人类的智能行为天然融合了视觉、听觉、语言等多种感知方式,并能进行深度思考,在遇到难题时调用外部工具辅助完成任务。然而,当前主流的多模态大模型仍主要局限于图文或音文等双模态交互,缺乏作为通用AI助手所需的全模态认知、长程推理与工具调用能力。
为填补这一空白,来自中国人民大学、小红书、东南大学、浙江大学和清华大学的研究团队联合推出了 OmniGAIA:一个专为评估原生全模态 AI 智能体而设计的高难度新基准。在此基础上,团队还提出了 OmniAtlas,一个具备主动感知能力、遵循工具集成推理范式的原生全模态基础智能体训练框架。

论文链接:https://arxiv.org/pdf/2602.22897
代码 & Demo:https://github.com/RUC-NLPIR/OmniGAIA
数据集 & 模型:https://huggingface.co/collections/RUC-NLPIR/omnigaia
-Leaderboard:https://huggingface.co/spaces/RUC-NLPIR/OmniGAIA-LeaderBoard
Demo
1. 图片 + 音频任务
题目: 图片中显示的事件与音频中描述的事件,时间上相隔多久?
2. 带音频的视频任务
题目: 视频中提到某部电影中的一座会动的桥,请调研这座桥的具体信息。
现有评测的局限性:为什么需要 OmniGAIA?
随着 Qwen3-Omni、Gemini-3 等全模态模型的涌现,模型已能在单一架构中统一处理文本、视觉与音频。但现有的评测基准大多聚焦于极短时长的音视频,题型也以感知型选择题为主。真实世界的任务往往更为复杂,例如:
视频中导游指着远处一座桥,提到它让他想起某部电影中的场景。请回答这座桥的名字,以及在 1979 年该电影开拍时,这座桥已建成多少年?
这类任务要求模型不仅具备感知能力,还需在长视频、长音频或多张图片中定位关键信息、主动通过搜索引擎验证事实,并进行多步推理与计算。现有基准无法评估这类能力,这正是 OmniGAIA 设计的初衷。

