最近大火的 OpenClaw(以前也叫 Clawdbot、moltbot),生动诠释了程序员最头疼的事情之一——给项目命名。毕竟,在它爆火的这段时间里,名字就已经改了两次。

那么,OpenClaw 的本质究竟是什么?它和大模型,以及近期同样火热的 Skills、RAG、MCP、Memory 这些技术概念又有什么关系?本文将一次性把这些概念串联起来,为你进行技术祛魅。
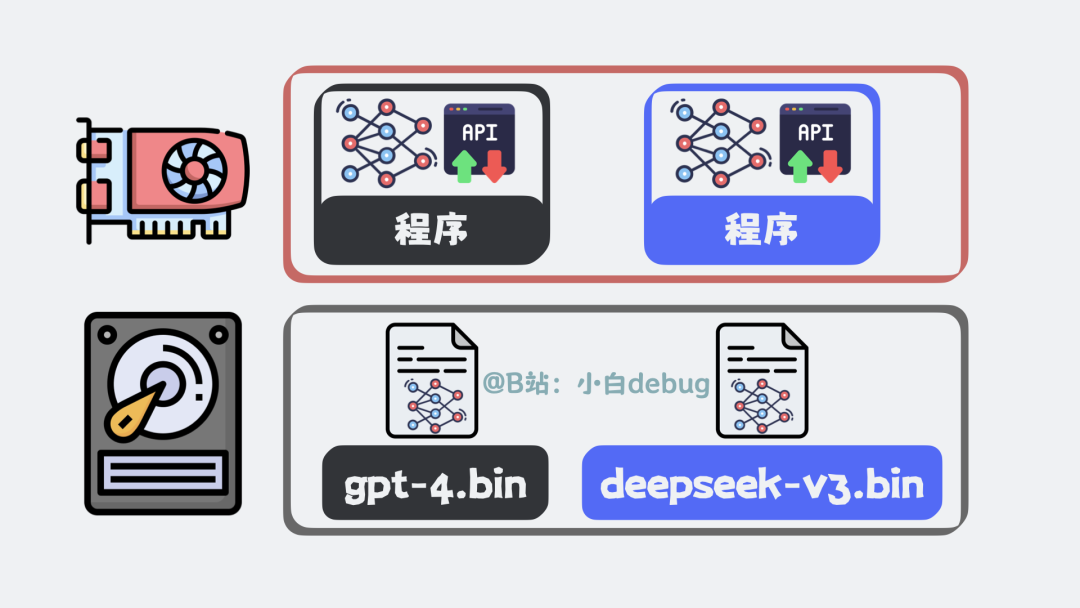
推理服务是什么
像 ChatGPT、DeepSeek 这类大语言模型,本质上就是一个体积超大的二进制文件,例如 gpt-4.bin 或 deepseek-v3.bin。它静静地躺在磁盘上,文件里存储的是训练过程中学到的海量知识参数。
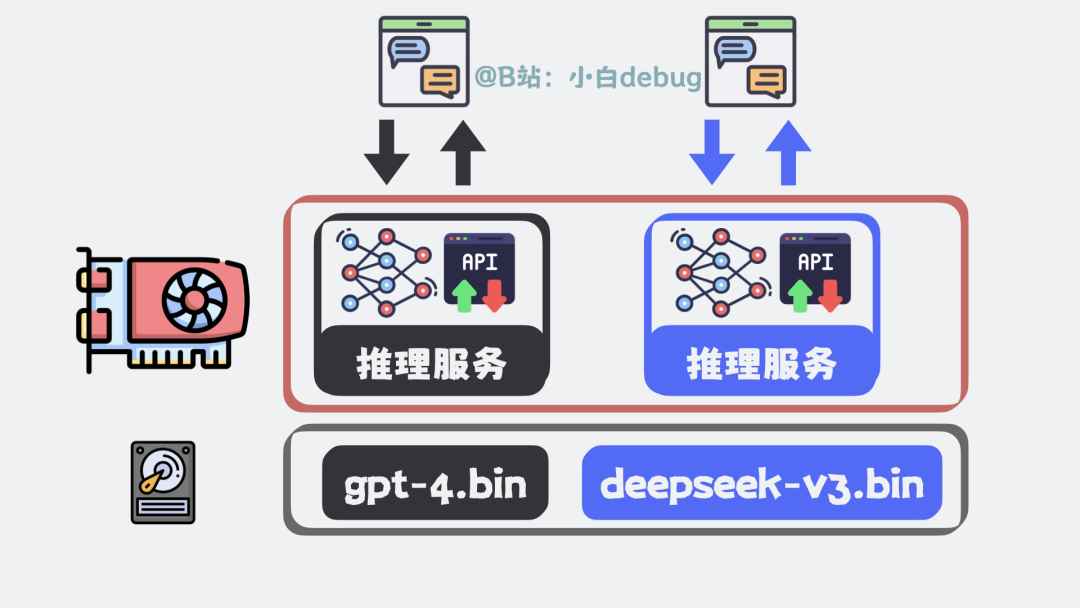
