VideoCaptioner 是一款基于大语言模型(LLM)的视频字幕处理助手。它支持 API 和本地离线两种语音识别方式,并能利用 LLM 对字幕进行智能断句、校正和翻译,实现从视频到字幕的全流程一键处理。
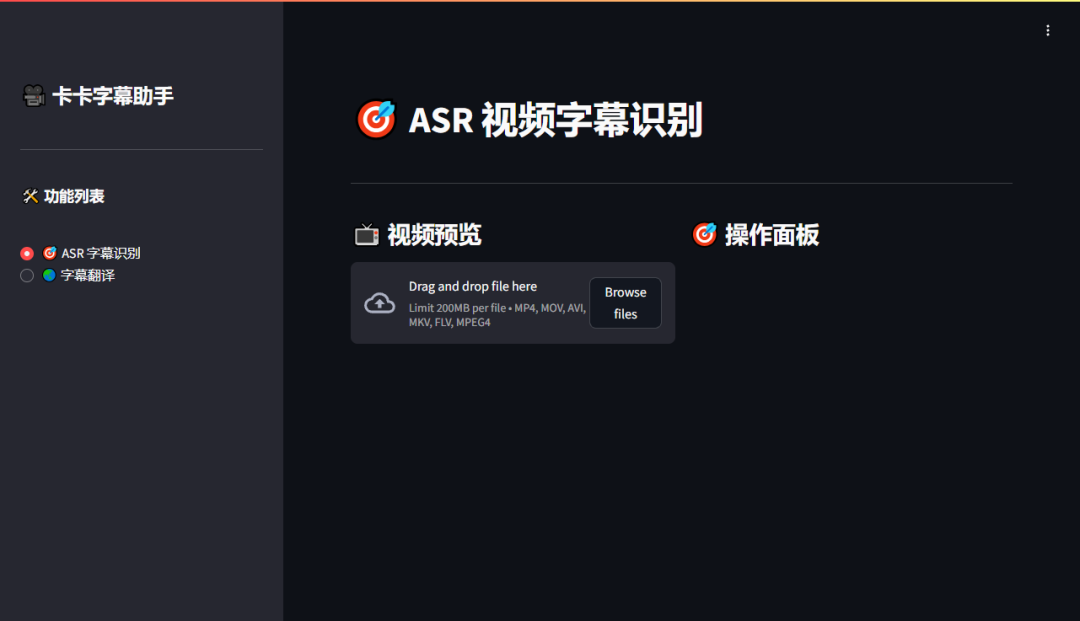
需要留意的是,其电脑版功能更为全面,而 Docker 版本的功能相对较少。
安装
Docker Compose
使用 Docker Compose 部署是最简单的方式,配置文件示例如下:
services:
