黄仁勋的战略目光并未局限于并购某个单一的推理应用厂商,其核心目标直指构建“堆栈深度”。自2024年下半年起,NVIDIA通过总额超过300亿美元的战略投资、授权协议与人才整合,实现了对推理技术栈的全方位渗透。这一系列举措绝非简单的资产扩张,而是借助资本手段系统性地获取关键技术能力。其布局逻辑清晰地映射在五个核心的技术维度:网络、编排、模型优化、架构IP以及推理分发。
短短数月间,这种战术便复刻了CUDA耗时18年才建立起的软件生态壁垒。在CES 2026上,Vera Rubin NVL72系统的问世正式标志着这种堆栈深度的交付能力:通过六款芯片的协同设计,实现了吞吐量10倍增长与成本下降90%。这不再是边际式的改良,而是全栈掌控所带来的代际性能压制。
一、五层架构:重塑推理基础设施的价值标准
英伟达将数据中心重新定义为“AI工厂”,其核心评价指标已从纯粹的算力峰值转向“每瓦吞吐量”的效率竞争。通过深度掌控下述五个技术层级,英伟达正致力于消除芯片、存储与网络之间的物理与性能界限:
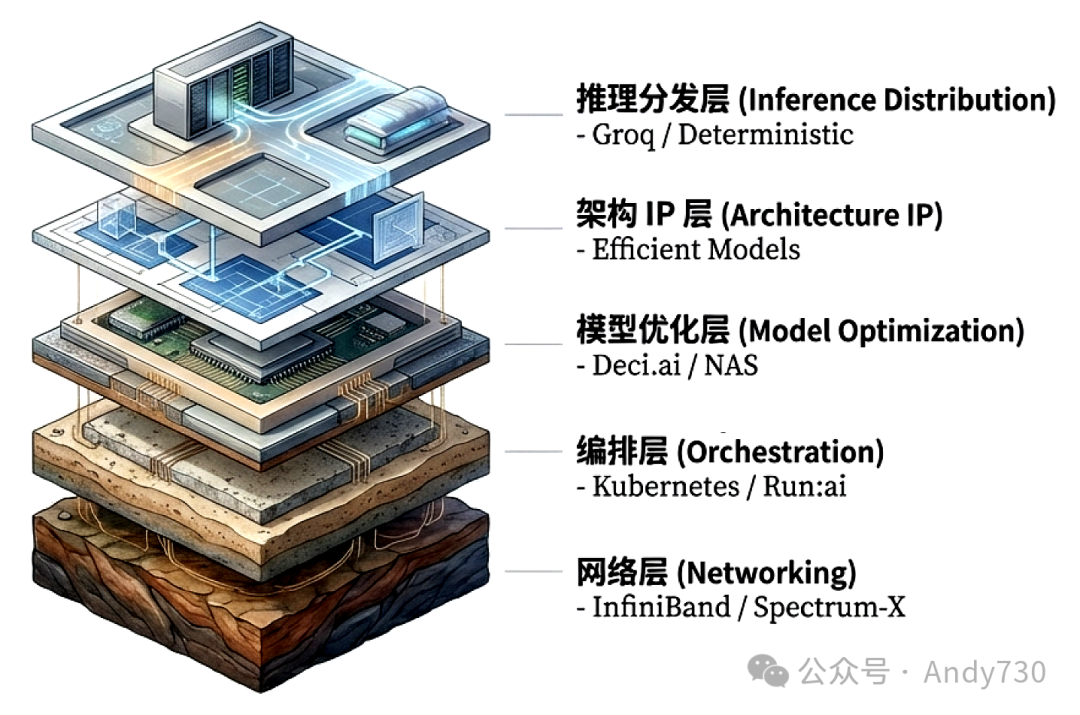
- 网络层:决定GPU跨节点通信效率的命脉。通过InfiniBand、NVLink及高性能以太网技术,确保计算集群在规模化扩张时,性能仍能保持线性增长。
- 编排层:实现算力资源的动态化、池化分配。利用先进的虚拟化与调度技术,将离散的GPU集群整合为高流动性、可弹性伸缩的“计算网络”。
- 模型优化:衔接研究原型与生产部署的关键桥梁。运用量化、剪枝及神经架构搜索(NAS)等技术,显著提升模型在特定硬件上的运行效率与成本效益。
- 架构IP:通过SSM-Transformer混合架构或MoE(混合专家模型)等底层创新,在给定的物理限制内,实现计算能力与存储资源的最优平衡。
- 推理分发:大规模AI服务可靠交付的最后一步。确立确定性延迟保障、智能批处理策略及多级缓存机制,将模型能力转化为高可用的商业服务。
二、硬件基石:Vera Rubin与“极致协同设计”
Vera Rubin平台代表了英伟达迄今为止最激进的软硬件协同设计成果,其设计初衷便是直接攻克“存储墙”与“通信带宽”这两大推理性能瓶颈。
- Vera CPU:搭载88个Olympus核心,通过高达1.8TB/s的NVLink-C2C链路实时驱动Rubin GPU,从根本上消除了传统的CPU-GPU通信瓶颈。
- Rubin GPU:将推理性能提升至50 PFLOPS,达到Blackwell架构的5倍。其核心突破在于NVFP4 Tensor Core架构,仅以1.6倍的晶体管增量便实现了5倍的性能跃升。此外,HBM4存储提供了高达22TB/s的带宽,直接缓解了大规模参数模型的数据传输压力。
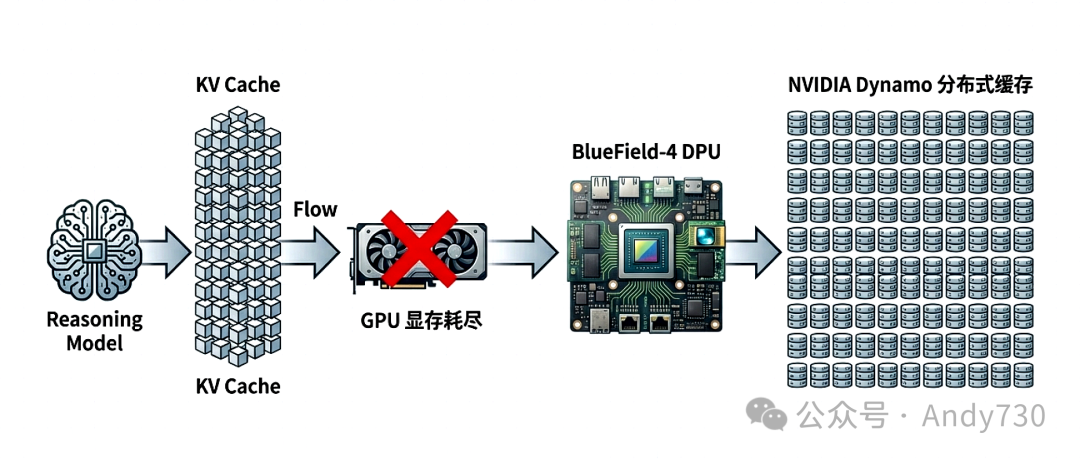
- BlueField-4 DPU:它已不再仅仅是智能网卡,而是进化为一个“分布式上下文内存平台”。通过运行NVIDIA Dynamo软件,可为单个机架扩展多达16TB的分布式内存,旨在彻底解决长文本推理中KV Cache暴增带来的显存难题。
