七八年前,我负责维护着上百套大规模 PostgreSQL 集群,面临着高可用方案的选型难题。当时我几乎调研了市面上所有知名方案,最终选择了 Patroni。上线后的实践证明,这个决定非常明智。这些年来,我们经历了数十次真实的硬件故障,系统的恢复时间目标基本都能稳定在二三十秒。最让人省心的是,这套方案可以实现故障的自动切换,大大减轻了运维压力。
如今看来,Patroni 已然成为 PostgreSQL 高可用的事实标准。无论是传统的发行版方案还是 Kubernetes Operator,其底层的高可用机制大多都绕不开 Patroni。那么,它究竟好在哪里?PostgreSQL 的高可用到底应该如何构建?本文将深入探讨这些问题。
可用性、RTO 与 RPO
可用性 通常用服务可用时间占总时间的百分比来计算。达到99.99%以上的可用性,即所谓的“四个九”,被认为是高可用水平。然而,可用性是一个业务连续性指标,它不能完全代表数据库的技术能力。真正体现系统容灾能力的是两个核心的技术指标:RPO 和 RTO。
- RPO:恢复点目标,定义了主库故障时允许丢失的最大数据量。
- RTO:恢复时间目标,定义了主库故障后,系统恢复写入能力所需的最长时间。
这两个指标代表了系统“扛事”的真实能力。那么,什么样的 RPO/RTO 水平才算优秀呢?国际和国内都有相关的标准。
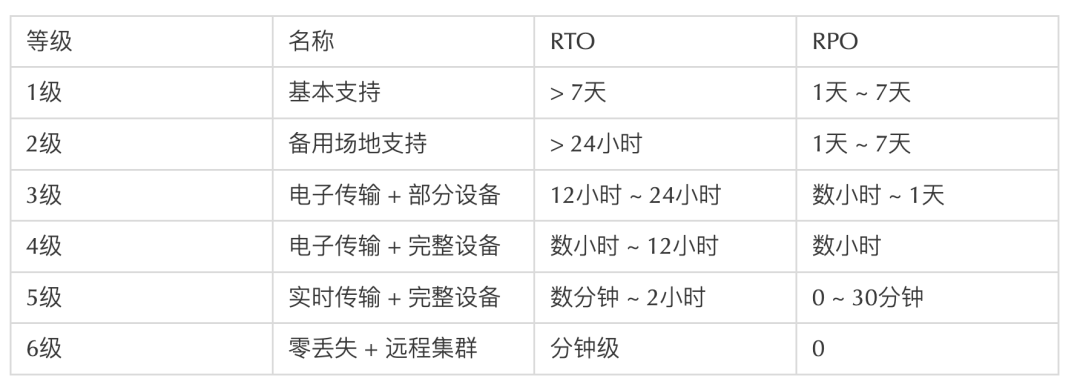
国内《网络安全技术 信息系统灾难恢复规范》的六个灾难恢复等级。
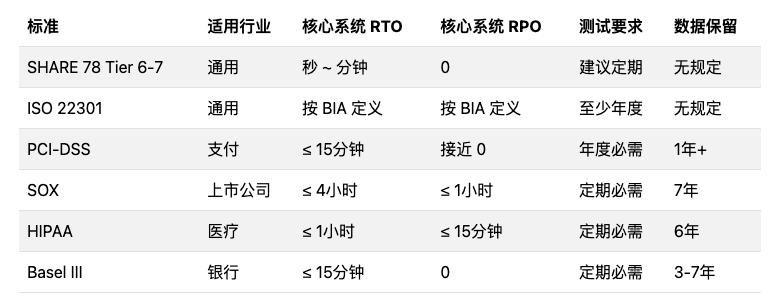
SHARE 78、ISO 22301、PCI-DSS等标准对核心系统RTO和RPO的要求。
最高等级的容灾通常要求 RTO 达到分钟级,并且 RPO = 0(即零数据丢失)。在过去,实现这一目标需要巨额投入。但在今天,借助 Patroni 与 PostgreSQL,实现金融级容灾的软件成本已无限趋近于零。
太长不看版结论
在合理配置下,Patroni 可以轻松实现 RTO < 30秒,RPO = 0 的水平。这不仅是理论推演,更是经过大规模生产环境检验的结果。
- 在 RPO 方面,Patroni 可以实现类似于 Oracle Data Guard 的“最大性能”、“最大可用性”和“最大保护”三种数据保护模式,甚至提供了更强的数据一致性选项。
- 在 RTO 方面,Patroni 能在常规硬件上实现端到端(包含负载均衡器健康检查)小于30秒的故障恢复。
接下来,我们将详细拆解在高可用设计中,如何对 RPO 和 RTO 进行利弊权衡与配置。
RPO 的利弊权衡
RPO 定义了故障时允许的数据丢失上限。对于金融交易等场景,通常要求 RPO = 0,即不允许任何数据丢失。然而,更严格的 RPO 要求是有代价的:它会引入更高的写入延迟、降低系统吞吐量,并可能因为从库故障而导致主库不可用。
