作为Linux内核异步I/O的明星方案,io_uring凭借零拷贝队列、无系统调用开销等特性,被奉为高并发场景的性能王者。而mmap作为经典的内存映射技术,看似只是通用文件操作工具,却在实测中意外领先io_uring。这一反差让不少开发者感到困惑:新一代异步框架真的不敌传统技术吗?真相远比表面的性能数值更为复杂。
在追求极致I/O效率的赛道上,mmap技术早已凭借其独特的内存映射机制脱颖而出,成为突破文件I/O瓶颈的利器。它跳过了传统I/O在内核态与用户态间的数据拷贝流程,将文件直接映射到进程地址空间,让数据读写近乎内存操作,大幅降低了开销。而io_uring的性能表现不佳,往往并非技术本身存在不足,更多是因为未能精准匹配业务场景,或是忽略了内核调度等隐性因素。理解mmap的优化密码,理清两种技术的适用边界,才能真正避开I/O性能陷阱,让系统在高并发读写场景下稳定输出极致效能。
一、初识mmap技术
mmap即 memory map,也就是内存映射。它是一种内存映射文件的方法,将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写“脏页面”到对应的文件磁盘上,从而完成了对文件的操作而不必再调用read、write等系统调用函数。相反,内核空间对这段区域的修改也直接反映到用户空间,从而可以实现不同进程间的文件共享。
你可以把mmap理解成一个超级“翻译官”,它能够将文件或者设备的“语言”,精准无误地翻译成进程能够轻松理解的虚拟地址空间“语言”。通过这种“翻译”,进程就能够像访问内存一样,直接对文件或设备进行高效操作。这就像你原本需要通过复杂的流程(传统I/O操作)才能拿到图书馆里的书,现在有了mmap这个“翻译官”,你可以直接在自己的“书房”(进程虚拟地址空间)里快速找到并阅读这本书。
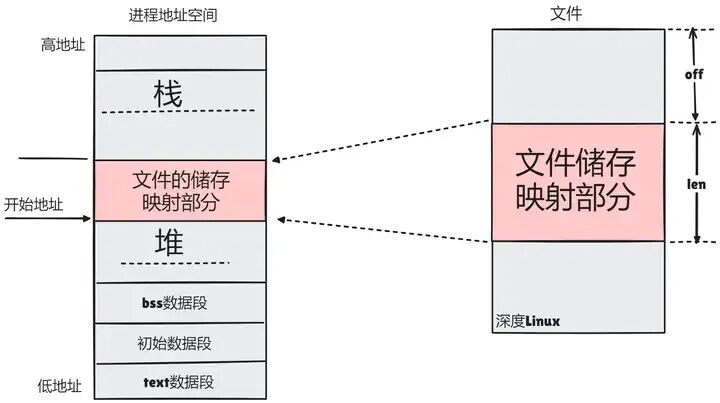
mmap的作用,在应用层看来,是让你把文件的某一段,当作内存一样来访问。它将文件映射到物理内存,将进程的虚拟空间映射到那块内存。这样,进程不仅能像访问内存一样读写文件,当多个进程映射同一文件时,还能保证虚拟空间映射到同一块物理内存,达到内存共享的目的。
mmap是Linux中一个用途非常广泛的系统调用。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。mmap必须以PAGE_SIZE为单位进行映射,而内存也只能以页为单位进行映射,若要映射非PAGE_SIZE整数倍的地址范围,需要先进行内存对齐,强行以PAGE_SIZE的倍数大小进行映射。
mmap的函数原型如下(在Linux/Unix系统中):
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
int munmap(void *addr, size_t length);
void *addr:建议的映射起始地址。通常设为NULL(由内核自动选择合适地址),也可指定特定地址(需对齐内存页,且可能被内核调整或拒绝)。size_t length:映射区域的长度(字节)。实际会按内存页大小(如4KB)向上取整。int prot:保护模式,控制内存访问权限,可组合使用PROT_READ(可读)、PROT_WRITE(可写)、PROT_EXEC(可执行)和PROT_NONE(不可访问)。int flags:指定映射类型和特性,常用组合包括MAP_SHARED(修改同步到文件并共享)、MAP_PRIVATE(写时复制私有映射)、MAP_ANONYMOUS(匿名内存分配)、MAP_FIXED(强制指定地址)等。int fd:文件描述符。若为匿名映射(使用MAP_ANONYMOUS),此参数设为-1。off_t offset:文件映射的偏移量,必须为内存页大小的整数倍。- 成功时返回映射区域的起始地址,失败时返回
