大模型推理的核心瓶颈长期在于自回归解码的串行本质。投机解码(Speculative Decoding, SD)通过引入一个轻量级的草稿模型来预测后续 token,并交由目标模型并行验证,从而有效加速了推理过程。
然而,SD 算法本身依然受限于一道严格的串行依赖——草稿模型必须等待目标模型的验证完成,才能开始下一轮的起草。
近日,出自 Mamba、FlashAttention 核心作者 Tri Dao 之手的全新框架——Speculative Speculative Decoding (SSD) 正式发布。该算法彻底打破了起草与验证之间的串行壁垒。
在目标模型执行验证的同时,草稿模型直接预测最可能的验证结果,并为这些结果提前生成推测 token。如果实际验证结果命中预测,推测序列将立刻返回,起草延迟被完全消除。
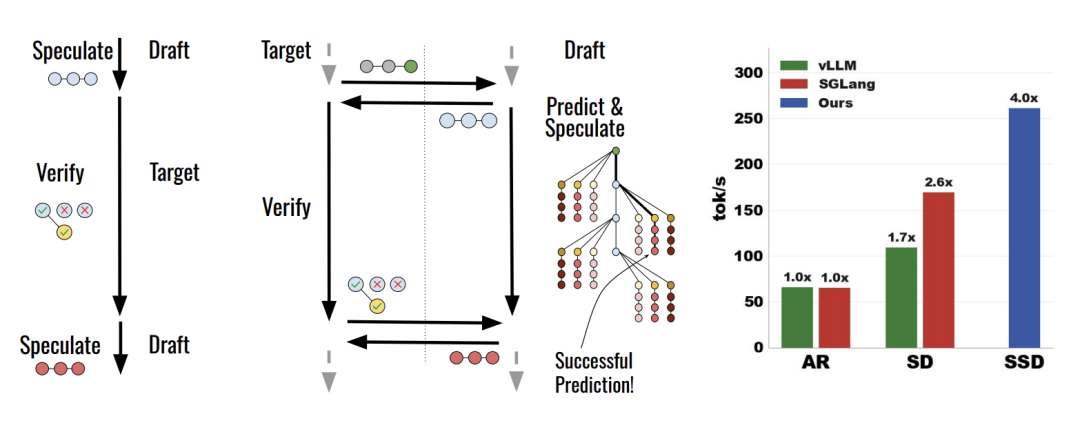
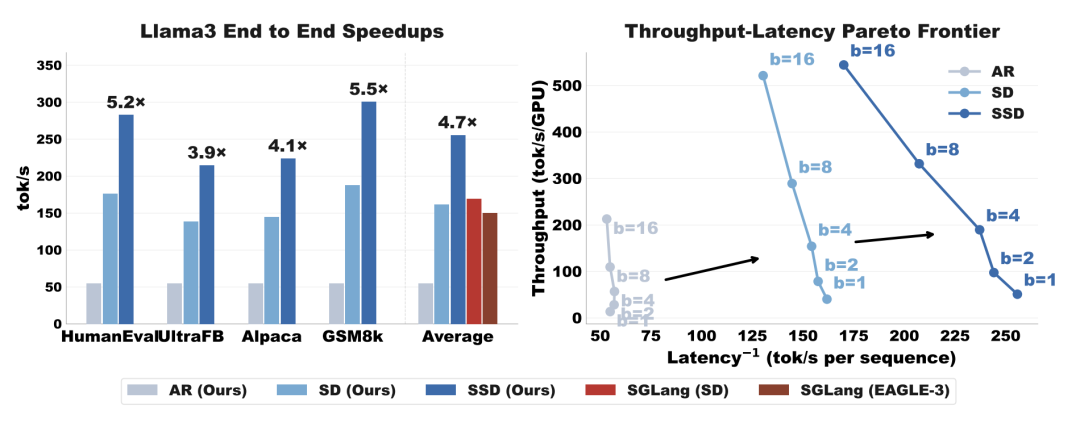
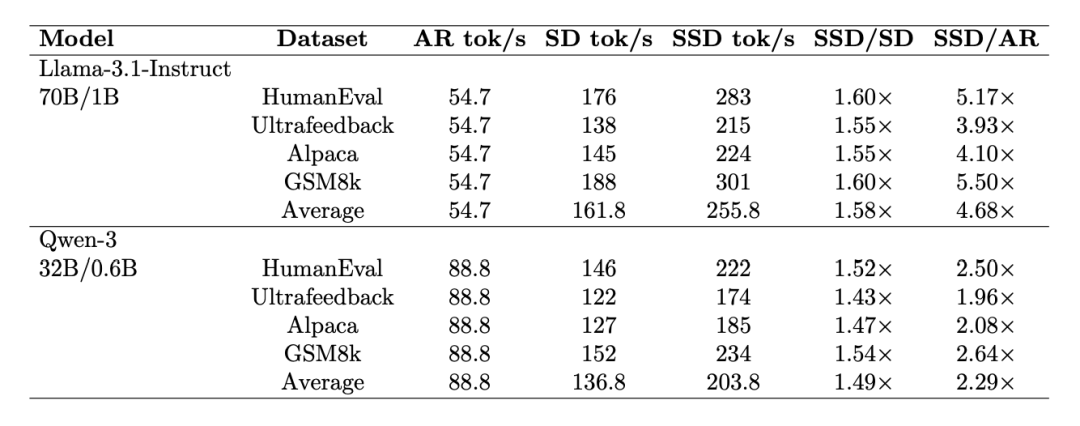
