作为后端开发者,我们几乎每天都在与「缓存」打交道。你是否想过,为何Linux读取文件的速度远高于直接磁盘访问?又为何MySQL面对百万级数据查询能够秒级返回?这一切卓越性能的背后,核心驱动力都源于缓存技术。
然而,缓存并非简单的“一用就灵”。若使用不当,它甚至可能从性能加速器转变为系统瓶颈。其中,预读失效会导致缓存命中率暴跌,而批量查询则可能引发严重的缓存污染。如果不理解这些问题的底层逻辑,优化工作将无从下手。
本文将从操作系统与数据库的视角,深入剖析缓存的实现机制。我们将首先了解Linux与MySQL的缓存核心,然后探讨传统LRU算法的局限性,最后揭秘两大系统如何通过精妙的改进,成功解决预读失效与缓存污染这两大难题。
Linux与MySQL的缓存核心是什么?
缓存的本质是 「用空间换时间」 。内存的访问速度在纳秒级别,而磁盘I/O则在毫秒级别,两者存在数量级的差距。因此,将高频访问的数据暂存于内存中,避免重复的慢速磁盘I/O,是提升系统性能的关键。
1. Linux操作系统的缓存:Page Cache
当应用程序读取磁盘文件时,Linux内核并不会只读取请求的那部分数据。基于效率考量,它会将更多的数据块缓存到 「Page Cache(页缓存)」 中。Page Cache是内存中预留的一块区域,其缓存的基本单位是「页(Page)」,通常大小为4KB。
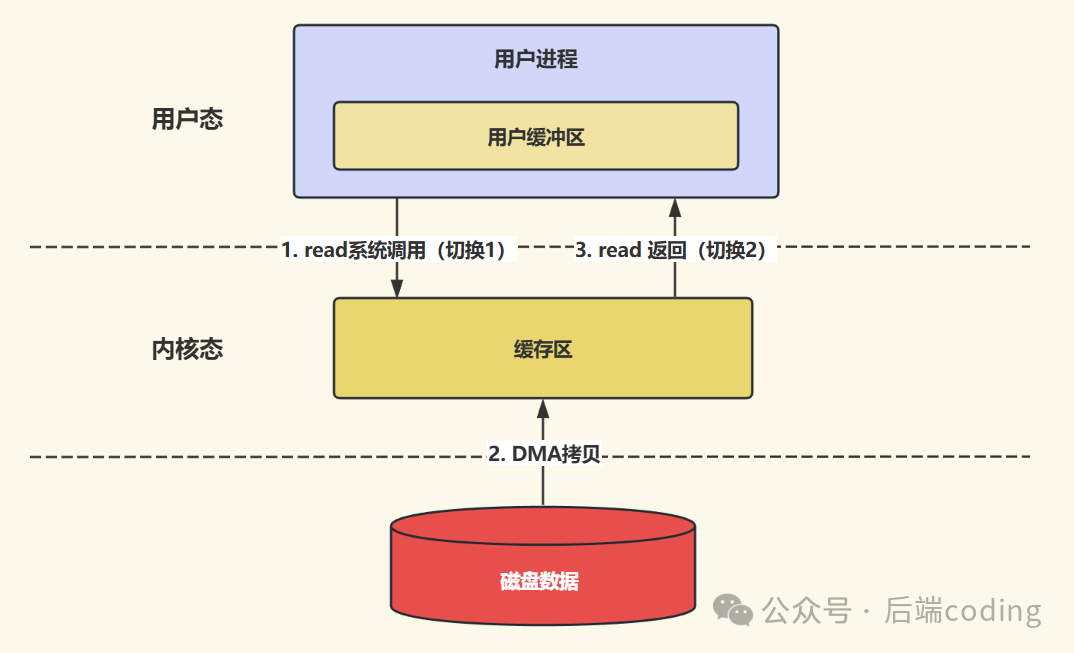