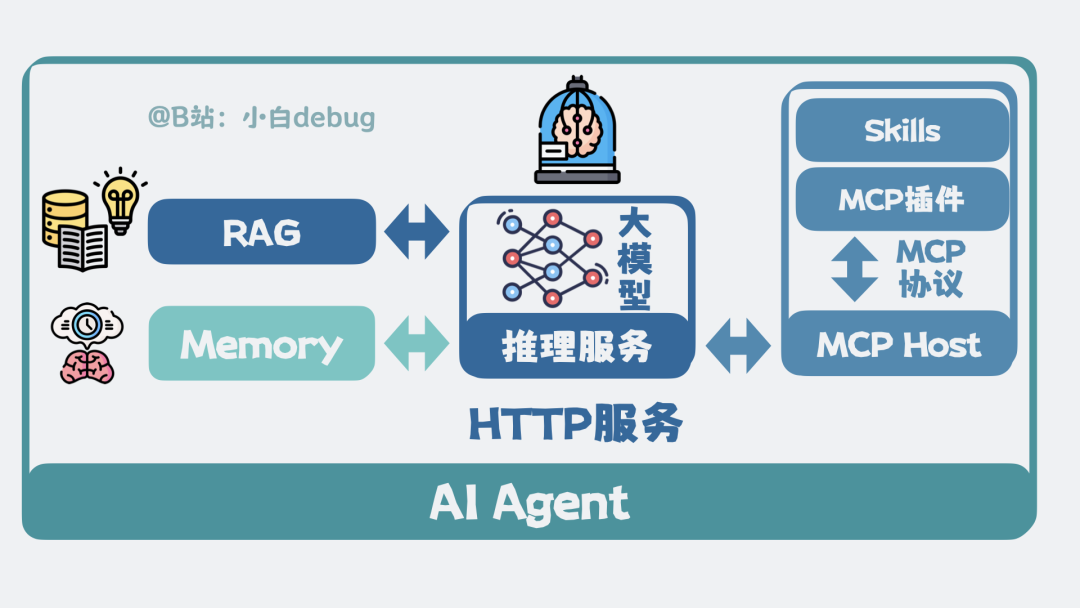
要让这个文件“活”起来工作,就需要一个程序把它加载到内存中,并对外暴露一个 HTTP 接口。这个服务负责接收用户的请求,调用模型进行推理计算,并返回结果。这就是推理服务。如果为它配上一个网页聊天框作为前端,就成了我们熟悉的聊天机器人。
Memory 是什么
推理服务本质上是一个无状态的 HTTP 服务。每个请求进来,处理完就结束,它本身不保存任何会话状态。为了应对高并发,通常会部署多个推理服务实例,并通过负载均衡分发请求。这意味着你的第一次请求可能被发送到机器 A,第二次请求可能发往机器 B,它们是完全独立的两个进程。
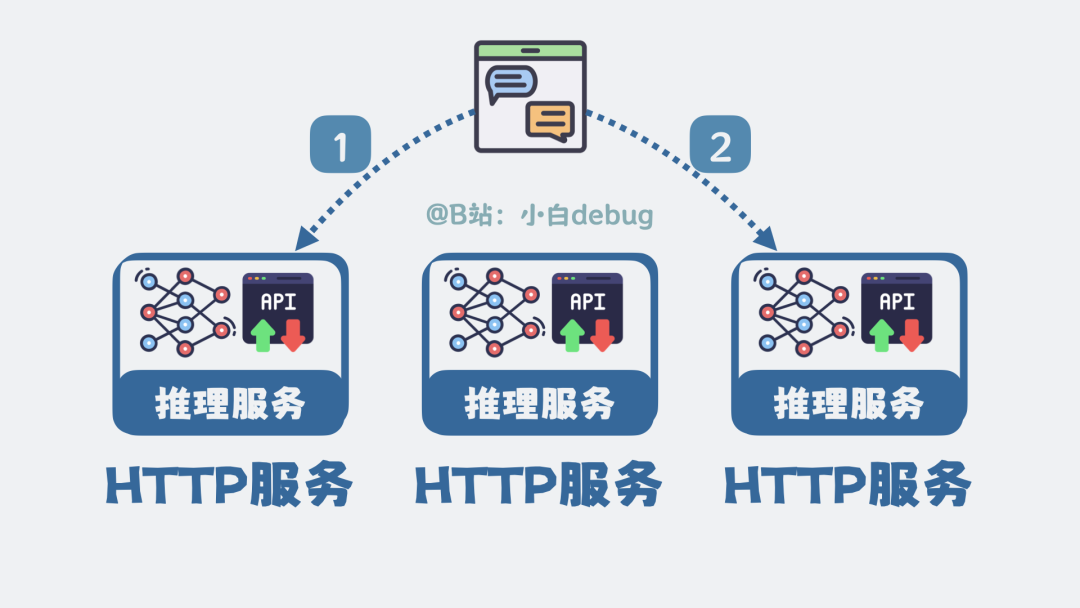
但这就产生了一个问题:我们在使用 AI 聊天时,明显能感觉到它“记得”之前的对话内容,这又是如何实现的?