在默认的异步复制模式下,主从之间存在复制延迟(通常在毫秒级和KB量级)。如果主库在此时故障,未复制的数据就会丢失。自动故障切换的逻辑如下图所示:
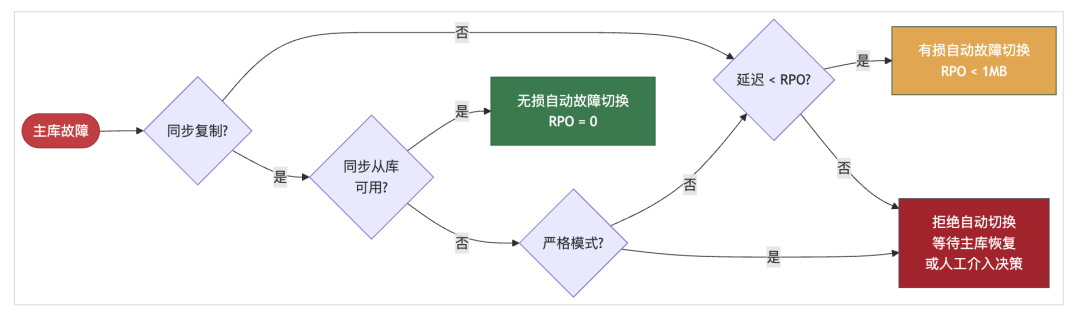
主库故障时,根据复制状态和配置决定切换策略的流程。
实现原理
Patroni 提供了一个关键参数 maximum_lag_on_failover,用于控制自动故障切换时允许的最大数据丢失量,默认值为 1MB。这意味着,当主库宕机时,如果存在复制延迟在 1MB 以内的从库,Patroni 会自动提升它为新主库。
如果所有从库的延迟都超过了这个阈值,Patroni 将拒绝自动切换以避免大量数据丢失,此时需要人工介入决策。这就引入了第一个权衡:你需要根据业务对数据一致性和服务可用性的侧重,来配置这个参数。
对于要求 RPO = 0 的场景,则需要启用 Patroni 的同步复制或严格同步复制模式。
三种数据保护模式
熟悉 Oracle 的读者可以将 Patroni 的复制模式类比为 Oracle Data Guard 的三种模式:

最大性能、最大可用性、最大保护三种模式的特性与适用场景对比。
实际上,通过配置 Patroni 和 PostgreSQL,你可以实现比 Oracle 最大保护模式更强的一致性保障。例如,可以配置多个同步从库,甚至要求数据在从库上完成应用(synchronous_commit: 'remote_apply')后才向客户端返回成功。

通过配置synchronous_mode和synchronous_mode_strict参数实现不同保护模式。
对于绝大多数业务,异步复制(最大性能)模式提供的 RPO 保证已经足够。对数据完整性要求极高的核心业务,则推荐使用最大可用性或最大保护模式。
RTO 的利弊权衡
RTO 定义了故障恢复所需的最长时间。整个恢复流程涉及故障检测、租约过期、新主选举、提升(Promote)以及负载均衡器感知等多个阶段,因此 RTO 不可能为零。
值得注意的是,RTO 并非越小越好。 更短的 RTO 意味着更短的超时等待时间,这会使集群对网络抖动异常敏感,从而增加误切换的风险。误切换频率上升,整体可用性反而可能下降。这就引出了第二个权衡:你需要在恢复速度与误切概率之间取得平衡。 网络质量越差,越应选择保守的配置。
关于 RTO 的“营销话术”
RTO 常常是数据库营销的重灾区。讨论 RTO 时,必须明确几个前提:
- 故障域:是计算节点、存储还是网络故障?
- 测量口径:是以数据库可写入,还是负载均衡器(LB)、应用端可连接为准?
- 统计量:宣称的是最优值、最差值还是平均值?
- 网络条件:是同机柜、同机房、同城还是跨地域?
