背景:异构 AI 时代为何需要“可扩展”的编译器
随着人工智能应用规模与复杂度的持续提升,底层计算硬件正呈现出前所未有的多样化趋势。从通用 CPU、GPU,到面向深度学习高度定制的 NPU、TPU,以及不断涌现的专用加速器,不同平台在计算模型、指令集结构、存储层次以及并行执行机制等方面均存在显著差异。
在这一背景下,编译器不再只是“代码生成工具”,而逐渐演变为连接算法表达与硬件能力的核心基础设施。传统依赖“手写内核 + 平台特定优化”的开发模式,虽然在单一硬件上可以获得较高性能,但其开发成本高昂、维护复杂、可移植性差,难以应对硬件快速演进与异构并存的现实需求。
因此,现代 AI 编译器被寄予更高期望:不仅需要具备跨平台能力,还必须在抽象表达与硬件适配之间建立清晰、可扩展的过渡路径。一个理想的 AI 编译器体系,通常应同时具备以下特征:
- 能够以统一的方式表达高层 AI 算法中的并行结构与数据访问语义;
- 支持逐层降低抽象级别,使计算语义能够逐步贴近底层硬件;
- 具备多后端支持能力,并能以较低成本扩展至新硬件架构;
- 允许开发者在关键阶段介入,能够比较容易地对性能敏感部分进行精细化调优。
正是在这一技术演进方向上,Triton 编译器凭借其基于 MLIR 的多层 IR 架构以及灵活的后端扩展机制,逐渐成为异构 AI 算子开发中承上启下的关键工具。
Triton 编译器在整个大模型编译器中所处的角色
在完整的大模型编译体系中,Triton 并不直接面向整张模型计算图,而是承担了介于图级优化与底层指令生成之间的中间层角色。
向上:承接图级编译器的算子下沉
在编译流程的上游,诸如 TorchInductor 等图编译器首先对模型计算图进行全局分析,包括算子融合、调度重排与内存规划等。当图级优化完成后,系统会将其中计算密集、控制复杂或对性能高度敏感的子图下沉至 Triton 处理。
对于 Triton 而言,这些输入不再是语义宽泛的“高层算子”,而是具备明确数据访问模式、并行结构与计算边界的计算问题。这一抽象粒度恰好处于“可表达硬件感知优化”与“保持开发灵活性”之间,为后续的系统化 lowering 提供了理想切入点。
向下:基于 MLIR 的逐层 Lowering 与后端生成
在编译流程的下游,Triton 依托 MLIR 与 LLVM 的基础设施,围绕以下核心问题展开转换与优化:
- 并行语义向线程、向量或 SIMD 执行模型的映射,例如并行语义从
Triton IR 逐步 lowering 到 SCF/Vector/Affine 相关 dialect;
- 显式建模内存层次与访问模式,例如 Triton IR 中的 Tensor Pointer 抽象了张量的内存引用,经过 lowering 转为
MemRef,同时利用 Affine dialect 表示可优化的线性索引访问;
- 将 Triton 算子逐步合法化为目标硬件可接受的硬件指令。
通过多层 Dialect 与 Pass Pipeline 的组合,Triton 将高层算子语义逐步 lowering 为与具体硬件架构强相关的 IR,最终生成 LLVM IR,并交由 LLVM 后端生成目标平台机器码。
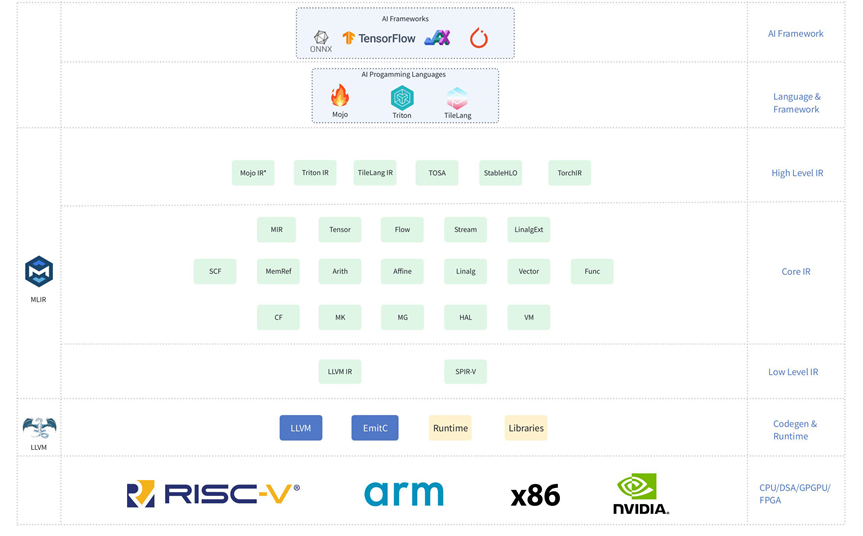
不同硬件后端下的角色体现
在CPU 后端中,Triton 将融合算子转换为显式循环与向量化结构,并结合 RVV、AVX、NEON、AMX 等指令集生成高性能代码; 在GPU后端中,其优化重点转向线程块/warp 级并行建模、共享内存管理以及针对 CUDA/ROCm 执行模型的指令重排。
综合来看,Triton 在大模型编译体系中承担的是一个从模型级语义到硬件级执行的中间层角色:它既不负责整图级的全局优化,也不直接绑定具体硬件指令,而是通过 MLIR 驱动的分层 IR 设计,在性能可控性与架构可扩展性之间建立清晰边界。
MLIR 框架概述:为多层次抽象而生的编译基础设施
传统编译器的局限性
传统编译器(如 LLVM)通常采用单一 IR 来统一承载从高层语言语义到底层机器码的全部信息。这种设计在通用编程语言领域行之有效,但在 AI 编译场景下逐渐显露出局限性:
- 领域特化语义难以表达:AI 计算涉及张量形状、并行模式、数据布局和访存语义等信息,单一底层 IR 难以自然、高效地表示。
- 优化粒度不匹配:传统 Pass 体系集中于函数、基本块以及指令级优化,难以同时覆盖高层算子融合与低层指令选择等不同抽象层次的优化需求。
因此,AI 编译器更适合采用多层次抽象的 IR 与变换体系:在合适的抽象层进行对应优化,实现结构化、可组合、可控的优化流程。
MLIR 核心特性
MLIR(Multi-Level Intermediate Representation)正是为多层抽象而生,其核心理念是:通过多方言(Dialect)和渐进式 lowering,将高层语义逐步降到硬件指令级。主要特性包括:
- Dialect 机制:允许针对不同领域或硬件定义专属 IR 方言,每个方言封装特定类型系统、操作集与语义,使优化灵活且可维护。
- 渐进式 Lowering:高层算子/张量方言可逐步转换为并行向量化方言,再进一步 lowering 到 LLVM IR,实现清晰的语义分层和独立优化空间。
- 高度可扩展:可轻松新增方言和自定义 Pass,以适应新硬件、算子更新或不同计算范式,提升编译器生命力。
MLIR 与 TVM、XLA 的对比
MLIR 并不是一个具体的 AI 编译器,而是一套用于构建编译器的通用基础设施。它通过多层次中间表示以及高度可组合的 dialect 机制,为不同抽象层级上的程序表示、分析与优化提供了统一框架。在 MLIR 之上,开发者可以根据目标场景与硬件特性,构建面向特定领域或特定任务的编译器。
- MLIR 的核心优势在于:允许多个抽象层级的 IR 共存,并通过显式、可控的 lowering 路径将它们连接起来。在较高抽象层级,开发者可以使用 linalg、affine 等偏通用的计算表示,对程序执行与硬件无关的优化,例如循环变换、算子融合、内存访问模式重排以及数据布局调整等;随后,IR 会逐步 lowering 到更接近硬件的 dialect,引入与具体目标架构或厂商相关的指令选择、内存层次管理以及调度策略。这种“先进行通用语义优化,再逐步引入硬件特化”的编译路径,使 MLIR 在 NPU、DSA(Domain-Specific Accelerator)等新型加速器领域具备较强的吸引力。
- 从后端代码生成的角度来看,MLIR 与 LLVM 生态之间具有天然且成熟的衔接能力。通过 MLIR 的 LLVM dialect,编译流程可以将高层 IR 平滑转换为标准的 LLVM IR,从而直接复用 LLVM 在后端代码生成与低层优化方面经过长期验证的能力。这一设计显著降低了构建和维护自研编译后端的工程复杂度,同时也提升了跨平台、多架构支持的可行性与稳定性。
- 从生态与产业实践的角度看,近年来在 Triton Developer Conference、PyTorch Conference 等技术会议中,与 AI 编译器相关的讨论正越来越多地围绕 MLIR 展开。尽管 TVM、XLA 仍在部分场景中发挥着重要作用,但整体趋势逐渐显现:MLIR 正在成为工业界构建可定制 AI 编译器、算子编译框架以及加速器软件栈时的重要基础设施选择。
- 在具体实践中,Triton 是一个构建在 MLIR 之上的、面向单算子优化的领域专用编译器。它强调对算子内部计算过程和内存访问模式的精细控制,是 MLIR 在算子级编译器方向上的典型代表。与 Triton 相比,IREE 同样基于 MLIR 构建,但其关注点更偏向于 模型或子图级别 的整体编译与调度,强调跨设备部署能力以及运行时执行效率,体现了 MLIR 在端到端 AI 模型编译器方向上的应用可行性。