实际上,大模型本身并不具备记忆能力。每次请求时,系统会将之前的历史聊天记录重新拼接到当前的问题中,然后一并发送给大模型。这一系列拼接后发给大模型的内容,统称为上下文。大模型看到了完整的上下文,自然就能接上话,营造出有记忆的假象。
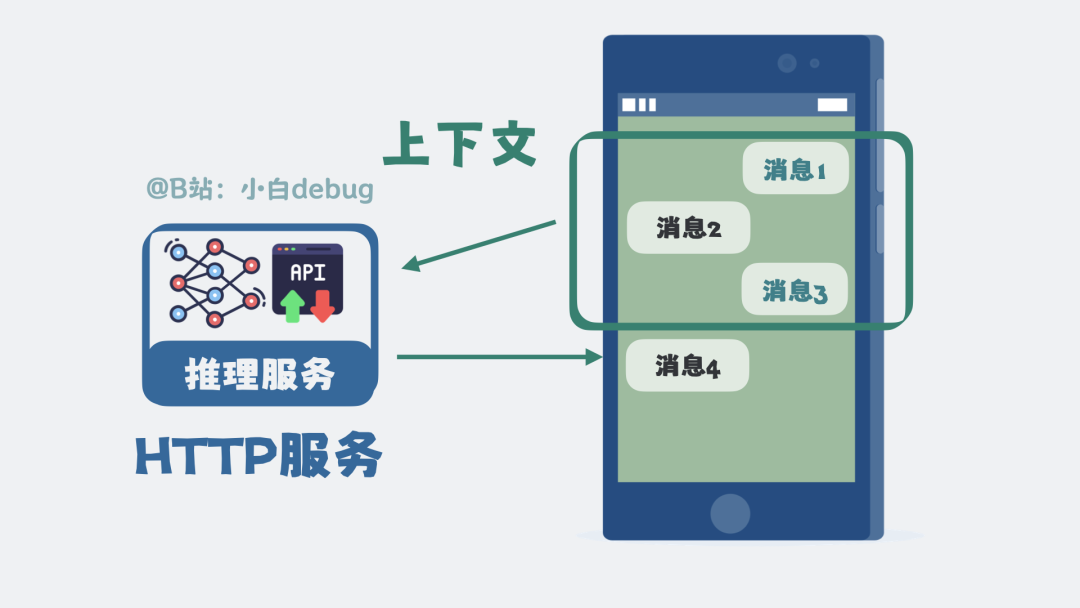
新的问题又来了:如果每次请求都把所有的历史对话都发出去,上下文会变得无比冗长,最终超出模型能处理的上限。如何解决?
我们可以对记忆进行分级管理。将当前会话最近的几轮对话完整保存,这称为短期记忆。将很久之前的对话,提取关键信息并压缩成摘要,这称为长期记忆。
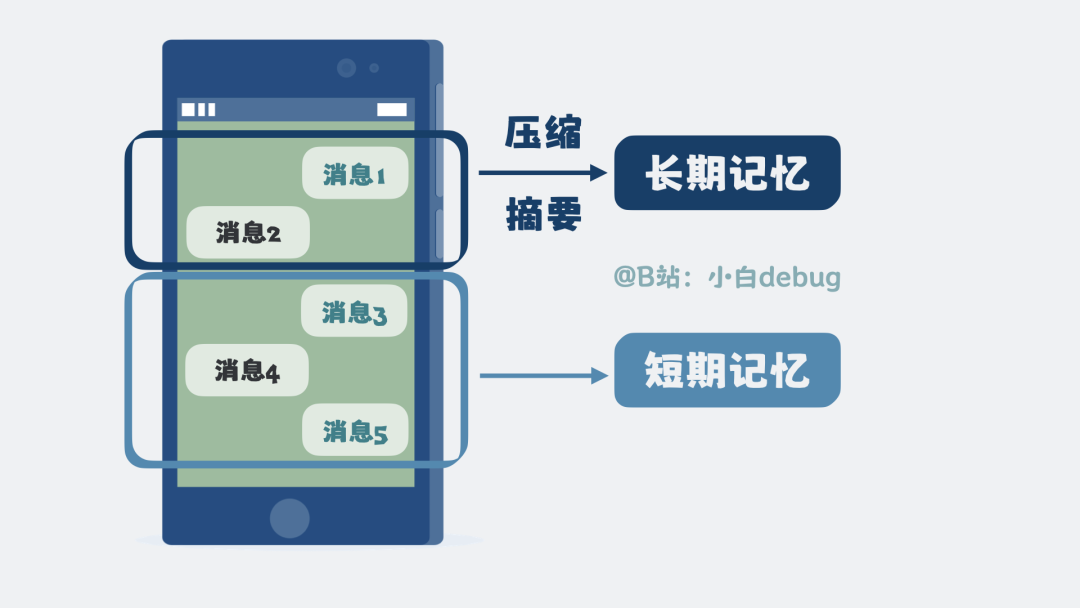
每次发起新请求时,将短期记忆和长期记忆摘要一起拼接到对话中,再发送给大模型。这样,大模型看起来就像拥有了连贯的记忆。
这套用于创建和管理上下文的机制,就叫做 Memory。
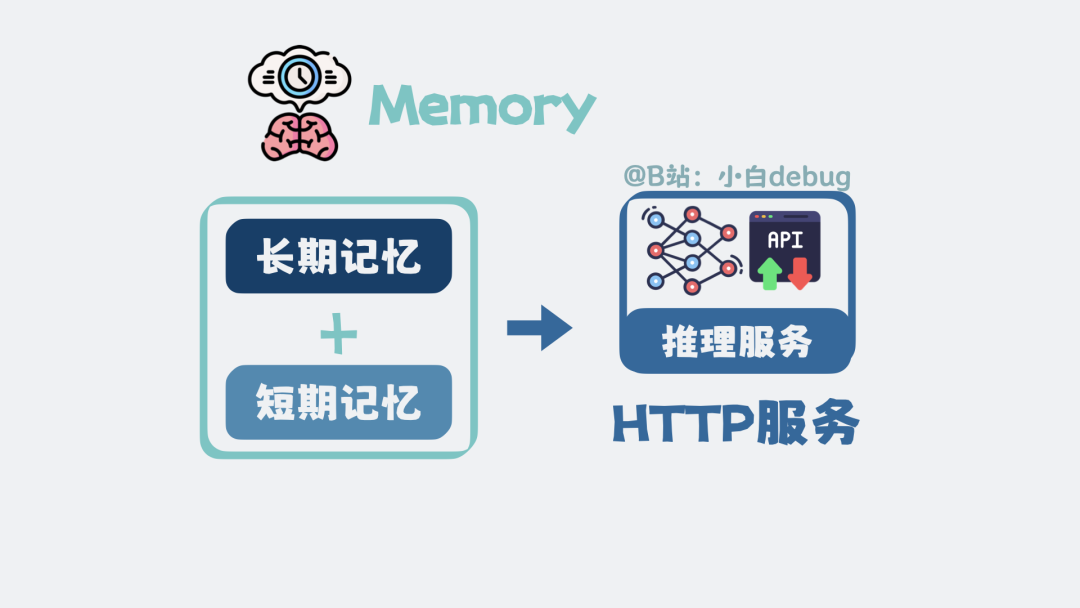
