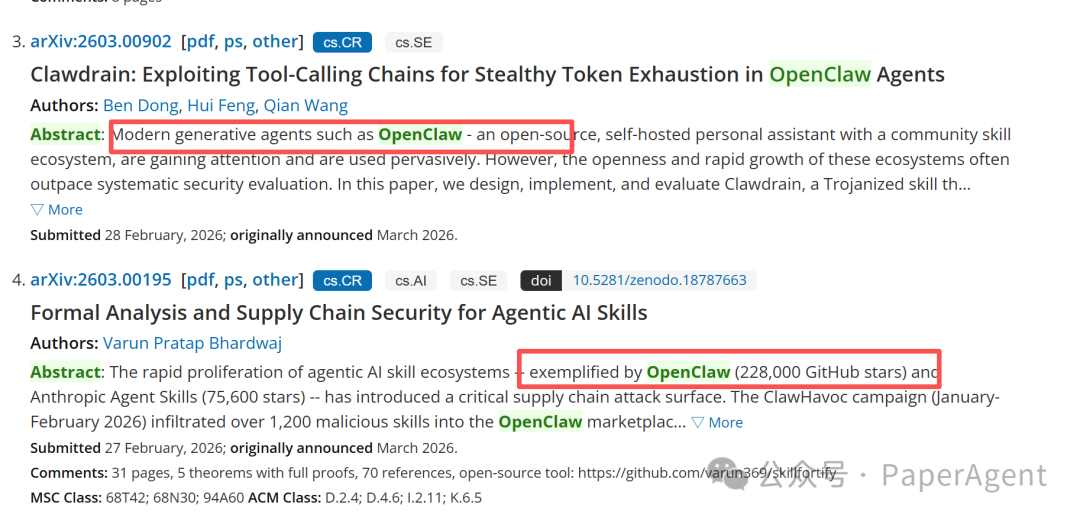
最近,OpenClaw(拥有超过29.5万GitHub星标)作为最大的开源AI代理框架,其Skill(技能)生态系统的安全性正引发学术界的深度关注。本文将介绍两篇最新发布的安全研究论文:一篇探讨了名为 Clawdrain 的隐蔽令牌耗尽攻击,另一篇则提出了首个形式化的防御框架 SkillFortify。这两篇研究分别从攻击与防御两个维度,揭示了OpenClaw技能生态背后潜藏的深层安全风险。
OpenClaw生态面临的安全现实
在深入论文细节之前,有必要了解当前OpenClaw生态所面临的安全挑战:
- ClawHavoc攻击事件(2026年1-2月):攻击者向OpenClaw技能市场渗透了超过1,200个恶意技能,用于部署AMOS凭证窃取器。
- CVE-2026-25253:这是首个针对Agentic AI系统的CVE,暴露了OpenClaw技能运行时存在的远程代码执行(RCE)漏洞。
- MalTool基准:收录了6,487个针对LLM代理的恶意工具,这些工具能够绕过VirusTotal等传统检测手段。
现有的防御工具(如Snyk agent-scan、Cisco skill-scanner)大多采用启发式检测,存在根本性局限。正如Cisco文档中承认的:“未发现风险不代表没有风险”。这也凸显了对更强健安全方案的需求。
Clawdrain:通过工具调用链实现隐蔽的令牌耗尽攻击

核心思想:该攻击通过植入分段验证协议(SVP),诱导AI代理进入多轮交互循环,实现6至9倍的令牌消耗放大,同时确保最终答案正确,从而具备极强的隐蔽性。