MAP_FAILED(即(void *) -1),可通过errno获取错误原因。
示例代码片段:
// 匿名私有映射(分配内存)
void *mem = mmap(NULL, 4096, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (mem == MAP_FAILED) {
perror("mmap failed");
}
// 文件共享映射
int fd = open("file.txt", O_RDWR);
void *file_mem = mmap(NULL, file_size, PROT_READ | PROT_WRITE,
MAP_SHARED, fd, 0);
在使用内存映射时,需要注意以下几点:首先,offset参数必须是对齐的,即其值应为系统页大小(可通过sysconf(_SC_PAGE_SIZE)获取)的整数倍;其次,映射完成后应使用munmap(void *addr, size_t length)及时释放映射区域以避免资源泄漏;最后,若为文件映射并涉及数据持久化,建议通过msync()将修改同步到磁盘,确保数据落盘。
内存映射的基本步骤如下:
- 打开文件:使用
open()系统调用打开目标文件,获取文件描述符fd。
- 建立映射:通过
mmap()将文件映射到进程的地址空间,返回映射区域的首地址指针start。
- 操作数据:通过指针
start直接读写内存,实现对文件的访问或修改。
- 解除映射:操作完成后,调用
munmap(start, length)释放映射的内存区域。
- 关闭文件:最后使用
close(fd)关闭文件描述符。
在实际应用中,mmap的用途十分广泛,主要体现在以下几个方面:
- 共享内存:多个进程可以通过
mmap映射同一文件,实现内存共享,就像多个人可以同时阅读同一本书并对其进行标记,彼此之间的修改都能实时看到,这在进程间通信、数据共享等场景中发挥着重要作用。
- 零拷贝I/O:
mmap减少了数据在用户空间和内核空间之间的拷贝次数,提升了I/O性能,这对于处理大文件、高并发I/O等场景意义重大。例如在文件传输中,传统方式需要多次拷贝数据,而mmap可以直接将文件映射到内存,减少了数据的搬运,大大提高了传输效率。
二、mmap工作原理
mmap的工作原理精妙而复杂,涉及用户态与内核态的协同、虚拟内存管理等多个层面,其核心依赖Linux内核的虚拟内存区域管理机制。其完整实现过程可分为三个阶段。
2.1 创建虚拟内存映射:搭建地址“桥梁”
这一阶段的核心是在进程虚拟地址空间中开辟专属区域,并通过内核数据结构建立虚拟地址与文件/设备的关联。
首先,进程在用户空间调用mmap库函数发起映射请求。内核收到请求后,会先在当前进程的虚拟地址空间中,寻找一段满足长度要求、连续且空闲的虚拟地址。接着,为这片区域分配一个vm_area_struct结构——这是Linux内核用于描述独立虚拟内存区域的核心数据结构。
内核会初始化vm_area_struct的各项字段,包括区域的起始地址、结束地址、内存保护权限、映射模式等;同时,其内部的vm_ops指针会关联对应操作集。最后,内核将这个新建的vm_area_struct插入进程的虚拟地址区域链表或树中,完成虚拟区间的创建。
