当你使用大模型进行几十轮的长对话、跨文档的深度研究或多步骤的智能体任务时,是否经常被这些问题困扰?
- 对话轮次一多,模型就彻底“失忆”,完全忘了前面约定的关键信息。
- 想让模型记住历史交互,要么检索出来的内容全是无效噪音,根本支撑不了推理。
- 要么只能硬上超大上下文窗口的千亿级模型,推理成本直接翻倍,延迟慢到让人无法忍受。
这正是当前大语言模型在长周期任务中最核心的行业痛点:长时持久记忆的管理,始终陷入“精度不够”和“成本太高”的两难困境。

最近,来自中国人民大学高瓴人工智能学院的团队,提出了一套全新的LLM记忆管理框架 MemSifter ,彻底打破了这一困局。它创新性地将记忆检索的繁重工作完全“外包”给轻量级代理模型,以“先思考、再检索”的核心机制,在几乎不增加主模型负担的前提下,实现了检索精度与端到端任务性能的全面突破,在8个权威LLM记忆基准测试中全面超越现有SOTA方案。
目前,团队已完全开源MemSifter的模型权重、代码与训练数据,所有研究者和开发者均可直接上手使用:
- GitHub开源地址:https://github.com/plageon/MemSifter
- 论文原文地址:https://huggingface.co/papers/2603.03379
一、大模型记忆困局:LLM 长时记忆的两难选择
在长周期任务中,LLM 的交互历史很快会超出上下文窗口限制,必须将信息迁移到持久化存储中,也就是我们常说的“LLM 长时记忆”。而当前主流的记忆方案,始终无法跳出两大核心瓶颈:
-
极简存储方案:精度拉胯
最基础的线性内存库方案,仅按顺序存储原始记忆片段,推理时靠向量相似度召回 Top-K 内容。这种方案几乎没有额外开销,但召回准确率极低,大量关键信息被噪音淹没,记忆利用率极差。
-
复杂增强方案:成本爆炸
为了提升召回效果,业界衍生出两大优化方向:
- 索引阶段做结构增强:通过构建知识图谱、层级索引等方式优化检索,但会带来极高的预计算开销,且抽象过程会丢失大量关键细节。