在同机柜高质量网络下,RTO < 30秒 可视为业界顶级水平。下文我们将采用最严格的口径:以 HAProxy 端侧开始接受写入连接作为 RTO 终点,并讨论 最坏情况(而非平均或最优情况)。
架构与参数配置
RTO 无法脱离架构讨论。经典的基于 Patroni 的 高可用 架构如下:
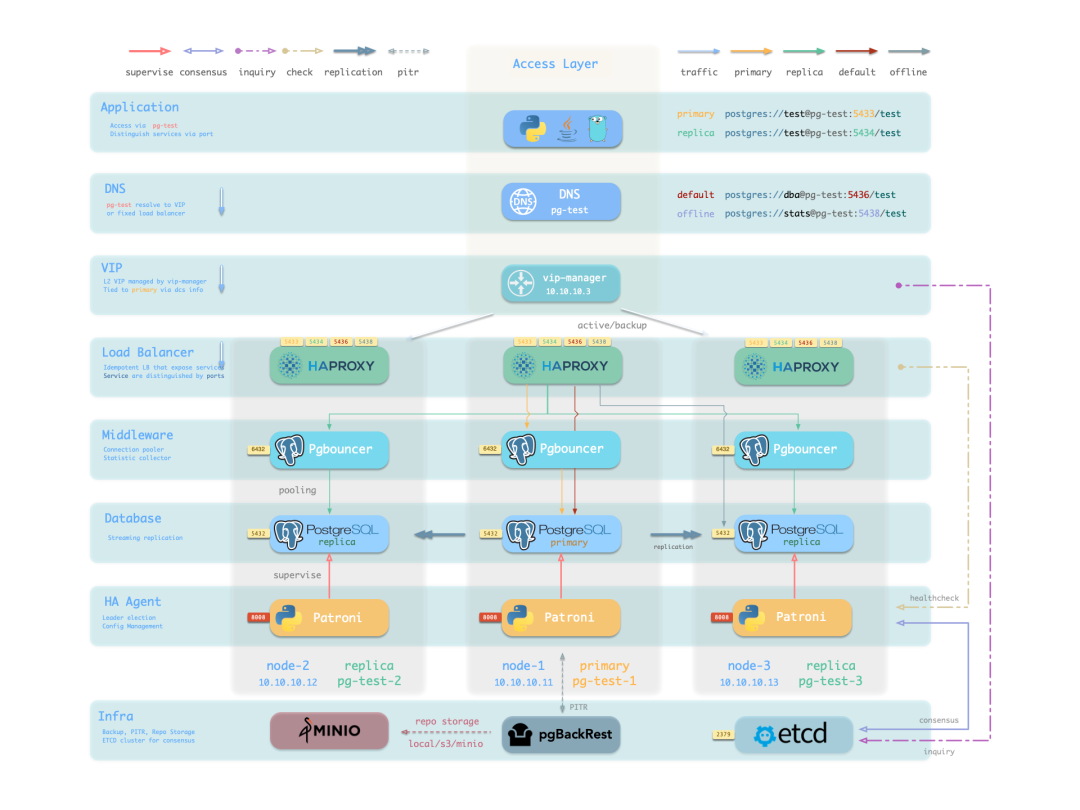
应用通过VIP和HAProxy访问由Patroni管理的PostgreSQL主从集群。
在该架构中:
- PostgreSQL 使用流复制构建物理从库。
- Patroni 管理 PostgreSQL 实例并处理高可用逻辑。
- Etcd 作为分布式配置存储(DCS),用于领导者选举。
- HAProxy 对外提供服务,并利用 Patroni 的健康检查接口自动分发流量。
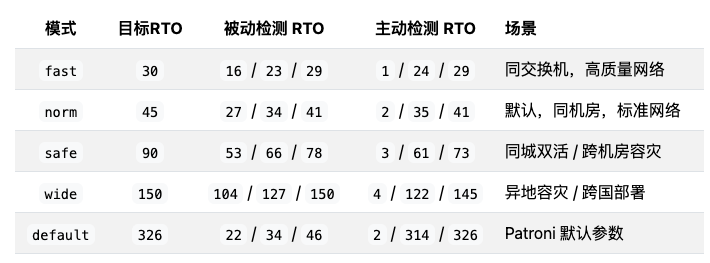
RTO 主要取决于 Patroni 的参数,其次受 HAProxy 健康检查参数影响。Patroni 的默认参数并非最优。根据不同的网络条件,我总结出四组优化后的参数配置预设:
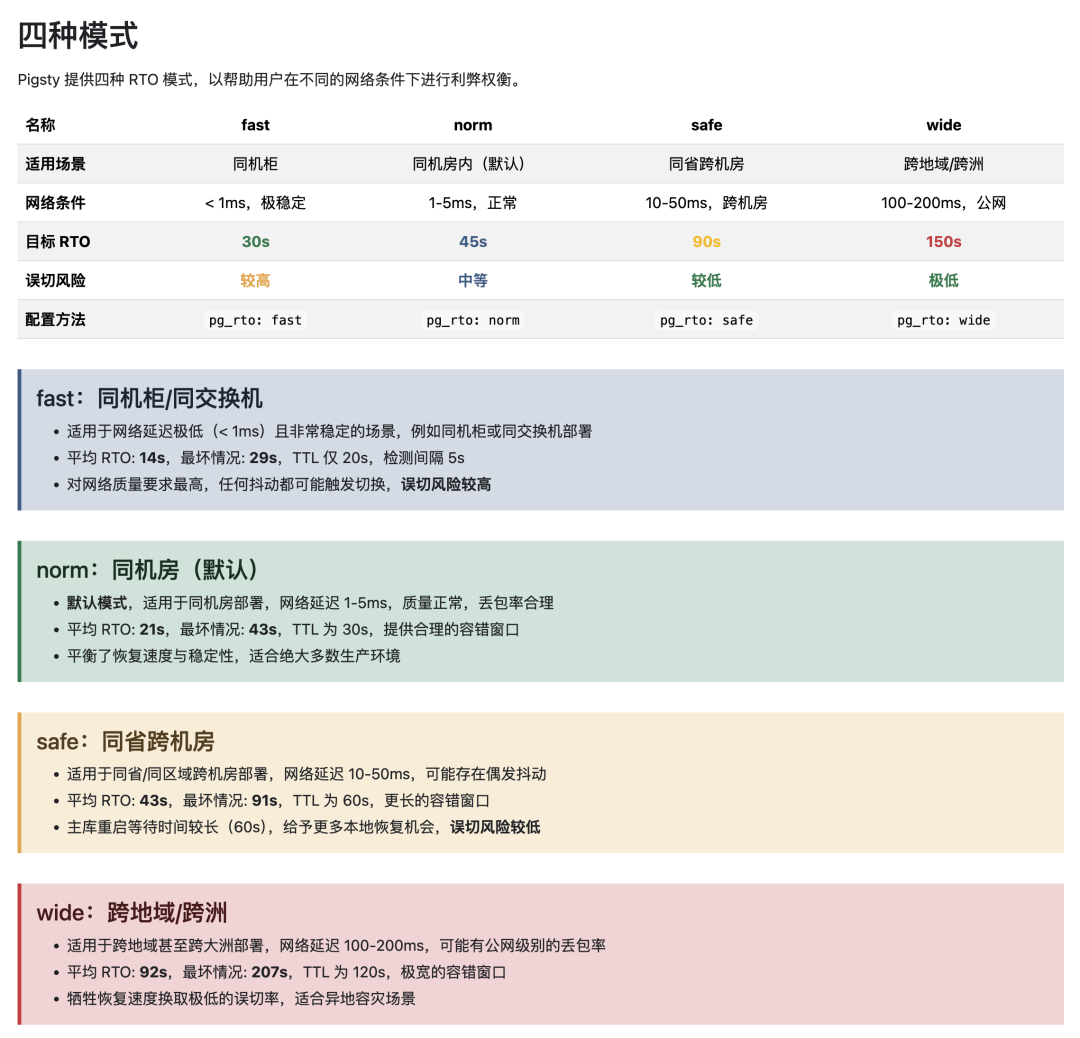
针对同机柜、同机房、跨机房、跨地域四种网络场景的RTO模式。
这四种模式对应着 Patroni 和 HAProxy 共 10 个核心参数的不同组合:
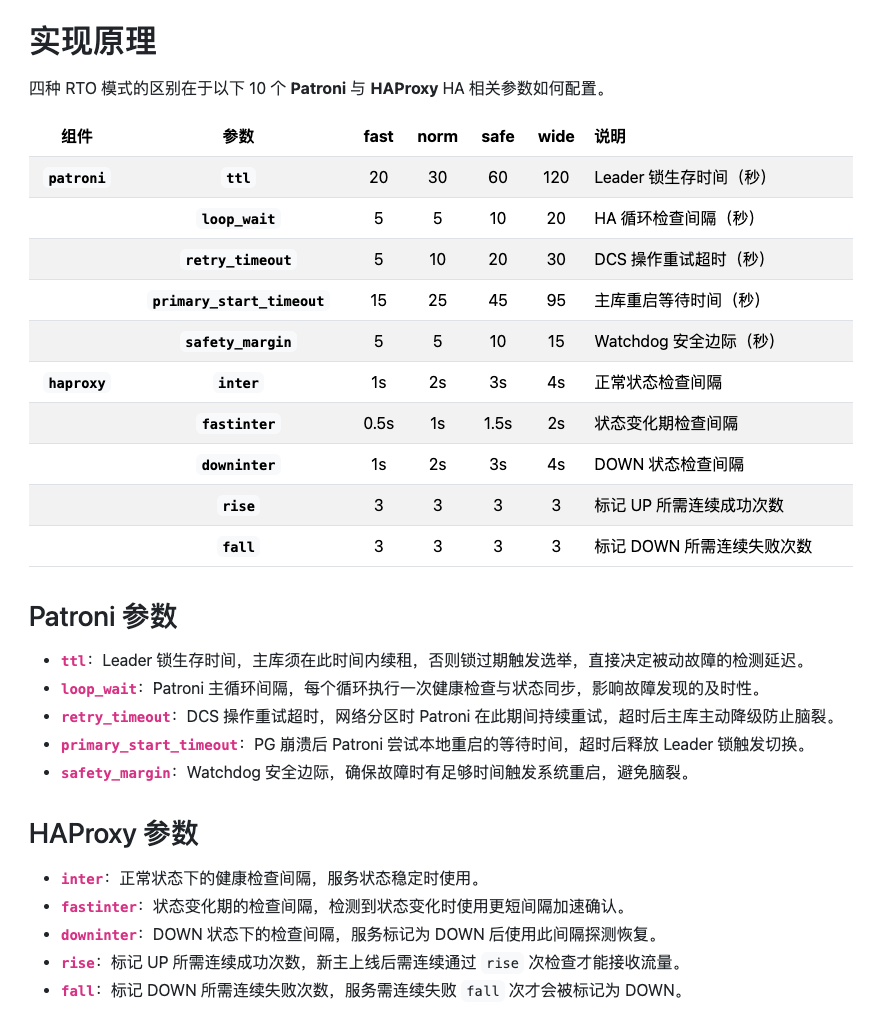
fast, norm, safe, wide四种模式下具体参数值。
在这些配置下,RTO 的理论表现如下图所示:
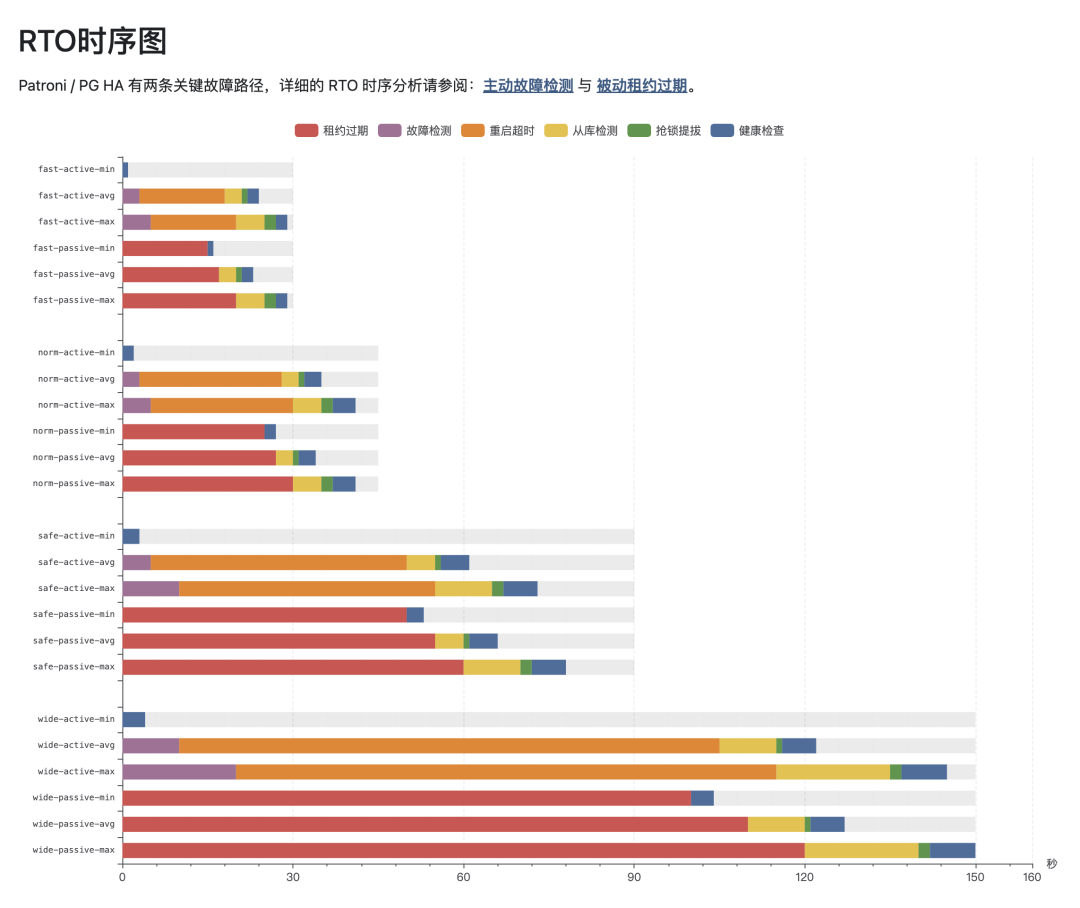
主动检测与被动检测两种故障路径下,各模式最优、平均、最差RTO的分解。
以最坏情况为基准:
- norm(默认优化)模式:RTO < 45秒。
- fast(同机柜)模式:RTO < 30秒。
- safe/wide 模式:RTO 目标分别为 90秒 和 150秒。