2.2 建立虚实地址映射:打通内核与文件关联
虚拟区间创建完成后,内核会调用自身的系统调用函数mmap,实现虚拟地址与文件物理地址的一一映射。
具体流程为:内核通过用户态传入的文件描述符fd,找到对应的struct file结构体。通过struct file可关联到文件的file_operations模块,触发内核mmap函数执行。随后,内核借助虚拟文件系统的inode模块,通过文件的inode信息定位到文件在磁盘上的物理地址。最后,调用remap_pfn_range函数建立页表,将vm_area_struct描述的虚拟地址区域与文件的磁盘物理地址绑定。至此,地址映射关系正式建立,但此时没有任何文件数据被拷贝到物理内存,虚拟地址仅为“空壳”,等待实际访问时填充数据。
2.3 延迟加载与同步:触发数据拷贝与回写
前两个阶段仅完成了地址层面的映射,真正的文件数据读写,要等到进程访问映射区域时才会触发,核心依赖缺页异常机制与脏页同步策略。
当进程第一次访问映射区域的虚拟地址时,CPU会查询页表,发现该虚拟地址尚未关联物理内存页,随即引发缺页异常。内核捕获异常后,会先进行合法性校验,确认无非法操作后,发起请求调页过程。
调页过程会先在交换缓存空间(swap cache)中查找目标内存页,若未找到,则调用nopage函数,将文件对应磁盘地址的数据拷贝到物理内存页中,同时更新页表。之后,进程即可正常读写这片物理内存。
数据同步则分两种场景:若采用MAP_SHARED模式,进程对内存的修改会标记该物理页为“脏页”,系统会在合适时机自动回写脏页面到文件对应的磁盘地址;若为MAP_PRIVATE模式,采用写时复制策略,进程写操作时内核会分配新物理页拷贝原始数据,修改仅在当前进程生效,不影响原文件。此外,也可调用msync()函数强制同步。
最后总结:mmap内存映射的实现是一个包含三个核心阶段的完整流程。首先,内核分配并初始化vm_area_struct结构体,为进程虚拟地址空间开辟空闲区域。接着,内核建立页表,将虚拟地址与文件磁盘物理地址绑定。最后,当进程访问映射地址时触发缺页异常,内核将磁盘数据加载到物理内存,修改后的数据可通过系统自动回写或主动调用msync()同步到文件。
三、mmap的I/O模型
3.1 mmap I/O模型的核心特性
传统read/write标准I/O流程需经历两次数据拷贝和两次系统调用:当进程调用read读取文件时,内核先将磁盘数据拷贝到内核态缓冲区(第一次拷贝),再从内核态缓冲区拷贝到用户态缓冲区(第二次拷贝);写入流程则相反。
这种模式的问题在于“冗余拷贝”,且每次系统调用都会触发用户态与内核态的上下文切换,高频I/O场景下开销巨大。而mmap彻底重构了I/O流程,通过“内存映射”将文件直接映射到进程虚拟地址空间,实现了“用户态直接操作内存,内核态自动同步数据”的模式,其核心特性可概括为三点:
- 无冗余拷贝:
mmap仅需一次数据拷贝——缺页异常时内核将磁盘数据拷贝到物理内存,之后进程直接操作该物理内存对应的虚拟地址,相比传统I/O减少一次核心拷贝。
- 弱化系统调用:映射建立后,进程通过指针读写内存即可完成文件操作,无需反复调用
read/write。仅在建立映射(mmap)和解除映射(munmap)时需要系统调用。
- 延迟加载与缓存复用:
mmap采用“按需加载”策略,避免一次性加载大文件导致的内存浪费;同时,加载到物理内存的数据会被系统缓存复用,多个进程映射同一文件时可共享同一份物理内存页。