下次应用再次访问相同数据时,会首先在Page Cache中查找。若命中(数据存在),则直接从高速内存中返回;若未命中,才转而向磁盘发起读取操作,并将新读取的数据同步载入Page Cache以备后用。
简而言之,Page Cache充当了磁盘数据的“高速中转站”,显著减少了直接磁盘I/O的次数,是Linux提升文件系统性能的基石。想要深入了解其背后的零拷贝等高级机制,可以参考云栈社区上关于系统调优的专题讨论。
2. MySQL的缓存:Buffer Pool
MySQL的数据最终持久化在磁盘上,但磁盘I/O的延迟会严重制约查询和更新性能。为此,InnoDB存储引擎设计了 「Buffer Pool(缓冲池)」 。它同样是内存中的一块区域,缓存的基本单位也是数据「页」。
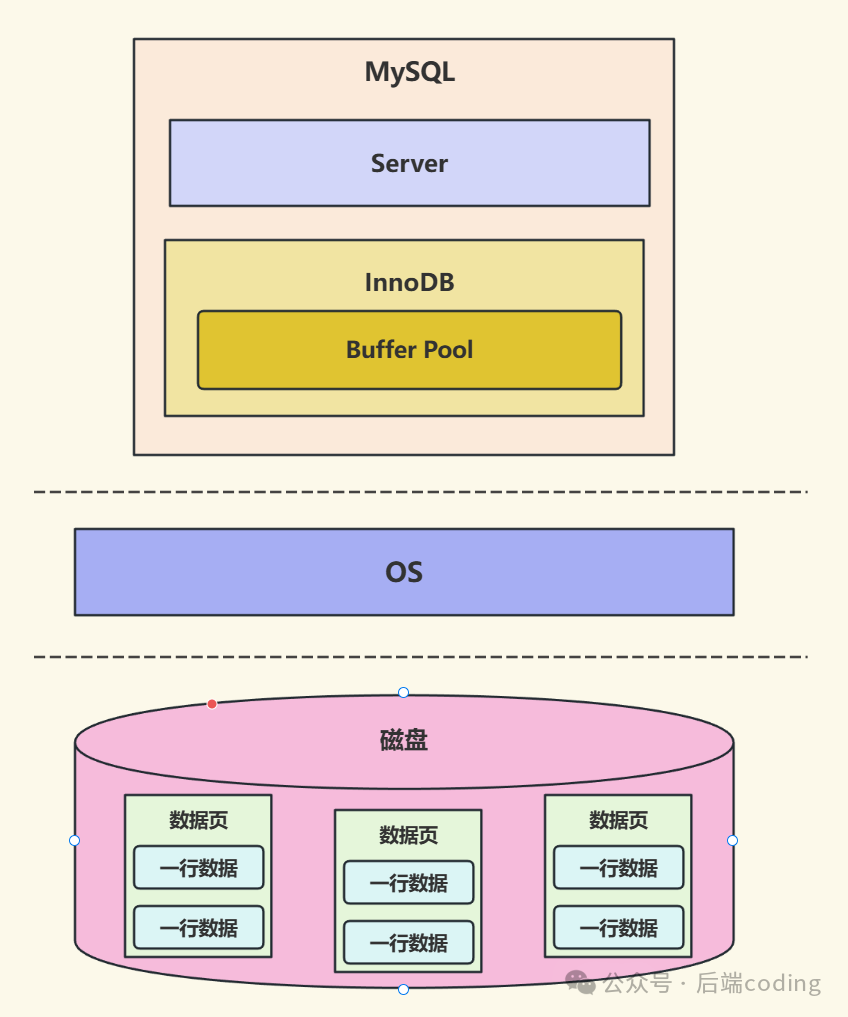
Buffer Pool的工作原理与Page Cache类似,但针对数据库事务场景进行了深度优化:
- 读取数据:首先查询Buffer Pool,命中则直接返回;未命中则从磁盘读取对应数据页,并将其加载到Buffer Pool中。
- 修改数据:直接在Buffer Pool中修改数据页,该页会被标记为「脏页」(内存与磁盘数据不一致),随后由后台线程异步刷回磁盘。这种设计避免了每次写操作都阻塞在磁盘I/O上,极大地提升了并发处理能力。关于MySQL的更多性能调优细节,可以深入探索。
传统LRU如何管理缓存数据?