相比之下,TVM 的目标是构建一个“从模型到硬件”的通用深度学习编译器体系。在 TVM 中,深度学习模型通常首先被表示为高层计算图中间表示(如 Relax IR),编译器在这一阶段执行算子融合、布局变换等跨算子的全局优化,以提升整体计算效率。随后,计算图中的算子会逐步 lowering 到更贴近硬件的 TensorIR(TIR)层级,并结合自动调度(Auto Scheduling)与自动调优(Auto Tuning)机制,为特定硬件平台搜索高性能的底层实现方案。TVM 的核心价值在于其面向不同硬件平台的自动化调度与优化能力(Auto Scheduling)。通过 AutoTVM 或 AutoScheduler 等自动调优工具,开发者无需针对不同硬件手工编写复杂的 kernel 实现,系统能够在给定算子描述的基础上,对调度空间进行搜索,并结合性能模型与实际运行反馈,自动生成接近专家级优化水平的代码实现。同时,TVM 对多种前端框架和后端硬件均提供了较为完善的支持。然而,TVM 的系统架构较为复杂,在调试流程和性能分析等方面具有较高的整体学习成本;同时,其固定的 IR 层级设计限制了扩展方式,用户通常只能在现有 IR 基础上进行功能拓展。
XLA 则强调以计算图为中心的整体编译优化路径。它最初与 TensorFlow 深度绑定,主要服务于 TPU 这种专用加速硬件,目标是将由高层深度学习框架构建的完整计算图整体下沉至编译器层进行统一分析与优化。随着 JAX 的兴起,XLA 逐渐从 TensorFlow 的内部组件演变为 JAX 的核心执行引擎,并进一步发展为一个相对通用的深度学习编译基础设施,用于连接前端编程模型与多种后端硬件架构。在执行过程中,XLA 会将模型的完整计算图转换为一种中间表示 —— HLO(High Level Optimizer)。HLO 描述的是一组语义清晰、硬件无关的张量操作,使编译器能够在这一抽象层级上进行跨算子的全局优化。近年来,XLA 的发展逐渐汇聚到更大的生态体系之中,即 OpenXLA。OpenXLA 是一个由 Google 发起并推动的开源项目,旨在将 XLA 从单一框架的后端组件,升级为一个跨框架、跨硬件的统一编译体系。
综合对比可以发现,MLIR、TVM 与 XLA 在定位上并不在同一层级。TVM 和 XLA 更像完整的深度学习编译器系统,而 MLIR 提供的是构建编译器的通用基础设施。
Triton 专注于算子级别的高性能代码生成,需要在保持前端编程模型稳定的同时,对计算过程和内存访问进行精细控制。MLIR 的多层 IR、可插拔 dialect 和渐进式 lowering 机制,正好满足这一需求,使 Triton 能够为不同硬件后端引入定制化编译路径,也为其插件化多后端架构奠定了基础。
Triton 编译器的整体代码结构设计
Triton 编译器在 MLIR 的多层 IR 与 Dialect 机制之上,构建了一套面向 AI Kernel 编程的具体实现方案,其核心设计目标可以概括为:前端统一、后端插件化、运行时延迟绑定。
在这一设计下,Triton 能够在保持统一前端 IR 与用户 API 的前提下,为 CPU、GPU 等异构硬件提供高度特化的编译与执行路径。
Triton 编译器整体结构可划分为五个逻辑层次:Python 抽象层(Frontend)、通用中间表示层(TTIR)、后端特化中间表示层(Backend Dialects)、后端转换与优化层(Lowering)、后端代码生成与运行层(Codegen & Runtime)。
下面以 Triton-CPU 项目为例,对这些层次及其对应的代码结构进行系统性说明。
Python 抽象层
Triton-CPU 项目的 Python 层架构分为三个核心抽象层,共同实现从 Python 代码到可执行内核的完整编译与执行流程:
triton-cpu/python/triton
├── backends
├── compiler
├── runtime
├── ...
1. triton/runtime (运行时抽象层)
负责内核的 JIT 编译编排、执行管理和设备抽象。在 kernel 函数被首次调用时,它会调用编译器层进行编译;编译完成后,通过后端驱动启动内核执行。
2. triton/compiler (编译时抽象层)
这是 Triton 编译器的核心入口:
- 负责将 Python AST 转换为 TTIR(Triton IR),这是 Triton 的最高层 IR,保留张量语义与块级并行抽象。