OmniGAIA:面向全模态智能体的高难度新基准
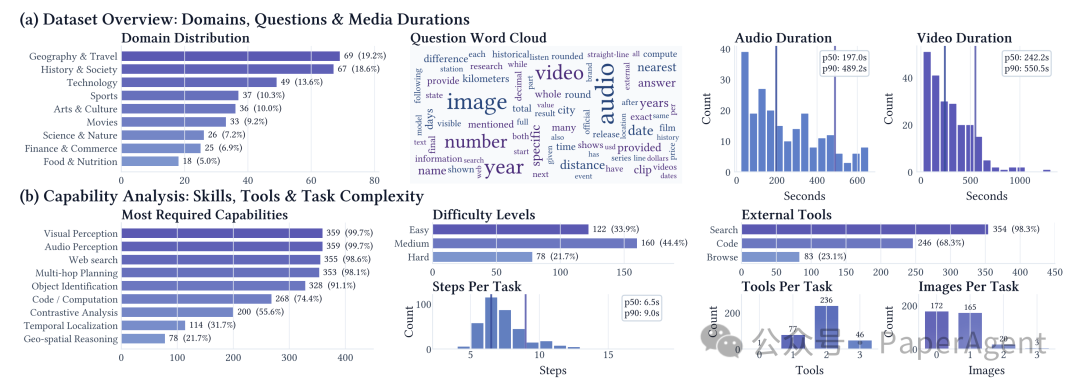
OmniGAIA 包含 360 个源自真实场景的高难度任务,覆盖地理、历史、科技、艺术、体育、金融等 9 大领域。输入形式包括时长可达数十分钟的“视频 + 音频”与“图像 + 音频”组合。任务设计强调多跳推理与多轮工具调用,要求模型输出唯一可验证的开放式答案。
构建方法:全模态事件图谱驱动
为确保任务逻辑严谨且具有挑战性,研究团队提出了一套系统化的构建流程:
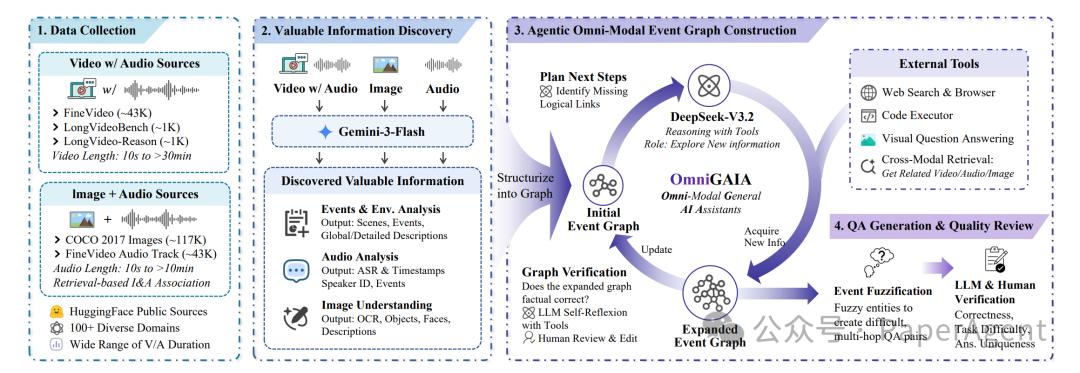
- 数据来源: 视频部分整合 FineVideo、LongVideoBench、LongVideo-Reason 等数据,图像 + 音频设定则结合 COCO 2017 与真实音频轨道,覆盖更复杂、更长上下文的真实场景。
- 信息挖掘: 团队使用 Gemini-3-Flash 对原始素材做细粒度解析。视频会切成不超过 60 秒的片段,音频侧补充时间戳 ASR、说话人分离和音频事件检测,图像侧则加入 OCR、物体/人物识别和整体场景概述。
- 事件图谱构建与扩展: 在这些中间信号之上,团队借助 DeepSeek-V3.2 构建“全模态事件图谱”,把跨模态实体、事件及其关系组织成图结构。随后再通过搜索、浏览、图像检索、视觉问答和代码执行等工具主动补充“下一跳证据”,把图谱从原始素材扩展到外部知识。
- 问答生成与审查: 论文采用“事件模糊化(event fuzzification)”策略,对推理链上的关键实体或属性进行遮蔽与抽象,把简单事实查询改造成需要跨模态关联和多跳推理的问题。最终样本会经过 LLM 初筛与人工复核,确保题目自然、答案正确且唯一。
OmniGAIA 具体的统计数据如下图所示:
OmniAtlas:原生全模态智能体基座模型