video-captioner:
image: ywsj/video-captioner:latest
container_name: video-captioner
ports:
- 8501:8501
volumes:
- ./temp:/app/temp
restart: always
参数说明(更多参数建议查阅项目文档)
OPENAI_BASE_URL(环境变量,可选):OpenAI 的基础 URL。OPENAI_API_KEY(环境变量,可选):OpenAI API 的密钥。
使用
容器启动后,在浏览器中输入 http://你的NAS_IP:8501 即可访问其 Web 界面。
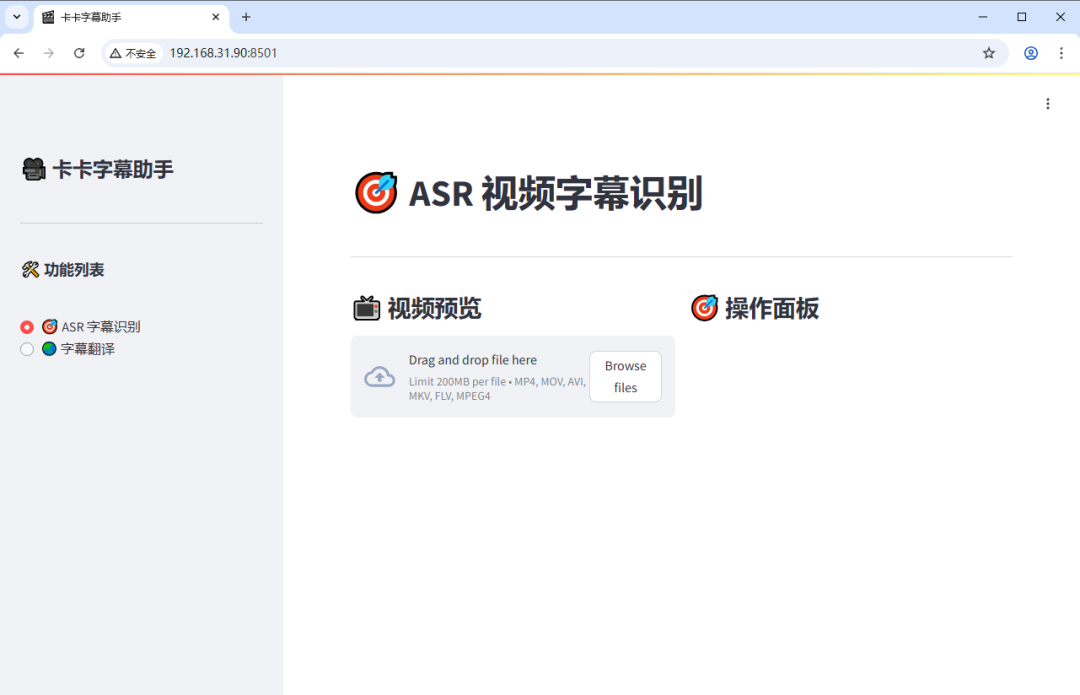
为了方便截图展示,下图已切换为深色主题模式。
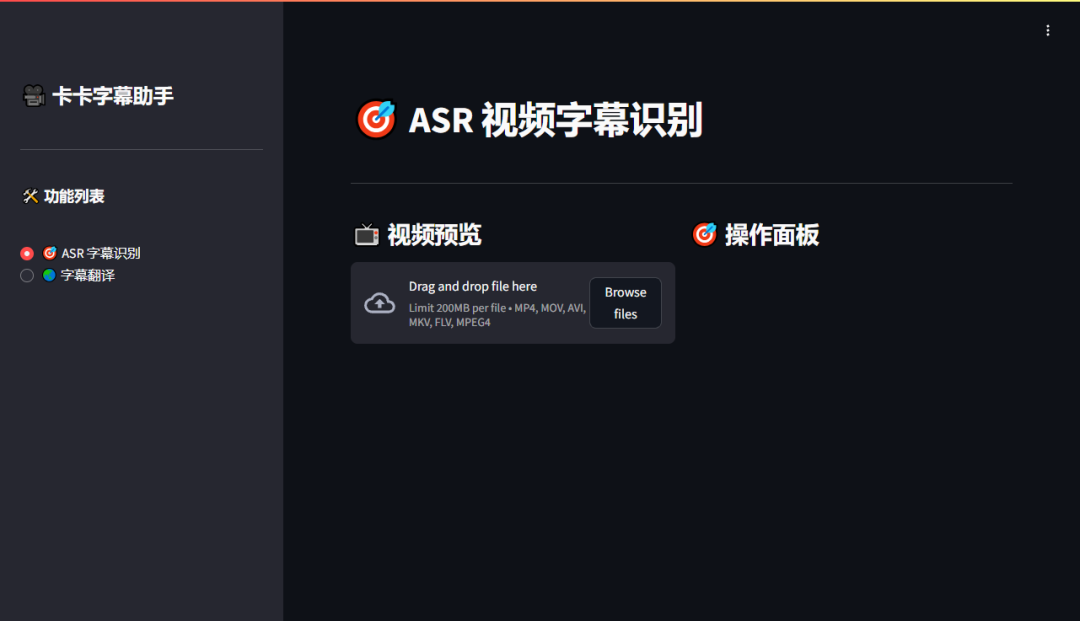
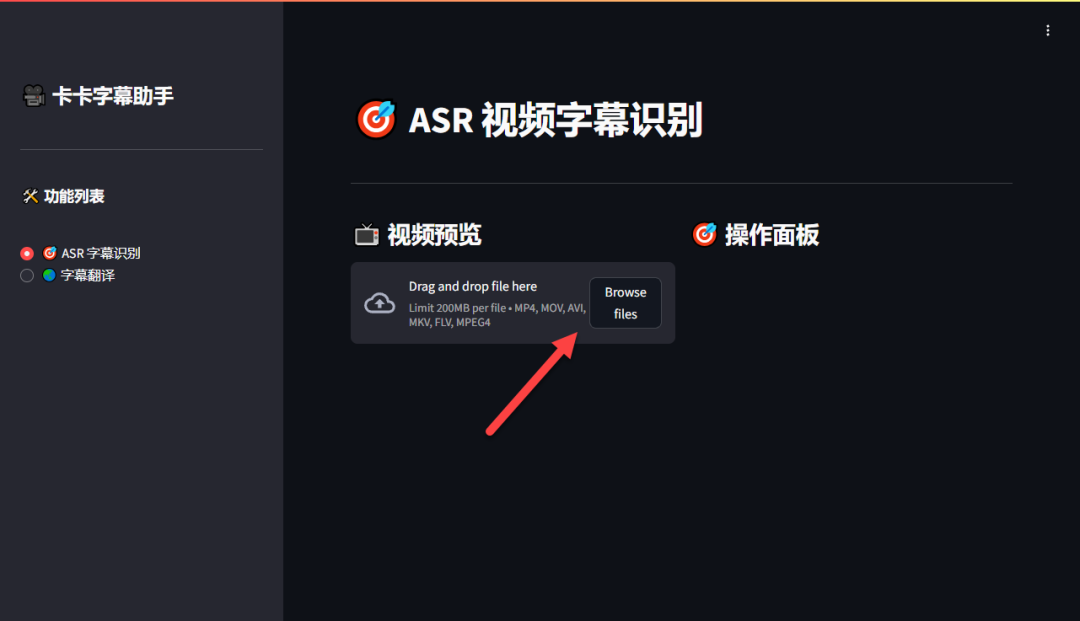
第一步:上传视频
点击“Browse files”或拖拽文件到指定区域,注意单个文件大小不能超过 200MB。
