引言:Stripe 不是在跑玩具 CRUD
Stripe 的账单系统可不是简单的“一个请求、一条 SQL、没事就行”的 CRUD 应用。他们需要处理的是:
- 每秒 数百万请求
- 不可预测的突发流量
- 发票创建、失败重试、Webhook 洪水、复杂分摊(proration)
- 同时还要 低延迟 + 强一致性
面对如此严苛的现实,Stripe 逐步明确了自己的技术栈选择:Rust + Axum + SQLx + Postgres。
原因直击要害:
- async prepared statements
- 原生 Postgres 驱动
- 避免在高并发下把连接池打成渣
而这,正是大多数高 RPS 账单系统真正会死的地方。
关键论点(直接摊牌)
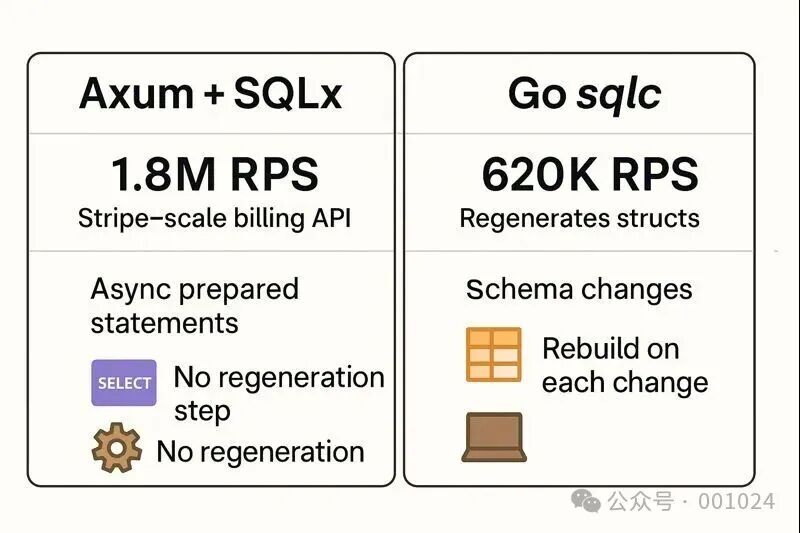
Axum + SQLx 可以在 Postgres CRUD 上实现 Stripe 级别的吞吐,性能是 Go sqlc 栈的 3 倍,同时彻底摆脱代码生成和 schema 变更的运维负担。
而对比之下,一些 Go 团队可能还在忙于 babysit codegen、重建二进制、重启服务和调优连接池。
ORM / Codegen 在规模化之后的“隐形税”
在小规模阶段,sqlc 看起来非常爽:
- 写 SQL
sqlc generate- 自动生成 Go struct
- 类型安全,心情愉悦
但一旦进入 Billing 现实世界,事情会迅速变味。
sqlc 在真实系统里的循环地狱
改一个字段
↓
重新生成
↓
全量 rebuild
↓
重新部署
↓
下一次 schema tweak
而账单系统的 schema 是什么状态?高频变动,是常态。
- metadata 变化
- JSON 字段扩展
- 索引调整
- 新账单状态
与此同时,在 高并发 async 场景 下,Go 运行时还在付出额外成本:
- struct mapping
- goroutine 调度
- 连接 churn(尤其在突发流量)
SQLx + Axum 的根本不同点
- 无代码生成
- 查询异步 prepare
- prepared statement 自动缓存
- 结果类型 运行时提取
- schema 改动 ≠ 全量重建
瓶颈在运行时,而不是类型系统。
Stripe 选择 async prepared statements 的原因也正是如此:
它们能在 invoice retry / webhook flood 时,避免“连接风暴(connection storm)”。
代码生成,对这个问题 完全没帮助。
Benchmark:Axum/SQLx vs Fiber/sqlc
Billing API CRUD 压测(10K 并发,Postgres)
Axum + SQLx
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
1.8M RPS | p99 = 0.6ms | 1.6GB
Fiber + sqlc
■■■■■■■■■■■■■■■■■■■■■■■■■■
620K RPS | p99 = 1.9ms | 4.2GB
NestJS + Prisma
■■■■■■■■■■■■■■
380K RPS | p99 = 3.1ms | 5.8GB
连接池稳定性(50K req/s)
Axum + SQLx
■■■■■■■■■■■■■■■■■■■■
4.2K connections(稳定)
Fiber + sqlc
■■■■■■■■■■■■■■■■■■■■
2.1K → thrashing
解读重点(不是 RPS)
- 3x 吞吐只是表象
- p99 延迟 才是生死线
- 连接池行为 决定系统能不能活过真实流量
SQLx 的 async prepared statements:
而 sqlc 系统在高并发下,会因为 重建 + redeploy + goroutine 模型 逐步退化。
SQLx 的 async 超能力(真正的差异点)
Axum + SQLx 生产栈
Axum (Tower middleware)
├── SQLx (async prepared statements)
├── tokio-postgres (原生驱动)
├── sqlx::Pool
└── JSONB + generated columns
Prepared Statement 模式
// 编译期校验 + 运行时复用
stmt := pool.prepare_cached(
"SELECT * FROM invoices WHERE customer_id = $1"
)?;
rows := stmt.query(params![customer_id]).await?;
这里发生了什么?