RAG 是什么
有了 Memory,大模型能记住历史对话了。但新问题随之而来:大模型的训练数据来源于互联网上的历史公开数据,训练完成后知识就固化了。如果你问它今天的新闻,或者公司内部的保密文档,它根本不可能知道。
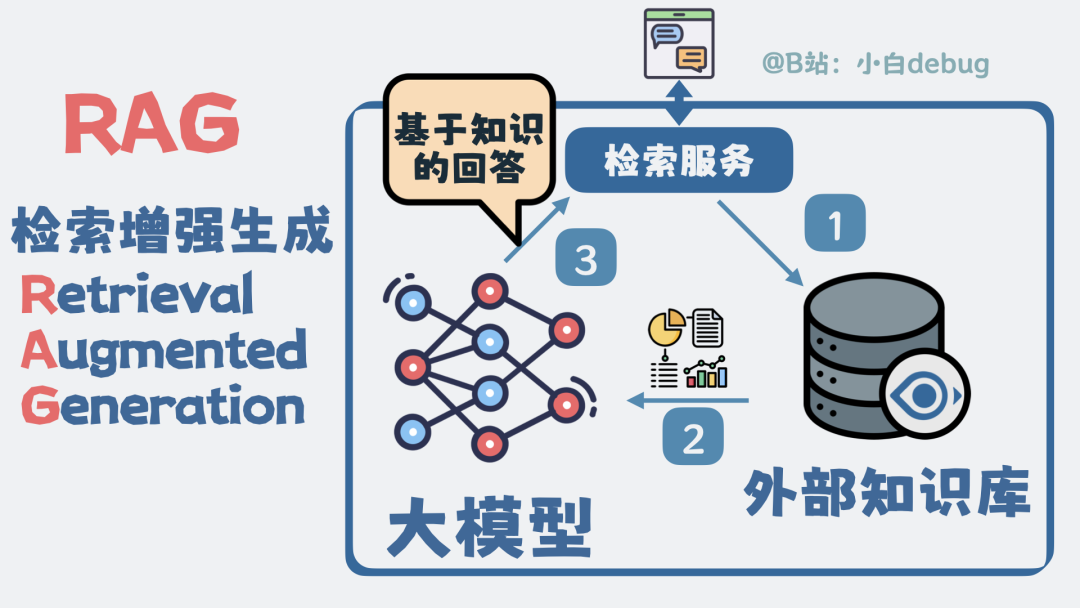
怎么办?我们可以为它配备一个外部知识库,里面存放最新的新闻、公司内部文档等资料。如果数据量很大,就需要存入数据库。
当用户提问时,先从这个外部知识库中进行检索匹配,获取相关知识片段,再将这些信息连同问题一起“喂”给大模型。大模型就能基于这些外部知识来生成回答。这种“检索外部知识来增强大模型回答能力”的方案,就是检索增强生成,英文全称 Retrieval-Augmented Generation,简称 RAG。
但传统数据库只能进行字面匹配。例如,“黄枫谷历飞羽”和“韩老魔”虽然指代同一个人,字面却完全不同,传统数据库无法匹配。如何解决语义匹配问题?