基于此框架实现的 Saguaro 算法,在 Llama-3 与 Qwen-3 系列模型上,实现了相较于自回归基线最高 5 倍的提速,相较于高度优化的开源推理引擎(如 vLLM 和 SGLang 中的 SD 实现)达到了最高 2 倍的性能提升。

论文标题:Speculative Speculative Decoding
论文链接:https://arxiv.org/pdf/2603.03251
代码链接:https://github.com/tanishqkumar/ssd
投机解码的瓶颈与 SSD 的核心机制
在标准 SD 中,系统效率的核心衡量指标是接受率 $\alpha$ 。接受率反映了草稿分布近似目标分布的程度,其定义如下:
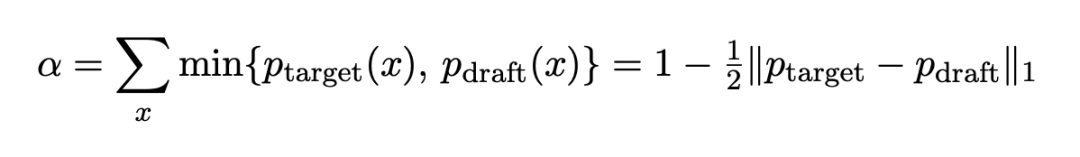
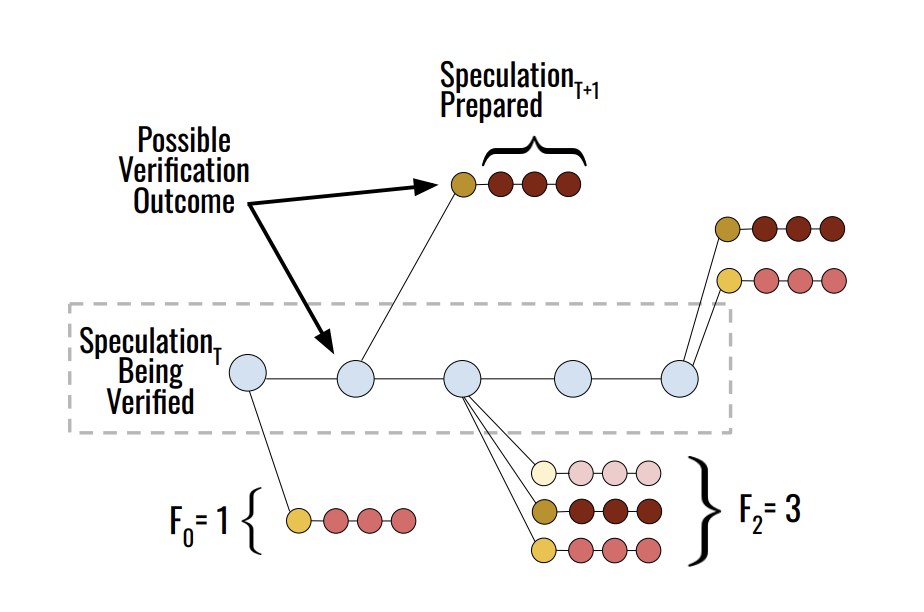
传统 SD 中,每一次验证必须等待前一次起草结束,反之亦然。SSD 则将草稿模型部署在独立的硬件节点上,使其在验证阶段保持异步运转。

在验证进行时,SSD 的草稿模型构建一个推测缓存(Speculation Cache)。一旦验证结果返回,系统仅需执行一次缓存查找。
SSD 的理论预期加速比直接取决于缓存命中率 $p_{hit}$、主推测器的耗时 $T_p$ 以及备份推测器的耗时 $T_b$:
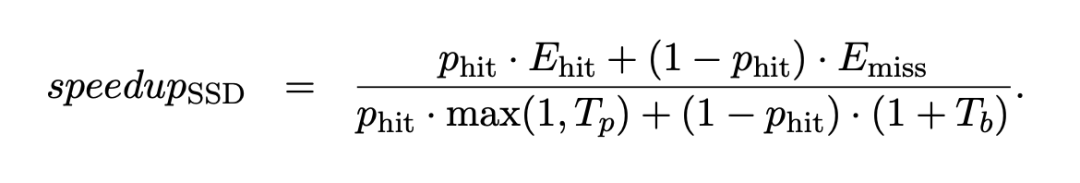
Saguaro 算法:解决异步推测的三大挑战
为了让 SSD 落地并逼近理论性能上限,研究团队设计了 Saguaro 算法,针对性地解决了三个关键的系统与算法挑战。
1. 验证结果预测与缓存拓扑优化
给定预测长度 $K$ 和词表大小 $V$,可能的验证结果空间约为 $V^K$,穷举推测在算力上并不可行。
Saguaro 将预测验证结果转化为一个约束优化问题:在给定的算力预算 $B$ 下,如何分配每个预测深度 $k$ 的分支数量(Fan-out)$F_k$ 以最大化缓存命中率。
证明表明,最优的 $F_k$ 分配服从截断几何级数:
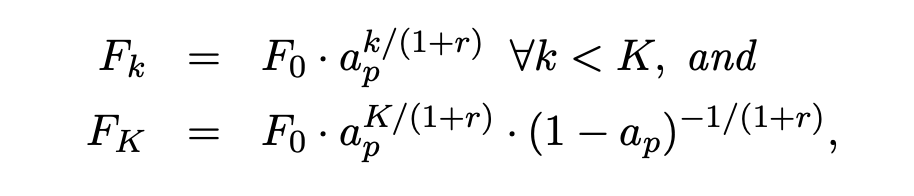
由于连续接受 $k$ 个 token 的概率随 $k$ 指数递减,系统应当在较浅的节点分配更多的算力分支来猜测 bonus token,而在较深的节点收敛算力。
2. 操纵残差分布
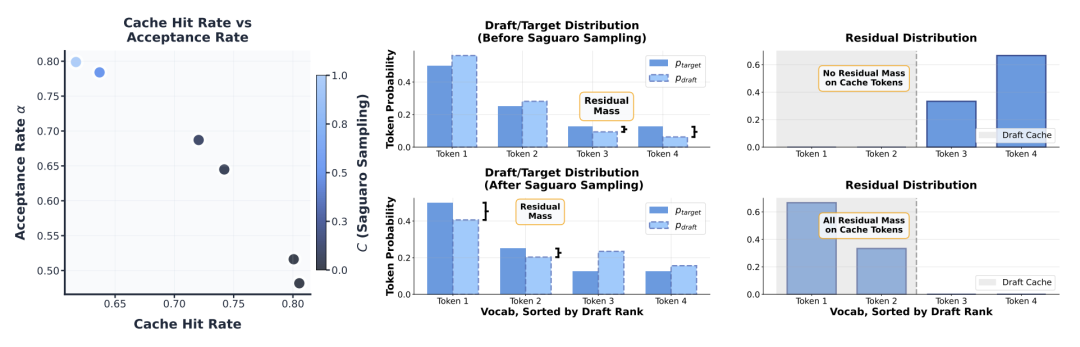
当推测的 token 被拒绝时,目标模型会从残差分布中采样 bonus token。残差分布定义为 $p_{target} - p_{draft}$。
