如今,“大模型”一词几乎无处不在,从媒体报道到企业战略,再到资本流向,仿佛只要带上“大”字,就自然代表着先进与未来。
但如果我们稍作停顿,仔细看看它的英文全称 Large Language Model (缩写为 LLM),一个更准确、也更本质的译名便浮现出来:大语言模型。
请注意中间那个词:Language(语言)。我们常常被“大”所吸引——千亿参数、庞大算力集群、惊人的能耗……这些固然构成了模型的“体格”,但真正决定其智能涌现、推理能力与泛化潜力的,恰恰藏在“语言”这两个字里。
语言为什么是核心?
你可能会好奇,人工智能领域探索多年,为什么偏偏是围绕“语言”的技术带来了这次颠覆性的爆发?

首先明确语言的功能。我们都知道,语言是人类交流思想、表达情感最自然、最直接的工具。但除此之外,语言还有一个至关重要的功能:人类历史上绝大部分知识,都是以语言文字的形式被记载和流传下来的。毫不夸张地说,语言就是人类文明的“硬盘”。
不妨想象一下这样一个工具:它能够系统地阅读、分析并有效运用人类有史以来积累的所有文字——从古老的典籍到最新的科研论文,从新闻报道到复杂的代码文档。如果真有这样的模型,即便它无法“真正理解”人类的主观意识,也已经在很大程度上内化了文明沉淀下来的知识结构和经验模式。
这并非一个全新的梦想。早在科幻作品中,我们就见过类似的场景:一个机器人“诞生”之初,便如饥似渴地翻阅书籍,瞬间掌握人类千年的智慧。过去几十年,人工智能研究者孜孜以求的,正是这样一个“知识吸收者”——一个能够从语言中自主学习、举一反三的通用智能基座。
而今天,大语言模型正让这一愿景趋近现实:它虽非实体“翻书”,却在海量训练数据中“阅读”了几乎整个互联网的公开文本;它虽不具备意识,却通过复杂的统计与模式识别,展现出对知识的组织、关联与调用能力——仿佛是整个文明史在数字世界中的一次深刻回响。
那么,这一切是如何一步步发生的?我们需要从它的前身说起:语言模型(Language Model)。
“语言模型”——远不止是“文字接龙”
在人工智能领域,“语言模型”是一个拥有近七十年历史的概念。它的核心任务看似非常朴素:给定一段已有的文字,预测下一个最可能出现的词是什么。