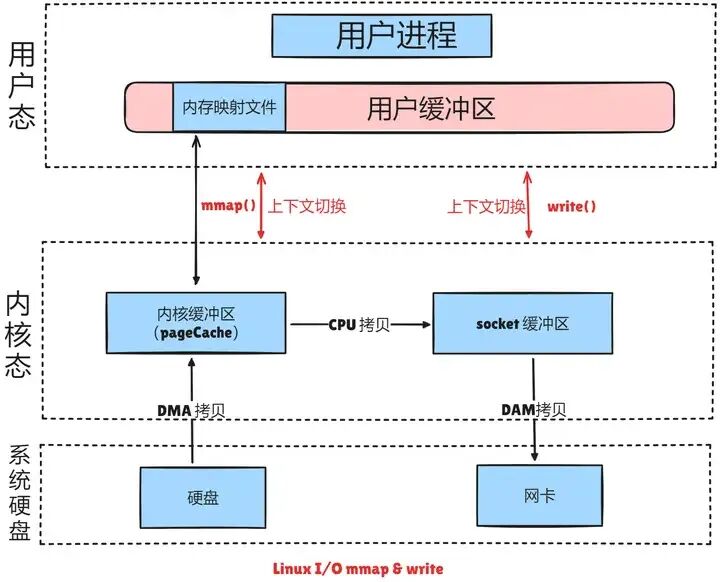
mmap也是一种零拷贝技术,其I/O模型如下图所示:
为更清晰区分,我们通过核心维度对比三种主流I/O模型:
- 标准I/O(read/write):两次数据拷贝、多次系统调用,依赖内核缓冲区缓存,适用于小文件、低频次I/O场景,编程简单但性能一般。
- 直接I/O(O_DIRECT):一次数据拷贝(磁盘→用户态),无内核缓冲区参与,适用于数据库等需自主管理缓存的场景,性能优于标准I/O,但需处理缓存一致性问题。
- mmap映射I/O:一次数据拷贝(磁盘→物理内存),极少系统调用,依赖内核缓冲区与缺页机制,适用于大文件、高频次I/O、进程间共享数据场景,性能最优但需注意内存管理与同步问题。
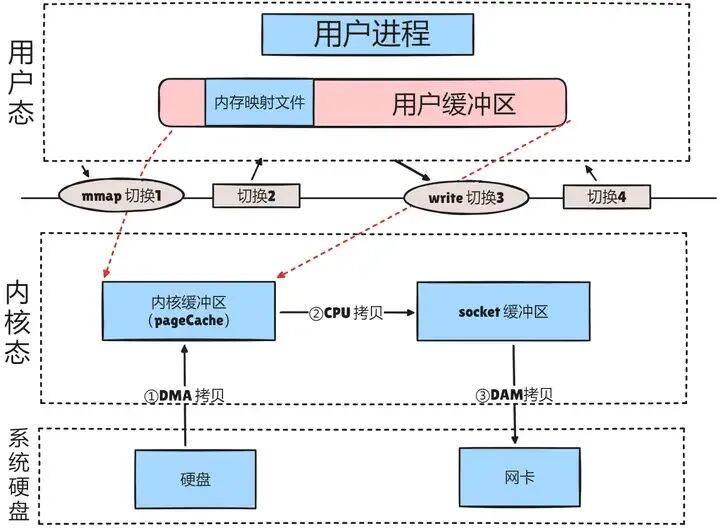
mmap技术有如下特点:
- 利用DMA技术来取代CPU进行内存与其他组件之间的数据拷贝,例如从磁盘到内存,从内存到网卡;
- 用户空间的
mmap file使用虚拟内存,实际上并不占据物理内存,只有在内核空间的kernel buffer cache才占据实际的物理内存;
mmap()函数需要配合write()系统调用进行配合操作,因此也至少需要4次上下文切换;mmap仅仅能够避免内核空间到用户空间的全程CPU负责的数据拷贝,但是内核空间内部还是需要全程CPU负责的数据拷贝;
利用mmap()替换read(),配合write()调用的整个流程如下:
- 用户进程调用
mmap(),从用户态陷入内核态,将内核缓冲区映射到用户缓存区;
- DMA控制器将数据从硬盘拷贝到内核缓冲区(使用了Page Cache机制);
mmap()返回,上下文从内核态切换回用户态;- 用户进程调用
write(),尝试把文件数据写到内核里的套接字缓冲区,再次陷入内核态;
- CPU将内核缓冲区中的数据拷贝到的套接字缓冲区;
- DMA控制器将数据从套接字缓冲区拷贝到网卡完成数据传输;
write()返回,上下文从内核态切换回用户态。
通过mmap实现的零拷贝I/O进行了4次用户空间与内核空间的上下文切换,以及3次数据拷贝;其中3次数据拷贝中包括了2次DMA拷贝和1次CPU拷贝。
3.2 mmap与常规文件操作的区别
在常规文件读写操作中,操作系统通常采用页缓存机制。读文件时,数据首先从磁盘复制到内核空间的页缓存中,再复制到用户空间的内存中;写文件时,用户空间的数据也需要先复制到内核空间的缓冲区,之后再写入磁盘。这两种情况均涉及两次数据拷贝。
相比之下,使用mmap进行文件操作时,在建立映射阶段并不发生实际的数据拷贝。只有当进程首次访问被映射的区域并触发缺页异常时,系统才会将对应的文件数据从磁盘直接加载到用户空间的内存中。这一过程仅需一次数据拷贝。
例如,在进程间通信场景中,多个进程可以通过mmap映射同一文件到各自的地址空间,共享同一段内存区域。访问该区域时只需一次从磁盘到内存的数据拷贝即可实现数据的快速共享与传递。
总结而言:常规文件操作涉及 “磁盘 → 页缓存 → 用户空间” 的两次拷贝;而mmap则通过映射机制实现了 “磁盘 → 用户空间” 的一次拷贝。其核心优势在于让用户空间能够直接与内核管理的文件数据进行交互,避免了不同地址空间之间多次复制的开销。
3.3 mmap不是银弹
mmap也有其缺陷,在相关场景下的性能存在不足:
- 由于
mmap使用时必须指定好内存映射的大小,因此不适合变长文件。