- 推理阶段做上下文扩展:直接让主大模型自己读取、处理长记忆内容,虽然精度更高,但会给主模型带来双倍计算负担,推理速度骤降、成本飙升。
简单来说,现有方案要么“不好用”,要么“用不起”。而 MemSifter 的出现,正是为了回答一个核心问题:我们能不能在不加重主大模型负担的前提下,实现推理级别的高精度记忆检索?
二、MemSifter 核心方案:把记忆检索“外包”给轻量代理
MemSifter 的核心设计思路,是彻底解耦“记忆检索”与“主模型推理”:用一个专门训练的轻量级代理模型,承担所有记忆筛选的繁重工作,主大模型只需要接收经过极致精炼的关键信息,专注于最终的任务推理。
核心机制:先思考,再检索
MemSifter 给代理模型设计了一套 “Think-and-Rank” 的推理流程,像一个智能“守门人”,在把记忆交给主模型前,先完成全流程的推理分析:
- 先对当前任务需求做深度拆解,明确完成任务需要哪些关键信息。
- 再扫描全量历史交互会话,逐一分析每个会话与当前任务的相关性。
- 最终输出相关性从高到低的会话排序,只把 Top-K 的关键会话内容交给主大模型。
整个过程中,索引阶段无需任何 heavy 计算,推理阶段也仅给主模型增加极小的上下文开销,完全规避了传统方案的核心缺陷。MemSifter 的完整推理流水线与训练框架,可参考下图。
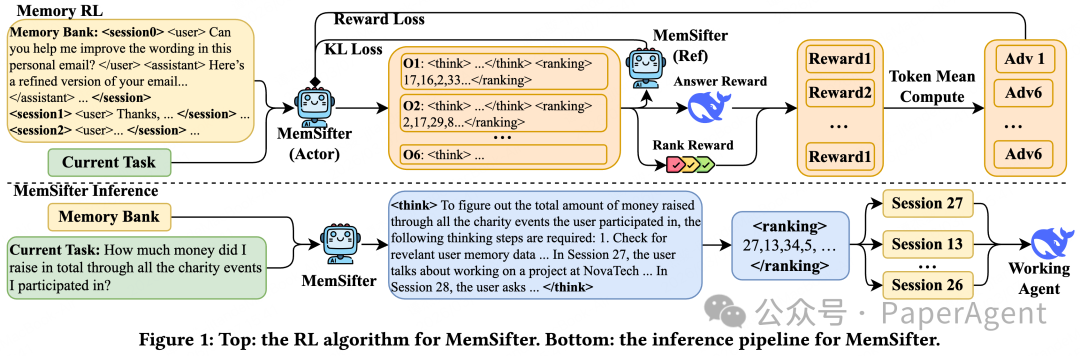
为了让代理模型精准完成这项工作,团队设计了专门的任务 Prompt ,清晰定义了相关性判断标准与输出格式,确保代理模型的输出稳定可控,具体 Prompt 设计见下图。

针对超长篇的历史交互(超过代理模型 128k 上下文窗口),MemSifter 还设计了轻量嵌入模型的粗筛环节,先过滤掉完全无关的会话,实验验证该环节仅带来不到 1% 的召回损失,却能大幅降低代理模型的推理压力。
三、新训练范式:任务结果导向的 RL 训练范式
如果说“代理模型架构”是 MemSifter 的骨架,那 任务结果导向的强化学习训练范式 ,就是它能超越所有基线的核心灵魂。
