1. 内存函数概述与基础概念
1.1 内存函数在C语言中的地位
在C语言体系中,直接操作内存的能力是其强大与灵活的关键所在,这也是它常被称为“系统编程语言”的原因。内存函数正是这一能力的核心体现,它们构成了底层系统开发的基石,同时也是程序稳定性和性能的决定性因素。
// 核心内存函数族
void *memcpy(void *dest, const void *src, size_t n);
void *memmove(void *dest, const void *src, size_t n);
void *memset(void *s, int c, size_t n);
int memcmp(const void *s1, const void *s2, size_t n);
void *memchr(const void *s, int c, size_t n);
1.2 基础内存模型理解
要熟练运用内存函数,首先需要建立清晰的内存模型概念。一个生活化的比喻可以帮助我们理解:
图书馆比喻:将计算机内存想象成一个巨大的图书馆
- 内存地址 = 书架编号 + 书籍位置
- 内存内容 = 书籍中的文字
- 内存函数 = 图书馆管理员的工作
- 数据类型 = 不同语言的书籍(但管理员不关心内容)

2. memcpy函数深度剖析
2.1 memcpy的工作原理
memcpy函数的核心任务是实现内存块的快速、无重叠复制。其工作原理可以用“流水线搬运”来理解:它不关心数据的具体含义,只负责将源地址开始的连续字节搬运到目标地址,这个过程在底层系统编程中至关重要。
核心实现机制:
void *memcpy_optimized(void *dest, const void *src, size_t n) {
if (dest == NULL || src == NULL || n == 0)
return dest;
// 类型转换以便字节操作
unsigned char *d = (unsigned char *)dest;
const unsigned char *s = (const unsigned char *)src;
// 检查对齐情况并处理前导不对齐字节
size_t alignment = ((uintptr_t)d | (uintptr_t)s) & (sizeof(uintptr_t)-1);
// 逐字节复制前导不对齐部分
while (alignment-- && n) {
*d++ = *s++;
n--;
}
// 使用字长进行批量复制(现代CPU优化)
uintptr_t *d_word = (uintptr_t *)d;
const uintptr_t *s_word = (const uintptr_t *)s;
while (n >= sizeof(uintptr_t)) {
*d_word++ = *s_word++;
n -= sizeof(uintptr_t);
}
// 处理剩余字节
d = (unsigned char *)d_word;
s = (const unsigned char *)s_word;
while (n--) {
*d++ = *s++;
}
return dest;
}
2.2 memcpy的核心数据结构和内存布局
2.3 memcpy的性能优化策略
| 优化策略 |
实现方式 |
性能提升 |
适用场景 |
| 字节复制 |
逐字节操作 |
基准 |
小数据量或不对齐 |
| 字长复制 |
按CPU字长复制 |
2-4倍 |
对齐的大数据量 |
| 向量化 |
SIMD指令集 |
4-16倍 |
现代CPU大数据量 |
| 预取优化 |
硬件预取 |
1.5-2倍 |
连续内存访问 |
3. memmove函数的精妙设计
3.1 内存重叠问题与解决方案
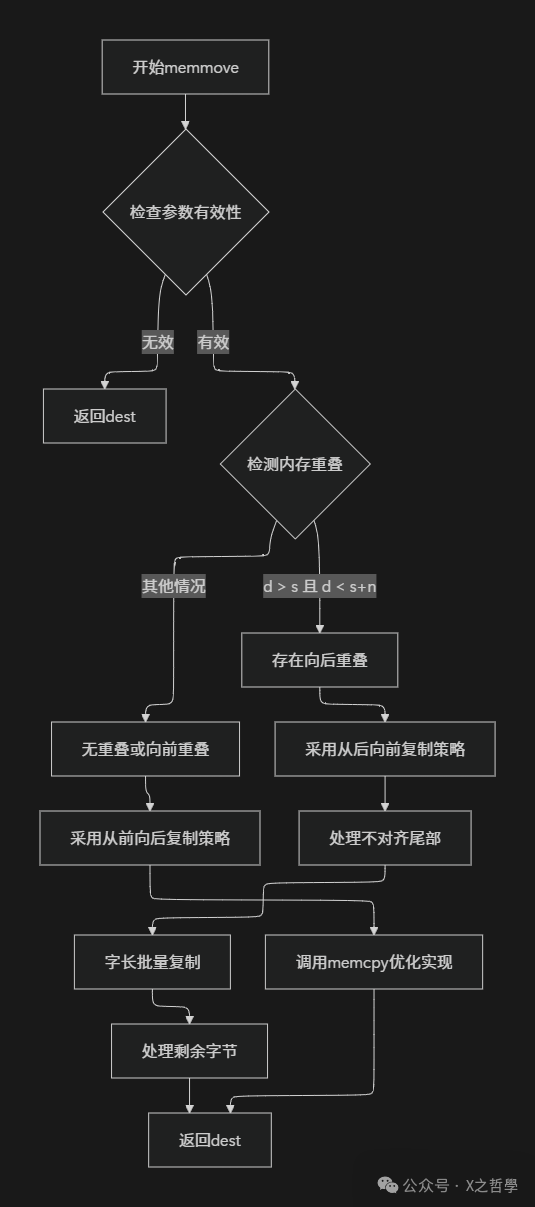
memmove与memcpy的关键区别在于其能安全处理内存重叠区域。这类似于搬家时遇到家具摆放位置重叠的情况:需要先判断方向,决定是从头开始搬还是从尾开始搬,以避免覆盖尚未搬动的物品。
void *memmove_impl(void *dest, const void *src, size_t n) {
if (dest == NULL || src == NULL || n == 0)
return dest;
unsigned char *d = (unsigned char *)dest;
const unsigned char *s = (const unsigned char *)src;
// 检测内存重叠并决定复制方向
if (d > s && d < s + n) {
// 存在重叠且目标在源之后 - 从后向前复制
d += n;
s += n;
// 处理后部不对齐字节
while (n && ((uintptr_t)d & (sizeof(uintptr_t)-1))) {
*--d = *--s;
n--;
}
// 字长复制
uintptr_t *d_word = (uintptr_t *)d;
const uintptr_t *s_word = (const uintptr_t *)s;
while (n >= sizeof(uintptr_t)) {
*--d_word = *--s_word;
n -= sizeof(uintptr_t);
}
// 处理剩余字节
d = (unsigned char *)d_word;
s = (const unsigned char *)s_word;