- 如果更新文件的操作很多,
mmap避免两态拷贝的优势就被摊还,最终还是落在了大量的脏页回写及由此引发的随机I/O上,所以在随机写很多的情况下,mmap方式在效率上不一定会比带缓冲区的一般写快。
- 读/写小文件(例如16K以下的文件),
mmap与通过read系统调用相比有着更高的开销与延迟;同时mmap的刷盘由系统全权控制,但是在小数据量的情况下由应用本身手动控制更好。
mmap受限于操作系统内存大小:例如在32-bits的操作系统上,虚拟内存总大小也就2GB,但由于mmap必须要在内存中找到一块连续的地址块,此时你就无法对4GB大小的文件完全进行mmap,必须分块映射,引入了额外的复杂性。
四、mmap技术的优势
4.1 简化用户进程编程
在用户空间看来,通过mmap机制以后,磁盘上的文件仿佛直接就在内存中,把访问磁盘文件简化为按地址访问内存。这样一来,应用程序自然不需要使用文件系统的write、read、fsync等系统调用,因为现在只要面向内存的虚拟空间进行开发。但是,这并不意味着我们不再需要进行这些系统调用,而是说这些系统调用由操作系统在mmap机制的内部封装好了。
- ①基于缺页异常的懒加载:出于节约物理内存以及
mmap方法快速返回的目的,mmap映射采用懒加载机制。具体来说,通过mmap申请1000G内存可能仅仅占用了100MB的虚拟内存空间。当你访问相关内存地址时,才会进行真正的write、read等系统调用,此时才会发生真正的物理内存分配。
- ②数据一致性由OS确保:当发生数据修改时,内存出现脏页。
mmap机制下由操作系统自动完成内存数据落盘(脏页回刷),用户进程通常并不需要手动管理数据落盘。
4.2 避免只读操作时的swap操作
虚拟内存带来了种种好处,但是一个最大的问题在于所有进程的虚拟内存大小总和可能大于物理内存总大小,因此当操作系统物理内存不够用时,就会把一部分内存swap到磁盘上。
在mmap下,如果虚拟空间没有发生写操作,那么由于通过mmap操作得到的内存数据完全可以通过再次调用mmap操作映射文件得到。但是,通过其他方式分配的内存,在没有发生写操作的情况下,操作系统并不知道如何简单地从现有文件中恢复内存数据,因此必须将内存swap到磁盘上。
- 高效的I/O操作方式,尤其在处理大文件或频繁访问文件内容时性能优势明显。
- 减少CPU和内存开销,具有更好的内核态数据传输效率。它避免了内核缓冲区和用户空间缓冲区之间的数据复制。
- 提升系统整体性能,改善用户体验。合理地利用
mmap技术,能够加速文件访问、减少内存拷贝、提高数据传输效率。
五、io_uring性能被mmap“吊打”的原因
5.1 原理层面差异
从原理上看,io_uring与mmap有着本质的不同。io_uring基于环形队列实现异步I/O,它通过提交队列(SQ)和完成队列(CQ)在用户态和内核态之间传递I/O请求和结果。应用程序将I/O请求填充到提交队列项(SQE)中,然后通过系统调用(如io_uring_enter)通知内核处理。内核从SQ中获取请求,执行I/O操作,再将结果放入完成队列项(CQE)并置于CQ。虽然io_uring通过这种方式减少了部分系统调用开销,但每次I/O操作仍涉及到系统调用,并且需要维护环形队列的状态等额外操作。
