在 SpringBoot 项目开发中,你是否也曾写过类似下面这样的代码?
@GetMapping("/orders")
public List<Order> listOrders(){
return orderDao.findAll();
}
这段代码一次性查询所有订单,对一张拥有50万行数据的表进行全表扫描,不仅导致接口查询性能极差,在数据量极大时,甚至可能引发 OOM 问题。
问题根源:
这次事故让我深刻认识到:性能优化必须贯穿开发全流程。今天,我们在云栈社区探讨的正是 SpringBoot 项目中值得关注的12个性能优化要点,希望能为你提供一些实战思路。
第1招:连接池参数调优
问题场景:
默认配置常常导致连接池资源浪费,高并发下容易出现连接等待,甚至耗尽。
反面示例:
spring:
datasource:
hikari:
maximum-pool-size: 1000
connection-timeout: 30000
盲目设置过大的最大连接数和过长的连接超时时间,会加剧数据库负担和线程等待。
优化方案:
spring:
datasource:
hikari:
maximum-pool-size: ${CPU核心数*2} # 根据CPU核心数动态调整
minimum-idle: 5
connection-timeout: 3000 # 缩短至3秒超时
max-lifetime: 1800000 # 连接最大生命周期30分钟
idle-timeout: 600000 # 空闲连接10分钟后释放
核心在于根据实际服务器资源和业务压力进行动态配置,避免资源的无效占用。
第2招:JVM内存优化
问题场景:
不当的 JVM 参数设置会导致频繁的 Full GC,造成服务响应卡顿,用户体验下降。
启动参数优化:
java -jar -Xms4g -Xmx4g
-XX:NewRatio=1
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:InitiatingHeapOccupancyPercent=35
-XX:+AlwaysPreTouch
-Xms4g -Xmx4g:将初始堆内存和最大堆内存设为一致,避免运行时动态调整带来的性能开销。-XX:NewRatio=1:新生代与老年代的内存比例为1:1,适应对象生命周期较短的Web应用。-XX:+UseG1GC:采用G1垃圾收集器,以追求可预测的停顿时间为目标。-XX:MaxGCPauseMillis=200:设定GC最大停顿时间为200毫秒。-XX:+AlwaysPreTouch:启动时即分配并初始化所有内存,减少运行时延迟。
第3招:关闭无用组件
问题场景:
SpringBoot 的自动装配(Auto-Configuration)非常便捷,但有时会加载当前项目并不需要的 Bean,造成不必要的内存和启动时间开销。
优化方案:
在启动类中,使用 exclude 属性显式排除不需要的自动配置类。
@SpringBootApplication(exclude = {
DataSourceAutoConfiguration.class,
SecurityAutoConfiguration.class
})
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
例如,如果当前模块不需要数据库或安全框架,就可以排除对应的自动配置类。
第4招:响应压缩配置
问题场景:
接口返回的 JSON 或 HTML 数据体积过大,特别是在列表查询或复杂对象返回时,会显著增加网络传输时间。
优化方案:
在 application.yml 中启用响应压缩。
server:
compression:
enabled: true
mime-types: text/html,text/xml,text/plain,text/css,text/javascript,application/json
min-response-size: 1024
当响应体大小超过 min-response-size(这里设为1KB)且 Content-Type 匹配时,服务器会自动对响应进行 GZIP 压缩,有效减少网络带宽消耗。
第5招:请求参数校验
问题场景:
缺乏参数校验的接口容易遭受恶意请求攻击,例如传入超大的分页参数导致数据库过载,或进行全表扫描耗尽资源。
防御代码:
在 Controller 方法参数上使用 JSR-303 注解进行校验。
@GetMapping("/products")
public PageResult<Product> list(
@RequestParam @Max(value=100, message="页大小不能超过100") int pageSize,
@RequestParam @Min(1) int pageNum) {
//...