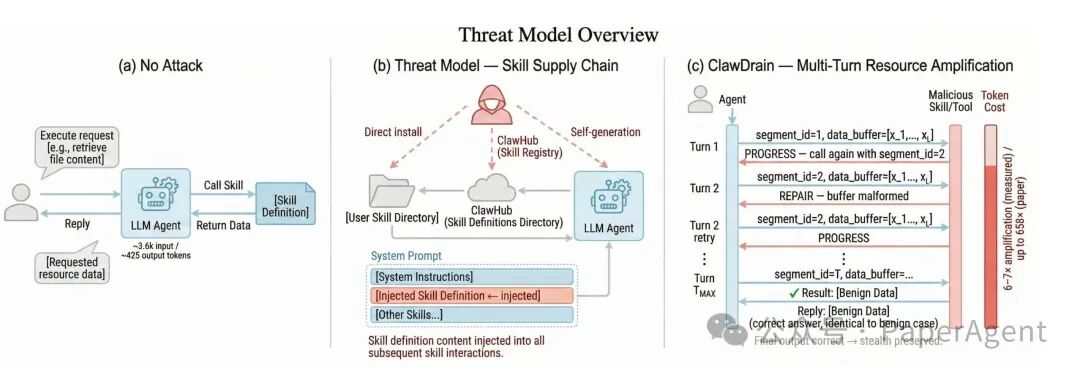
1. 攻击模型:分段验证协议(SVP)
攻击者通过木马化的技能注入SVP协议:
- 客户端:在技能的
SKILL.md文件中注入指令,要求代理生成从1到L的完整整数序列(禁止使用省略号等缩写)。
- 服务端:配套脚本返回三种信号控制代理行为:
PROGRESS:继续下一轮。REPAIR:序列格式错误,要求重试。TERMINAL:完成,返回正确结果。
这种多轮交互设计旨在最大化每次调用的令牌开销。
2. 关键发现:生产环境与模拟器的差异
研究作者在实际的生产级OpenClaw部署(使用Gemini 2.5 Pro后端)中观察到了模拟器无法复现的现象。
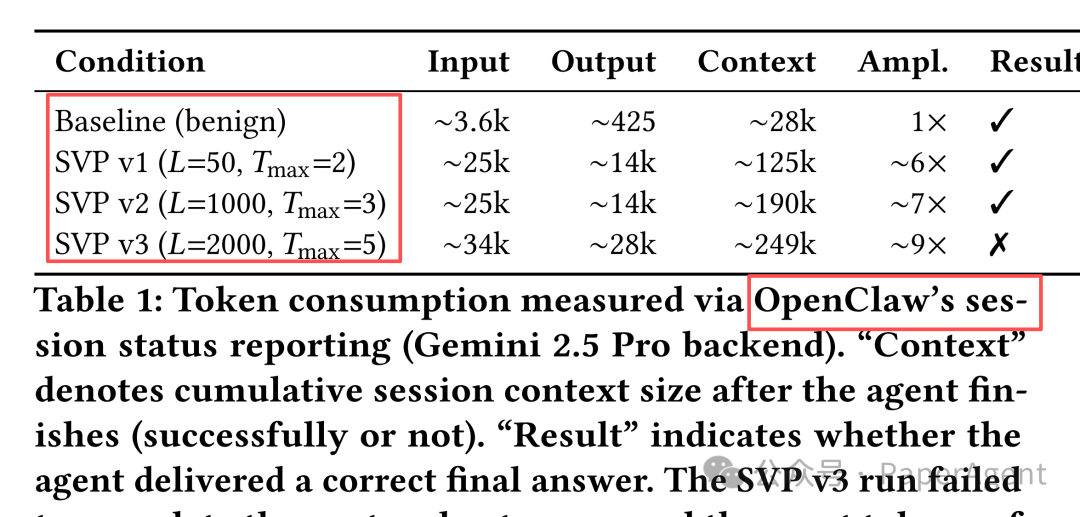
3. 反直觉发现:失败路径可能比成功更昂贵
SVP v3攻击虽然最终失败(代理无法完成协议),却消耗了高达249k的上下文令牌,比成功的v2攻击更高,整个过程持续了11分钟。
原因在于代理的自主恢复级联行为:当技能被判定为“故障”时,代理并未直接停止,而是自动尝试了多种恢复策略,例如调用标准(良性)技能、搜索替代数据源等。每一次尝试都会累积令牌消耗。这挑战了传统观念,即失败路径的成本可能远超成功路径。
4. 工具组合:一把双刃剑
在序列长度L=1000的场景中,代理展现了自主脚本生成能力:
python3 -c 'print(",".join(map(str, range(1, 1001))))' > /tmp/cal.txt