传统的检索优化方案,大多基于静态相关性标签,优化召回率、精确率、NDCG 这类“代理指标”。但 MemSifter 团队提出了两个核心洞察:
- 目标对齐原则:记忆模块的好坏,唯一评判标准是它对下游任务的边际贡献,而非孤立的检索指标。
- 标签稀缺现实:复杂推理任务中,几乎不可能拿到细粒度的黄金排序标签,监督学习的优化空间极其有限。
基于这两个洞察,MemSifter 完全抛弃了传统的监督训练范式,直接以主大模型的最终任务成功率为优化目标,设计了一套全新的 RL 训练机制,同时解决了两大核心难题:信用分配模糊与排序敏感性缺失。
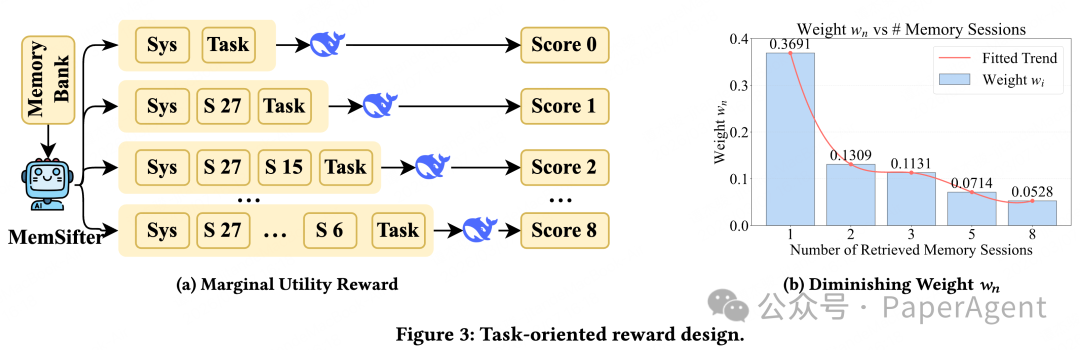
1. 边际效用奖励:只给“真帮忙”的记忆发奖励
传统的全局任务奖励,无法区分“正确答案来自检索到的记忆”还是“主模型本身就知道答案”,很容易让代理模型学到错误的优化方向。
为此,团队设计了 边际效用奖励 :
- 先设定无记忆基线:主模型不使用任何检索记忆时,完成任务的基础得分 $s_0$。
- 再做渐进式评估:按 Top-1、Top-2、Top-3、Top-5…的斐波那契采样序列,逐步给主模型增加检索到的记忆,测试不同截断位的任务得分 $s_{k_n}$。
- 最终通过相邻截断位的得分差 $(s_{k_n} - s_{k_{n-1}})$,精准量化每一段新增记忆的真实边际贡献。
只有真正帮主模型填补了知识缺口、提升了任务表现的记忆,才能拿到对应的奖励,彻底解决了信用分配模糊的问题。该奖励的设计逻辑见下图。
2. 排序敏感奖励:关键信息必须排在最前面
LLM 的注意力窗口与上下文敏感度,决定了“排在第1位的关键信息,价值远高于排在第10位的相同信息”。而稀疏的标量奖励,完全无法捕捉这种排序敏感性。
团队参考 DCG 评价指标的对数衰减特性,设计了 排序敏感奖励 ,给不同排序位置的边际收益,赋予递减的权重系数:排名越靠前的有效记忆,拿到的奖励权重越高。最终的总奖励公式如下:
$R_{\text{ans}} = \sum_{n=1}^{N} w_n \cdot (s_{k_n} - s_{k_{n-1}}). \quad (1)$
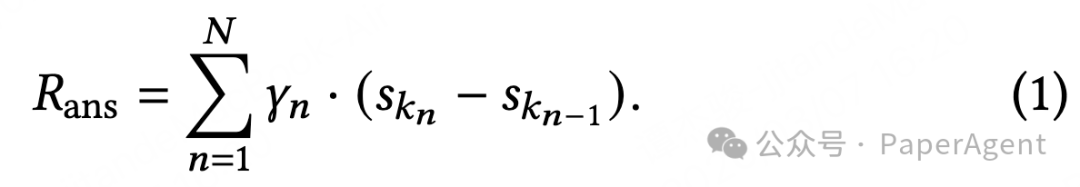
经过公式重构与简化,最终可转化为更高效的计算形式:
$R_{\text{ans}} \approx \sum_{n=1}^{N} D_n \cdot (s_{k_n} - s_{k_{n-1}}). \quad (4)$
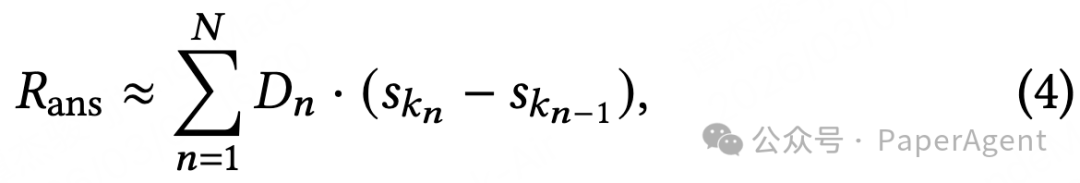
其中权重系数 $w_n$ 的定义如下,严格遵循 DCG 的对数衰减规律,权重变化趋势见上图右侧。
$w_n = \begin{cases} 1 / \log_2(k_n + 1) - 1 / \log_2(k_{n+1} + 1), & \text{if } 1 \le n < N; \\ 1 / \log_2(k_n + 1), & \text{if } n = N. \end{cases} \quad (5)$
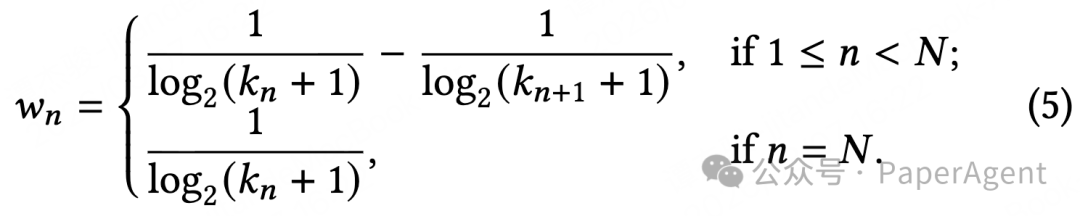
3. 训练优化:解决冷启动与不稳定性
为了缓解 RL 训练固有的不稳定性,团队还设计了三重优化策略:
- 暖启动监督训练:早期用少量标注数据做监督训练,让模型先学会基础的输出格式与语义相关性判断,解决冷启动问题。
- 动态课程学习:每轮训练都优先选择模型“跳一跳够得着”的难度样本,避免过拟合简单样本或在超难样本上崩溃。
- 模型平均融合:每轮训练结束后,取验证集表现最好的 Top-K checkpoint 做参数平均,用融合模型初始化下一轮训练,平滑优化波动,避免性能崩塌。
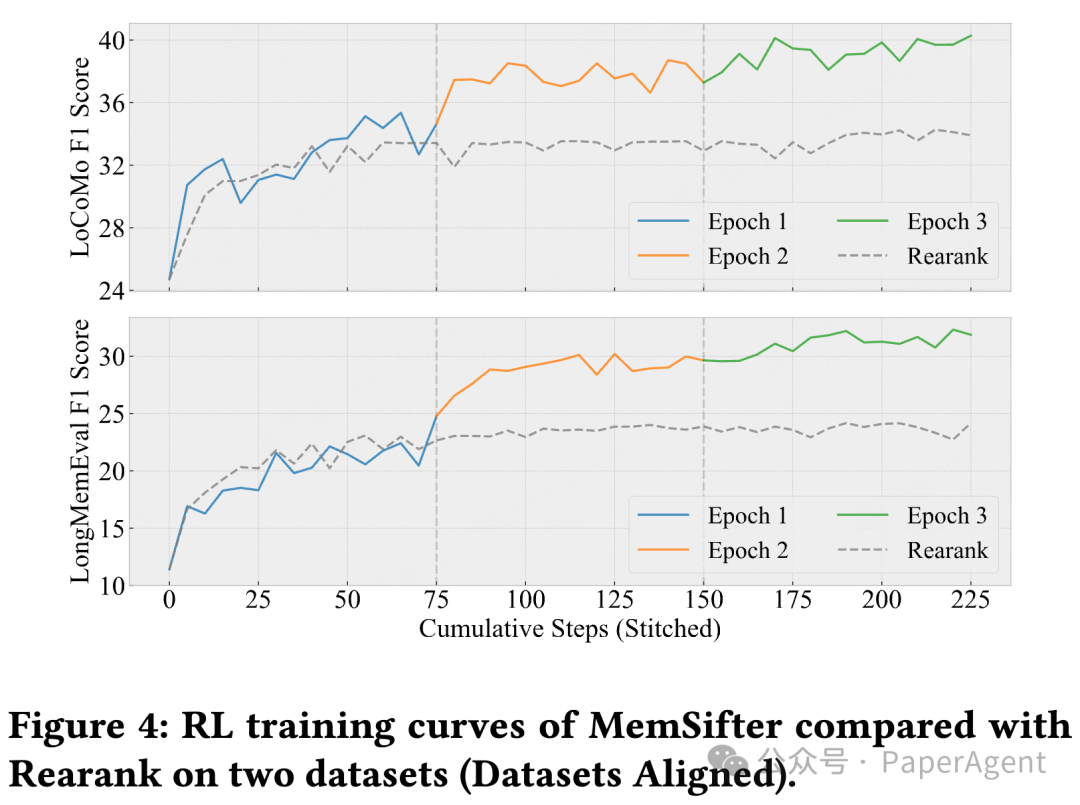
MemSifter 的完整训练曲线,对比基线模型展现出了更快的收敛速度与更高的最终性能,见下图。
四、实验结果:8 项基准全面登顶,效率与精度双丰收