- compiler.py 中的 compile() 函数编排后端编译流水线,
ast_to_ttir()函数执行从 Python AST 到 TTIR 的转换。
- 编译层还管理
add_stages()后端的 IR 转换阶段,这些阶段的具体实现由后端层提供。
3. triton/backends (后端抽象层)
提供可插拔的后端架构,每个后端(如 CPU、CUDA)实现 BaseBackend 和 DriverBase 接口。后端层定义特定的编译阶段(如 CPU 后端可能使用 MLIR 转换,GPU 后端使用 PTX 生成),并提供设备驱动实现,用于内核加载和执行。这种设计使得 Triton 可以支持多种硬件目标,而编译抽象层和运行时抽象层保持后端无关。
中间表示层:基于 MLIR 的多层 Dialect 体系
采用 MLIR 的 Dialect 机制,定义了多个层次化的 IR:TTIR(Triton Dialect)作为通用前端 IR,定义了高层张量语义与块级并行抽象,TTCIR(TritonCPU Dialect)和 TTGPUIR(TritonGPU Dialect)作为后端特定的中间表示,每个 Dialect 通过 TableGen(.td 文件)定义操作、类型和属性,形成类型安全的 IR 系统。Dialect 定义分布在以下目录:
triton-cpu/include/triton/Dialect
用户也可以在后端添加自定义 Dialect 中间层,此处以 NVIDIA 为例。
triton-cpu/third_party/nvidia/include/Dialect/NVGPU/IR
├── CMakeLists.txt
├── Dialect.h
├── NVGPUAttrDefs.td
├── NVGPUDialect.td
└── NVGPUOps.td
后端转换与优化层:面向硬件的渐进式 Lowering
在 Triton 编译器中,后端层承担将高层算子语义逐步映射到具体硬件指令的职责。这一过程通过一系列系统化的转换(Lowering)与优化 Pass 完成,形成从领域特化 IR 到低层硬件可执行 IR 的渐进式路径。以 CPU 后端为例,其核心设计思想是模块化、多层次和可扩展的优化体系。
从架构角度来看,后端流程可以抽象但不局限为三类主要阶段:
- IR 转换层(高层 Triton IR → 后端 Dialect) 高层 TTIR(Triton Tensor IR)首先被降级为针对目标硬件可分析的中间 Dialect。在这一阶段,编译器引入硬件感知的中间语义,如内存访问模式、标量化操作、点积与归约的结构化表示等,以便后续 Pass 能够高效地执行针对性优化。
- IR 优化层(后端 Dialect 内部优化) 在目标硬件 Dialect 上,编译器执行结构化和硬件特定的优化。优化内容包括内存访问重排、向量化操作合并、掩码操作优化以及将通用数学运算映射到硬件特化指令(如 AMX、FMA 或 Ukernel)。这一层的设计允许编译器根据不同 CPU 特性自动选择最优实现策略。
- IR 降级层(后端 Dialect → LLVM IR / 硬件 IR) 最终,优化后的 Dialect 被逐步降级为 LLVM IR 或其他硬件可执行 IR。在这一阶段,编译器保留向量结构和并行执行信息,同时将高层算子映射为底层内存操作、循环结构和硬件库函数调用,为生成高效机器码做准备。
在实际后端 lowering 的过程中,并不局限于三层设计,而是一个可配置的、模块化的序列。最终目标是系统地、高效地将高级算子语义,经过多次语义转换和硬件特化优化,逐步精确地映射到目标硬件的低级指令和运行时接口上。这部分模块集中在./triton-cpu/third_party目录下,这里以 CPU 为例,简单提供代码结构。
triton-cpu/third_party/cpu/lib
├── Analysis // 分析Pass
├── CMakeLists.txt
├── TritonCPUToLLVM // IR降级Pass
