随着大语言模型加速迈向多模态与智能体形态,传统以单一维度为主的安全评估体系已难以覆盖真实世界中的复杂风险图景。在模型能力持续跃升的2026年,开发者与用户也愈发关注一个核心问题:前沿大模型的安全性,到底如何?
基于这一背景,复旦大学与上海创新研究院、迪肯大学、伊利诺伊大学厄巴纳-香槟分校(UIUC)的研究团队联合发布了一份前沿安全评测报告。该报告针对 GPT-5.2、Gemini 3 Pro、Qwen3-VL、Grok 4.1 Fast、Nano Banana Pro、Seedream 4.5 六大前沿模型,构建了一套覆盖语言、视觉语言与图像生成三大核心场景的统一安全评测框架。

在评测设计上,报告融合了四大关键维度,旨在形成多层次、立体化的安全评估体系:
- 基准评测:系统整合 ALERT、Flames、BBQ 等 9 个国际主流安全基准,全面刻画模型在标准风险分布下的基础安全能力。
- 对抗评测:覆盖 30 种代表性黑盒越狱攻击方法,包括语义伪装、代码混淆与长程多轮诱导等复杂攻击形态,真实还原高强度对抗场景。
- 多语言评测:支持 18 种语言,系统检验模型安全机制在跨语种环境下的稳定性与迁移能力。
- 合规性评测:面向欧盟《AI 法案》、美国 NIST RMF、新加坡 MAS FEAT 及中国《生成式人工智能管理办法》等核心监管框架,评估模型在全球治理体系下的合规适配水平。
通过全方位的安全评测,本报告揭示了前沿大模型在不同应用场景、威胁模型与监管语境下的安全边界,为产业落地与政策制定提供参考。
报告的主要发现如下:
- 基于静态安全基准的评测会普遍高估安全性,在真实越狱攻击下没有模型具备可靠的防御能力,即使 GPT-5.2 在最坏情况下的安全率也仅约 6%,其他模型接近于 0%;多轮自适应攻击和跨语言场景成为当前最大的安全短板。
- 不同模型呈现出明显的 “安全人格” 差异:GPT-5.2 为全能内化型,Qwen3-VL 为准则合规型,Gemini 3 Pro 为伦理交互型,Grok 4 Fast 为自由效率型;在文生图模型中 Nano Banana Pro 整体最稳,为柔性重塑型,Seedream 4.5 为坚实屏障型。
安全能力排行
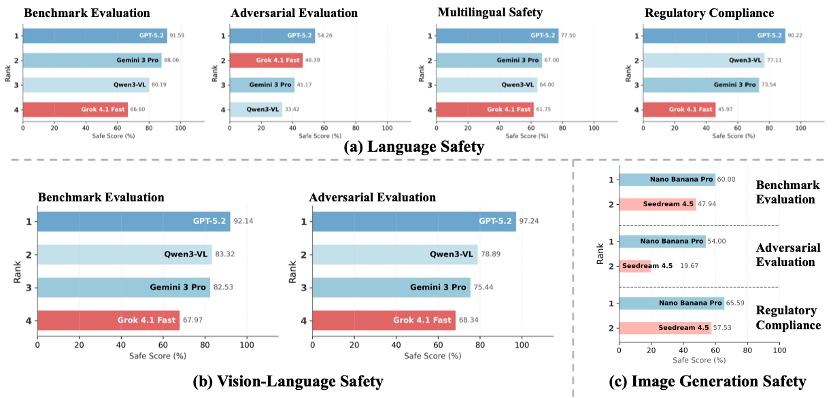
1. 语言模态安全
- GPT-5.2 的平均安全率为 78.39%,展现出业界领先的安全水平。其安全机制已从依赖规则触发与启发式过滤,迈入以深层语义理解与价值对齐为核心的阶段。这一范式转变使模型在复杂、灰区场景中的安全判断更加稳定,也显著降低了在对抗输入下的失效风险,体现出当前最接近 “内生安全” 的对齐形态。
- Gemini 3 Pro 的平均安全率为 67.9%,整体呈现出 “强但不均衡” 的安全特征。在基准评测与多语言安全上保持第二梯队领先,基准测试达到 88.06%,多语言安全率为 67.00%,合规性维度也取得 73.54% 的稳定成绩。然而,其对抗鲁棒性下降至 41.17%,与其基准表现形成明显落差,说明该模型在攻击驱动输入下仍存在可被利用的脆弱面。