- Spectrum-X CPO:全球首款光子以太网交换机,利用共封装光学技术(CPO)将互联带宽推至102.4Tb/s,从物理层面极大改善了大规
模集群互联的功耗与效率。
三、资本布局:关键收购与技术支点的时间线
英伟达通过一系列极具穿透力的战略交易,特别是在以色列等技术高地的布局,迅速补齐了自身的技术拼图。以下是其构建推理堆栈深度的关键里程碑:
- Mellanox(2020年4月,69亿美元):奠定了其在网络层的统治性地位。其InfiniBand技术已成为DGX SuperPOD的底层标准,让英伟达掌握了GPU集群“对话”的根本方式。
- Run:ai(2024年4月,约7亿美元):大幅强化了编排层能力。该软件实现了GPU资源的池化与动态切片调度。值得注意的是,英伟达计划将其适配至竞争对手的硬件,意图使自身标准成为行业通用规范。
- Deci AI(2024年5月):锁定了模型优化这一关键环节。其NAS技术能实现3至15倍的推理加速。与TensorRT结合,英伟达构建了从模型研发到生产部署的全链路优化闭环。
- Enfabrica授权与投资(2024年):强化了针对AI工作负载的高性能以太网解决方案,确保英伟达在InfiniBand之外,于以太网生态中也拥有强大竞争力。
- Groq战略授权(2025年12月,估值约200亿美元):通过非排他性授权与核心人才吸纳,英伟达吸收了其在确定性、低延迟推理方面的宝贵经验。更关键的是,Groq的架构逻辑为英伟达提供了规避CoWoS先进封装与HBM供应链限制的潜在替代路径。
- AI21 Labs(传闻并购中):旨在吸纳长文本处理与内存高效型模型设计(如Jamba架构)领域的顶尖人才,进一步加强在该细分市场的技术壁垒。
四、软件驱动的性能表现:堆栈深度的实证
堆栈深度的商业价值,最终体现在其惊人的性能演进速度上。2026年1月的测试数据显示,在完全相同的GB200 NVL72硬件上运行DeepSeek-R1模型,仅通过TensorRT-LLM的软件迭代,推理吞吐量相较三个月前就增长了2.8倍。而在HGX B200平台上,开启NVFP4新架构与多标记预测(MTP)技术后,吞吐量提升超过了4倍。
这种突破性提升主要得益于两项核心软件优化:
- 解耦服务(Disaggregated Serving):将计算密集的预填充(Prefill)阶段与内存访问密集的解码(Decode)阶段,动态分配至不同的GPU组执行,实现了计算资源利用率的最大化。
- 内核级优化:利用程序化依赖启动(PDL)等技术,显著降低了GPU内核的启动延迟,减少了空闲等待时间。
五、行业竞争格局:护城河的差异化与垂直挑战
尽管各大云服务提供商(CSP)都在尝试垂直整合,但英伟达通过构建“堆栈深度”,已然建立了一道难以逾越的差异化护城河。
1. 云原生巨头的垂直局限(Google/Amazon/Microsoft)