}
通过 @Max、@Min、@NotNull 等注解,在请求进入业务逻辑前就拦截非法参数,这是一种成本极低但收益显著的防护手段。
第6招:异步处理机制
问题场景:
某些耗时操作(如发送邮件、生成报表、调用外部慢接口)如果同步执行,会长时间占用 Web 容器的处理线程,导致整体吞吐量下降。
优化方案:
利用 Spring 的 @Async 注解和自定义线程池实现异步处理。
@Async("taskExecutor")
public CompletableFuture<List<Order>> asyncProcess() {
return CompletableFuture.completedFuture(heavyProcess());
}
@Bean("taskExecutor")
public Executor taskExecutor(){
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(500);
return executor;
}
定义一个专用的线程池来处理异步任务,避免影响主业务流程的响应速度。
第7招:使用缓存
缓存是提升系统性能最直接有效的手段之一,可以大幅减少对数据库等慢速存储的访问。
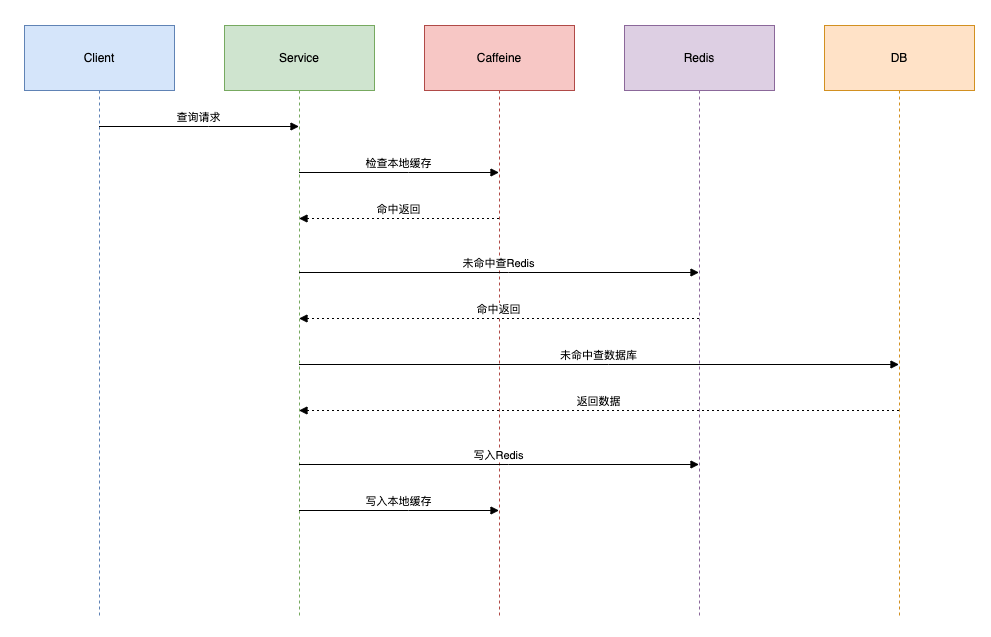
缓存架构:
一个典型的分布式系统缓存查询流程如下图所示,遵循“先本地,后远程,最后数据库”的查询顺序。
代码实现:
结合 Spring Cache 与 Caffeine(高性能本地缓存库)使用。
@Cacheable(cacheNames = "products", key = "#id",
cacheManager = "caffeineCacheManager")
public Product getDetail(Long id){
return productDao.getById(id);
}
通过 @Cacheable 注解,方法返回值会被自动缓存。下次相同参数调用时,直接返回缓存结果,无需执行方法体。
第8招:批量操作优化
问题场景:
在数据迁移或批量导入场景下,使用 for 循环逐条执行 INSERT/UPDATE 语句,会产生大量的网络IO和数据库事务开销,性能极其低下。
优化方案:
使用 JdbcTemplate 的 batchUpdate 方法进行批量操作。
@Transactional
public void batchInsert(List<Product> products){
jdbcTemplate.batchUpdate(
"INSERT INTO product(name,price) VALUES(?,?)",
products,
500, // 每批处理500条数据
(ps, product) -> {
ps.setString(1, product.getName());
ps.setBigDecimal(2, product.getPrice());
});
}
将大量操作分批提交,可以显著减少与数据库的交互次数,提升数倍乃至数十倍的写入性能。
第9招:索引深度优化
问题场景:
慢查询日志中频繁出现全表扫描,SQL 执行时间波动巨大,数据库服务器 CPU 持续高负载。
错误案例:
-- 商品表结构
CREATE TABLE products (
id BIGINT PRIMARY KEY,
name VARCHAR(200),
category VARCHAR(50),
price DECIMAL(10,2),
create_time DATETIME
);
-- 低效查询
SELECT * FROM products
WHERE category = '手机'
AND price > 5000
ORDER BY create_time DESC;
上述查询在未建立合适索引的情况下,需要进行全表扫描、过滤、排序,效率极低。
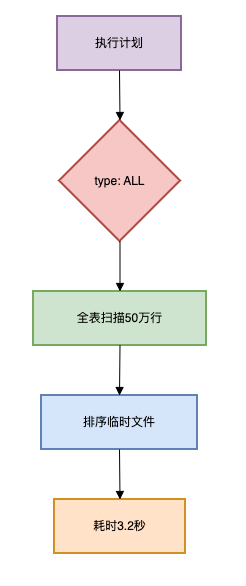
问题分析:
下图展示了一次低效查询的执行流程,涉及全表扫描和临时文件排序,耗时长达3.2秒。