无论是Linux的Page Cache还是MySQL的Buffer Pool,都需要一套高效的机制来管理有限的内存空间:决定哪些数据页应该被保留,哪些可以被淘汰。其核心依赖的算法便是 「LRU(最近最少使用)」。
LRU算法的逻辑直观而简单:它使用一个链表来存储所有缓存页。最近被访问过的页会被移动到链表头部,而最久未被访问的页则自然沉到链表尾部。当需要淘汰旧数据以腾出空间时,只需移除链表尾部的页即可。
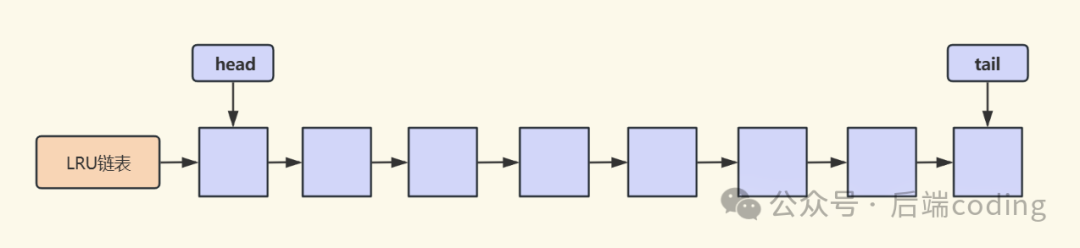
传统LRU的实现遵循两步走策略:
- 缓存命中:当访问的页已存在于链表中时,将其移动到链表头部,标记为“最近使用”。
- 缓存未命中:当访问的页不在链表中时,从磁盘加载该页,并将其插入链表头部。如果链表已满,则淘汰链表尾部的页。
这套逻辑看似完美,但在真实的操作系统与数据库负载下,却会暴露两个致命缺陷:预读失效 与 缓存污染。
痛点一:预读失效
要理解预读失效,首先必须了解 「预读机制」 。这是系统和数据库为了进一步压榨性能而设计的“智能预加载”逻辑。
1. 什么是预读机制?
预读机制的理论基础是 「空间局部性原理」:当前被访问的数据,其相邻的数据在将来有很大概率也会被访问。
基于这一原理:
- Linux:在读取文件时,会提前将比当前请求范围更大的磁盘块加载到Page Cache中。
- MySQL:从磁盘加载某个数据页时,会将其相邻的几个数据页也一并加载到Buffer Pool中。
预读机制旨在通过减少未来的磁盘I/O次数来提升整体吞吐量。但如果预判失误,就会导致 「预读失效」。
2. 什么是预读失效?