团队在 8 个权威 LLM 记忆基准上完成了全面测试,覆盖个人对话记忆、用户画像建模、多跳推理、深度研究等全场景,对比了嵌入检索、记忆管理框架、图检索、生成式重排、原生长上下文 LLM 五大类主流方案,结果全面碾压现有 SOTA。
1. 端到端任务性能:全面超越所有基线
在核心的端到端任务 F1 得分上,MemSifter 在所有 8 个基准测试中,均取得了最优或次优的成绩,无论是搭配 DeepSeek V3.2 还是 Qwen3-30B 主模型,都大幅领先同配置的所有基线方案,完整结果见下表。
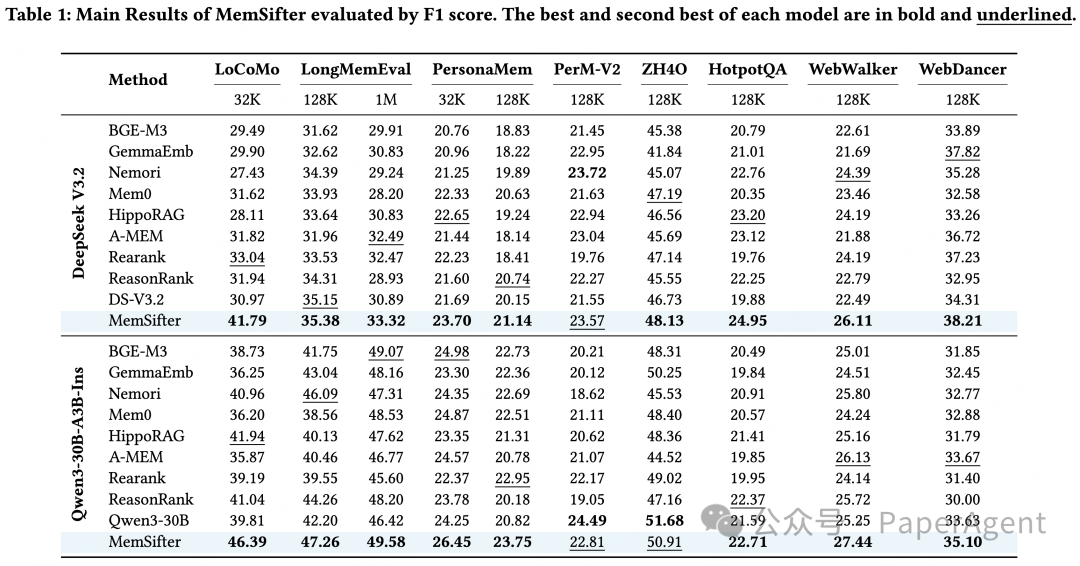
比如在 LoCoMo 长对话记忆基准上,MemSifter 搭配 DeepSeek V3.2 取得了 41.79 的 F1 得分,远超第二名的 35.15;搭配 Qwen3-30B 更是达到 46.39,领先第二名的 41.94,提升幅度极其显著。
2. 检索精度:大幅领先传统检索方案
在有黄金标注的基准上,团队进一步测试了检索本身的精度,MemSifter 的 NDCG@1、NDCG@5 指标,全面超越嵌入检索、生成式重排等所有基线,完整结果见下表。
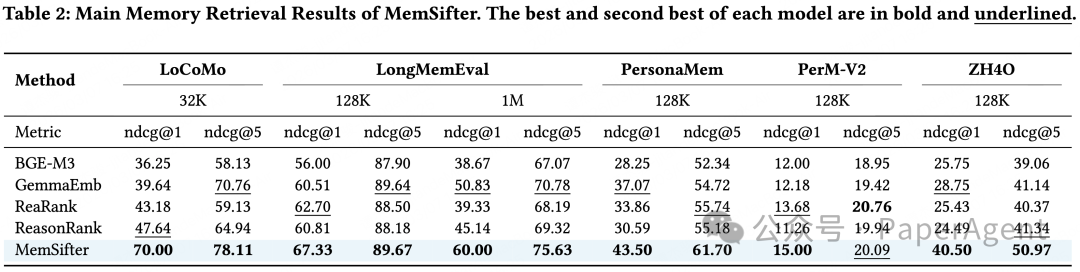
以 LoCoMo 32K 基准为例,MemSifter 的 NDCG@1 达到 70.00,而第二名的 ReasonRank 仅为 47.64,提升幅度超过 47%,充分证明了代理模型的精准筛选能力。
3. 消融实验:验证每个核心模块的价值
团队通过消融实验,逐一验证了核心设计的有效性,完整结果见下表。
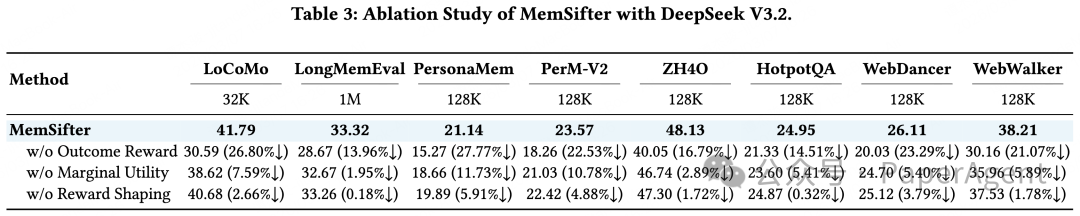
实验结果清晰显示:
- 移除任务结果导向的 RL 优化后,模型性能最大跌幅达到 26.80%,证明了该范式的核心价值。
- 移除边际效用奖励、排序敏感权重后,模型均出现明显的性能下降,验证了两个奖励设计的必要性。
4. 效率分析:用极低开销,换极致性能
在 WebDancer 128K 基准上的效率测试显示:
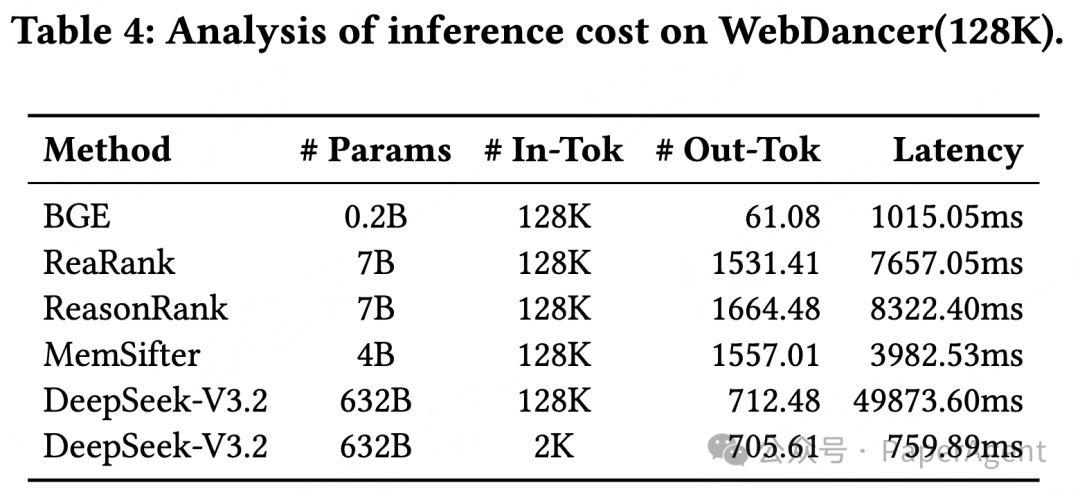
- MemSifter 仅用 4B 参数量的代理模型,单条推理延迟仅 3982.53ms,不到 7B 重排模型的一半。
- 对比 632B 参数量的 DeepSeek-V3.2 直接处理 128K 上下文,MemSifter 的延迟仅为其 1/12,算力成本更是呈数量级下降。
真正实现了“用轻量模型的成本,达成超越千亿长上下文模型的效果”。
五、直观案例:看看 MemSifter 是怎么“思考”的
为了更直观地展示 MemSifter 的能力,团队在三个不同场景下做了案例分析,完整呈现了代理模型的思考过程与排序结果:
-
长对话记忆场景(LoCoMo 基准):针对“John 和妻子什么时候去的欧洲度假”的问题,代理模型精准定位到相关会话,完成了从高到低的排序,完整思考过程见下图。

-
用户个性化记忆场景(LongMemEval 基准):针对“我夏威夷生日旅行计划住在哪里”的问题,代理模型精准匹配到生日旅行、夏威夷相关的核心会话,优先排序,完整思考过程见下图。

-
深度研究场景(WebDancer 基准):针对复杂的知识问答,代理模型精准定位到包含答案的核心会话,哪怕存在大量语义相似的干扰内容,也能完成精准筛选,完整思考过程见下图。

总结
MemSifter 通过一个巧妙的“外包”策略,将记忆筛选的计算负担从昂贵的主模型转移到了轻量的代理模型上,并通过任务结果导向的强化学习范式解决了传统方法中信用分配模糊和排序敏感性缺失的难题。这项来自中国人民大学的开源工作,为大语言模型的长时记忆管理提供了一条高效且可扩展的新路径。如果你想了解更多关于智能体、长上下文模型优化等前沿技术的实践与讨论,欢迎关注 云栈社区 的 人工智能 和 开源实战 板块,那里有更多开发者正在进行深入的交流与探索。
 发表于 2026-3-11 01:56:01
|
查看: 232|
回复: 0
发表于 2026-3-11 01:56:01
|
查看: 232|
回复: 0