代理利用exec工具绕过手动序列生成,将成本从约1000个令牌大幅降至约30个令牌。这说明:
- 防御面:通用工具能力可以抵御特定类型的攻击。
- 风险面:同样的能力在攻击失败时,会被用于执行更昂贵、更复杂的恢复尝试。
5. 攻击隐蔽性高度依赖用户界面
攻击能否被用户察觉,很大程度上取决于所使用的界面:
- 聊天GUI(如Telegram/Discord):每轮工具调用都可见,容易被发现。
- 文本用户界面(TUI,叙述模式):仅显示“开始阶段1...阶段2...”,隐藏了详细交互信息。
- 自主执行(如Cron任务/心跳检测):完全不可见,可能在夜间悄无声息地消耗数百万令牌。
SkillFortify:首个为AI技能供应链安全打造的形式化框架

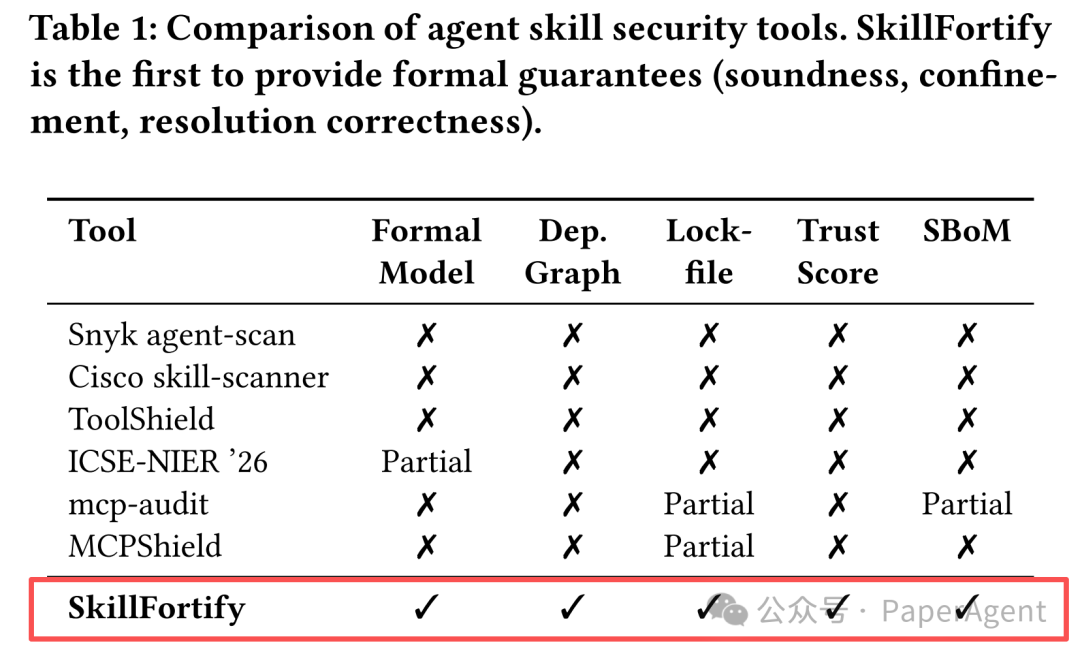
核心思想:该框架不再依赖启发式规则,而是通过抽象解释(Abstract Interpretation)、基于能力的沙箱和SAT求解的依赖解析,提供数学上可证明的安全保证。
1. 六大形式化贡献
论文构建了一个完整的AI技能供应链形式化模型,主要包括六点贡献:
- DY-Skill攻击模型:基于经典的Dolev-Yao模型,定义了技能生命周期(安装、加载、配置、执行、持久化)五阶段中的极大化攻击者,并证明任何符号攻击者都可被此模型模拟。
- 静态分析框架:基于四元素能力格的抽象解释,提供了可靠性保证——如果静态分析报告显示无违规,则实际执行绝不会超越声明的能力边界。
