你是否遇到过这样的情形:辛辛苦苦训练好的模型,在训练集上表现近乎完美,可一旦遇到新数据,预测结果就惨不忍睹。又或者,模型怎么“教”都“学不会”,连训练数据本身都拟合不好。
这背后,其实是构建高效深度学习模型时必须直面的三大核心挑战:模型选择、欠拟合和过拟合。理解并驾驭它们,是让你的模型从“实验室玩具”蜕变为“实用工具”的关键。
一、三大核心概念解析
1. 模型选择:为任务匹配“最佳拍档”
定义:模型选择是指在多种候选模型中,依据特定评估准则,挑选出最适合当前任务和数据集的那个模型的过程。
关键要素:
- 训练误差:模型在训练数据上的表现。
- 泛化误差:模型在从未见过的新数据(测试集)上的表现,这是我们真正关心的核心指标。
- 验证集:用于在训练过程中评估模型性能、调整超参数的“模拟考场”,不参与最终训练。
- 测试集:用于最终、一次性评估模型泛化能力的“正式考场”。
- K折交叉验证:当数据量稀缺时,将训练集分成K份,轮流将其中一份作为验证集,其余作为训练集,以充分利用数据、获得更稳健的评估结果。
生活比喻:就像招聘,不能只看候选人在培训期的模拟表现(训练误差),更要看他在实际岗位上的工作能力(泛化误差)。验证集好比试用期考察,而测试集则是最终的转正答辩。
2. 欠拟合:模型“学不会”的尴尬
定义:模型结构过于简单或训练不足,导致其无法捕捉数据中潜在的基本规律与模式。结果是训练误差和泛化误差都很高。
典型表现:
- 训练误差高
- 验证误差也高
- 训练误差与验证误差之间的差距很小
生活比喻:让一个幼儿园小朋友去解微积分题,无论怎么讲解,他都无法理解。这不是他不努力,而是问题的复杂度远远超出了他当前的认知能力。
3. 过拟合:模型“死记硬背”的陷阱
定义:模型结构过于复杂,或训练过度,导致其不仅学会了数据中的一般规律,还“记住”了训练数据中的噪声、随机波动和特定样本的无关细节。结果是训练误差极低,但泛化误差很高。
典型表现:
- 训练误差非常低(甚至接近于零)
- 验证误差显著高于训练误差
- 训练误差与验证误差之间的差距非常大
生活比喻:学生为了应付考试,把历年真题的答案背得滚瓜烂熟,却没有理解题目背后的知识点和解题逻辑。一旦考试中出现新的题型或问法,他就束手无策。
二、深度学习中的“三角”作用
1. 模型选择:平衡复杂性与泛化能力
在深度学习中,模型选择贯穿始终,它决定了:
- 神经网络的深度(层数)与宽度(每层神经元数)
- 激活函数(如ReLU, Sigmoid)的类型
- 正则化策略(如Dropout, L2)的应用与强度
- 优化器(如SGD, Adam)的选择与参数配置
其核心作用是找到模型复杂度的“甜点区”——刚好能捕捉数据中的关键规律,又不会对噪声和特例过度敏感。
2. 欠拟合:模型复杂度的“下限警示”
在深度学习中,欠拟合常表现为:
- 网络层数太少
- 神经元数量或通道数不足
- 学习率设置过低,导致收敛缓慢
- 训练轮次(Epoch)太少,模型尚未充分学习
它的关键作用是提醒我们:当前模型可能能力不足,需要增加模型容量或优化训练策略。
3. 过拟合:模型复杂度的“上限警示”
在深度学习中,过拟合常表现为:
- 网络过于庞大、参数过多
- 训练时间过长,在训练集上“钻牛角尖”
- 训练数据量相对模型复杂度而言不足
- 缺乏有效的正则化手段
它的关键作用是发出警告:模型可能变得太“复杂”或“敏感”,需要引入正则化、简化结构或增加数据。
三、实战案例:MNIST手写数字识别
让我们通过经典的MNIST数据集,使用PyTorch框架,直观地展示并比较欠拟合、适度拟合和过拟合三种状态。
1. 数据准备
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
import numpy as np
# 设置随机种子
torch.manual_seed(42)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载MNIST数据集
full_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, transform=transform)
# 划分训练集和验证集 (80%训练, 20%验证)
train_size = int(0.8 * len(full_dataset))
val_size = len(full_dataset) - train_size
train_dataset, val_dataset = random_split(full_dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=1000, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
2. 定义三种模型
class UnderfitModel(nn.Module):
"""欠拟合模型:过于简单"""
def __init__(self):
super(UnderfitModel, self).__init__()
self.fc1 = nn.Linear(784, 10) # 单层线性模型