而mmap则是将文件直接映射到进程的虚拟地址空间,使得对文件的访问就如同对内存的访问一样。在这个过程中,进程可以直接读写映射的内存区域,无需进行额外的系统调用(除了最初的mmap调用和最后的munmap调用)。例如,在一个需要频繁读取文件中固定位置数据的场景中,使用mmap,进程可以直接通过内存指针访问该位置的数据,而使用io_uring则需要构建I/O请求,通过系统调用将请求发送到内核,内核处理后再返回结果,这一系列操作带来的开销在这种简单的内存访问场景下就显得多余了。
5.2 应用场景特性
io_uring和mmap在不同的应用场景下表现各异。io_uring适用于高并发的I/O场景,特别是当有大量I/O请求需要同时处理时,它的异步特性和批量提交、处理能力能够充分发挥优势。比如在一个大规模的文件服务器中,众多客户端同时请求读取不同的文件片段,io_uring可以高效地管理这些请求,让内核并行处理多个I/O操作,从而提高整体的吞吐量。
然而,在某些特定场景下,mmap却更具优势。例如在频繁进行小数据量读写的场景中,mmap的性能往往优于io_uring。假设一个应用程序需要频繁读取配置文件中的少量数据(几字节到几十字节)。对于io_uring来说,每次构建I/O请求、通过系统调用提交请求以及从完成队列获取结果的开销相对较大。而mmap将文件映射到内存后,直接通过内存访问获取数据,速度更快。再比如在一些对实时性要求极高的场景中,mmap由于减少了系统调用的等待时间,能够更快地响应数据请求。
5.3 使用方式不当
io_uring性能不佳有时也可能是由于使用方式不当造成的。io_uring的配置参数较为复杂,如果配置不合理,可能无法发挥其优势。例如,提交队列和完成队列的大小设置不当,可能导致队列溢出或未满时就频繁进行系统调用。此外,io_uring的请求设计也很关键,如果请求的合并和拆分策略不合理,会增加内核处理的复杂性。比如在一个需要顺序读取大文件的场景中,如果每次只提交很小的I/O请求,而不是将多个小请求合并成较大的请求进行批量提交,就会导致系统调用次数增多,降低整体性能。
相比之下,mmap的使用方式相对简单直接,只要正确映射文件并进行内存操作即可。只要遵循基本的使用规范,一般不会因为使用方式而导致明显的性能问题。
5.4 性能测试对比
为了准确地测试io_uring和mmap的性能,我们搭建了测试环境:使用一台配备高性能CPU、大内存和NVMe SSD的服务器,操作系统为Ubuntu 20.04 LTS(内核5.15),使用GCC 9.4和liburing 2.3库。
我们设计了以下测试用例:
- 小文件随机读写测试:准备1000个大小为1KB的小文件,分别使用
io_uring和mmap进行随机读写操作。
- 大文件顺序读写测试:选取一个大小为1GB的大文件,分别使用
io_uring(批量提交)和mmap进行顺序读写。
- 混合读写测试:模拟实际应用中既有小文件读写又有大文件读写的场景。
通过测试,我们得到了如下数据:
| 测试用例 |
io_uring 耗时(s) |
mmap 耗时(s) |
io_uring 带宽(MB/s) |
mmap 带宽(MB/s) |
| 小文件随机读写 |
1.2 |
0.8 |
0.83 |
1.25 |
| 大文件顺序读写 |
2.5 |
3.0 |
400 |
333.33 |
| 混合读写 |
3.0 |
2.2 |
- |
- |
从测试结果可以看出:
- 在小文件随机读写测试中,
mmap的性能明显优于io_uring,耗时更短,带宽更高。这是因为小文件随机读写时,io_uring构建和提交I/O请求的开销相对较大,而mmap直接通过内存访问,避免了这些开销。
- 在大文件顺序读写测试中,