我们可以将文本转化为数学向量,通过计算向量之间的距离来衡量文本之间的语义相似度。
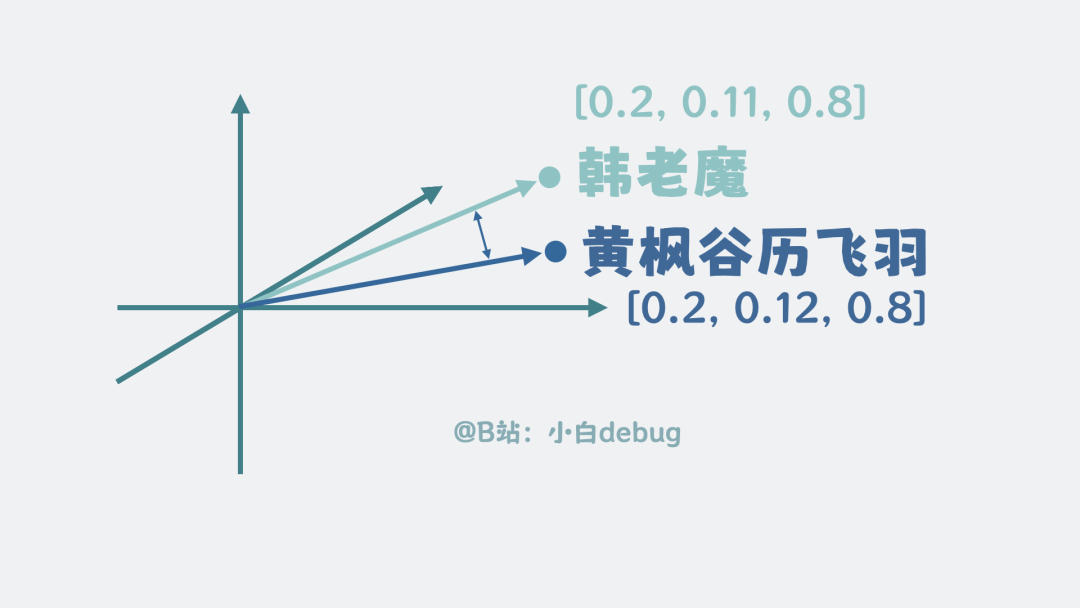
这样,语义相近但表述不同的文本就能被匹配上。因此,RAG 系统中使用的数据库存储的是向量数据,这类数据库也称为向量数据库,例如 Milvus。如果数据量不大,也可以使用我们熟悉的 PostgreSQL 等支持向量扩展的关系型数据库。

MCP 是什么
在 Memory 和 RAG 的加持下,大模型能记住历史并获取外部知识了。但新的瓶颈又出现了:现在的大模型只能对话和思考,就像一个“缸中大脑”,没有手脚。如何让它具备操作外部工具的能力?
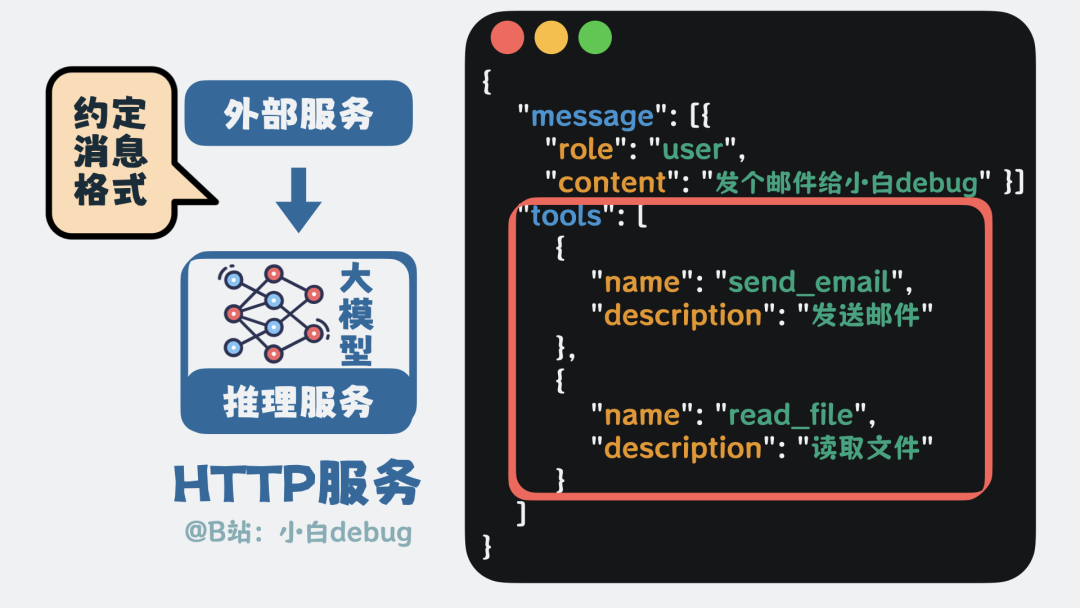
方法很简单:我们可以在与模型的对话中,约定一种特定的消息格式。外部程序先告诉大模型有哪些工具可用,格式大致如下:
{
"message": [{
"role": "user",
"content": "发个邮件给小白debug"
}],
"tools": [