def forward(self, x):
x = x.view(-1, 784)
return self.fc1(x)
class GoodFitModel(nn.Module):
"""适度拟合模型:适中复杂度"""
def __init__(self):
super(GoodFitModel, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = x.view(-1, 784)
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.relu(self.fc2(x))
x = self.dropout(x)
return self.fc3(x)
class OverfitModel(nn.Module):
"""过拟合模型:过于复杂"""
def __init__(self):
super(OverfitModel, self).__init__()
self.fc1 = nn.Linear(784, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 128)
self.fc4 = nn.Linear(128, 64)
self.fc5 = nn.Linear(64, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 784)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.relu(self.fc3(x))
x = self.relu(self.fc4(x))
return self.fc5(x)
3. 训练和评估函数
def train_model(model, train_loader, val_loader, epochs=10):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_losses = []
val_losses = []
train_accs = []
val_accs = []
for epoch in range(epochs):
# 训练阶段
model.train()
train_loss = 0.0
correct = 0
total = 0
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
train_loss /= len(train_loader)
train_acc = 100. * correct / total
train_losses.append(train_loss)
train_accs.append(train_acc)
# 验证阶段
model.eval()
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for data, target in val_loader:
output = model(data)
loss = criterion(output, target)
val_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
val_loss /= len(val_loader)
val_acc = 100. * correct / total
val_losses.append(val_loss)
val_accs.append(val_acc)
print(f'Epoch {epoch + 1}/{epochs}: Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%, '
f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')
return train_losses, val_losses, train_accs, val_accs
4. 训练三种模型并比较
print("\n=== 欠拟合模型训练 ===")
underfit_model = UnderfitModel()
train_losses_u, val_losses_u, train_accs_u, val_accs_u = train_model(underfit_model, train_loader, val_loader,
epochs=10)
print("\n=== 适度拟合模型训练 ===")
goodfit_model = GoodFitModel()
train_losses_g, val_losses_g, train_accs_g, val_accs_g = train_model(goodfit_model, train_loader, val_loader, epochs=10)
print("\n=== 过拟合模型训练 ===")
overfit_model = OverfitModel()