io_uring的性能略优于mmap,带宽更高,耗时更短。这得益于io_uring的批量提交和异步处理能力,能够充分利用内核的并行处理能力。
- 在混合读写测试中,
mmap再次展现出更好的性能,耗时比io_uring短。这说明在复杂的I/O场景下,mmap的稳定性和高效性更具优势。
六、mmap技术的应用场景
6.1 内存映射I/O,加速文件读写操作,适合处理大文件。
mmap可以将文件直接映射到进程的虚拟地址空间,避免了传统文件读写中的多次系统调用和数据拷贝。在处理大文件时,这种方式尤其有效。通过内存映射,进程可以像访问内存一样访问文件数据,减少了磁盘I/O的开销。虽然读写过程中可能会触发缺页中断,但对于大文件的处理,mmap仍然具有很大的优势。
6.2 进程间通信,多个进程可通过共享内存实现快速通信。
多个进程可以通过mmap映射同一文件到各自的地址空间,共享同一块物理内存,实现进程间快速通信。这种方式比传统的管道、消息队列等IPC方式速度更快,因为数据不需要在内核和用户空间之间多次拷贝。
6.3 内存分配,匿名映射可提供比malloc更灵活的内存管理机制。
当需要大块的内存,或者特定对齐要求的内存时,mmap的匿名映射可以提供比malloc更灵活的内存管理机制。例如,当需要分配的内存大于一定阈值(如128KB)时,glibc会默认使用mmap代替brk来分配内存。共享匿名映射也可以让相关进程(如父子进程)共享一块内存区域。
七、如何使用mmap技术
7.1 mmap使用细节
使用mmap需要注意的一个关键点是,映射区域大小必须是物理页大小(page_size,通常4KB)的整倍数。因为内存的最小粒度是页,进程虚拟地址空间和内存的映射也是以页为单位。
内核可以跟踪被内存映射的底层对象(文件)的大小,进程可以合法地访问在当前文件大小以内又在内存映射区以内的那些字节。映射建立之后,即使文件关闭,映射依然存在。因为映射的是磁盘的地址,不是文件本身,和文件句柄无关。
在上面的知识前提下,我们下面看看如果大小不是页的整倍数的具体情况:
①情形一:一个文件的大小是5000字节,mmap函数从一个文件的起始位置开始,映射5000字节到虚拟内存中。
分析:因为单位物理页面的大小是4096字节,虽然被映射的文件只有5000字节,但是对应到进程虚拟地址区域的大小需要满足整页大小,因此mmap函数执行后,实际映射到虚拟内存区域8192个字节,5000~8191的字节部分用零填充。映射后的对应关系如下图所示:
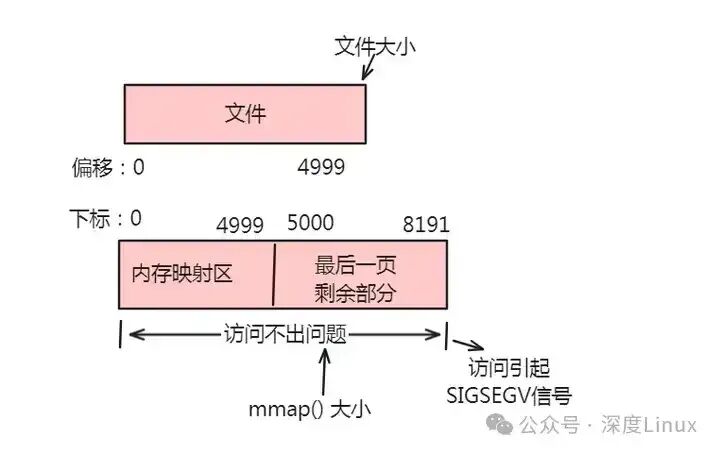
此时:
(1)读/写前5000个字节(0~4999),会返回操作文件内容。
(2)读字节5000~8191时,结果全为0。写5000~8191时,进程不会报错,但是所写的内容不会写入原文件中。
(3)读/写8192以外的磁盘部分,会返回一个SIGSEGV错误。
②情形二:一个文件的大小是5000字节,mmap函数从一个文件的起始位置开始,映射15000字节到虚拟内存中,即映射大小超过了原始文件的大小。
分析:由于文件的大小是5000字节,其对应两个物理页。这两个物理页都是合法可以读写的,只是超出5000的部分不会体现在原文件中。由于程序要求映射15000字节,而文件只占两个物理页,因此8192字节~15000字节都不能读写,操作时会返回异常。如下图所示:
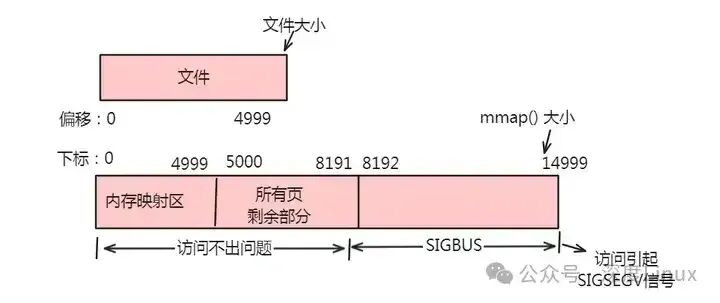
此时:
(1)进程可以正常读/写被映射的前5000字节(0~4999),写操作的改动会在一定时间后反映在原文件中。