├── TritonCPUTransforms // IR优化Pass
└── TritonToTritonCPU // IR转换Pass
后端代码生成层:LLVM 后端与目标产物生成
third_party/cpu/backend/compiler.py中的(make_asm 和 make_so)将 LLVM IR 通过 LLVM 后端生成目标平台的汇编代码,并最终链接为共享库。
后端运行层:内核加载与执行
triton-cpu/third_party/cpu/backend/driver.py阐述启动代码的生成以及调用真正的内核代码。
基于这一整体流程,后续章节将进一步从具体后端出发,分析这些设计如何在实际的 IR 转换与优化中被逐步落实,并以 Triton-CPU 的 lowering 过程作为示例进行说明。
以 Triton-CPU 为例了解多后端适配
Triton 将后端实现拆分为 Backend(编译器)与 Driver(运行时)两个角色,这一设计并非简单的工程划分,而是为了实现编译与执行解耦。
Backend(BaseBackend):负责编译流程,将 Triton IR 转换为目标代码
Driver(DriverBase):负责运行时设备管理、内核加载与启动
Triton 通过将后端选择推迟到运行时,在运行时触发 JIT 编译过程并根据实际硬件架构绑定唯一后端。借助这种设计,同一套 Triton 程序能够复用统一的前端表示,并在不同硬件平台上于运行时生成适配目标架构的高效代码,从而实现跨平台的无缝运行。
多后端适配中的运行层通过DriverBase抽象基类实例化CPULauncher对象,从而绑定唯一后端BaseBackend、生成启动代码,并在真正运行时根据启动代码调用 Kernel 函数。
多后端适配中的转换与优化层以及后端代码生成层通过 BaseBackend 抽象基类实现(triton.backends.compiler.BaseBackend),每个后端(如 CPUBackend、CUDABackend、HIPBackend)继承该基类并实现 add_stages 方法注册自己的编译阶段。这种设计使得新增后端只需在 third_party 目录下实现相应的 Dialect 定义、转换 Pass 和后端编译器类,而无需修改核心框架。完整的适配流程如下:

从运行时视角看 Triton 的后端插件模型
1. 后端发现与注册机制
Triton 在初始化阶段会通过 _discover_backends() 动态发现所有可用后端(backends)并注册,但此时并不会立即确定具体的后端类型。
2. 运行时驱动激活与后端绑定
驱动激活
真正的后端选择发生在 kernel 首次执行时:Triton 通过 driver.active()里的 _create_driver()查询当前可用设备。通过遍历所有已注册后端,调用各后端的 is_active(),收集返回 True 的驱动,最终据此激活对应的唯一的 Driver 实现(如 CPUDriver)。例如 CPU 后端的 is_active()函数实现如下:
@staticmethod
def is_active():
return True
后端绑定
随后,CPUDriver 通过 get_current_target() 返回包含 backend 信息的 Target 信息,从而找到对应的唯一后端的 BaseBackend,并实例化成 CPUBackend,实现反向绑定其关联的 BaseBackend,从而确定后续的编译流程与运行时执行模型。
def make_backend(target):
actives = [x.compiler for x in backends.values() if x.compiler.supports_target(target)]
if len(actives) != 1:
raise RuntimeError(
f"{len(actives)} compatible backends for target ({target.backend}) ({actives}). There should only be one."