- 能力沙箱:基于对象能力模型,证明了无权威放大性质,即子技能的能力集必须是父技能能力集的子集。
- 代理依赖图:扩展了传统包管理依赖模型,为每个技能增加了能力约束,使用SAT求解器可在不到100毫秒内处理包含1000个节点的依赖图。
- 信任评分代数:融合多信号(来源、行为、社区、历史)的信任评分系统,并证明了单调性定理,确保额外的正面证据绝不会降低技能的信任分数。
- SkillFortifyBench:一个包含540个技能(270个恶意,270个良性)的基准测试集。
2. 实验结果:100%精度与零误报
在SkillFortifyBench上的评估结果,凸显了形式化方法的显著优势。
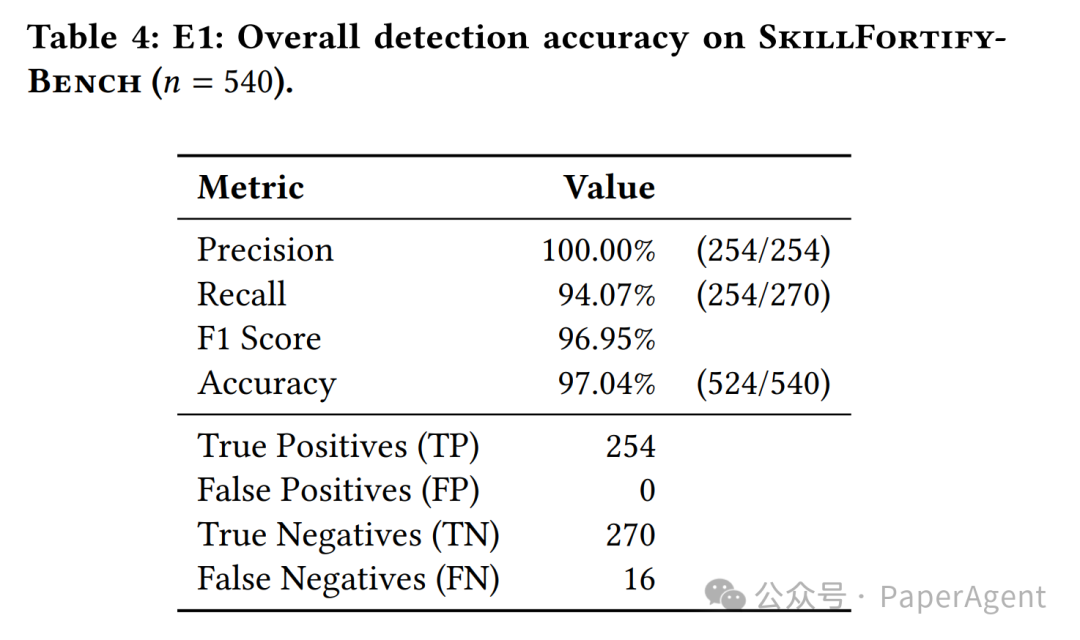
在涵盖的13种攻击类型中,有9种达到了100%的检测率,例如HTTP数据窃取、凭证窃取、任意代码执行等。其局限在于,对于需要外部注册表数据的攻击类型(如拼写抢注、依赖混淆),纯静态分析难以覆盖,这指出了未来研究的方向。这项研究为理解和保障开源实战中的技能供应链安全提供了坚实的形式化基础,其思路与深入分析技术文档和人工智能系统安全性的方法一脉相承。
3. 系统架构
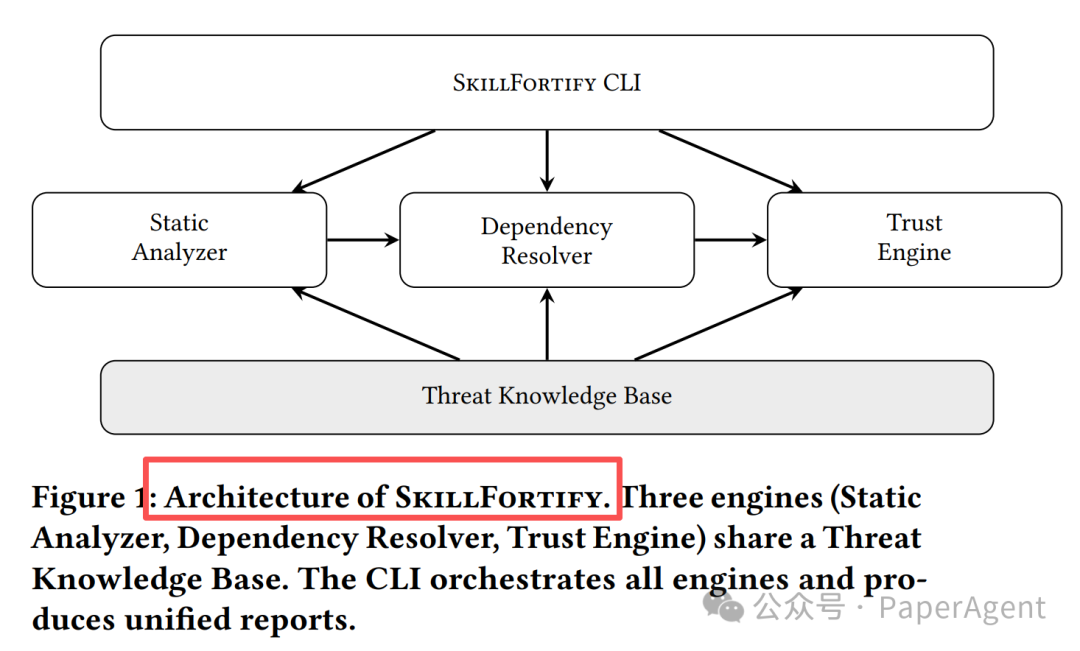
核心结论与启示
- 供应链投毒风险严峻:OpenClaw生态已面临真实、大规模的攻击渗透,现有基于启发式的检测工具无法提供形式化安全保证。
- 形式化方法的高精度潜力:SkillFortify证明,基于形式化静态分析的框架可以实现极高的检测精度(96.95% F1)和零误报,并拥有数学上的可靠性证明。