{
"name": "send_email",
"description": "发送邮件"
},
{
"name": "read_file",
"description": "读取文件"
}
]
}
当大模型决定使用某个工具时,它会输出一段特定格式的 JSON。例如,要发送邮件,JSON 中会写明收件人和邮件内容。
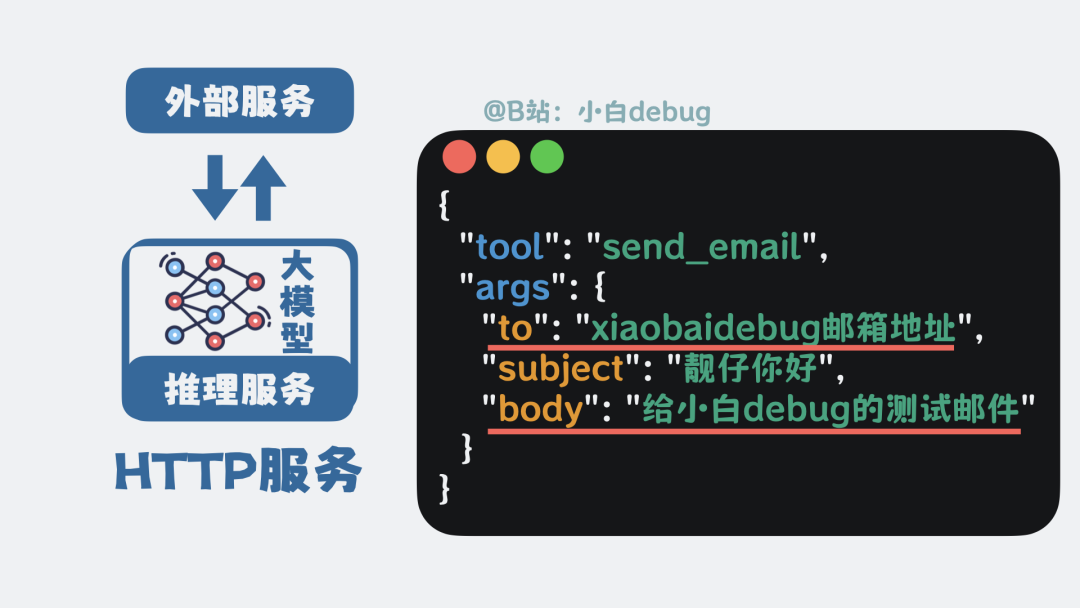
外部程序收到这段 JSON 后,解析并执行发送邮件的操作。操作完成后,再将执行结果返回给大模型。
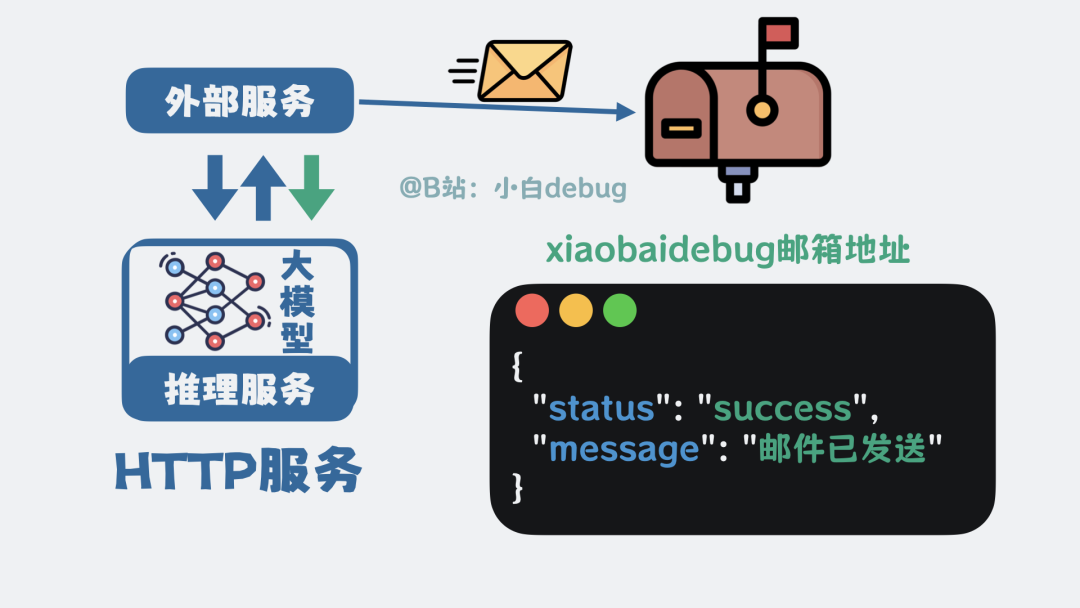
大模型基于工具的执行结果,生成最终的回复给用户。
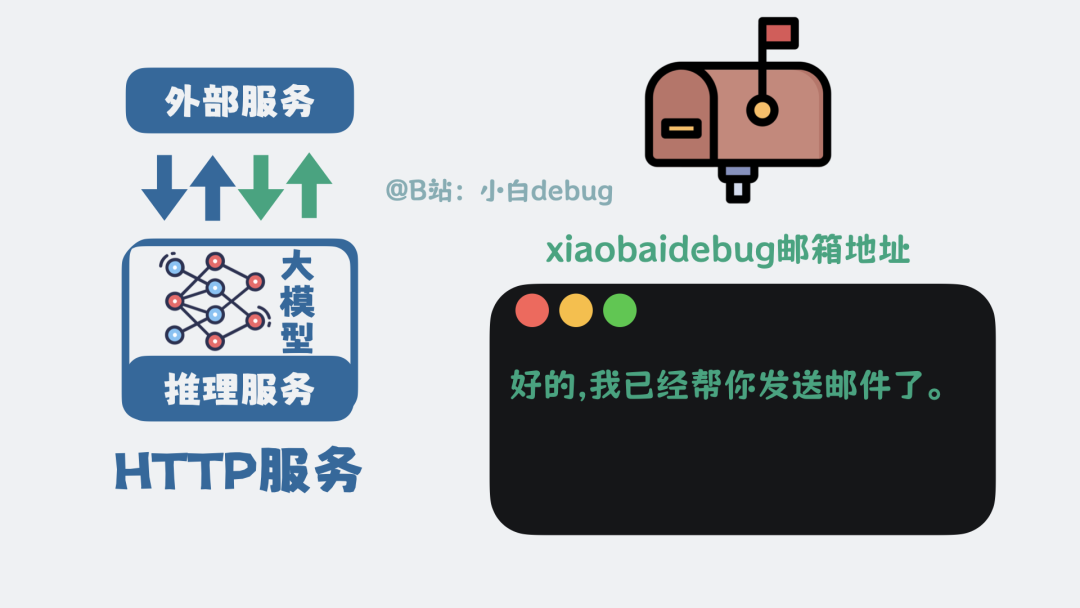
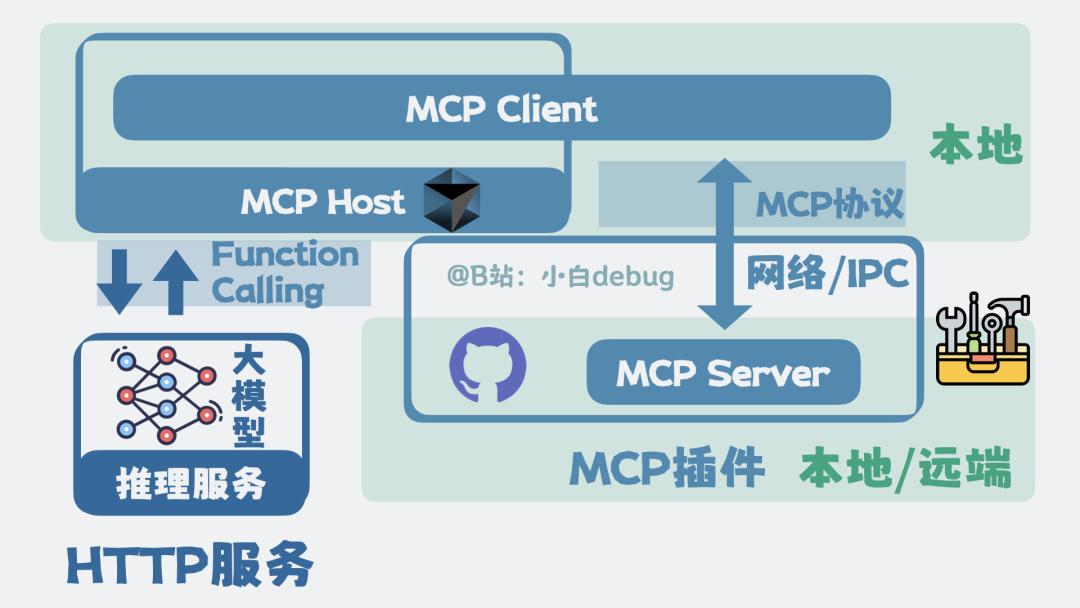
这种大模型与外部程序之间通过特定格式来表达工具调用意图的机制,被称为 Function Calling。而外部程序根据这一意图与具体工具插件进行交互所遵循的协议,则被称为 Model Context Protocol,简称 MCP。