该分布在高温下较难预测。Saguaro Sampling 通过在草稿分布中压低最高频 token 的采样概率来解决这一问题。
当 $C$ 减小,这些 token 在残差分布中的概率质量会相应增加,从而迫使 bonus token 大概率落入预设的缓存中。
其采样方案 $\sigma_{F, C}(z)$ 定义如下,其中 $C$ 为降权超参数:
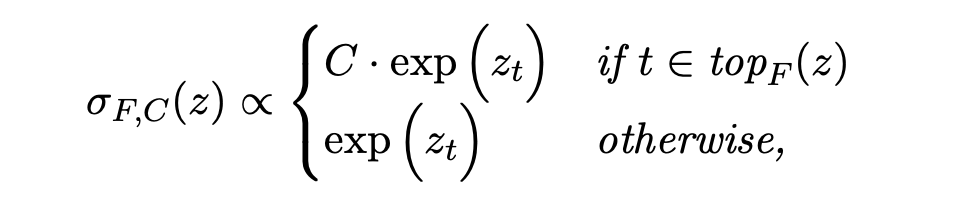
3. 大 Batch 下的退避策略
当 batch size 增大时,整个 batch 发生缓存未命中的概率上升。一旦未命中,系统必须退避至同步推测模式,整个 batch 都会阻塞在备份推测器的延迟上。
Saguaro 提出了一种动态退避策略。在低 batch size 下,使用高精度慢模型作为备份能带来更高收益。
而当 batch size 超过某个由命中率和系统延迟共同决定的临界值时,必须立刻切换为极低延迟的推测器(如返回随机 Token 或使用 n-gram 模型)以避免全局拖累。
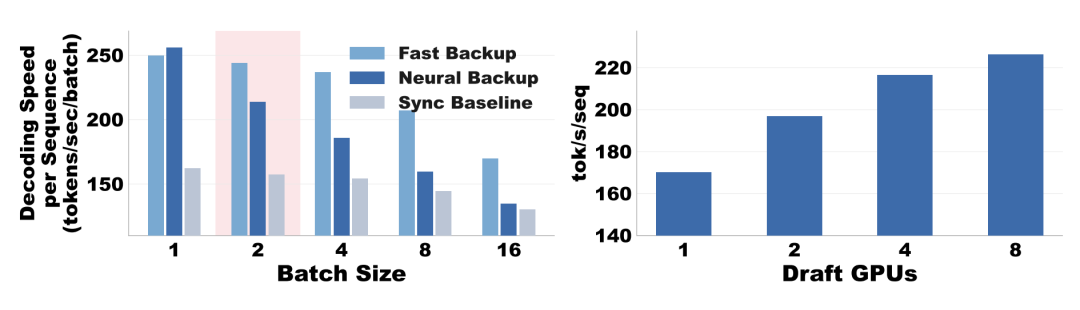
工程优化与系统表现