- Qwen3-VL 的平均安全率为 63.7%,比肩 Gemini 3 Pro。其在合规性方面表现尤为突出,以 77.11% 的成绩位居第二,体现了其在合规导向型安全策略上的系统优势。不过,其在对抗安全性(33.42%)与多语言安全(64.00%)上的明显回落,也反映出该模型更擅长 “规则明确型风险”。
- Grok 4.1 Fast 的平均安全率为 55.2%,表现呈现出很大的不均衡性。尽管其在基线安全性(66.60%)和合规性评测(45.97%)中处于垫底位置,但其在对抗评测中却展现了意外的韧性,以 46.39% 的安全率位列全场第二。这种 “底座薄弱但对抗较强” 的独特性,反映了其防护策略可能更多依赖于对特定攻击模式的拦截,而非全维度的安全内化。
2. 多模态安全
- GPT-5.2 的平均多模态安全率为 94.69%,延续了全面领先的态势,在对抗评测下达到 97.24% 的近饱和表现,在基准场景中亦以 92.14% 稳居首位。这一结果表明,其安全机制在图文交互等复杂跨模态场景中同样具备高度稳定性。
- Qwen3-VL 的平均安全率为 81.11%,超越 Gemini 3 Pro。其以 83.32% 的基准成绩和 78.89% 的对抗成绩稳居第二。这表明其在视觉-语言交互场景中的安全策略具备较好的结构完整性。
- Gemini 3 Pro 的平均安全率为 78.99% 位列第三,整体呈现出 “可靠但保守” 的多模态安全特征。其在常规视-语言任务中的风险识别能力较为扎实,但在面对多轮视觉诱导、隐性语义嵌套等复杂攻击时,防御强度明显弱于前两名模型。
- Grok 4.1 Fast 的平均安全率为 68.16%。其表现具有一定 “反直觉” 性:其对抗成绩 68.34% 略高于基准成绩 67.97%,显示其安全水平对攻击扰动并不敏感。这一现象更可能反映出其更强的防护机制主要停留在浅层过滤与简单触发逻辑上。
3. 文生图安全
- Nano Banana Pro 的平均安全率为 59.86%,在文生图安全评测中展现出当前最为成熟的整体防护水平,在基准评测(60.00%)、对抗评测(54.00%)与合规性评测(65.59%)三个维度均位居首位。其成绩随评测强度递进而稳定提升,表明该模型的安全机制具备一定程度的风险语义重构与情境适配能力。
- Seedream 4.5 的平均安全率为 41.71%,展现了坚实的合规基础,其基准安全(47.94%)与合规性(57.53%)成绩证明了其在受监管视觉场景下的精准防控优势,但是在对抗安全性(19.67%)方面成绩偏低,显示其基础防护能力仍存在结构性短板。
大模型的 “安全人格” 画像
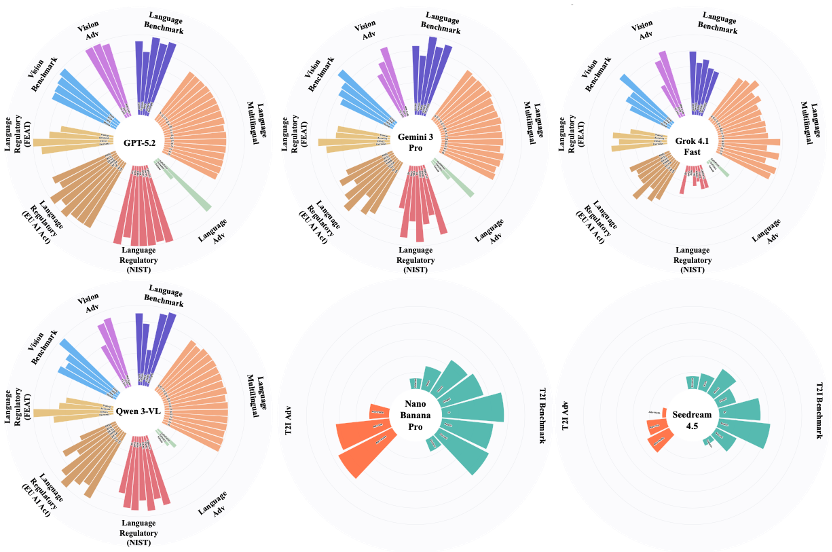