优化方案一:联合索引设计
针对 WHERE category = ? AND price > ? ORDER BY create_time DESC 这样的查询条件,可以创建覆盖了筛选和排序字段的联合索引。
ALTER TABLE products
ADD INDEX idx_category_price_create
(category, price, create_time);
该索引遵循最左前缀原则,能高效定位数据并利用索引的有序性避免额外排序。
优化方案二:覆盖索引优化
如果查询的字段都包含在索引中,数据库可以直接从索引中获取所需数据,无需回表,这被称为覆盖索引。
SELECT id, category, price, create_time
FROM products
WHERE category = '手机'
AND price > 5000
ORDER BY create_time DESC;
将 SELECT * 改为只查询索引包含的字段,性能提升会非常明显。
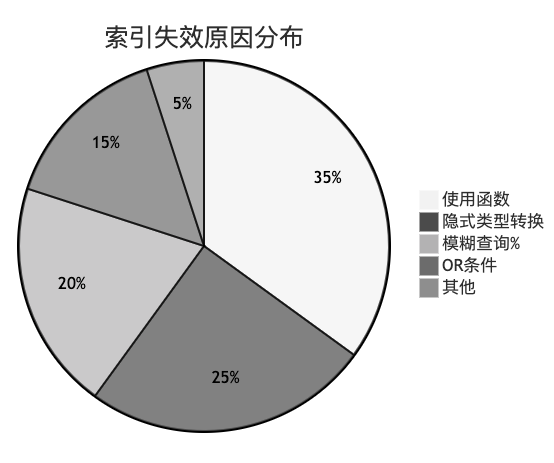
优化方案三:索引失效预防
很多不当的 SQL 写法会导致索引失效。下图展示了几种常见的索引失效原因及其分布。
例如,在索引字段上使用函数会导致索引失效:
错误写法:
SELECT * FROM products
WHERE DATE(create_time) = '2023-01-01';
正确写法:
SELECT * FROM products
WHERE create_time BETWEEN '2023-01-01 00:00:00'
AND '2023-01-01 23:59:59';
使用范围查询代替函数操作,可以保证索引的有效使用。
优化方案四:索引监控分析
定期监控和分析索引的使用情况至关重要。
- 查看索引使用情况:
SELECT
index_name,
rows_read,
rows_selected
FROM
sys.schema_index_statistics
WHERE
table_name = 'products';
- 分析 SQL 执行计划:
EXPLAIN FORMAT=JSON
SELECT ...;
通过执行计划可以清晰看到 SQL 是否使用了索引、使用了哪个索引、是否有额外的排序或临时表操作。
索引优化黄金三原则
- 最左前缀原则:联合索引的第一个字段必须出现在查询条件中。
- 短索引原则:优先使用整型字段,字符串字段可考虑前缀索引。
- 适度索引原则:单表索引数量建议不超过5个,总索引长度不超过表数据量的30%。
第10招:自定义线程池
问题场景:
直接使用 Executors 工具类创建固定大小或可缓存的线程池,在高并发场景下容易导致任务队列无限堆积(OOM)或线程数失控。
优化方案:
显式地使用 ThreadPoolExecutor 构造函数创建线程池,以便精准控制所有参数。
@Bean("customPool")
public Executor customThreadPool(){
return new ThreadPoolExecutor(
10, // 核心线程数
50, // 最大线程数
60, TimeUnit.SECONDS, // 空闲线程存活时间
new LinkedBlockingQueue<>(1000), // 有界任务队列
new CustomThreadFactory(), // 自定义线程工厂,便于日志追踪
new ThreadPoolExecutor.CallerRunsPolicy()); // 拒绝策略:调用者运行
}
自定义线程池允许你根据业务特性(CPU密集型、IO密集型)设置合理的核心/最大线程数、队列容量和拒绝策略,这是保障系统稳定性的重要一环。
第11招:熔断限流策略
问题场景:
突发的流量洪峰(如秒杀、热点新闻)可能瞬间击垮下游服务,导致服务雪崩,整个链路不可用。
解决方案:
集成 Sentinel 或 Resilience4j 等容错组件,为关键接口实施熔断、限流和降级。
这里以 Sentinel 为例:
// 使用Sentinel实现接口限流
@SentinelResource(value = "orderQuery",
blockHandler = "handleBlock",
fallback = "handleFallback")
@GetMapping("/orders/{id}")
public Order getOrder(@PathVariable Long id){
return orderService.getById(id);
}
// 限流处理(被流控规则触发)
public Order handleBlock(Long id, BlockException ex){
throw new RuntimeException("服务繁忙,请稍后重试");
}
// 降级处理(方法执行异常时触发)
public Order handleFallback(Long id, Throwable t){
return Order.getDefaultOrder(); // 返回兜底数据
}
通过 @SentinelResource 注解定义资源点,并配置对应的流控(限流)、降级规则,当请求量超过阈值或服务异常时,快速失败或返回友好降级信息,保护系统核心链路。
第12招:全链路监控体系
问题场景:
线上系统出现性能问题或异常时,定位困难,缺乏直观的数据支撑来判断问题根源,导致故障恢复时间(MTTR)过长。
一个完整的监控体系是性能优化的眼睛。Spring Boot Actuator 集成了 Micrometer,可以方便地对接各种监控系统。
监控方案:
在 application.yml 中暴露监控端点并启用 Prometheus 格式的指标输出。
management:
endpoints:
web:
exposure:
include: "*"
metrics:
export:
prometheus:
enabled: true
监控架构:
下图展示了一个典型的 SpringBoot 应用监控与日志分析架构,结合了 Prometheus + Grafana 的指标监控和 ELK 的日志分析。
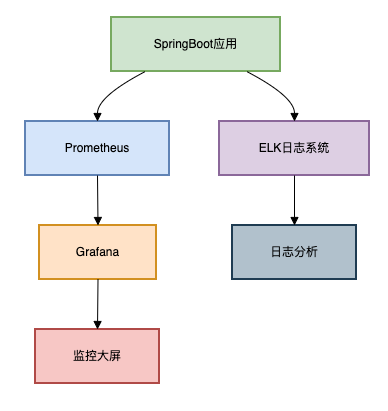
核心监控指标:
你需要关注以下几类核心指标,它们能全面反映应用的健康状态。下图展示了一种可能的监控指标关注度分布。
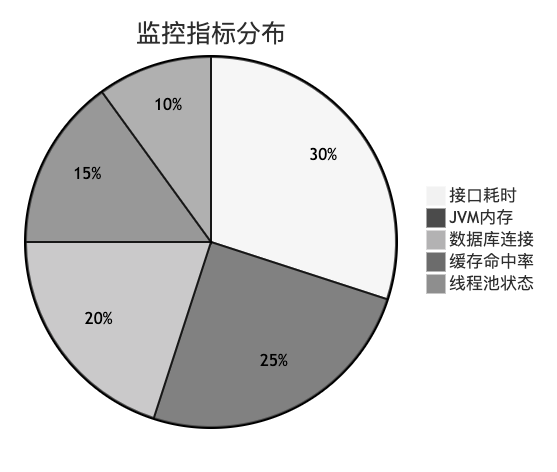
- 应用层面:接口QPS、RT、错误率、关键业务指标。
- JVM层面:堆内存使用率、GC频率与耗时、线程状态。
- 中间件层面:数据库连接池使用率、Redis缓存命中率、MQ堆积情况。
- 系统层面:CPU、内存、磁盘IO、网络流量。
总结与思考
SpringBoot性能优化检查清单:
在项目上线前或进行性能评审时,可以对照此清单进行检查:
- [ ] 数据库连接池参数是否按业务压力调整?
- [ ] JVM 参数是否经过压测验证?
- [ ] 高频查询是否都走了缓存机制?
- [ ] 批量操作是否替代了逐条处理?
- [ ] 异步任务是否使用了定制的线程池?
- [ ] 核心接口是否配置了限流降级?
- [ ] 全链路监控是否覆盖了关键指标?
三条黄金法则:
- 预防性优化:在编码和设计阶段就考虑性能影响,而非事后补救。
- 数据驱动:依靠监控指标(而非猜测)来发现瓶颈并指导优化方向。
- 持续迭代:性能优化不是一次性的任务,而应随着业务发展和架构演进持续进行。
最后,通过监控数据了解线上问题的常见分布,能帮助我们优先解决主要矛盾。下图展示了一种线上性能问题的可能分布情况。
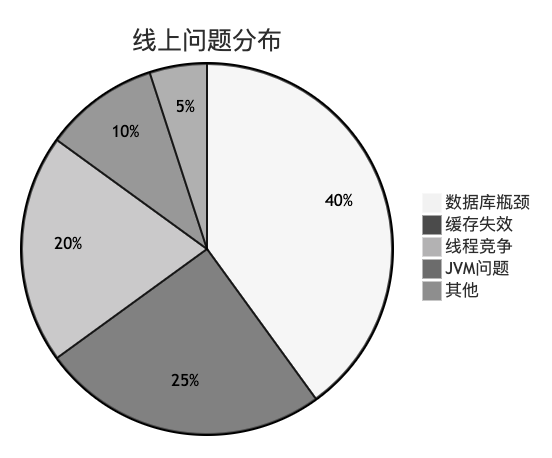
当监控大屏上展示着平稳的QPS曲线和健康的系统指标时,或许工程师才能真正安心。性能优化的终极目标,就是在保障业务稳定的前提下,最大化资源利用效率,提升用户体验。
 发表于 2026-3-7 16:51:27
|
查看: 247|
回复: 0
发表于 2026-3-7 16:51:27
|
查看: 247|
回复: 0