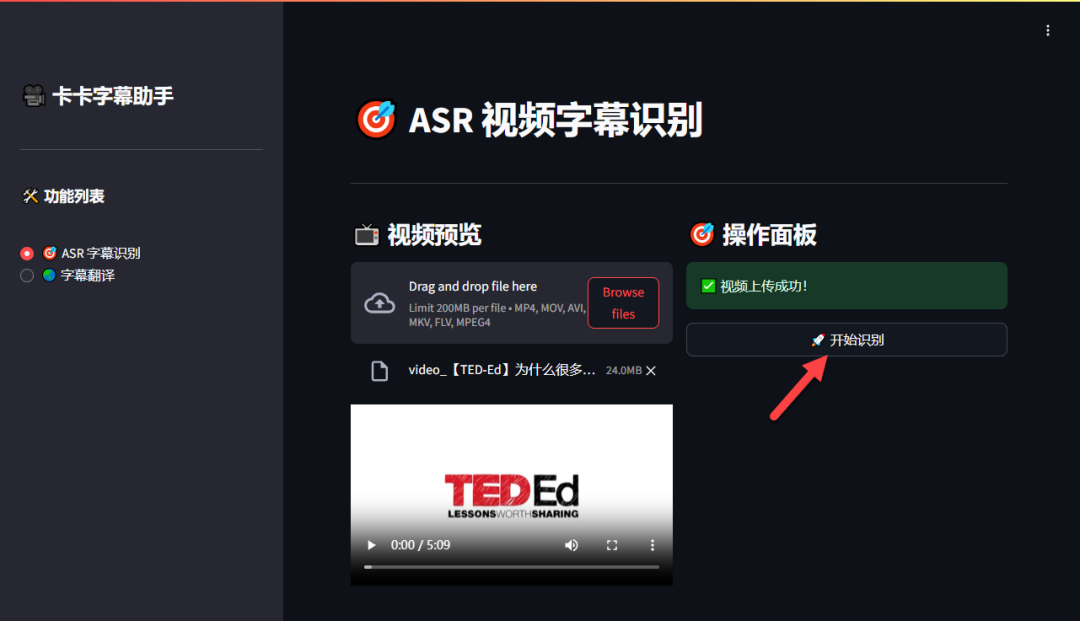
第二步:开始字幕识别
视频上传成功后,右侧操作面板会提示“视频上传成功!”,点击“开始识别”按钮即可。
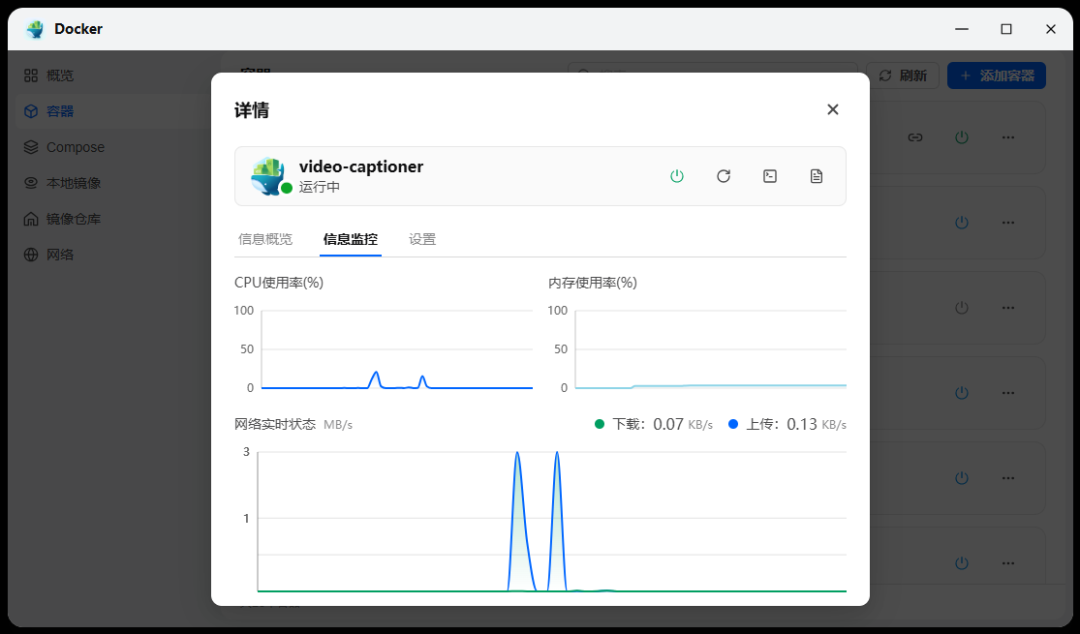
识别过程在本地进行,资源消耗极低,几乎可以忽略不计。
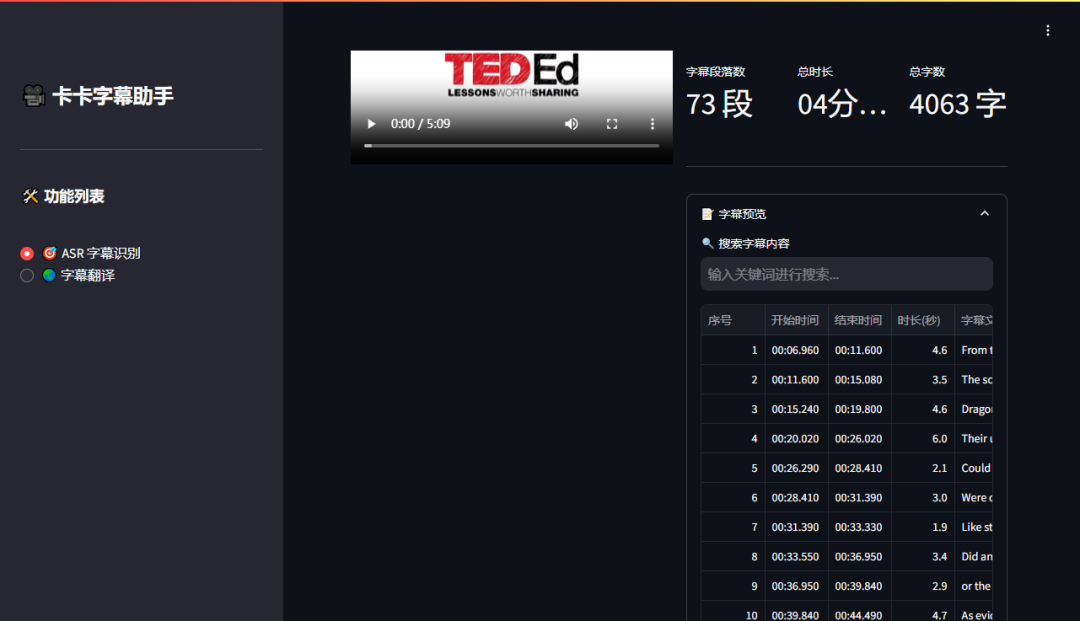
对于较短的视频,字幕识别通常在几秒钟内即可完成。
第三步:下载字幕文件
滚动页面到底部,点击“导出字幕”即可下载生成的 SRT 格式字幕文件。
