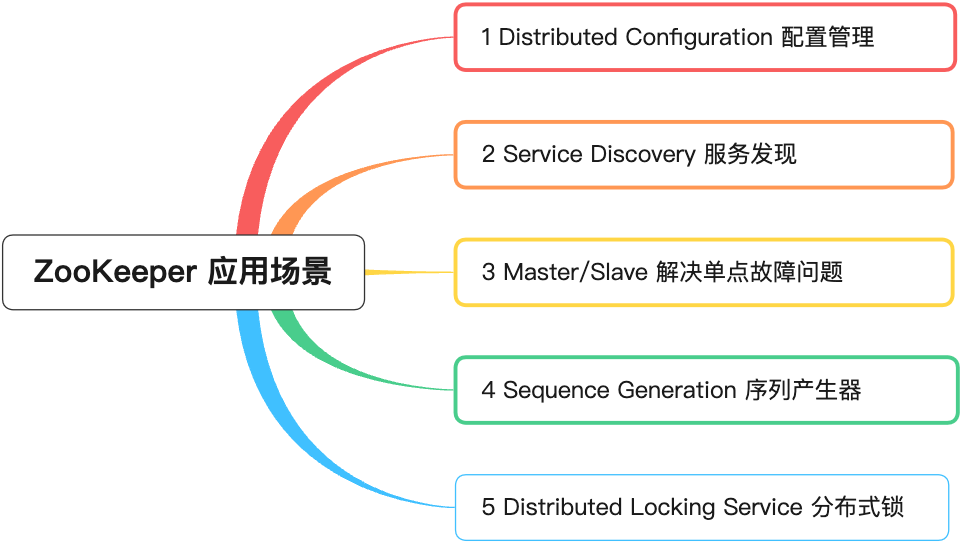
1 配置管理
在项目开发和维护中,经常会遇到大量需要统一管理的公共配置或资源。传统做法是将它们写在公共类或配置文件中,但一旦配置变更,就需要重新部署应用,过程繁琐。尤其在微服务和分布式架构普及后,管理和同步多个服务的配置变得愈发复杂。
为应对这些挑战,实现“一次构建,多处部署”,降低维护成本和风险,业界普遍采用将可变配置外部化并通过可视化界面统一管理的方案,这就是配置中心的核心理念。
下图展示了配置中心的通用架构设计:
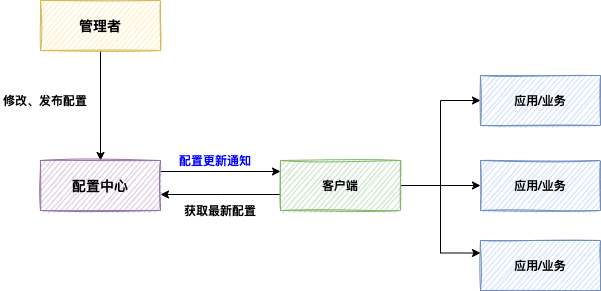
ZooKeeper 天然适合作为配置中心的底座,其优势主要体现在两点:
- 配置数据可以存储在 ZooKeeper 的节点中。
- 应用可以注册对该节点的 Watch 监听,一旦节点数据变更,所有订阅的客户端都能实时收到通知。
基于 ZooKeeper 的配置管理流程如下图所示:
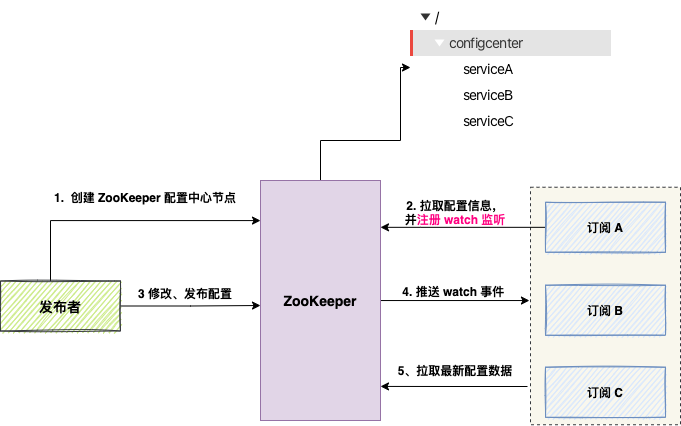
具体流程如下:
- 配置发布:发布者作为 ZooKeeper 客户端,在 ZK 中创建一个节点,其数据内容即为应用服务 A 的配置文件。
- 配置获取:应用服务 A 启动时,从该 ZK 节点读取数据,完成配置初始化。
- 注册监听:读取配置后,应用服务 A 向该节点注册一个数据变更的 Watcher 监听。
- 变更通知:当发布者更新配置并写入对应节点时,ZooKeeper 会触发 Watcher 事件,并向所有监听的应用 A 推送通知。
- 配置热更新:应用 A 收到事件后,触发回调方法,重新从 ZK 拉取最新的配置数据,实现配置的动态更新。
2 服务发现
在服务大规模部署后,服务数量急剧增长。服务消费者调用服务提供者时,通常需要在配置文件中硬编码提供者的地址(URL)。当提供者发生故障、扩缩容或地址变更时,所有相关的消费者都需要手动更新配置,维护成本极高。
因此,实现服务上下线的动态感知和地址的自动维护变得至关重要。