while (n--) {
*--d = *--s;
}
} else {
// 无重叠或目标在源之前 - 从前向后复制(同memcpy)
memcpy_optimized(dest, src, n);
}
return dest;
}
3.2 内存重叠检测算法
4. memset函数机制解析
4.1 memset的底层实现
memset函数用于将一块内存区域快速填充为指定的字节值,在初始化数据结构或清空缓冲区时极为高效。
void *memset_optimized(void *s, int c, size_t n) {
if (s == NULL || n == 0)
return s;
unsigned char *p = (unsigned char *)s;
unsigned char byte_val = (unsigned char)c;
// 构建字长模式的值
uintptr_t word_val;
unsigned char *byte_ptr = (unsigned char *)&word_val;
for (size_t i = 0; i < sizeof(uintptr_t); i++) {
byte_ptr[i] = byte_val;
}
// 处理前导不对齐字节
while (n && ((uintptr_t)p & (sizeof(uintptr_t)-1))) {
*p++ = byte_val;
n--;
}
// 字长设置
uintptr_t *word_ptr = (uintptr_t *)p;
while (n >= sizeof(uintptr_t)) {
*word_ptr++ = word_val;
n -= sizeof(uintptr_t);
}
// 处理剩余字节
p = (unsigned char *)word_ptr;
while (n--) {
*p++ = byte_val;
}
return s;
}
4.2 memset的性能模式分析
| 填充模式 |
实现复杂度 |
性能特点 |
缓存影响 |
| 字节填充 |
O(n) |
稳定但较慢 |
缓存行逐字节填充 |
| 字长填充 |
O(n/字长) |
快速高效 |
充分利用缓存行 |
| 向量填充 |
O(n/向量长) |
极速但需硬件支持 |
最大缓存利用率 |
5. memcmp与memchr函数分析
5.1 内存比较算法
memcmp实现内存区域的逐字节比较,是字符串比较等操作的底层基础。它不关心数据是否以空字符结尾,只比较指定长度的内存内容。
int memcmp_optimized(const void *s1, const void *s2, size_t n) {
if (s1 == NULL || s2 == NULL)
return s1 == s2 ? 0 : (s1 < s2 ? -1 : 1);
const unsigned char *p1 = (const unsigned char *)s1;
const unsigned char *p2 = (const unsigned char *)s2;
// 字长比较优化
if ((((uintptr_t)p1 | (uintptr_t)p2) & (sizeof(uintptr_t)-1)) == 0) {
const uintptr_t *w1 = (const uintptr_t *)p1;
const uintptr_t *w2 = (const uintptr_t *)p2;
while (n >= sizeof(uintptr_t)) {
if (*w1 != *w2) {
break;
}
w1++;
w2++;
n -= sizeof(uintptr_t);
}
p1 = (const unsigned char *)w1;
p2 = (const unsigned char *)w2;
}
// 逐字节比较剩余部分
while (n--) {
if (*p1 != *p2) {
return *p1 - *p2;
}
p1++;
p2++;
}
return 0;
}
5.2 内存搜索算法
memchr用于在内存块中线性搜索特定字节的出现位置。优化的实现会利用位运算技巧在字长级别进行快速匹配检测。
void *memchr_optimized(const void *s, int c, size_t n) {
if (s == NULL || n == 0)
return NULL;
const unsigned char *p = (const unsigned char *)s;
unsigned char target = (unsigned char)c;
// 检查前导不对齐字节
while (n && ((uintptr_t)p & (sizeof(uintptr_t)-1))) {
if (*p == target)
return (void *)p;
p++;
n--;
}
if (n >= sizeof(uintptr_t)) {
// 构建字长模式的目标值检测掩码
const uintptr_t magic_bits = 0x0101010101010101ULL;
const uintptr_t carry_mask = 0x8080808080808080ULL;
const uintptr_t target_word = target * magic_bits;
const uintptr_t *word_ptr = (const uintptr_t *)p;