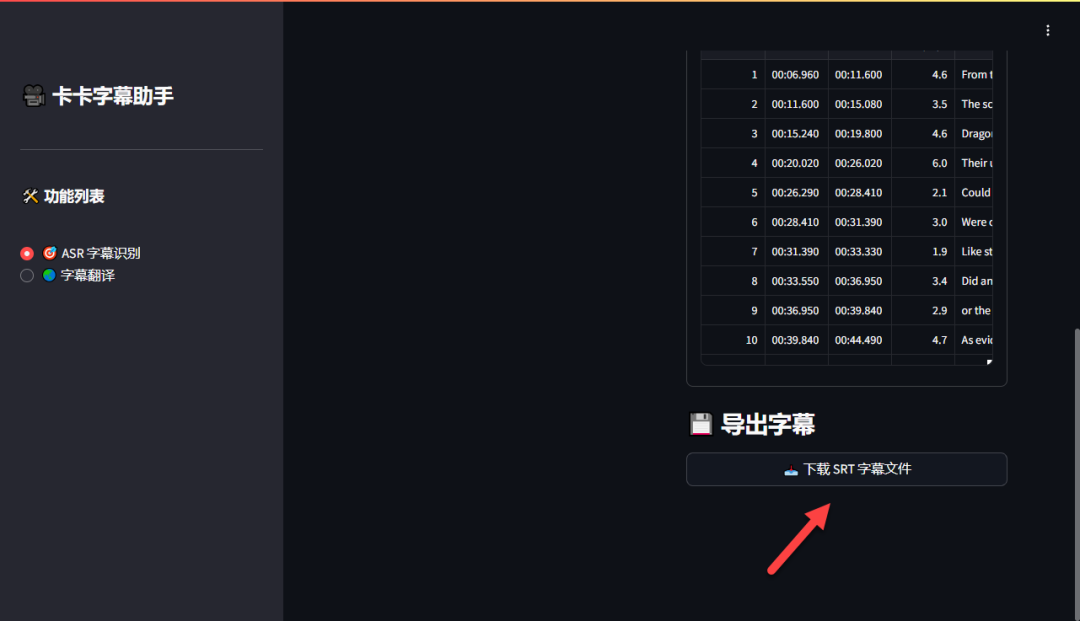
识别出的字幕效果准确,时间轴匹配良好。

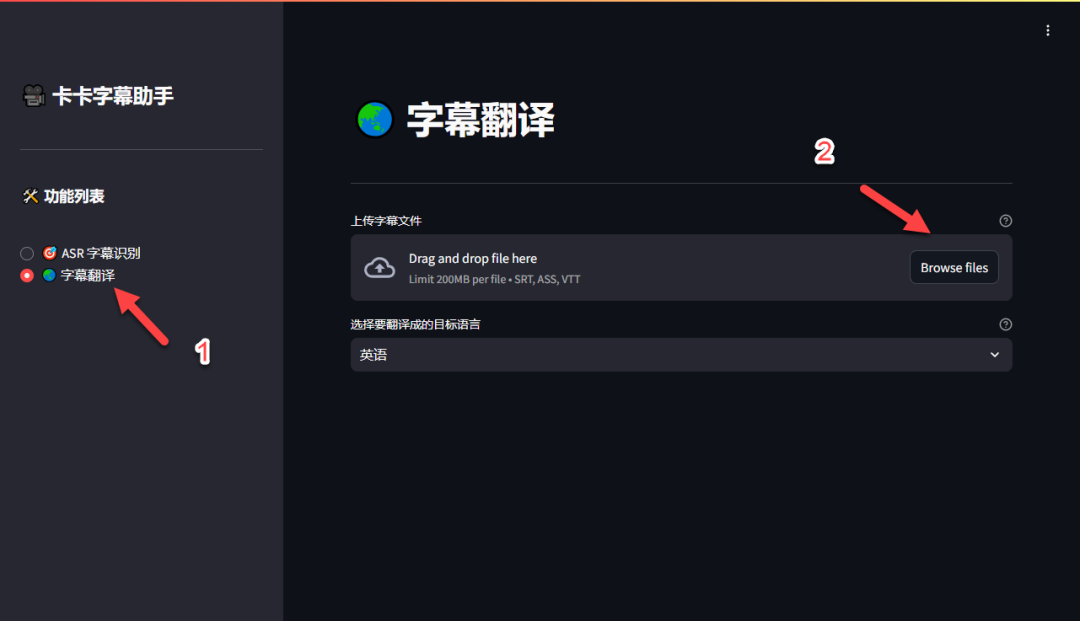
第四步:字幕翻译
切换到“字幕翻译”功能标签页,上传刚才下载的 SRT 字幕文件。
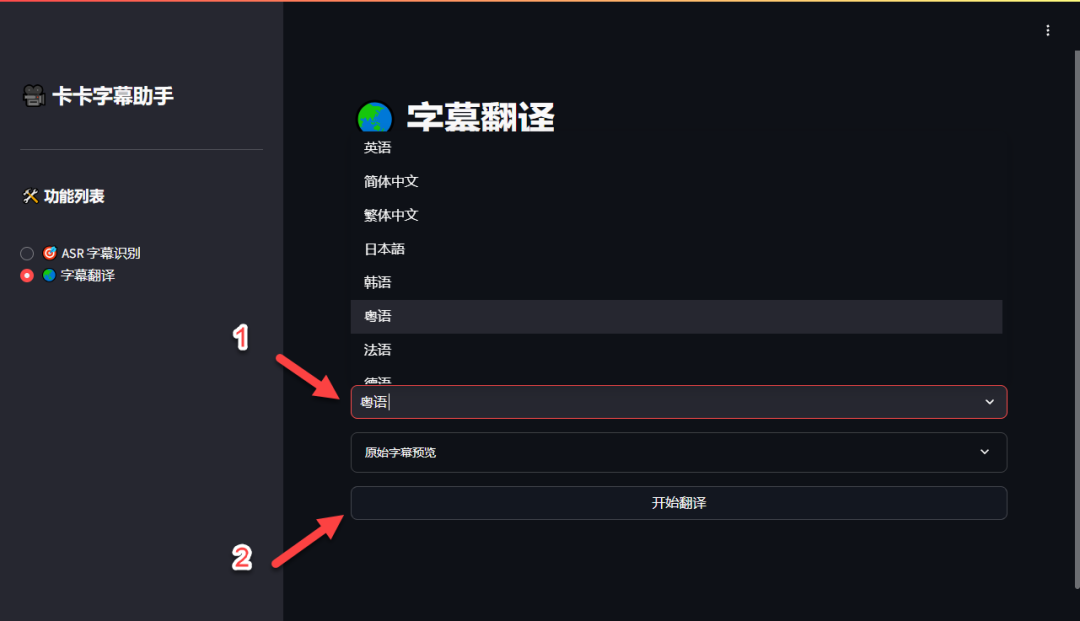
选择需要翻译的目标语言(这里以粤语为例),然后点击“开始翻译”。
翻译过程几乎是实时的,且翻译结果地道自然。