在严苛的测试下,早期的开源模型表现较差。为了提升开源全模态模型的 智能体 能力,团队不仅提出了基准,更给出了一套开源解法与完整的“训练秘籍”—— OmniAtlas,目标是让模型具备更强的自主规划、主动感知与工具使用能力。
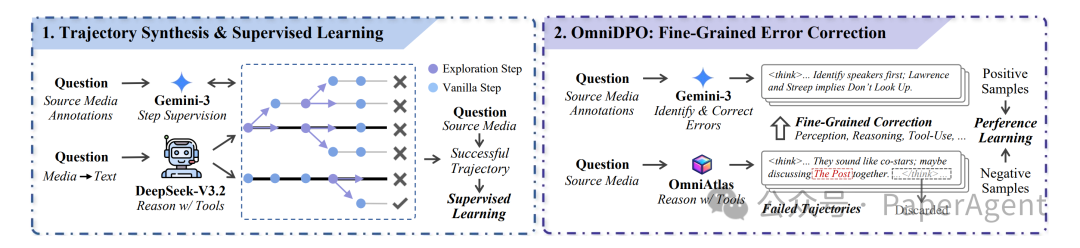
它遵循工具集成推理范式(Tool-Integrated Reasoning, TIR),将内部思考与外部工具调用交织在同一条轨迹中。围绕这一范式,OmniAtlas 包含三大核心能力:
1. 主动全模态感知
面对超长视频或高清大图,传统的全局降采样往往会丢失细节。OmniAtlas 赋予了模型“指哪看哪、听哪”的能力:当它怀疑关键信息只出现在某段音频、某几秒视频或图像局部区域时,可以通过内置工具(read_video / read_audio / read_image)只读取对应内容,在降低成本的同时保留关键细节。
2. 高质量轨迹合成与监督微调
团队提出了一套“轨迹合成 + 监督学习”的 训练框架。首先把原始多模态输入转换成高质量文本描述,再让强推理模型进行“后见之明引导的树探索”,在每一步采样多个候选“思考 + 动作”分支,并结合标准答案与验证器剪掉错误路径,只保留真正通向正确答案的成功轨迹。
在监督微调阶段,论文采用轨迹级的掩码监督:只对模型自己生成的“思考 token”和“动作 token”计算损失,而不强行拟合工具返回的观察内容,从而让模型重点学会“如何思考和决策”。
3. OmniDPO 细粒度纠错
全模态任务极易“一步错,步步错”。为此,团队提出了 OmniDPO:先让经过 SFT 的模型在训练集上自主探索,再让强模型结合标注答案定位失败轨迹中的“第一处错误点”,并生成修正后的正确前缀。这样得到的正负样本对更聚焦局部关键错误,能够更精准地纠正感知、检索、工具使用和推理中的偏差。
实验结果:性能对比与深层分析
1. 主实验结果:开源与闭源模型差距显著
在统一提供外部工具(搜索、浏览、代码执行)的设定下,评测结果显示:
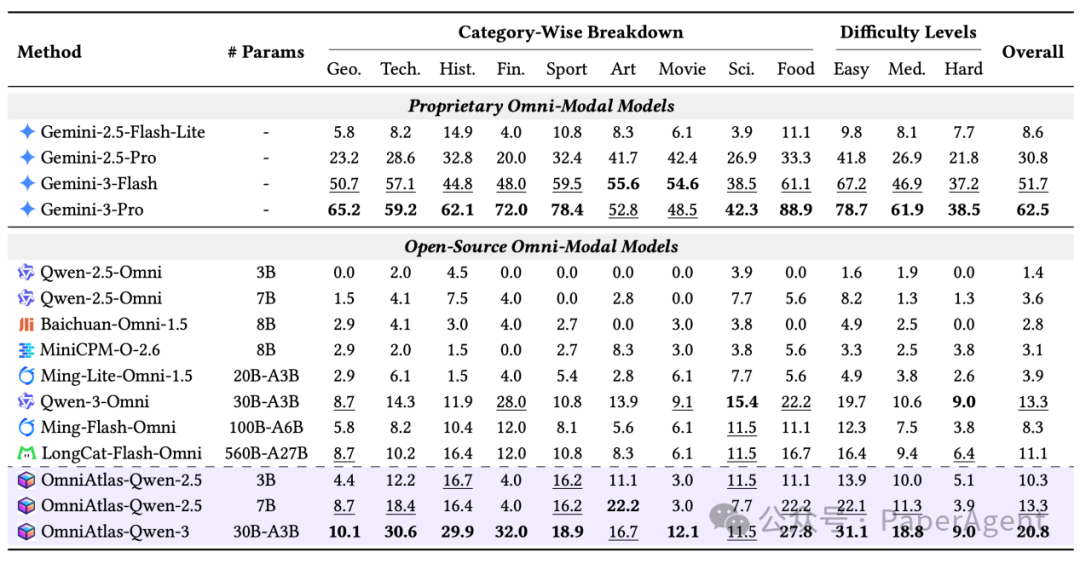