)
return actives[0](target)
例如 CPU 后端的 supports_target 函数实现如下。编译时,通过 make_backend(target) 根据 target 的 backend 字段以及各自后端实现的 supports_target()函数,判断 target.backend 是否是“cpu”,如果是,就绑定 BaseBackend 为 CPUBackend。
def supports_target(target: GPUTarget):
return target.backend == "cpu"
Triton-CPU 的插件化后端实现
当运行时确定当前设备为 CPU 后,Triton 会激活 CPU 后端插件,并将后续的编译与执行流程完全交由 CPUBackend 负责。CPUBackend 通过实现 Triton 定义的统一接口,定义不同编译阶段,并在对应阶段中添加 lowering Pipeline,此时用户就可以根据自己硬件的需求,定义抽象层级的方言、添加自己的优化 Pass 并更改 Pipeline 内部的顺序:
1. 定义编译 stage
通过make_ttir()等函数定义不同编译阶段,并在阶段内添加 MLIR 中的优化或者转换 Pass 。
# triton-cpu/third_party/cpu/backend/compiler.py
class CPUBackend(BaseBackend):
def make_ttir(self, mod, metadata, opt): ...
def make_ttcir(self, mod, metadata, opt): ...
def make_tttcir(self, mod, metadata, opt): ...
def make_llir(self, src, metadata, options): ...
2. 注册 stages
在triton-cpu/third_party/cpu/backend/compiler.py实现add_stages()函数,从而将上述的不同后端的编译阶段收集,供抽象层的 compiler.py 文件中的 compiler()函数调用,实现多后端适配。
def add_stages(self, stages, options):
stages["ttir"] = lambda src, metadata: self.make_ttir(src, metadata, options)
stages["ttcir"] = lambda src, metadata: self.make_ttcir(src, metadata, options)
stages["tttcir"] = lambda src, metadata: self.make_tttcir(src, metadata, options)
stages["llir"] = lambda src, metadata: self.make_llir(src, metadata, options)
stages["asm"] = lambda src, metadata: self.make_asm(src, metadata, options)
stages["so"] = lambda src, metadata: self.make_so(src, metadata, options)
3. 启动代码生成及 kernel 函数运行
# triton-cpu/third_party/cpu/backend/driver.py
class CPUDriver(DriverBase):
def is_active(): ...
def get_current_device(self): ...
def get_device_interface(self): ...
def load_binary(self, name, kernel, shared_mem, device): ...