- Google (TPU v7 / JAX):虽然在自研TPU与JAX框架上实现了极高的软硬件协同,但其优势基本被禁锢在其封闭的云生态内部。英伟达的优势恰恰在于其中立性,能够将其全栈能力输出给主权云、私有数据中心及广大初创企业。
- Amazon (Trainium 3) & Microsoft (Maia 100):虽然通过自研芯片降低了部分运营成本,但它们总体上仍处于“补课”阶段。在算子库的深度与广度、编排调度的灵活性、以及与海量第三方模型的即插即用适配性上,仍落后英伟达1-2个代际。对这些巨头而言,造出匹敌的芯片只是第一步,真正的挑战在于缺乏像TensorRT或Run:ai这样贯穿全局的优化工具链。
2. 芯片竞争对手的软件短板(AMD/Intel)
- AMD (MI400 / ROCm):尽管MI400的硬件参数(如内存容量和带宽)在纸面上已追平甚至超越英伟达,但其ROCm软件栈在关键的推理分发层级缺乏深度与成熟度。AMD提供的是优秀的芯片,而英伟达提供的是“让芯片发挥出极限性能”的全栈架构创新。
- Intel (Gaudi 4):其设计主要针对特定工作负载进行优化,难以在通用AI任务的软件生态丰富度和全栈解决方案的完整性上与英伟达竞争。
3. 工作负载特定化的组合防御策略
英伟达正在针对不同的推理细分市场建立多维度的组合拳:
- 超大型模型推理:依靠Vera Rubin平台与HBM4(22TB/s带宽)确保绝对的性能上限。
- 超低延迟场景:借鉴并融合Groq风格的确定性架构思想,实现亚毫秒级的极速响应。
- 长文本处理工作负载:通过BlueField-4上下文内存平台,将KV Cache的存储能力从单张GPU扩展至整个机架。
英伟达的真正护城河,已不在于单一芯片的性能,而在于模型与最终用户之间每一层技术栈的绝对掌控与持续创新。
六、未来展望:从数据中心到“物理AI”
英伟达的推理技术布局,其终极指向是具身智能与物理AI(Physical AI)。
- Cosmos世界模型:将计算过程本身转化为训练数据,生成符合物理定律的合成场景,为自动驾驶、机器人训练提供无限、合规的模拟环境。
- Alpamayo推理VLA:首个宣称具备因果推理能力的视觉-语言-行动模型,旨在为机器人等智能体完成复杂序列决策提供核心支持。
- 开放生态引领:通过主导开源模型生态(如Nemotron、Groot),英伟达确保其硬件与软件栈始终是所有前沿AI能力首选的底层载体。
目前,英伟达已完成从硬件供应商向AI推理全栈标准定义者的角色跃迁。对于所有竞争对手而言,追赶英伟达已不再仅仅是制造一颗更好的芯片,而是需要复刻并持续运营一套同样深邃、且能自我强化的技术生态系统。关于AI基础设施的更多深度讨论,欢迎在云栈社区交流。 |  发表于 2026-1-24 15:45:05
|
查看: 126|
回复: 0
发表于 2026-1-24 15:45:05
|
查看: 126|
回复: 0