- 闭源模型 Gemini-3-Pro 以 62.5% 的 Pass@1 遥遥领先,展现出成熟的规划与验证能力。
- 最强开源基线 Qwen-3-Omni(30B)仅达 13.3%,差距约 4.7 倍。
- 模型规模并非决定性因素:560B 参数的 LongCat-Flash-Omni 得分(11.1%)反而不如 30B 的 Qwen-3-Omni(13.3%),说明工具调用策略与推理能力比单纯参数量更关键。
- OmniAtlas 提升显著:经 OmniAtlas 优化后的 Qwen-3-Omni 从 13.3% 提升至 20.8%(+7.5%);在 7B 小模型上,准确率从 3.6% 跃升至 13.3%,提升近 4 倍。
2. 细粒度错误分析:工具使用与推理是主要瓶颈
对失败轨迹的深入剖析显示:
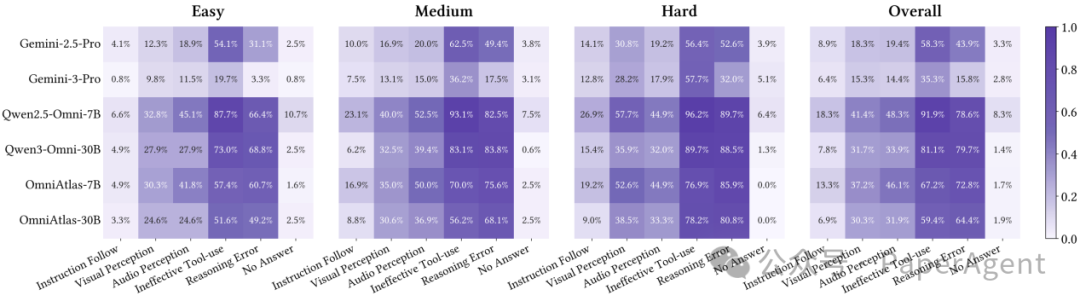
- 在困难任务中,开源模型的失败有 90% 以上可归因于工具使用不当(如未调用、调用错误方向或陷入无效循环),进而引发推理崩溃。
- Gemini-3-Pro 在工具使用与推理错误率上远低于开源模型(35.3% vs 81.1%;15.8% vs 79.7%),体现出更强的鲁棒性。
- OmniAtlas 显著降低了工具使用错误率(81.1% -> 59.4%)与推理错误率(79.7% -> 64.4%),但感知错误仍占约 30% - 50%,提示基础感知能力仍是未来提升重点。
3. 工具调用行为分析
分析不同模型的工具调用模式可以发现:
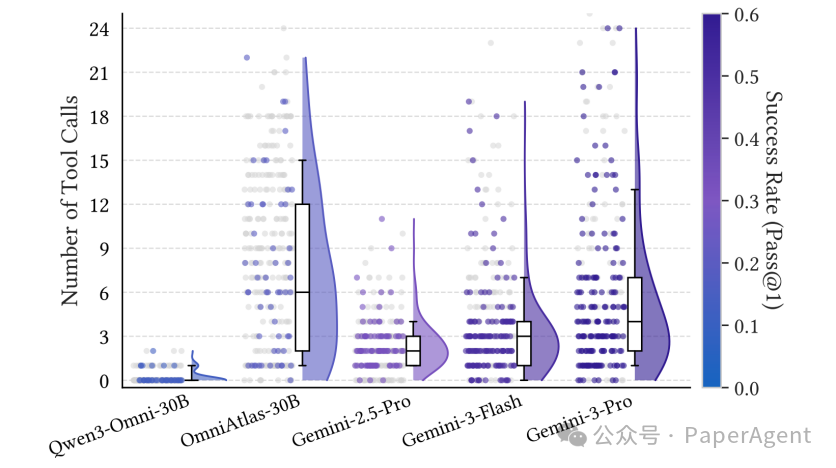
- “零调用”模型成功率极低,证明仅靠模型内部知识难以应对复杂任务。
- 调用次数并非越多越好:部分失败轨迹调用 10 次以上工具却陷入无效循环,说明工具效率与策略比调用次数更重要。
- OmniAtlas 模型调用分布更广且更主动,有效探索率提升直接带动任务成功率。
4. 原生感知 vs 外挂感知工具:谁更胜一筹?