一个重要提醒:很多方案直接使用 Patroni 的默认参数。其中 primary_start_timeout 默认为 300秒,这会导致在主库进程崩溃(但节点存活)的场景下,最坏 RTO 可能超过 300秒,这是不可接受的。
故障路径与 RTO 拆解
上述 RTO 数据是如何得出的?这需要分析具体的故障路径。Patroni 高可用架构中的故障可归并为两条典型路径:
- 被动故障切换:节点宕机或网络隔离,主库租约过期触发选举。
- 主动故障切换:Patroni 存活但 PostgreSQL 崩溃,尝试本地重启超时后触发选举。

主库故障后,无论是主动检测还是被动等待租约过期,最终都会触发从库竞选与新主提升。
这两条路径的 RTO 计算方式有差异,详细的时序拆解如下图所示:
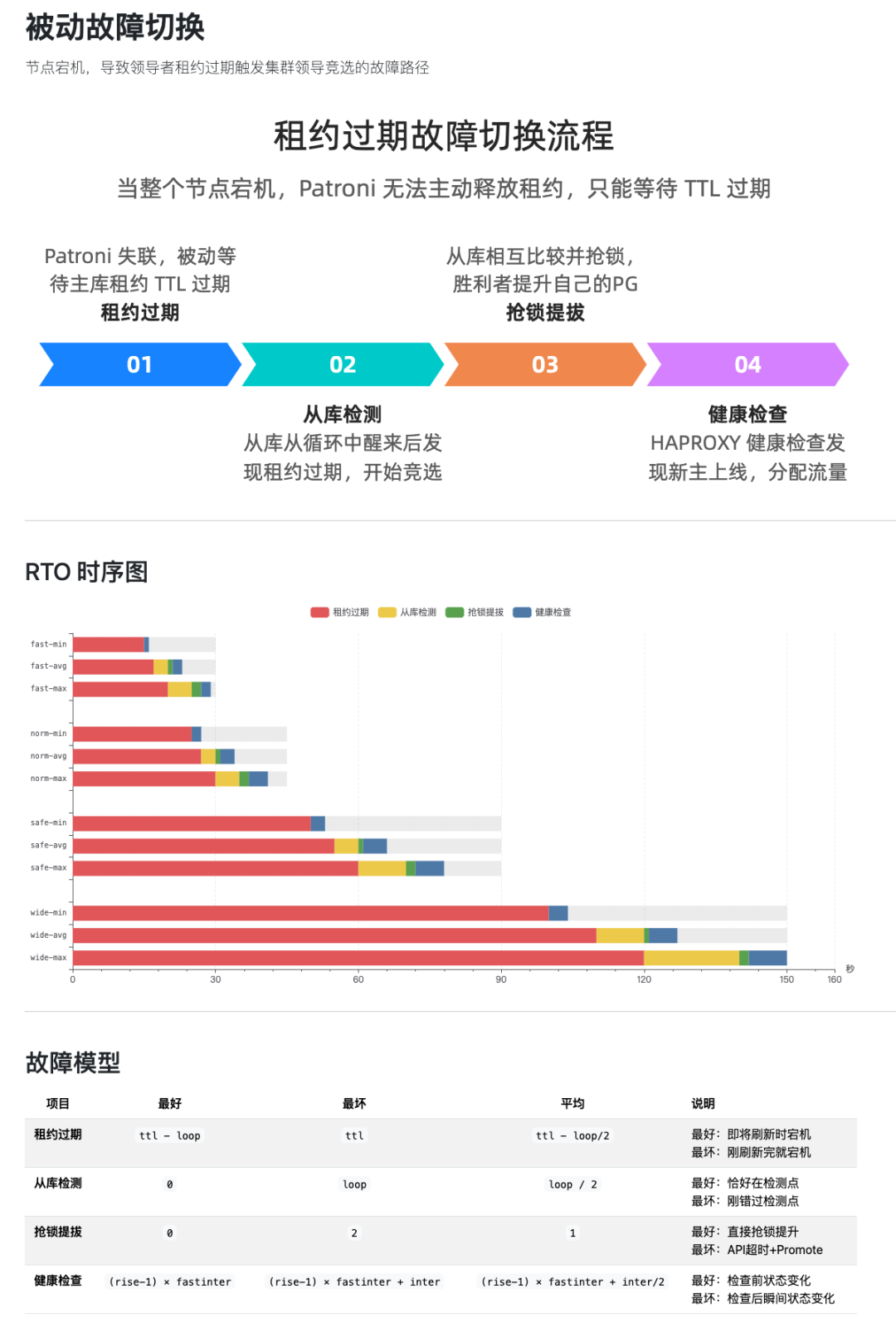
节点宕机导致租约过期场景下的RTO阶段分解与计算模型。
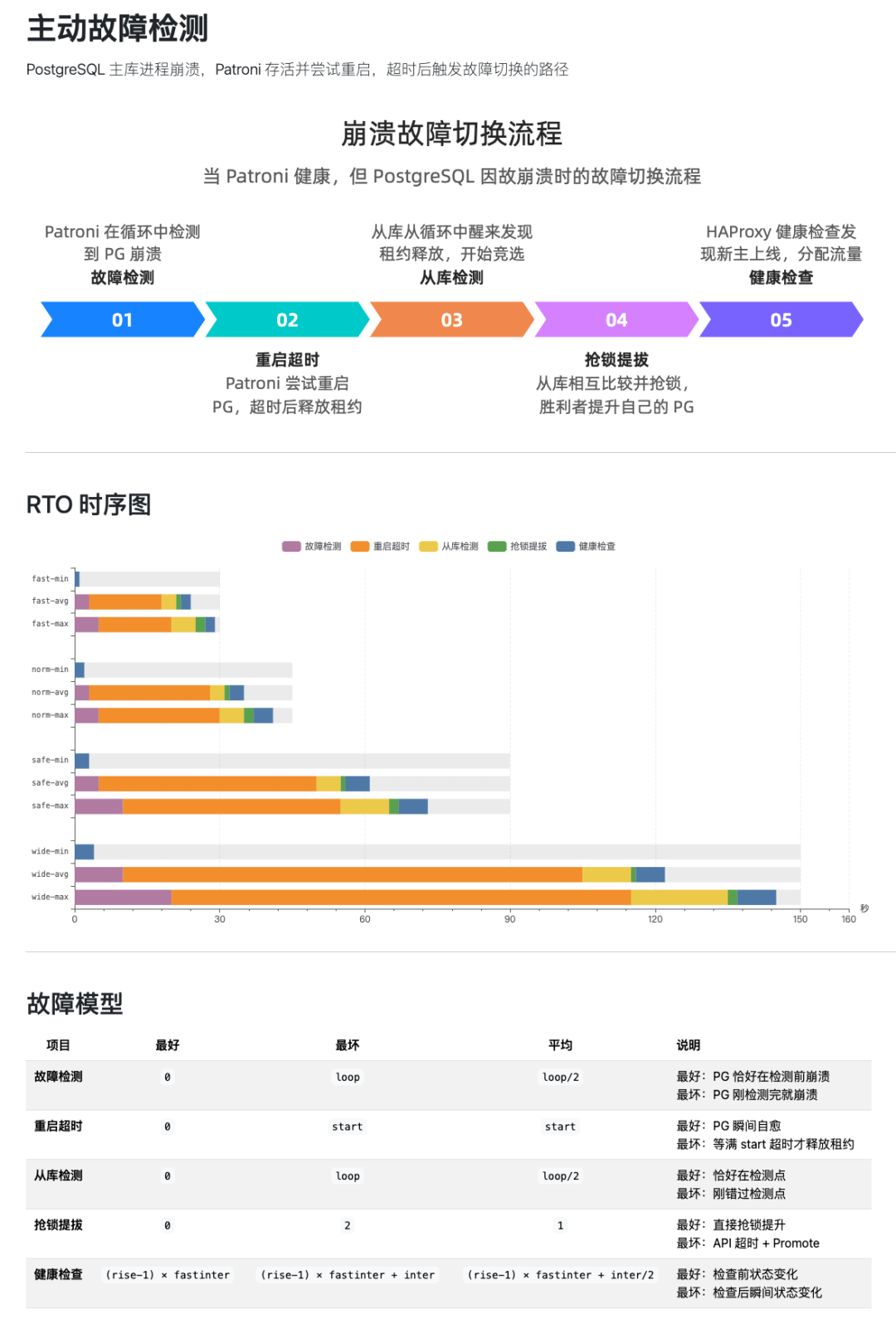
PG进程崩溃,Patroni尝试重启超时场景下的RTO阶段分解与计算模型。
综合两种路径,各模式下的 RTO 表现汇总如下:
fast, norm, safe, wide及Patroni默认模式的目标RTO与实际RTO数据。
生产环境中的一次真实故障切换监控如下图所示,RTO 约 30秒:
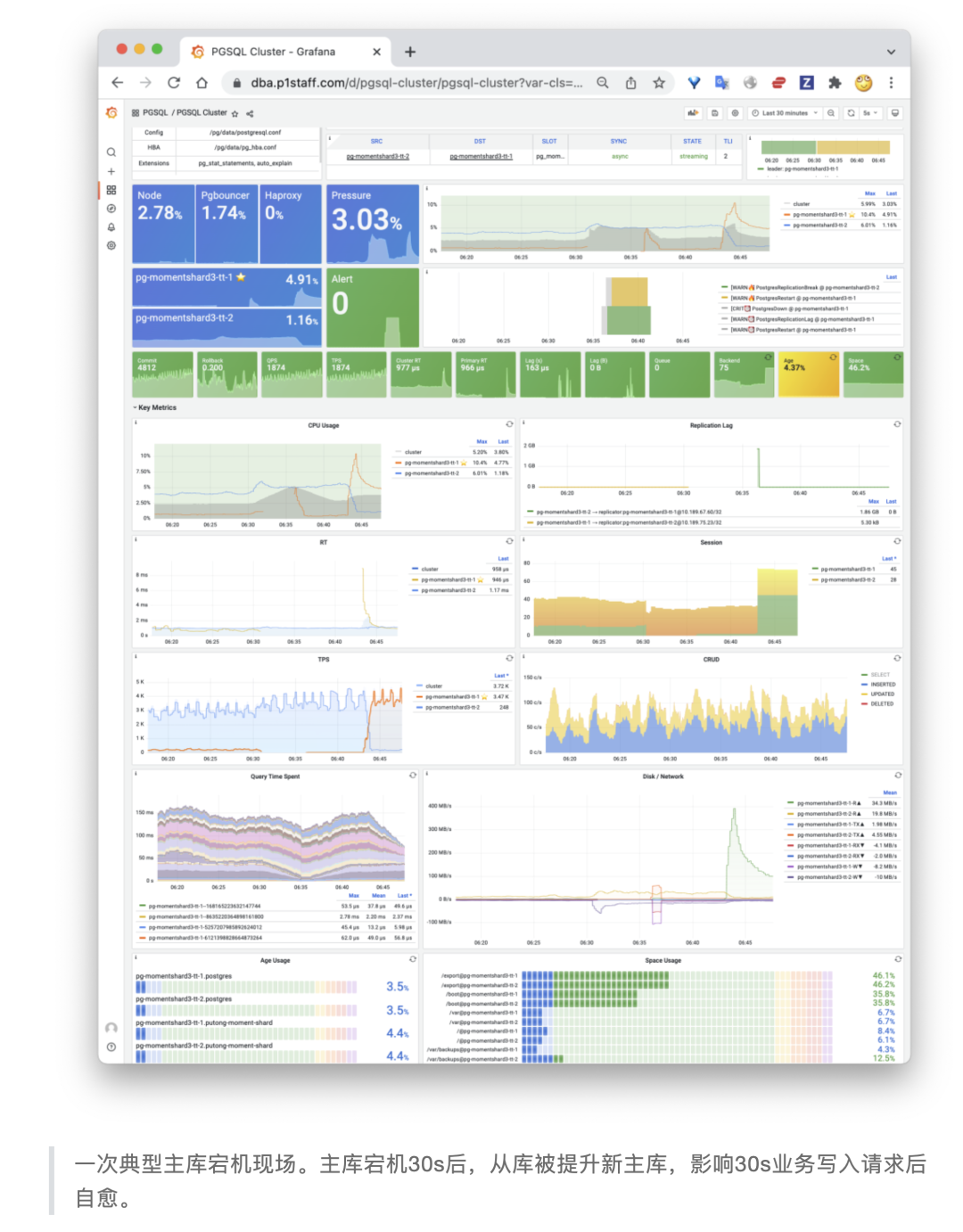
监控显示主库宕机约30秒后,从库被提升,写入服务恢复。
关于其他高可用架构
有些数据库声称 RTO 极低甚至为0,这通常基于共享存储(如 RAC)或分布式共识协议。但这些方案往往只针对特定故障域(如计算节点故障),且会引入其他局限性。例如,共享存储架构将单点风险转移到了存储层,并且难以水平扩展。
相比之下,Patroni 所基于的无共享架构思路更清晰:每个节点独立自治,通过流复制同步数据。这种架构没有存储单点,易于水平扩展(例如可以构建 1 主 N 从的集群),已成为现代数据库高可用的主流选择。
如何快速落地?
理解了原理,但手动配置 Etcd、Patroni、HAProxy 这一整套系统依然繁琐。为此,我将这套经过生产环境验证的方案封装成了开箱即用的解决方案 —— Pigsty。你只需要用简单的 YAML 定义集群,即可一键部署。