下图为我们熟知的 RPC框架 Dubbo 的架构。服务提供者启动后,会将自己的服务注册到注册中心;服务消费者则从注册中心订阅所需服务。消费者获取路由信息后,便可直接调用提供者。
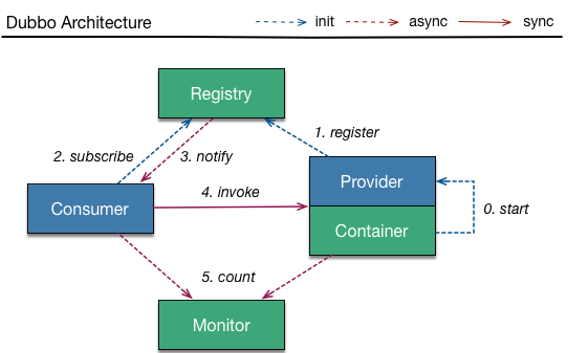
ZooKeeper 提供了对 Znode 的订阅/通知机制,当节点状态或客户端连接状态变化时会触发事件。这一机制为服务调用者实时感知提供者状态变化提供了完美的解决方案。
在 Dubbo 中,利用 ZooKeeper 实现服务注册与发现的典型目录结构如下:
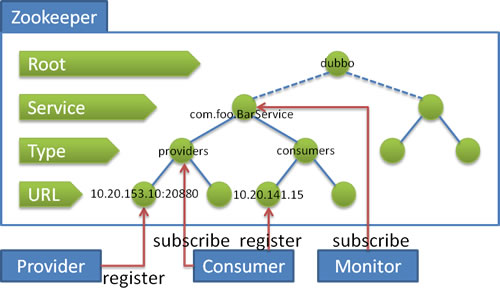
具体流程:
- 服务提供者启动时:向
/dubbo/com.foo.BarService/providers 目录下写入自己的 URL 地址。
- 服务消费者启动时:订阅
/dubbo/com.foo.BarService/providers 目录下的提供者地址,并向 /dubbo/com.foo.BarService/consumers 目录写入自己的 URL 地址。
- 监控中心启动时:订阅
/dubbo/com.foo.BarService 目录下的所有提供者和消费者 URL 地址,实现服务治理。
3 Master / Slave 选举与高可用
在分布式架构中,为保证服务高可用,常采用集群模式:当某个节点故障时,集群中的其他节点能接替其工作。
在这种模式下,需要从集群中选出一个节点作为 Master(主节点)负责协调或处理核心任务,其余节点作为 Slave(备节点)待命。当 Master 故障时,需要从 Slave 中快速选举出新的 Master。
利用 ZooKeeper 实现 Master选举 主要有以下两种经典方式:
3.1 争抢创建临时节点
此方法利用了 ZooKeeper 的一个特性:多个客户端同时创建同一个路径的临时节点时,最终只有一个客户端能成功。
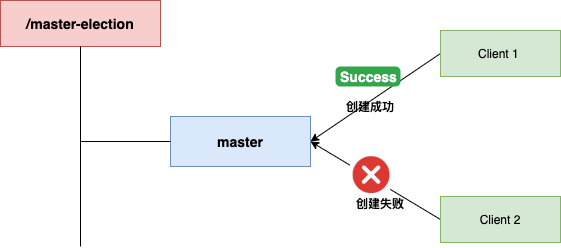
具体步骤如下:
- 选举:集群中所有节点同时发起创建临时节点