在外部负责解析 JSON 并协调工具调用的程序叫做 MCP Host,例如我们常用的编程助手 Cursor、Claude Code。
那些能被调用的具体工具,就是 MCP 插件,它们也被称为 MCP Server。MCP 插件可以部署在本地电脑,也可以在远端服务器上。MCP Host 上专门负责与 MCP Server 通信的组件,叫做 MCP Client。
例如,一个 GitHub MCP 插件,本地 MCP Host 上的 MCP Client 负责接收调用请求,而真正的 MCP Server 可能部署在 GitHub 的服务器上,执行实际的 GitHub API 操作。
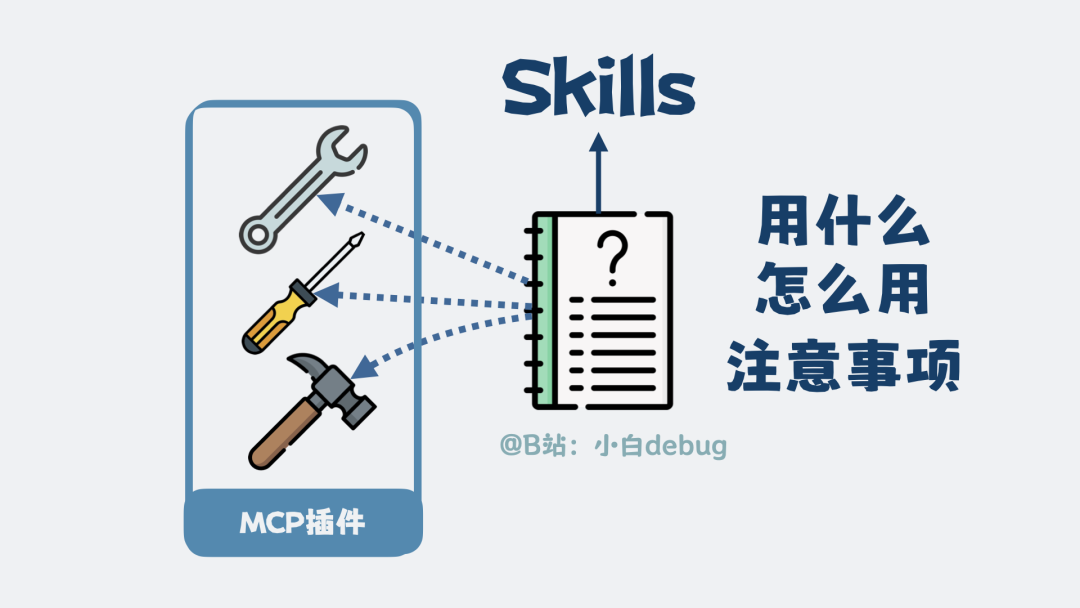
Skills 是什么
MCP 协议和插件解决了“能调用工具”的问题,但新问题又来了:面对琳琅满目的插件,大模型怎么知道在什么场景下、该按什么顺序、如何组合使用这些工具呢?