train_losses_o, val_losses_o, train_accs_o, val_accs_o = train_model(overfit_model, train_loader, val_loader, epochs=10)
# 5. 可视化结果
plt.figure(figsize=(15, 10))
# 训练损失对比
plt.subplot(2, 2, 1)
plt.plot(train_losses_u, label='Underfit (Train)', linestyle='--')
plt.plot(train_losses_g, label='Good Fit (Train)', linestyle='-')
plt.plot(train_losses_o, label='Overfit (Train)', linestyle=':')
plt.title('Training Loss Comparison')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
# 验证损失对比
plt.subplot(2, 2, 2)
plt.plot(val_losses_u, label='Underfit (Val)', linestyle='--')
plt.plot(val_losses_g, label='Good Fit (Val)', linestyle='-')
plt.plot(val_losses_o, label='Overfit (Val)', linestyle=':')
plt.title('Validation Loss Comparison')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
# 训练准确率对比
plt.subplot(2, 2, 3)
plt.plot(train_accs_u, label='Underfit (Train)', linestyle='--')
plt.plot(train_accs_g, label='Good Fit (Train)', linestyle='-')
plt.plot(train_accs_o, label='Overfit (Train)', linestyle=':')
plt.title('Training Accuracy Comparison')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.grid(True)
# 验证准确率对比
plt.subplot(2, 2, 4)
plt.plot(val_accs_u, label='Underfit (Val)', linestyle='--')
plt.plot(val_accs_g, label='Good Fit (Val)', linestyle='-')
plt.plot(val_accs_o, label='Overfit (Val)', linestyle=':')
plt.title('Validation Accuracy Comparison')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig('model_comparison.png')
plt.show()
5. 展示模型预测示例
def show_predictions(model, title):
model.eval()
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():
output = model(example_data)
pred = output.argmax(dim=1, keepdim=True)
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(example_data[i].squeeze(), cmap='gray')
plt.title(f"Pred: {pred[i].item()}\nTrue: {example_targets[i].item()}", fontsize=8)
plt.axis('off')
plt.suptitle(title)
plt.tight_layout()
plt.savefig(f'{title.lower().replace(" ", "_")}_predictions.png')
plt.show()
show_predictions(underfit_model, "Underfit Model Predictions")
show_predictions(goodfit_model, "Good Fit Model Predictions")
show_predictions(overfit_model, "Overfit Model Predictions")
四、结果分析
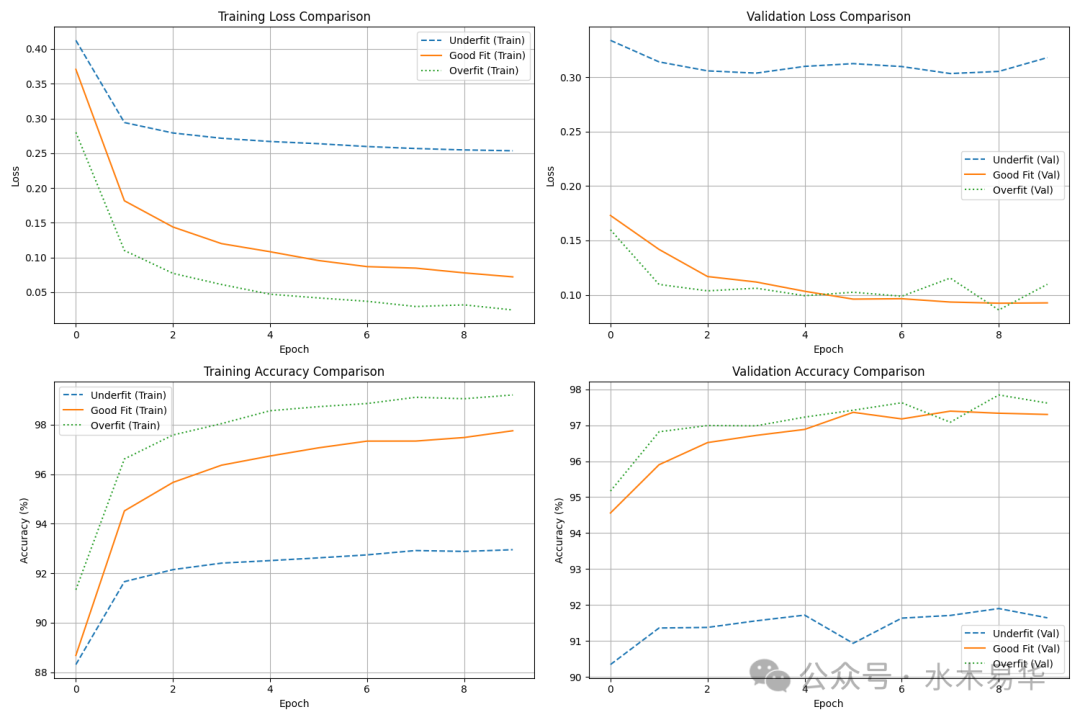
1. 欠拟合模型表现

- 训练损失和验证损失都很高,且下降缓慢。
- 训练准确率和验证准确率都较低,最终约在92%左右。