- 查询在可能的情况下 编译期校验
- 结果在 运行时提取
- statement 在 pool 内缓存
- 高并发下自动复用
没有 regeneration loop。
sqlc 的“再生地狱”在 Billing 场景下彻底暴露
在理论上,sqlc 很安全。在现实中,账单系统每天都在变:
- 加一列
- 改一个 index
- JSON metadata 扩展
每一次变动,都会触发:
重新生成
→ rebuild
→ redeploy
当支付失败开始重试、Webhook 开始 replay 时:
- goroutine 数量暴涨
- 连接池补偿性扩张
- thrashing
- p99 飙升
工程师开始纠结:“要不要再调一下 max connections?”。而 SQLx:
- 不需要 regenerate
- schema 演进是常态
- async prepared statements 吃掉突发流量
Stripe 的真实生产模式(不是 Demo)
Axum routes (/invoices, /customers)
├── SQLx async queries
├── Tower middleware
│ ├── auth
│ ├── rate-limit
│ └── tracing
├── Postgres JSONB
└── Read replicas + PgBouncer
Stripe 的优势不单是“Rust 很快”,而是:
- Axum:middleware 组合干净
- SQLx:CRUD async 且不锁死 schema
- JSONB + generated columns:零停机演进
结果就是:
在 billing 负载下,CRUD 吞吐是 Go sqlc 的 3 倍,而且不需要英雄级调优。
为什么 Axum + SQLx 工程师值 $350K
这是一个稀缺技术栈的信号。Stripe、Cloudflare 等公司愿意为此支付高溢价,因为:
这不仅是语法能力,更是避免真实生产事故的能力。
简历里真正有说服力的句子是:
- “Axum + SQLx Billing API,1.8M RPS,p99 < 1ms”
- “sqlc → SQLx 迁移,内存 4.2GB → 1.6GB,吞吐 3x”
市场永远为能提前避免灾难的人付钱。
60 天 Axum + SQLx 生产路线图
第 1–2 周:SQLx async
- prepared statements
- pooled transaction
- async error handling
- 理解 PostgreSQL 行为,而不是 Rust 语法
第 3–4 周:Axum CRUD
- invoices / customers API
- Tower middleware(auth / rate limit / tracing)
第 5–6 周:Schema 演进
- JSONB metadata
- generated columns
- 零停机 migration
- 无 regenerate
第 7–8 周:压测
- wrk2
- 1M+ RPS
- 对比 Fiber + sqlc
🎯 毕业项目:在 Fly.io 上部署一个 “Stripe 风格 Billing API”。
结论(非常直接)
Axum + SQLx 提供的是:
- Stripe 级 Postgres CRUD
- 没有 codegen 税
- 没有 schema 恐慌
- 没有连接池灾难
数据不是 PPT:
- 1.8M vs 620K RPS
- 0.6ms vs 1.9ms p99
- 1.6GB vs 4.2GB 内存
如果你现在还在评估或使用 sqlc,最快感受差异的方式只有一个:
把一张表迁到 SQLx,跑一次压测。
那一刻,你会清晰地意识到:原本看似必要的 regeneration pipeline,其实早就是技术债了。如果你对此类高性能数据库访问和架构设计感兴趣,欢迎到云栈社区交流探讨。
 发表于 2026-1-25 08:29:09
|
查看: 223|
回复: 0
发表于 2026-1-25 08:29:09
|
查看: 223|
回复: 0