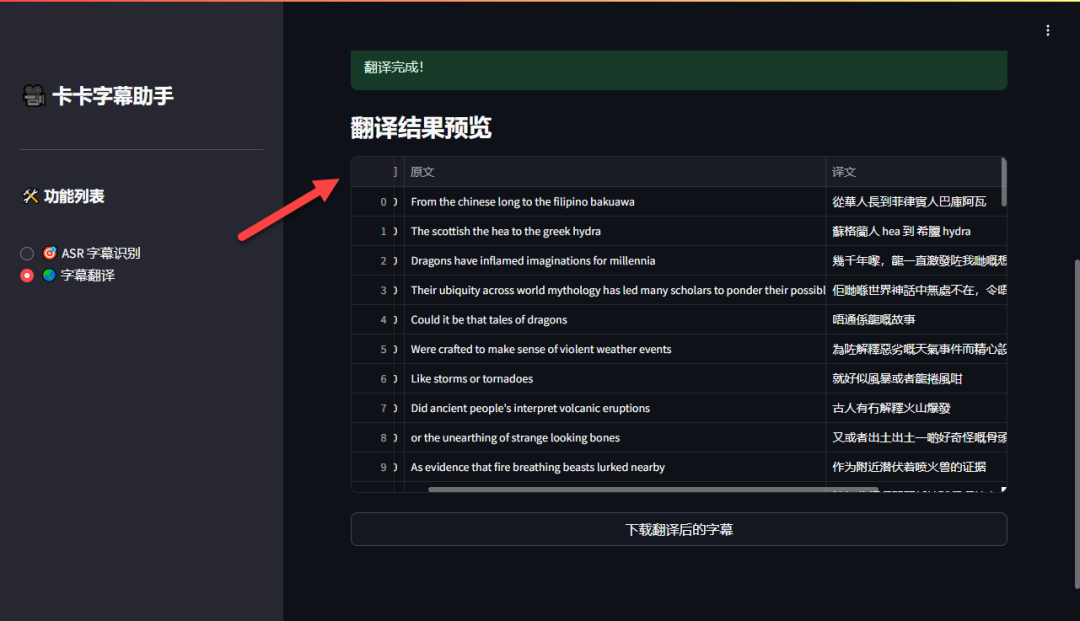
确认翻译无误后,点击“下载翻译后的字幕”即可获得双语字幕文件。
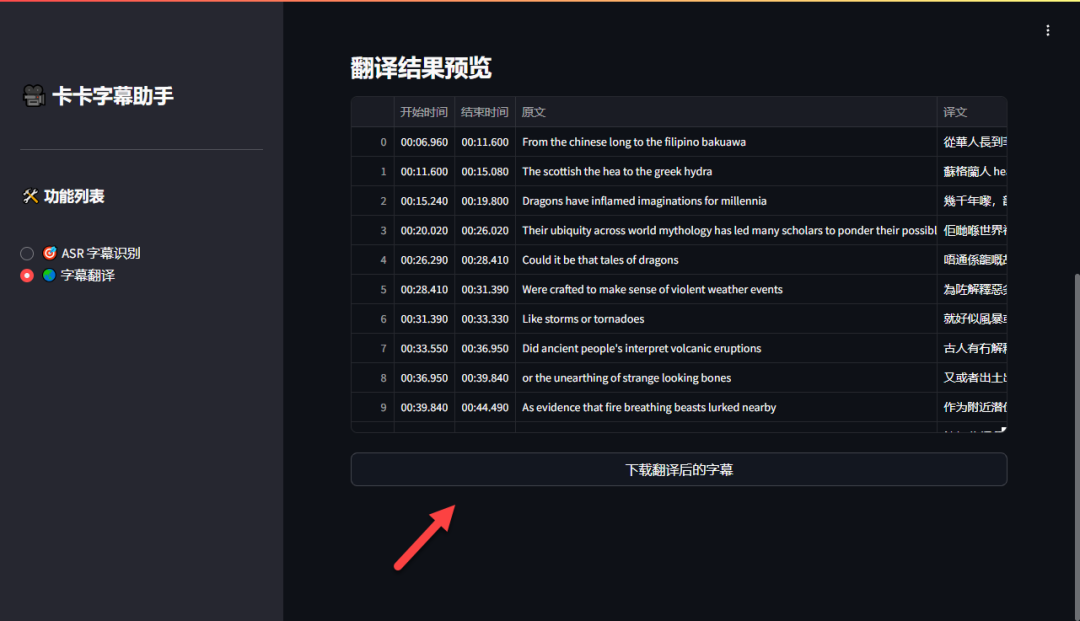
最终,你将得到一个包含原文和译文的双字幕视频。

总结
VideoCaptioner 本身是一个理念不错的项目,但其完整功能主要体现在电脑版上。Docker 版本目前的功能相对单一,且维护似乎不够活跃。不过,对于仅有少量小体积视频需要快速添加或翻译字幕的用户而言,在 NAS 上部署其 Docker 版本仍是一个可行的选择。它完全本地运行,资源占用低,处理速度也很快。
如果你对这类能提升本地媒体处理效率的工具感兴趣,欢迎到云栈社区探索更多相关的开源项目和实战教程。
- 综合推荐:⭐⭐⭐(适合快速处理小体积视频字幕)
- 使用体验:⭐⭐⭐(功能较基础,期待后续完善)
- 部署难易:⭐⭐(非常简单)
|  发表于 2026-1-25 02:10:50
|
查看: 328|
回复: 0
发表于 2026-1-25 02:10:50
|
查看: 328|
回复: 0