这就好比给一个大学生一堆钳子、扳手,他也不一定能修好车。他缺少的是经验和流程。
解决办法是:我们可以编写一份“结构化操作手册”,里面详细说明遇到特定场景时该用什么工具、先做什么后做什么、以及有哪些注意事项。这份结构化的操作指南,就叫做 Skills。
以排查线上事故为例,MCP 只是把“查监控、查日志、查配置、回滚版本”这些工具能力给到大模型。而“排查问题”这个 Skills,则明确规定了“先看监控判断影响范围 → 再查日志和配置定位问题模块 → 必要时执行回滚”这一整套固定流程。
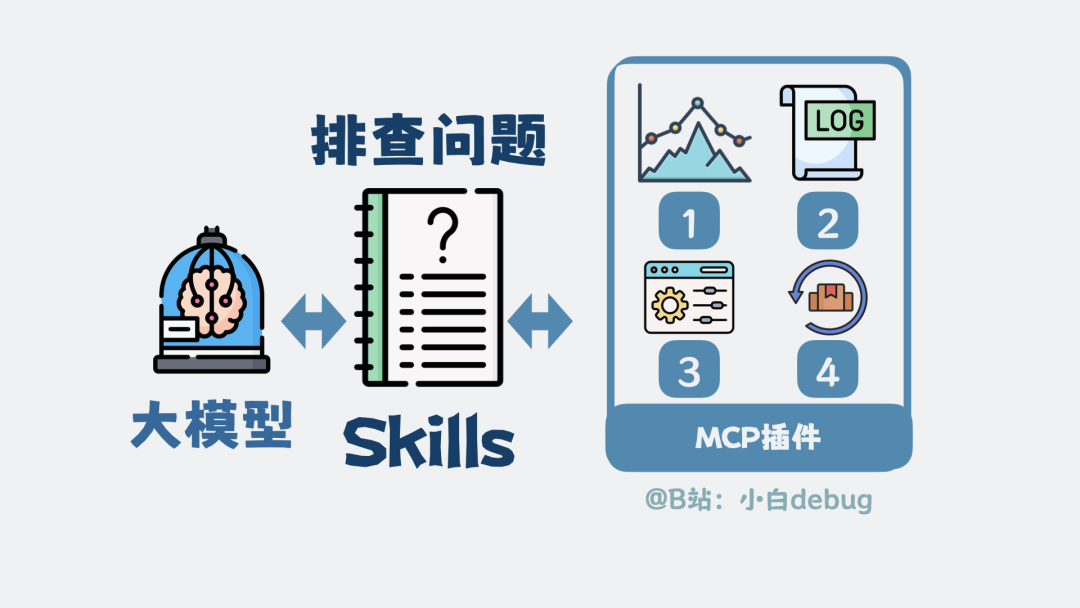
换句话说,大模型就像大脑,MCP 协议让它有了手,MCP 插件就是手上的具体工具;而 Skills 则是操作经验,规定在什么场景下、按什么顺序、组合使用哪些工具来完成特定任务。
AI Agent 是什么
大模型本身具备思考和规划能力。给它加上 Memory,它就能记住历史;加上 RAG,它就能获取外部知识;加上 MCP 和 Skills,它就能操作工具并按流程办事。这些组件共同构成了一个能在某些功能上代替人类、自主行动并完成目标的 AI 系统,这就是 AI Agent。本质上,它是一个智能的“工具人”。
通过提示词为它设定不同的角色,它可以扮演智能客服、程序员助理、私人律师等各种角色,听从指令并完成任务。
OpenClaw 的本质
最近很火的 OpenClaw,其本质就是一个帮你自动操作电脑的 AI Agent。理论上,你能在电脑上做什么,它就能做什么,比如发送邮件、投递简历,甚至进行交易。因此,其权限和安全问题至关重要。
客观地说,OpenClaw 所做的事情在技术上并非突破性的创新。它与前段时间同样备受关注的 Manus 是类似的产品。区别在于,OpenClaw 主要面向本地电脑操作,而 Manus 出于安全考虑,将操作环境放在了远端的虚拟机中。如果将 OpenClaw 部署到远端服务器,就颇有“开源版 Manus”的味道了。

安全问题最终需要用户自行权衡,OpenClaw 本身只管开源,这种“野路子”的风格让它近期火爆异常。建议开发者们理性看待,先想清楚到底有哪些重复性工作真正需要它来完成。
至此,我们梳理了从基础推理服务到复杂 AI Agent 的完整技术栈。单个 Agent 你已了解,那么多个 Agent 之间是如何协作的?多 Agent 系统又有哪些经典架构?这将是另一个有趣的话题。
 发表于 2026-3-12 11:17:01
|
查看: 168|
回复: 0
发表于 2026-3-12 11:17:01
|
查看: 168|
回复: 0
