
上一篇文章《没想到「少样本」微调SAM3效果竟然这么好~》中,我分享了用50张“少样本”数据对SAM3进行“耕地圈占存放”违规行为实例分割的微调过程,效果令人惊喜。之后,团队也进一步扩大了训练数据的规模和类别范围。这表明,在那些对实时性要求不高的应用场景里,这个技术方案完全值得考虑。
当然,基于对SAM3的微调经验,下一个我想要尝试在本地进行微调训练的模型就是Qwen3-VL。主要原因有两个:
- SAM3主要解决的是传统的“目标检测”和“实例分割”这类视觉任务。但按照现在大模型的发展趋势,从“看见”到“看懂”还不够,更重要的是能够支持“行动”,这也是我个人非常感兴趣的方向。
- 实现“行动”就需要借助Qwen3-VL这类视觉语言模型在“对话”和“推理”方面的能力。我在之前的文章《利好私有化,Qwen3.5发布一系列小模型(0.8B/2B/4B/9B/27B)~》中验证过Qwen3.5 0.8B小模型在图像推理上的潜力;在《强,基于Qwen3.5的无人机视觉语言导航~》中也尝试过用Qwen3-VL实现视觉语言推理导航,能看到一条有前途的技术路径。但当时使用的是在线大模型的能力,要真正落地,本地化以及模型小型化是必经之路。
这就像节后鸿蒙智行技术发布会上提到的华为WEWA架构思路:先在云端用最强算力训练一个大模型,再通过知识蒸馏的方式训练一个能部署在车端的小模型。

当然,我们做不了乘用车。以我个人的兴趣和能力,更关注的是如何将这些优秀厂商的经验,学习并应用到一些行业的有限场景中落地,比如工程机械的自主执行、无人机自主飞行等。
事实上,现在行业内不少团队都在使用Qwen3-VL作为基座模型,然后进一步训练得到各自的垂直领域模型。因此,Qwen整个团队对行业的贡献非常大,这也是近期其人事变动引发广泛关注的原因。
我手头现有的数据仍然是关于“圈占”的数据集,所以现阶段就用它来尝试对Qwen3-VL进行微调训练,主要目的是验证效果并理解整个技术流程。
微调方法的选择
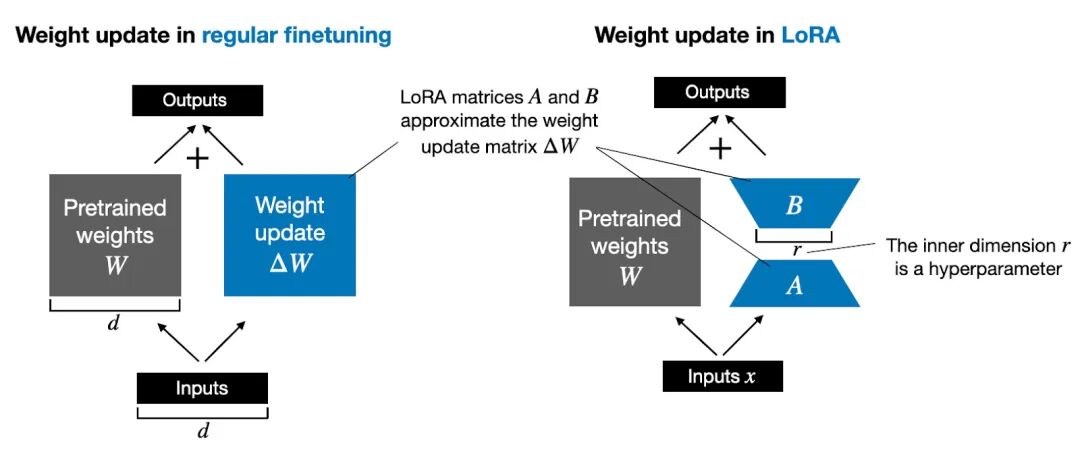
Qwen3-VL目前支持“全量微调”和“LoRA微调”两种方式。“全量微调”效果通常更好,但对计算资源的要求极高。即使使用2B的基座模型,在我们当前的环境下也无法直接运行全量微调。因此,即便是针对2B模型,我们也选择了“LoRA微调”方案。
LoRA本质上是一种低秩适应方法,它通过训练两个小的低秩矩阵来更新模型权重,而不是直接更新庞大的原始参数。这种方案有它的优势:它是一种天然的正则化方法,有助于避免过拟合和模型的“死记硬背”,让模型学到更通用的规律。当然,它的训练效率相对会低一些,但所需的资源也少得多。
数据集的准备
与SAM3可以直接使用COCO格式的数据集不同,Qwen3-VL微调需要的数据集格式更接近于对话数据集,需要进行转换。
每个样本的标注包含 image 和 conversations 两个部分。image 部分是图片的路径,conversations 则是一个列表,里面包含了对话的输入和输出。输入部分的 from 为 human,对应的 value 是用户的提示词;输出部分的 from 为 gpt,对应的 value 是检测结果的JSON格式。
{
"image": "quanzhan_qwen3_tuning/test/frame_000001.jpg",
"conversations": [
{
"from": "human",
"value": "\n请检测图像中的所有目标,目标类别包括:农业废弃物圈占存放、建筑材料圈占存放、生活垃圾圈占存放。以JSON格式输出每个目标的边界框坐标(bbox_2d)和标签(label)。"
},
{
"from": "gpt",
"value": "[{\"bbox_2d\": [380, 280, 690, 690], \"label\": \"农业废弃物圈占存放\"}]"
}
]
}