为探究原生全模态感知与调用外部感知工具的优劣,研究设计了四种模式(原生、仅视觉 + 音频工具、仅音频 + 视觉工具、双工具),分别对比强模型(Gemini-3-Flash)与弱模型(Qwen-3-Omni)的表现。
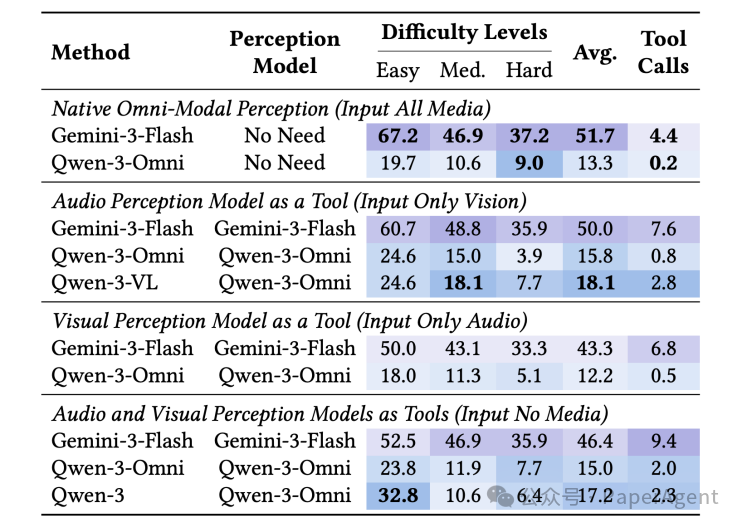
- 对强模型:原生感知准确率最高(51.7%),工具调用次数最少(4.4 次);外挂工具不仅导致准确率下滑(最低 43.3%),调用成本更翻倍至 9.4 次,得不偿失。
- 对弱模型:外挂工具在简单任务上可小幅提升准确率(如 19.7% -> 24.6%),但在困难任务中准确率大幅下跌(从 9.0% 降至 3.9%),说明工具无法替代原生跨模态融合在复杂推理中的核心作用。
结论: 原生感知是强模型的最优解,外挂工具仅能作为弱模型的临时补丁,无法应对高难度跨模态推理。
5. OmniAtlas 训练策略有效性
消融实验量化了 OmniAtlas 两个训练阶段的具体贡献:
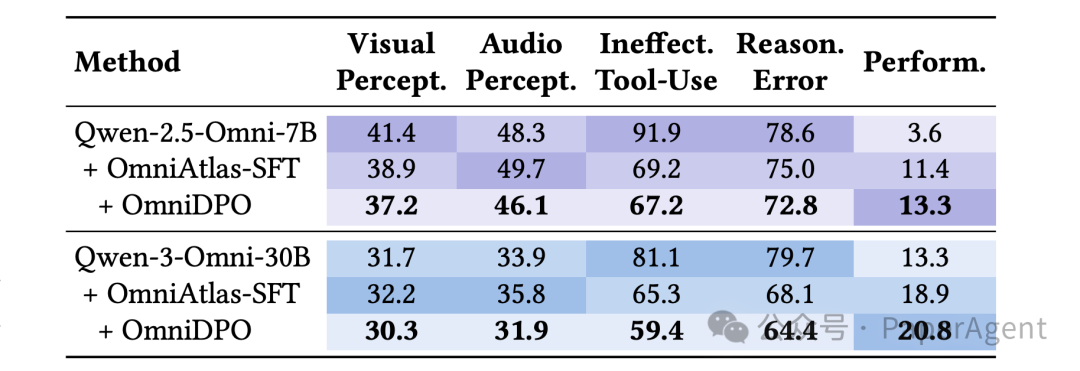
- OmniAtlas-SFT 贡献了主要增益:它是提升模型准确率(Pass@1)和降低“无效工具调用率”的主力。例如,Qwen-3-Omni-30B 的性能由 13.3% 跃升至 18.9%,无效调用率由 81.1% 骤降至 65.3%。
- OmniDPO 实现全方位进阶:在 SFT 基础上,DPO 通过细粒度纠错提供了额外的性能增益(30B 模型性能进一步提升至 20.8%),并全面且持续地降低了视觉/音频感知、工具调用和逻辑推理等各项错误率。
总结与未来展望
OmniGAIA 揭示了当前全模态模型在长程推理与工具使用上的关键短板,而 OmniAtlas 提供了一套行之有效的训练方案,显著提升了开源模型在该类任务上的表现。研究团队指出,未来全模态智能体的发展可从以下方向深入:
- 全模态智能体强化学习:在真实反馈中直接优化长时决策策略。
- 全模态 MCP 生态构建:为智能体接入更丰富的工具集,拓展应用边界。
- 全模态具身 AI 智能体:将智能体引入物理世界,完成真实环境中的交互任务。
 发表于 2026-3-12 11:26:26
|
查看: 285|
回复: 0
发表于 2026-3-12 11:26:26
|
查看: 285|
回复: 0