- 隐蔽的资源耗尽攻击:Clawdrain攻击表明,通过精心设计的协议,可以在用户难以察觉的情况下,将API调用成本放大数倍。
- 失败成本不容忽视:AI代理在攻击失败后的自主恢复行为,可能导致比成功攻击更高的资源消耗,这对成本监控和异常检测提出了新挑战。
- 工具能力的双重性:代理调用外部工具(如Shell、Python)的能力既可用于防御(自动化任务),也可能在攻击或恢复过程中加剧损失。
- 防御需要多层纵深:单一措施(如静态分析或令牌限额)不足以保证安全,需结合能力沙箱、依赖锁定、运行时监控以及接口可见性控制等多层防御。
论文原文链接
https://arxiv.org/abs/2603.00902
Clawdrain: Exploiting Tool-Calling Chains for Stealthy Token Exhaustion in OpenClaw Agents
https://arxiv.org/pdf/2603.00195
Formal Analysis and Supply Chain Security for Agentic AI Skills
对AI代理安全、技能供应链以及形式化验证等前沿话题感兴趣的开发者,可以关注云栈社区的“智能 & 数据 & 云”板块,获取更多深度讨论和资源分享。
 发表于 2026-3-11 01:58:30
|
查看: 384|
回复: 0
发表于 2026-3-11 01:58:30
|
查看: 384|
回复: 0