while (n >= sizeof(uintptr_t)) {
uintptr_t word = *word_ptr;
// 使用位运算技巧快速检测字节匹配
uintptr_t diff = word ^ target_word;
uintptr_t temp = (diff - magic_bits) & ~diff & carry_mask;
if (temp != 0) {
// 找到匹配,定位具体位置
p = (const unsigned char *)word_ptr;
for (size_t i = 0; i < sizeof(uintptr_t); i++) {
if (p[i] == target)
return (void *)(p + i);
}
}
word_ptr++;
n -= sizeof(uintptr_t);
}
p = (const unsigned char *)word_ptr;
}
// 处理剩余字节
while (n--) {
if (*p == target)
return (void *)p;
p++;
}
return NULL;
}
6. 完整实现示例与测试框架
6.1 内存函数库完整实现
#include <stddef.h>
#include <stdint.h>
#include <stdbool.h>
// 内存函数库头文件
typedef struct {
void *(*memcpy)(void *dest, const void *src, size_t n);
void *(*memmove)(void *dest, const void *src, size_t n);
void *(*memset)(void *s, int c, size_t n);
int (*memcmp)(const void *s1, const void *s2, size_t n);
void *(*memchr)(const void *s, int c, size_t n);
} memory_ops_t;
// 优化的memcpy实现
void *memcpy_opt(void *dest, const void *src, size_t n) {
// 如前文所述的优化实现
// 此处为简洁省略具体代码
}
// 完整的内存函数库实例
const memory_ops_t mem_ops = {
.memcpy = memcpy_opt,
.memmove = memmove_impl,
.memset = memset_optimized,
.memcmp = memcmp_optimized,
.memchr = memchr_optimized
};
6.2 测试验证框架
#include <stdio.h>
#include <assert.h>
void test_memory_functions() {
printf("=== 内存函数测试框架 ===\n");
// 测试memcpy
char src[] = "Hello, Memory World!";
char dest[50];
mem_ops.memcpy(dest, src, sizeof(src));
assert(mem_ops.memcmp(dest, src, sizeof(src)) == 0);
printf("✓ memcpy测试通过\n");
// 测试memmove重叠复制
char buffer[] = "ABCDEFGHIJ";
mem_ops.memmove(buffer + 2, buffer, 5);
assert(mem_ops.memcmp(buffer, "ABABCDEFGH", 10) == 0);
printf("✓ memmove测试通过\n");
// 测试memset
char set_buf[10];
mem_ops.memset(set_buf, 0xAA, sizeof(set_buf));
for (size_t i = 0; i < sizeof(set_buf); i++) {
assert(set_buf[i] == (char)0xAA);
}
printf("✓ memset测试通过\n");
// 测试memchr
const char *search_str = "Find the letter X here";
void *found = mem_ops.memchr(search_str, 'X', strlen(search_str));
assert(found != NULL && *(char*)found == 'X');
printf("✓ memchr测试通过\n");
printf("所有测试通过!\n");
}
7. 性能分析与优化策略
7.1 内存函数性能对比表
| 函数 |
时间复杂度 |
空间复杂度 |
最佳数据大小 |
最差场景 |
| memcpy |
O(n) |
O(1) |
4KB-1MB |
小数据+不对齐 |
| memmove |
O(n) |
O(1) |
4KB-1MB |
完全重叠复制 |
| memset |
O(n) |
O(1) |
1KB-256KB |
单个字节设置 |
| memcmp |
O(n) |
O(1) |
1KB-64KB |
首字节不同 |
| memchr |
O(n) |
O(1) |
256B-16KB |
目标在末尾 |
7.2 CPU架构对内存函数的影响