总的来说:CPUDriver 负责 CPU 设备检测、线程模型管理以及本地二进制的加载与执行,CPUBackend 负责将 Triton IR 逐层 lowering 为面向 CPU 架构的 LLVM IR,并最终生成可执行代码。
这种解耦设计使得 CPU 后端能够作为一个独立插件接入 Triton 框架,而无需修改核心编译器逻辑。
Triton-CPU 基于 MLIR 的多层编译器设计
CPUBackend 基于 MLIR 的多方言与多层转换机制,将通用 Triton IR 逐步特化为面向具体 CPU 架构的 LLVM IR。
1. 中间表示层:方言注册
Triton 编译器方言注册一般是在自己的后端 ./third_party/cpu/include 目录中,通常可以定义后端相关的方言以描述 MLIR 框架中现有的无法抽象的表达。CPU 稍微特殊一点,TritonCPU 方言层级定义在./triton-cpu/include/triton/Dialect/TritonCPU/IR目录下
./triton-cpu/include/triton/Dialect/TritonCPU/IR
├── Attributes.h
├── CMakeLists.txt
├── Dialect.h
├── TritonCPUAttrDefs.td
├── TritonCPUDialect.td
├── TritonCPUInterfaces.h
├── TritonCPUOps.td
├── TritonCPUTypes.td
└── Types.h
Trtion 在 CPU 后端的 lowering 过程中引入了 TritonCPU Dialect,TritonCPU 方言是 “介于 Triton 高层并行/块语义与 LLVM 低层指令语义之间” 的 CPU 语义承载层,用于显式表达向量化、并行映射、访存模式和硬件能力假设,以便在 lowering 之前做 CPU 专属分析与优化。
2. CPU 后端的三层转换架构
CPU 后端的编译流程可划分为三个层次:
第一层:TritonToTritonCPU
该层将 Triton IR(TTIR)往下层 Dialect 翻译,主要包括:
- 标量化处理: 将张量级并行操作转换为基于
scf.for 的标量循环,适配 CPU 的执行模型
- 内存操作转换: 将 Triton 的张量指针语义转换为
memref 与向量加载/存储操作
- 操作特化: 将通用算子(dot、reduction、scan)映射为 TritonCPU dialect 中的对应操作
例如:
struct DotOpConversion :
public OpConversionPattern<triton::DotOp> {
using OpConversionPattern::OpConversionPattern;
LogicalResult
matchAndRewrite(triton::DotOp op, OpAdaptor adaptor,
ConversionPatternRewriter &rewriter) const override {
...