这听起来很像我们熟悉的“文字接龙”游戏。但要真正理解它的深刻意义,我们需要把视角拉得更宏观一些。
想象一个孩子在学习说话。他并非被直接灌输语法规则,而是通过反复聆听大人的对话,逐渐发现一些模式:比如“妈妈”后面常常跟着“抱抱”;“天要下雨”之后可能会说“记得带伞”;“床前明月”后面,接“光”的可能性远大于“火锅”。这种从海量语言实例中自发归纳出统计模式的能力,就是语言模型最基础的雏形。
早期的语言模型(例如上世纪80年代的 n-gram 模型)就像一个“短视的接龙选手”:它只能看到当前词前面的几个词(N个)。例如,输入“今天天气真”,它会遍历语料库,统计发现“好”出现了1万次,“差”出现了200次,“蓝”出现了50次——于是它选择预测“好”。但它无法判断“今天天气真蓝”在特定语境下(比如高原地区)也可能是合理的,因为它严重缺乏对长上下文的综合理解能力。
而现代基于 Transformer 架构的语言模型,则更像一位“博闻强记的说书人”:它不只记忆零碎的片段,更能把握整段故事的脉络与逻辑。当它读到“诸葛亮站在城楼上,焚香抚琴”时,即使后文没有出现“空城计”这三个字,它也能推测出司马懿接下来大概率会“退兵”——因为它已经从《三国演义》原著、各类评书、甚至影视剧解说中,反复“学习”并内化了这个完整的逻辑链条。
换句话说,语言模型的本质,是在用数学和统计的方法,尝试重建一张覆盖了事实、逻辑、情感与文化惯例的庞大“常识地图”。它通过对人类海量语言数据的学习,逐步逼近我们如何使用语言来编码和描述整个世界。
从“语言模型”到“大语言模型”:量变如何引起质变?
那么问题来了:既然语言模型的概念和研究早已存在,为什么直到2020年前后(以 OpenAI 的 GPT-3 模型为标志性事件),我们才突然迎来了所谓的“大模型爆发”?
这里就涉及到一个关键转变:规模。答案藏在 LLM 的第一个 L——Large 之中,意味着模型的规模必须足够大。
我们可以通过模型参数规模变迁的三个关键阶段,来理解这场“量变引起质变”的技术革命:
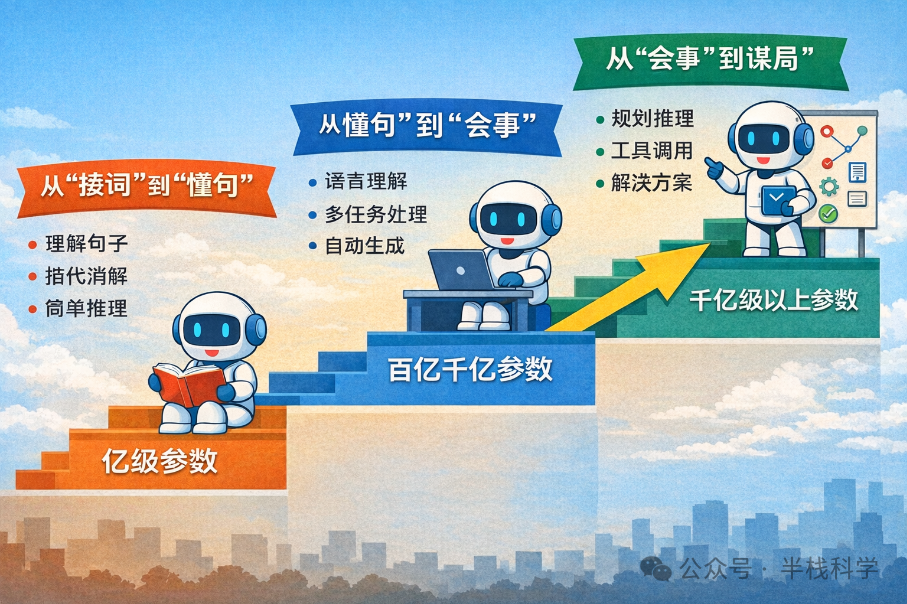
🔹 第一跃迁:从“接词”到“懂句”
早期的微型模型可能只会机械地续写(例如“今天天气真”→大概率接“好”)。而当参数规模达到亿级(例如2018年的 BERT),模型开始真正“读懂”句子:不仅能分析句法结构(理解“猫追老鼠”中谁在行动、谁是目标),还能处理复杂的指代消解(判断“张伟把书递给李娜,她笑了”中的“她”更可能指谁),甚至能完成简单的逻辑推理(如果A比B高,B比C高,那么A比C高吗?)。
🔹 第二跃迁:从“懂句”到“会事”
当模型规模膨胀到百亿至千亿级(例如2020年的 GPT-3),令人惊叹的现象出现了:模型不再需要为每个特定任务进行单独、复杂的训练。你只需用最自然的语言指令告诉它:“请将下面这段话翻译成法语”、“请总结这篇文章的三个核心要点”、“请模仿李白的风格创作一首关于AI的诗”——它就能尝试完成。这种“零样本/少样本学习”能力,标志着模型已经内化了任务的一般结构和解决模式,而不仅仅是记住了语言的表面形式。
🔹 第三跃迁:从“会事”到“谋局”
当模型参数迈向千亿级以上(例如后续更强大的模型),它们展现出更为惊人的能力:能够拆解极其复杂的开放式问题、进行分步规划求解、在执行中自我反思与纠错、甚至调用外部工具(如计算器、代码解释器、搜索引擎 API)。这时的模型,就像一个“善于拆解问题的智能助手”——你给出一个模糊的需求(例如“帮我策划一场碳中和主题的婚礼”),它能自主规划出步骤:预算制定→场地筛选与评估→交通方案设计→碳排放估算→供应商比选建议……
这绝非预设的程序流程,而是语言数据中隐含的思维与推理模式,在足够庞大的模型中被充分激活和重组的结果。
“大”之所以至关重要,不仅在于它让模型“记住更多事实”,更在于它驱动模型从表面的统计模仿,走向深层的结构化理解。就像一个人阅读:读完10本书,可能只会复述;读完1000本,就能进行比较和辨析;而读完十万本并深入思考其中的关联,最终便能形成自己独立的思想框架。大语言模型正是在对海量人类语言的“深度沉浸式”学习过程中,重构了知识之间那些隐性的、复杂的关联网络。
结论:回归“语言”的本质
当我们谈论“大模型”时,真正驱动其智能的,从来不只是堆叠的参数和消耗的算力——而是它对语言本身的深度建模与重建:从基础的语法、到丰富的语义、再到复杂的逻辑、叙事结构乃至文化背景。
参数可以不断堆叠,硬件可以持续迭代,但如果没有“语言”作为知识与思维的载体与桥梁,再庞大的模型也可能只是一台空转的引擎。
因此,它的准确中文名不应被简化为宽泛的“大模型”,而应始终强调其核心——大语言模型。
认清它的真实名字与本质,我们才能更清醒地看待这场技术变革:它并非凭空降临的“智能奇迹”,而是人类用语言写就的文明史诗,在数字世界中的一次深刻回响与技术性重建。在技术飞速发展的今天,理解其底层原理有助于我们在云栈社区这样的技术交流平台上进行更深入、更理性的探讨。

 发表于 2026-1-25 08:31:35
|
查看: 203|
回复: 0
发表于 2026-1-25 08:31:35
|
查看: 203|
回复: 0