我们将之前调用在线Qwen3-VL接口的技能工具 images_qwenvl_annotation,修改为调用本地微调模型的版本进行运行。
训练与初步验证
经过LoRA微调后,模型由两部分组成:冻结的基座模型和训练得到的LoRA权重。加载模型时需要将这两部分权重合并。
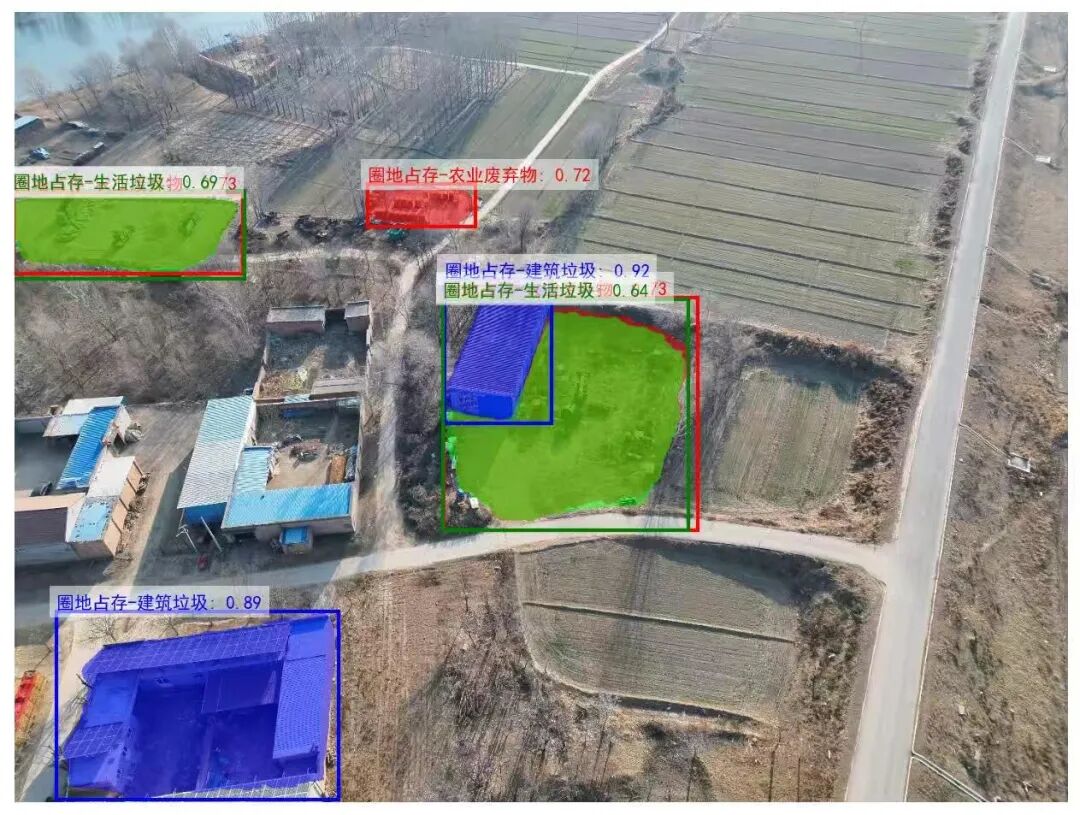
下图是使用初步微调的模型进行的一个检测示例。可以看到,此时模型倾向于将目标检测为多个独立的对象,因此针对同一类别的区域,会输出多个检测框。

然而,当使用500张数据集,经过5个epoch(约3小时)的训练后,模型的理解能力明显增强。无论是类别的判定还是目标范围的判定,都变得更加准确。

不过,针对之前的遥感数据集,模型虽然能检测出目标,但对类型的判断仍有些许不准。后续还需要继续调整迭代次数、输入图像分辨率以及模型大小(例如尝试4B模型)来进行验证和优化。

在我写这篇文章时,10个epoch的训练和4B模型的并行训练仍在进行中,但由于整体周期较长,后续的结果我会在云栈社区的 开源实战 板块与大家继续分享探讨。
一些实践思考
今天的实验表明,在当前许多非实时性场景中,同行们可能习惯性地使用YOLO这类模型。但YOLO通常需要更大的训练样本,且泛化能力相对稍弱。根据我这段时间的验证,在这些场景下,其实可以考虑SAM3以及Qwen3-VL这类参数较小的大模型。它们在少样本学习、复杂语义理解方面展现出了独特的优势,为 计算机视觉 任务的私有化部署提供了新的思路。
 发表于 2026-3-10 07:16:37
|
查看: 246|
回复: 0
发表于 2026-3-10 07:16:37
|
查看: 246|
回复: 0