rewriter.replaceOpWithNewOp<cpu::DotOp>(op, a, b, c, op.getInputPrecision(),
op.getMaxNumImpreciseAcc());
return success();
}
};
将 triton IR 层级的 Dot 算子往 triton-cpu 层级的 Dot 算子下降,以便后续优化 pass 分析,从而适配特定的硬件指令。
CPU 架构感知的硬件特化优化
该层在 TritonCPU IR 基础上引入硬件感知的优化策略:
- 矩阵乘法特化
- Intel AMX:
ConvertDotToAMX
- AVX512:
ConvertDotToFMA
- 通用路径:向量外积展开
这一阶段的转换路径并非固定,而是由 CPU 特性动态选择。
例如:triton-cpu/third_party/cpu/lib/TritonCPUTransforms/ConvertDotOp/ConvertDotToAMX.cpp中:
- 先会根据 isAmxCandidate() 检查类型以及形状是否满足 AMX 指令的要求。
bool checkInputShapes(VectorType lhsTy, VectorType resTy){
if (lhsTy.getRank() != 2)
return false;
if (lhsTy.getDimSize(0) < 8 || lhsTy.getDimSize(1) < 8 ||
resTy.getDimSize(1) < 8)
return false;
return true;
}
- 通过 setupBlockAndTileSizes()函数确认 tile 的策略
- 最后通过 convertCandidate()中的 生成 AMX 操作,例如
// 转换后的 TTCIR(包含 AMX 操作)
// 1. 加载 LHS tile
%lhs_tile = amx.tile_load %lhs_buf[%m, %k] :
memref<16x32xbf16> -> !amx.tile<16x32xbf16>
// 2. 加载并打包 RHS tile(AMX 需要 VNNI 格式)
%rhs_tile = amx.tile_load %rhs_buf[%k, %n] :
memref<32x16xbf16> -> !amx.tile<32x16xbf16> // 已打包为 VNNI 格式
// 3. 加载累加器 tile
%acc_tile = amx.tile_load %acc_buf[%m, %n] :
memref<16x16xf32> -> !amx.tile<16x16xf32>
// 4. 执行 AMX 矩阵乘法(硬件加速)
%result_tile = amx.tile_mulf %lhs_tile, %rhs_tile, %acc_tile :
!amx.tile<16x32xbf16>, !amx.tile<32x16xbf16>, !amx.tile<16x16xf32> -> !amx.tile<16x16xf32>
// 5. 存储结果 tile
amx.tile_store %result_tile, %out_buf[%m, %n] :
!amx.tile<16x16xf32>, memref<16x16xf32>
第三层:TritonCPUToLLVM
最终 LLVM IR 生成
最后一层将生成标准 LLVM IR,向量操作会真正映射到 LLVM 向量指令(RISC-V/x86 / ARM)
生成的 LLVM IR 随后交由 LLVM 后端完成目标代码生成。例如
rewriter.replaceOpWithNewOp<amx::x86_amx_tdpfp16ps>(
op, resType, tsza.first, tszb.second, tsza.second, adaptor.getAcc(),
adaptor.getLhs(), adaptor.getRhs());
这里会将 AMX dialect 操作转换为 LLVM intrinsic,最终由 LLVM 后端生成 x86 AMX 指令。
Triton-CPU 后端通过分层的渐进式决策机制,将架构选择拆解为多个阶段,在编译过程中逐步精化优化策略,并在运行时结合实际硬件特性动态调整,实现从高层 IR 到最终机器码的完整 lowering:在 Driver 层首先识别设备类型为 CPU;随后在 Backend 层选择对应的编译器实现(CPUBackend);接着根据 CPU 的特性,如 AMX、AVX 或 NEON,在 Pass 层确定优化路径;最终在 Lowering 层将 IR 收敛为唯一的 LLVM IR 和目标机器码。得益于 MLIR 的多 Dialect 与 Pass 机制,硬件差异的处理被有效推迟到后期,从而在保持灵活性的同时提升性能。结合运行时的后端激活策略和分层编译架构,Triton 构建了一个高度解耦、可扩展的多后端适配方案,这不仅降低了新增后端的工程成本,也为异构硬件平台释放了更大的性能潜力。
总结
在异构 AI 硬件快速演进的背景下,编译器的可扩展性正成为性能之外的关键指标。Triton 通过引入 MLIR、多层 IR 以及插件化后端机制,在统一抽象与硬件特化之间建立了一条清晰、可演进的编译路径。
通过“延迟绑定 + 分层 lowering + 后端插件”的系统设计思路,Triton 能够在保持统一前端语义的同时,为不同硬件后端提供独立、可定制的优化与代码生成流程,在性能可控性与工程可扩展性之间取得良好平衡。这种以架构分层而非条件分支为核心的多后端适配思路,为面向未来异构 AI 计算环境的编译器设计提供了具有实践价值的参考。
 发表于 2026-1-25 13:01:56
|
查看: 338|
回复: 0
发表于 2026-1-25 13:01:56
|
查看: 338|
回复: 0