/master-election/master 的请求。创建成功的客户端所在节点即成为 Master,其余成为 Slave。
- 监听:所有 Slave 向该临时节点的父节点
/master-election 注册一个子节点列表变更的 Watcher 监听。
- 故障转移:一旦 Master 宕机,其会话结束,临时节点自动删除。ZooKeeper 会向所有 Slave 发送子节点变更事件。Slave 收到事件后,再次发起创建临时节点的请求,新一轮选举开始,新创建成功的节点成为新任 Master。
3.2 创建临时有序节点
这是一种更为优雅和有序的选举方式。
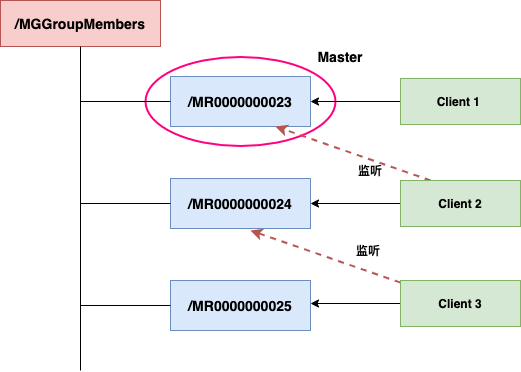
设计思路如下:
- 创建父节点:创建一个持久的(Persistent)父节点,例如
/election,作为选举的根路径。
- 创建子节点:每个参与选举的节点启动时,都在
/election 下创建一个临时的、带顺序编号的子节点(Ephemeral Sequential),例如 /election/node_00000001。
- 确定Master:所有子节点按序号排序,序号最小的节点对应的客户端被选为 Master。
- Slave监听:每个 Slave 客户端监听比自己序号小的、序号最大的那个节点的
NodeDeleted 事件。
- Master晋升:当某个 Slave 监听的节点被删除(意味着其对应的客户端失效),该 Slave 会检查是否自己已成为最小序号节点。如果是,则晋升为新的 Master;如果不是,则更新监听目标为新的“前一个”节点。
4 分布式序列号生成器
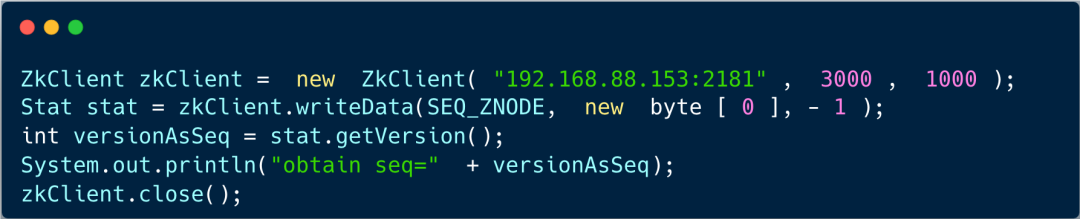
在分布式系统中,经常需要生成全局唯一的递增序列号(如订单号)。ZooKeeper 可以利用其节点的数据版本号(Version)特性来实现一个简单的序列号生成器。
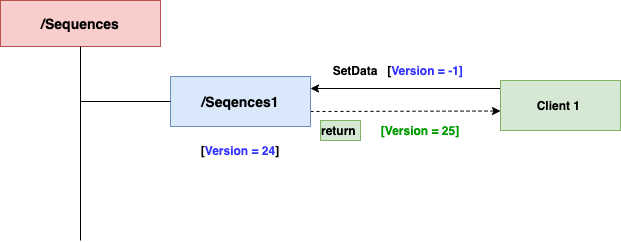
核心流程如下:
- 创建持久节点:首先在 ZooKeeper 中创建一个用于存储序列号的持久节点,例如
/sequence。
- 设置版本号:客户端在调用
setData 操作时,将数据版本号(Version)参数设置为 -1。这告诉 ZooKeeper 忽略版本校验,总是执行成功,并自动将节点的数据版本号加 1。
- 获取序列号:操作成功后,ZooKeeper 返回的最新数据版本号,即可作为全局唯一的递增序列号使用。
该方案的优点是一次 RPC 调用即可获取序列号,性能较高。缺点是受限于 ZooKeeper 数据版本号为 32 位整数,序列号范围有限。
伪代码示例如下:
5 分布式锁服务
分布式锁是控制分布式系统或集群中多进程/线程同步访问共享资源的一种机制。ZooKeeper 凭借其强一致性和临时顺序节点特性,可以实现高效的分布式锁。
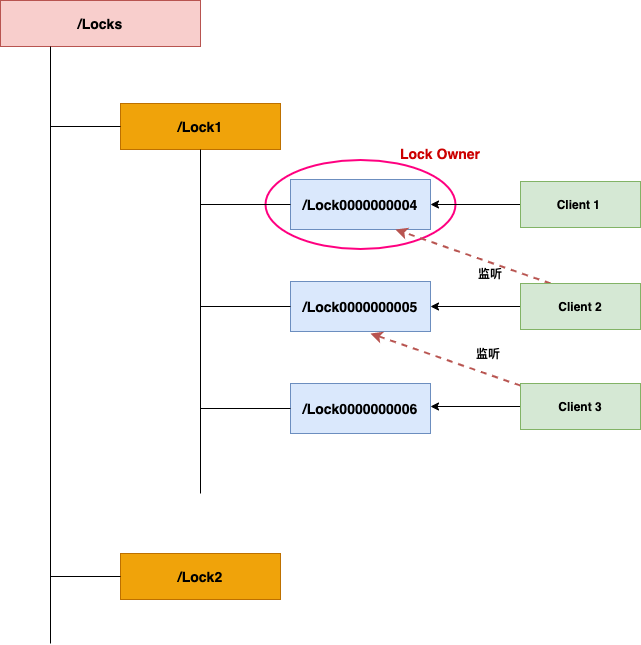
核心实现流程如下:
- 定义锁:为每一种锁资源在 ZooKeeper 中创建一个持久的父节点,作为锁的命名空间,例如
/locks/Lock1。
- 申请锁:客户端尝试获取锁时,在锁节点(例如
/locks/Lock1)下创建一个临时的、带顺序的子节点,如 lock_00000001。
- 检查锁:客户端获取锁父节点下的所有子节点,并按序号排序。
- 获取锁:如果客户端发现自己创建的子节点序号是当前最小的,则表示成功获取锁。
- 释放锁:持有锁的客户端完成业务逻辑后,主动删除自己创建的子节点即可释放锁。由于是临时节点,即使客户端崩溃,连接断开后节点也会自动删除,避免了死锁。
- 等待锁:如果客户端创建的节点不是序号最小的,它需要监听比自己序号小的、最近的那个节点的
NodeDeleted 事件。
- 锁晋升:当监听的节点被删除(前一个锁持有者释放了锁),当前客户端会收到通知,然后重复步骤3-4,检查自己是否已成为最小序号节点,从而决定是否获取锁。
|  发表于 2025-12-2 02:07:22
|
查看: 260|
回复: 0
发表于 2025-12-2 02:07:22
|
查看: 260|
回复: 0
