库 实战技巧和原理剖析?欢迎来 云栈社区 的 数据库/中间件/技术栈 板块,与更多开发者一起交流成长。
 发表于 2026-3-12 06:53:34
|
查看: 118|
回复: 0
发表于 2026-3-12 06:53:34
|
查看: 118|
回复: 0