如果提前加载到内存中的 「预读页」 在后续从未被实际访问过,那么这次预加载就变成了“无效劳动”,这就是预读失效。
结合传统LRU算法,问题会更加严重:这些无用的预读页会被插入到LRU链表头部,占据了“最近使用”的宝贵位置。而当内存不足需要淘汰时,被踢出的却是链表尾部那些真正的 「热点数据」 。
最终结果就是:无用的数据鸠占鹊巢,热点数据被无情淘汰,缓存命中率大幅下降,系统性能不升反降。
3. 解决方案:拆分LRU,隔离冷热数据
解决预读失效的核心思路是:让预读页在内存中“短暂停留”,只允许真正被访问的热点数据长期驻留。
Linux和MySQL不约而同地采用了类似的改进方案——将LRU结构进行拆分,分别管理冷数据(访问频率低)和热数据(访问频率高)。
3.1 Linux:双LRU链表(active_list + inactive_list)
Linux将缓存页的管理拆分为两个独立的链表:
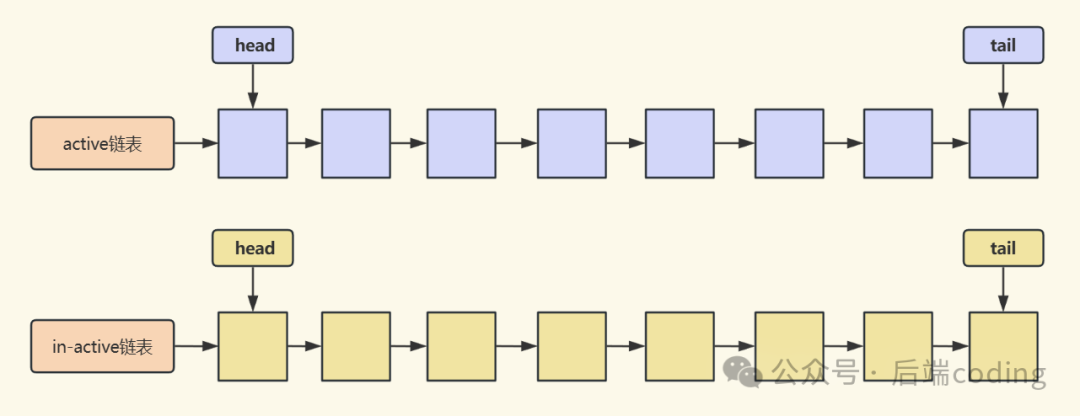
- active_list(活跃链表):存放最近被反复访问的热数据页,这些页会受到“长期保护”。
- inactive_list(非活跃链表):存放很少被访问的冷数据页,它们是优先被淘汰的对象。
优化后的工作逻辑如下:
- 新加载的预读页只插入到inactive_list的头部,不会侵占active_list中热点数据的位置。
- 如果这个预读页后续被真正访问到,则将其移动到active_list的头部,晋升为热数据。
- 如果预读页始终未被访问,它会随着时间推移移动到inactive_list尾部并被淘汰,整个过程完全不影响active_list中的热点数据。
3.2 MySQL InnoDB:单LRU链表拆分区域(young + old)
InnoDB没有采用两个独立链表,而是在一个LRU链表上划分出两个区域(默认比例:young区域占5/8,old区域占3/8):
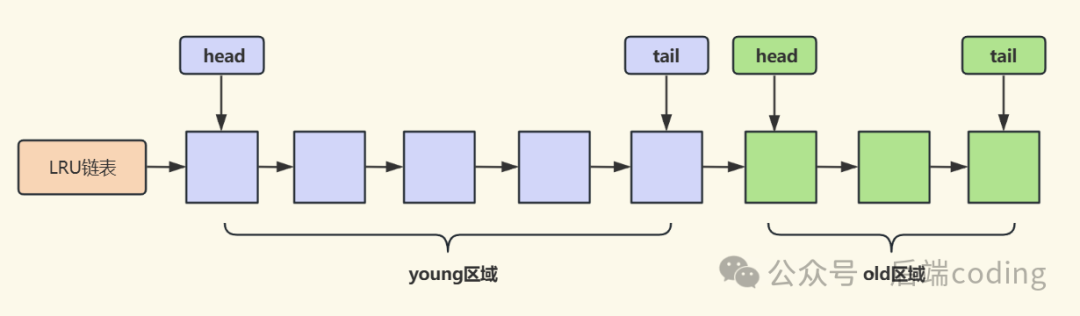
- young区域(热数据区):位于链表前半部分,存放高频访问的热点数据页。
- old区域(冷数据区):位于链表后半部分,存放新加载或低频访问的冷数据页。
优化后的工作逻辑如下:
- 预读页及新加载的数据页只插入到old区域的头部。
- 只有当这些页在old区域中被再次访问时,才会被移动到young区域的头部,完成“转正”。
- 始终未被二次访问的页,会在old区域尾部被淘汰,从而确保young区域纯净。
痛点二:缓存污染
解决了预读失效,我们迎来了另一个挑战——缓存污染。即便隔离了冷热数据,如果进入热数据区的“门槛”过低,热点数据依然可能被一次性涌入的冷数据“冲走”。
1. 什么是缓存污染?