- 模型过于简单(单层线性),无法有效捕捉手写数字的复杂空间特征。
=== 欠拟合模型训练 ===
Epoch 1/10: Train Loss: 0.4124, Train Acc: 88.31%, Val Loss: 0.3338, Val Acc: 90.34%
Epoch 2/10: Train Loss: 0.2941, Train Acc: 91.66%, Val Loss: 0.3140, Val Acc: 91.36%
Epoch 3/10: Train Loss: 0.2791, Train Acc: 92.15%, Val Loss: 0.3057, Val Acc: 91.38%
Epoch 4/10: Train Loss: 0.2715, Train Acc: 92.41%, Val Loss: 0.3037, Val Acc: 91.56%
Epoch 5/10: Train Loss: 0.2668, Train Acc: 92.51%, Val Loss: 0.3099, Val Acc: 91.72%
Epoch 6/10: Train Loss: 0.2637, Train Acc: 92.62%, Val Loss: 0.3124, Val Acc: 90.93%
Epoch 7/10: Train Loss: 0.2596, Train Acc: 92.74%, Val Loss: 0.3097, Val Acc: 91.63%
Epoch 8/10: Train Loss: 0.2567, Train Acc: 92.92%, Val Loss: 0.3033, Val Acc: 91.71%
Epoch 9/10: Train Loss: 0.2547, Train Acc: 92.88%, Val Loss: 0.3052, Val Acc: 91.90%
Epoch 10/10: Train Loss: 0.2535, Train Acc: 92.95%, Val Loss: 0.3179, Val Acc: 91.64%
2. 适度拟合模型表现

- 训练损失和验证损失都稳步下降,且数值较低。
- 训练准确率和验证准确率都较高,最终约在97%左右,且两者数值接近。
- 训练曲线和验证曲线趋势一致,没有出现明显分离,说明模型泛化能力良好。
=== 适度拟合模型训练 ===
Epoch 1/10: Train Loss: 0.3707, Train Acc: 88.68%, Val Loss: 0.1729, Val Acc: 94.56%
Epoch 2/10: Train Loss: 0.1815, Train Acc: 94.52%, Val Loss: 0.1418, Val Acc: 95.90%
Epoch 3/10: Train Loss: 0.1438, Train Acc: 95.67%, Val Loss: 0.1169, Val Acc: 96.52%
Epoch 4/10: Train Loss: 0.1199, Train Acc: 96.37%, Val Loss: 0.1118, Val Acc: 96.72%
Epoch 5/10: Train Loss: 0.1082, Train Acc: 96.74%, Val Loss: 0.1033, Val Acc: 96.88%
Epoch 6/10: Train Loss: 0.0955, Train Acc: 97.07%, Val Loss: 0.0961, Val Acc: 97.36%
Epoch 7/10: Train Loss: 0.0868, Train Acc: 97.34%, Val Loss: 0.0965, Val Acc: 97.17%
Epoch 8/10: Train Loss: 0.0846, Train Acc: 97.34%, Val Loss: 0.0934, Val Acc: 97.39%
Epoch 9/10: Train Loss: 0.0778, Train Acc: 97.49%, Val Loss: 0.0924, Val Acc: 97.33%
Epoch 10/10: Train Loss: 0.0720, Train Acc: 97.76%, Val Loss: 0.0926, Val Acc: 97.30%
3. 过拟合模型表现

- 训练损失持续快速下降,但验证损失在后期出现波动甚至上升的趋势(如Epoch 8)。
- 训练准确率快速攀升并接近100%,而验证准确率在达到约97%后增长停滞。
- 训练曲线和验证曲线出现明显分离,训练集上的性能远优于验证集,这是过拟合的典型标志。
=== 过拟合模型训练 ===
Epoch 1/10: Train Loss: 0.2800, Train Acc: 91.34%, Val Loss: 0.1598, Val Acc: 95.17%
Epoch 2/10: Train Loss: 0.1100, Train Acc: 96.62%, Val Loss: 0.1096, Val Acc: 96.82%