8. 调试工具与诊断技术
8.1 常用调试命令工具集
# 内存调试工具集合
$ valgrind --tool=memcheck ./program # 内存错误检测
$ gcc -fsanitize=address -g program.c # 地址消毒剂
$ ltrace -e memcpy,memmove ./program # 库函数调用跟踪
$ perf stat -e cache-misses ./program # 缓存性能分析
$ size --format=sysv executable # 内存段分析
8.2 高级调试技巧
// 内存调试包装器
#ifdef DEBUG_MEMORY
#define MEMCPY(dest, src, n) do { \
printf("memcpy: %p -> %p, size: %zu\n", src, dest, n); \
debug_memcpy(dest, src, n); \
} while(0)
void debug_memcpy(void *dest, const void *src, size_t n) {
// 添加边界检查
assert(ptr_in_valid_range(dest, n));
assert(ptr_in_valid_range(src, n));
// 检查重叠
if (is_overlapping(dest, src, n)) {
fprintf(stderr, "警告: memcpy检测到内存重叠\n");
}
// 调用实际实现
memcpy_opt(dest, src, n);
}
#endif
9. 实际应用场景分析
9.1 数据结构初始化模式
// 安全数据结构初始化模板
typedef struct {
int id;
char name[64];
double values[100];
size_t count;
} data_container_t;
void init_data_container(data_container_t *container) {
if (container == NULL) return;
// 使用memset清零整个结构
mem_ops.memset(container, 0, sizeof(data_container_t));
// 设置默认值
container->id = -1;
mem_ops.memcpy(container->name, "Default", 8);
container->count = 0;
}
// 高效数组复制
void copy_double_array(double *dest, const double *src, size_t count) {
// 直接内存复制,避免元素级循环
mem_ops.memcpy(dest, src, count * sizeof(double));
}
9.2 内存池管理应用
// 简单内存池实现
typedef struct {
void *base_ptr;
size_t total_size;
size_t used_size;
uint8_t *allocation_map;
} memory_pool_t;
void *pool_alloc(memory_pool_t *pool, size_t size) {
if (pool == NULL || size == 0) return NULL;
// 对齐处理
size_t aligned_size = (size + 7) & ~7;
if (pool->used_size + aligned_size > pool->total_size) {
return NULL; // 内存不足
}
void *alloc_ptr = (uint8_t *)pool->base_ptr + pool->used_size;
// 清零分配的内存
mem_ops.memset(alloc_ptr, 0, aligned_size);
// 更新使用情况
pool->used_size += aligned_size;
return alloc_ptr;
}
10. 总结与核心要点
经过对C语言内存函数的深入分析,我们可以得出以下核心结论:
10.1 关键技术洞察
- 内存对齐是性能关键:正确的内存对齐可以带来数倍的性能提升
- 重叠处理决定正确性:memmove的智能方向选择确保了重叠内存操作的正确性
- 批量操作优于逐字节:字长和向量化操作是现代CPU性能的基石
- 缓存友好性至关重要:顺序内存访问模式能充分利用CPU缓存层次结构
10.2 各函数特性对比总结
| 特性维度 |
memcpy |
memmove |
memset |
memcmp |
memchr |
| 主要用途 |
内存复制 |
安全复制 |
内存设置 |
内存比较 |
字节搜索 |
| 重叠处理 |
不保证 |
完全处理 |
不适用 |
不适用 |
不适用 |
| 性能关键 |
对齐复制 |
方向判断 |
模式填充 |
早期终止 |
模式检测 |
| 使用频率 |
极高 |
高 |
极高 |
中 |
低 |
正确理解和使用这些内存函数,不仅能提升程序的稳定性和性能,也是深入系统调试和性能分析的基础。掌握其底层原理,有助于开发者在面对复杂内存问题时,能够做出准确的诊断与高效的优化。
 发表于 2025-12-2 02:18:41
|
查看: 221|
回复: 0
发表于 2025-12-2 02:18:41
|
查看: 221|
回复: 0