当我们执行 「批量扫描」 操作时(例如全表扫描、导出大量数据),大量冷数据会被依次访问一次。如果按照上述“访问一次就晋升”的规则,这些一次性访问的数据会全部涌入热数据区。
后果就是:热数据区被这些“一次性访客”迅速填满,原本驻留在其中的高频热点数据被全部挤出。随后,这些批量数据不再被访问,导致整个热数据区被“污染”,缓存命中率瞬间触底。典型的场景包括批量数据导出、大型日志文件分析等。
2. 解决方案:提高热数据区的“晋升”门槛
缓存污染的根源在于“一次访问即晋升”的规则过于宽松。因此,解决方案非常明确:大幅提高数据页从冷区晋升到热区的门槛,确保只有真正的“活跃分子”才能入驻。
2.1 Linux:两次访问升级机制
Linux的规则简单而有效:一个内存页必须被访问至少两次,才有资格从inactive_list晋升到active_list。
这样一来,批量扫描产生的数据页通常只会被顺序访问一次,无法满足“两次访问”的条件,因此它们会永远停留在inactive_list中,最终被淘汰,而不会污染active_list。
2.2 MySQL InnoDB:两次访问 + 时间间隔过滤
InnoDB的规则更为严谨,它引入了 「时间阈值」(默认innodb_old_blocks_time为1000毫秒)作为第二道过滤网:
- 数据页在old区域被第一次访问时,会记录一个时间戳。
- 当它被第二次访问时,系统会检查两次访问的间隔时间。
- 如果间隔 ≤ 1秒:则认为可能是顺序扫描(如批量查询)的一部分,不予晋升,使其留在old区域。
- 如果间隔 > 1秒:则认为是离散的真实业务请求,准予晋升到young区域。
这个设计极为巧妙。批量扫描的冷数据,即便被访问两次,其间隔通常也在毫秒级,无法突破1秒的阈值,从而被拦截在热区之外。而真正的热点数据,其访问模式是离散且存在时间间隔的,能够顺利晋升。
总结:两大系统的缓存优化哲学
无论是Linux的Page Cache,还是MySQL InnoDB的Buffer Pool,其缓存优化的核心哲学都是一致的:精准识别并区分数据的冷热属性,不惜代价保护热点数据,毫不犹豫地淘汰冷数据。具体策略可归结为两大应对措施:
- 应对预读失效:通过拆分LRU结构(双链表或冷热分区),为预读页设置“缓冲区”。预读页必须先进入冷数据区“实习”,只有被真正访问后才能“转正”进入热数据区,从而避免无效预读对热点空间的挤占。
- 应对缓存污染:通过设置更高的“晋升”门槛(如两次访问规则、时间间隔过滤),将一次性访问或顺序扫描的冷数据牢牢挡在热数据区之外,确保热区资源的纯净与高效利用。
深入理解这些底层机制,不仅能帮助我们在遇到缓存命中率低下、磁盘I/O异常等性能问题时快速定位根因,更能为我们的日常开发(如设计本地缓存策略、优化数据库查询模式)提供宝贵的设计思路。优秀的缓存设计,是保障后端系统高效稳定运行的基石。欢迎在技术社区中继续交流与探讨相关的实践心得。
 发表于 2026-1-25 02:24:00
|
查看: 155|
回复: 0
发表于 2026-1-25 02:24:00
|
查看: 155|
回复: 0