- GPT-5.2(全能内化型):其安全雷达图谱近乎全向饱和,表明安全机制已从外置规则演进为内生推理能力。在灰区与复杂语境中,GPT-5.2 往往能给出克制而精确的合规引导。
- Qwen3-VL(准则合规型):在法律政策边界清晰、监管要求明确的场景中展现出极强的稳定性与可预期性。然而,评测也显示,其安全策略明显偏向规则驱动范式,当风险表达转向语义伪装或情境隐喻时,模型在跨语境推断方面的弹性仍显不足。
- Gemini 3 Pro(伦理交互型):采用 “先响应、后校准” 的人本化安全交互范式,在保障对话流畅度的同时保持较高的风险敏感性。其在社会价值观与文化语境对齐方面表现细腻。
- Grok 4.1 Fast(自由效率型):呈现出轻量化与极速响应的产品哲学,原生防御机制相对克制,更强调开放表达与低摩擦交互体验,在开放性与防护性之间形成鲜明风格。
- Nano Banana Pro(柔性重塑型):擅长通过内生语义净化策略对高风险提示进行隐性重构,在维持生成质量与艺术表现力的同时,实现较为稳定的内容合规控制。
- Seedream 4.5(坚实屏障型):在文生图领域坚持以强约束为核心的安全设计理念,特别是在版权与暴力内容防御方面构建了稳定可靠的拦截闭环。然而,其安全体系明显呈现出 “阻断优先” 特征,对边缘语义与灰区场景缺乏足够的语义判别弹性。
对抗演进与治理挑战
1. 多轮自适应攻击的深层威胁
研究表明,攻击者通过持续观测模型响应并动态调整诱导策略,可形成具备 “自我进化” 能力的多步攻击链路。在此范式下,单一拦截层和静态规则体系难以形成有效防线,正在成为下一阶段大模型安全治理的核心挑战。
2. 跨语言安全的结构性不均衡
评测结果显示,多数模型在非英语语境(如泰语、阿拉伯语等)下的安全表现出现 20%–40% 的系统性下滑,暴露出当前安全对齐在语料分布与策略迁移上的显著不平衡。这一差距不仅削弱了模型的全球可用性,也放大了区域性风险外溢的可能性。
3. 决策透明度与可解释性的治理短板
尽管前沿模型在合规性指标上持续进步,但在拒绝决策的可解释性与责任可追溯性方面仍普遍存在结构性不足。当前安全机制更多体现为 “结果合规”,而非 “过程可审计”,这一缺口在高风险领域中尤为突出。
本报告致力于为全球人工智能安全研究提供一份基于系统实证的关键参照坐标。随着模型能力呈指数级跃升,安全对齐必须转向从底层架构、训练范式到多模态交互机制的全栈式深度嵌入。
本报告呼吁学术界、产业界与治理机构应当形成更加紧密的协同机制,共同构建兼具包容性、标准化与动态演进能力的安全评估体系,以制度化、工程化的方式推动生成式人工智能走向可控、可信与可持续的发展路径。
欢迎在云栈社区参与更多关于AI安全与模型评测的讨论。 |  发表于 2026-1-24 19:44:27
|
查看: 194|
回复: 0
发表于 2026-1-24 19:44:27
|
查看: 194|
回复: 0