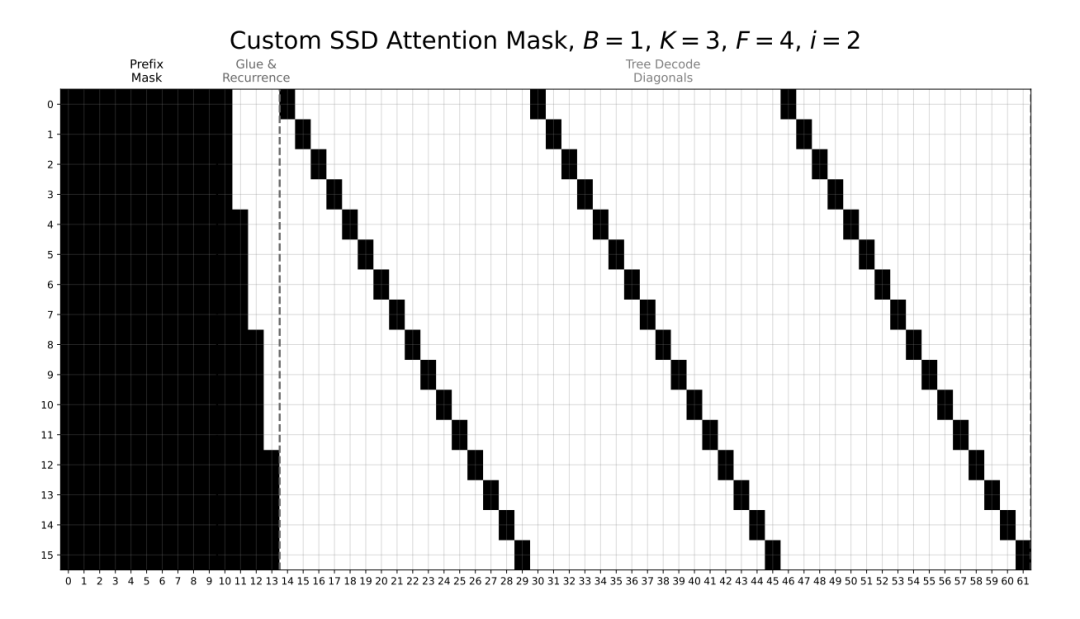
在异步推测阶段,草稿模型需要在一个前向传播中并行解码所有 $F_k$ 个分支。研究团队为此在推理引擎中开发了定制化的稀疏注意力掩码。
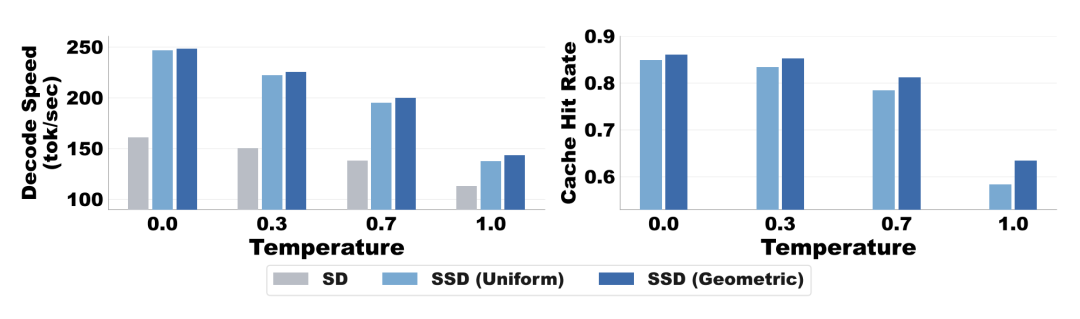
最终的端到端评估在 Llama-3 与 Qwen-3 上进行。测试表明,结合开源推理框架,SSD 能够在吞吐量与延迟的二维指标上突破现有的帕累托前沿。
结语
投机解码原本旨在牺牲计算资源换取低延迟,这往往导致它在吞吐量受限的场景(如大规模 RL 或离线数据生成)中难以施展拳脚。
然而,SSD 展现出了一种全新的可能性。通过极致的异步解耦,它不仅没有加重验证器的计算负担,反而实质性地拓宽了延迟与吞吐量的帕累托前沿。
SSD 的真正价值在于,它证明了在模型架构无需变动的前提下,系统级调度与底层算法的精细协同依然蕴含着巨大的性能红利。这为后续的推理优化研究,例如探索更高效的开源实战或改进Transformer架构的内部并行性,提供了新的思路和更高的基准。
 发表于 2026-3-7 16:47:28
|
查看: 210|
回复: 0
发表于 2026-3-7 16:47:28
|
查看: 210|
回复: 0