pg-test: # 定义新集群 ‘pg-test’
hosts: # 在3个节点上部署3个实例
10.10.10.11: { pg_seq: 1, pg_role: primary }
10.10.10.12: { pg_seq: 2, pg_role: replica }
10.10.10.13: { pg_seq: 3, pg_role: offline }
vars: # 配置数据库参数
pg_cluster: pg-test
pg_vip_address: 10.10.10.3
pg_users: [ { name: test } ]
pg_databases: [ { name: test } ]

左侧的YAML配置对应右侧完整的监控、高可用、连接池等架构组件。
你也可以选择其他集成方案,但核心高可用架构万变不离其宗。Pigsty 的区别在于,它直接提供了针对不同网络条件优化好的 RTO/RPO 策略,并内置了连接池、监控告警等生产必需功能。
最后需要强调,高可用(HA)主要应对硬件和节点故障。对于误删数据、逻辑错误等,还需要依靠备份与点-in-时间恢复(PITR)来兜底。这涉及到另一个事实标准 —— pgBackRest。
总结
通过精细的参数调优,我们可以精确控制 Patroni 的 RTO 上界。在常规网络环境下,30 秒的 RTO 水平是完全可实现的。多年来生产环境中的实际故障切换记录也验证了这一点,RTO 稳定在 20~30 秒区间,足以满足最严苛的容灾要求。
技术选型的核心在于解决问题,而非追求复杂或昂贵。Patroni 以其简洁的架构实现了可靠的 高可用 效果,这正是它成为 PostgreSQL 生态中事实标准的根本原因。希望本文的探讨能帮助你更好地理解和运用这一强大工具。更多关于 PostgreSQL 及后端架构的深度讨论,欢迎关注云栈社区的技术分享。
 发表于 2026-1-25 08:35:29
|
查看: 141|
回复: 0
发表于 2026-1-25 08:35:29
|
查看: 141|
回复: 0