Epoch 3/10: Train Loss: 0.0771, Train Acc: 97.59%, Val Loss: 0.1037, Val Acc: 96.99%
Epoch 4/10: Train Loss: 0.0611, Train Acc: 98.05%, Val Loss: 0.1061, Val Acc: 96.98%
Epoch 5/10: Train Loss: 0.0471, Train Acc: 98.57%, Val Loss: 0.0993, Val Acc: 97.22%
Epoch 6/10: Train Loss: 0.0417, Train Acc: 98.73%, Val Loss: 0.1024, Val Acc: 97.42%
Epoch 7/10: Train Loss: 0.0369, Train Acc: 98.86%, Val Loss: 0.0988, Val Acc: 97.62%
Epoch 8/10: Train Loss: 0.0294, Train Acc: 99.11%, Val Loss: 0.1154, Val Acc: 97.08%
Epoch 9/10: Train Loss: 0.0318, Train Acc: 99.05%, Val Loss: 0.0862, Val Acc: 97.84%
Epoch 10/10: Train Loss: 0.0244, Train Acc: 99.20%, Val Loss: 0.1097, Val Acc: 97.62%
从预测结果图可以直观看出:
- 欠拟合模型:容易将形状相似的数字混淆(例如某些“4”和“9”)。
- 适度拟合模型:对大多数数字的预测都准确。
- 过拟合模型:虽然在训练集上表现完美,但对测试集中的某些样本可能表现出“过度自信”或对细微噪声敏感。
五、实战策略:构建“三角”平衡术
1. 解决欠拟合的策略
| 策略 |
具体方法 |
适用场景 |
| 增加模型复杂度 |
添加更多网络层、增加神经元/滤波器数量 |
模型结构明显过于简单的任务 |
| 减少正则化 |
降低Dropout比率、减小L1/L2正则化的系数 |
因正则化过度导致模型能力被抑制 |
| 增加训练轮次 |
延长训练时间,运行更多Epoch |
模型尚未收敛,训练明显不足 |
| 特征工程 |
构造更有意义的特征、使用特征交叉 |
原始特征不足以描述问题 |
2. 解决过拟合的策略
| 策略 |
具体方法 |
适用场景 |
| 数据增强 |
对图像进行旋转、裁剪、翻转、颜色抖动等 |
图像分类、目标检测等视觉任务 |
| 正则化 |
在损失函数中添加L1或L2范数惩罚项 |
模型参数过多,需要约束 |
| Dropout |
在前向传播中随机将一部分神经元的输出置零 |
全连接层或卷积层过多的大型网络 |
| 早停 |
监控验证集性能,当性能不再提升时停止训练 |
训练时间过长,明显开始过拟合 |
| 简化模型 |
减少网络层数或每层的单元数 |
模型结构冗余,远超任务需求 |
| 获取更多数据 |
收集或生成更多训练数据 |
数据量是瓶颈的根本原因 |
3. 模型选择的最佳实践
3.1. 使用K折交叉验证
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5, shuffle=True)
for fold, (train_idx, val_idx) in enumerate(kfold.split(dataset)):
# 根据索引划分训练集和验证集
# 训练和验证模型
3.2. 绘制与分析学习曲线
通过绘制模型在训练集和验证集上的损失/准确率随训练轮次(Epoch)或训练样本数量变化的曲线,可以直观判断模型处于欠拟合、适度拟合还是过拟合状态。
3.3. 系统化超参数搜索
- 网格搜索:在指定的超参数网格中穷举所有组合。
- 随机搜索:从指定的分布中随机采样超参数组合,效率通常更高。
- 贝叶斯优化:基于之前的评估结果,智能地选择下一个最有希望的超参数组合进行尝试,适用于评估成本高昂的场景。
六、总结:寻找复杂性与简单性的平衡点
模型选择、欠拟合和过拟合构成了模型训练与评估的“铁三角”。它们之间相互关联、相互制约:
- 欠拟合是信号,提示我们模型可能“能力不足”,需要增加其复杂度或优化学习过程。
- 过拟合是警报,警告我们模型可能“聪明反被聪明误”,变得过于复杂和敏感,需要引入正则化、简化结构或补充数据。
- 模型选择则是方法论,是我们寻找欠拟合与过拟合之间那个最佳平衡点的系统性过程。
在实际的深度学习项目中,不存在一个“通用最优”的模型。成功的秘诀在于为你的特定任务和特定数据,找到那个复杂度与泛化能力达成最佳平衡的“搭档”。掌握识别欠拟合与过拟合的能力,并熟练运用相应的解决策略与模型选择技术,是你构建出强大、稳健的深度学习模型的核心技能。
最终,这不仅是技术,也是一门艺术——一门在模型的复杂性与简单性之间,进行精妙权衡的艺术。如果你在实践中遇到了具体的拟合问题,欢迎来云栈社区与更多开发者交流探讨。
 发表于 2026-1-25 05:02:50
|
查看: 161|
回复: 0
发表于 2026-1-25 05:02:50
|
查看: 161|
回复: 0