(2)对于5000~8191字节,进程可以进行读写过程,不会报错。但是内容在写入前均为0,另外,写入后不会反映在文件中。
(3)对于8192~14999字节,进程不能对其进行读写,会报SIGBUS错误。
(4)对于15000以外的字节,进程不能对其读写,会引发SIGSEGV错误。
③情形三:一个文件初始大小为0,使用mmap操作映射了1000*4K的大小,即约4M字节空间,mmap返回指针ptr。
分析:如果在映射建立之初,就对文件进行读写操作,由于文件大小为0,并没有合法的物理页对应,会返回SIGBUS错误。但是,如果每次操作ptr读写前,先增加文件的大小,那么ptr在文件大小内部的操作就是合法的。例如,文件扩充4096字节,ptr就能操作ptr ~ [ (char)ptr + 4095]的空间。只要文件扩充的范围在1000个物理页(映射范围)内,ptr都可以对应操作相同的大小。这样,方便随时扩充文件空间,随时写入文件,不造成空间浪费。
7.2 函数定义及参数解释
在Linux中,mmap函数定义如下:void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);。参数解释如下:
addr:希望映射的起始地址,通常为NULL,表示由内核决定映射的地址。length:映射区域的大小(以字节为单位)。prot:映射区域的保护权限。常见的权限选项包括:PROT_READ(可读)、PROT_WRITE(可写)、PROT_EXEC(可执行)、PROT_NONE(无权限)。flags:映射的类型和行为控制。常见的标志包括:MAP_SHARED(共享映射)、MAP_PRIVATE(私有映射)、MAP_ANONYMOUS(匿名映射)。fd:文件描述符,指向要映射的文件。如果使用匿名映射,应将fd设置为-1,并且需要设置MAP_ANONYMOUS标志。offset:文件映射的偏移量,必须是页面大小的整数倍。
返回值:返回映射区域的起始地址,如果映射失败,则返回MAP_FAILED。
7.3 mmap映射过程与适用场景
在内存映射的过程中,并没有实际的数据拷贝,文件没有被载入内存,只是逻辑上被放入了内存。mmap()会返回一个指针ptr,它指向进程逻辑地址空间中的一个地址。要操作其中的数据,必须通过MMU将逻辑地址转换成物理地址。当MMU在地址映射表中无法找到与ptr相对应的物理地址时,将产生一个缺页中断,中断响应函数会通过mmap()建立的映射关系,从硬盘上将文件读取到物理内存中。
mmap内存映射的实现过程:
- 进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域。
- 调用内核空间的系统调用函数
mmap,实现文件物理地址和进程虚拟地址的一一映射关系。
- 进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝。
适合的场景
- 您有一个很大的文件,其内容您想要随机访问一个或多个时间。
- 您有一个小文件,它的内容您想要立即读入内存并经常访问。这种技术最适合那些大小不超过几个虚拟内存页的文件。
- 您需要在内存中缓存文件的特定部分。文件映射消除了缓存数据的需要,这使得系统磁盘缓存中的其他数据空间更大。当随机访问一个非常大的文件时,通常最好只映射文件的一小部分。
不适合的场景
- 您希望从开始到结束的顺序从头到尾读取一个文件。
- 这个文件有几百兆字节或者更大。将大文件映射到内存中会快速地填充内存,并可能导致分页。
- 该文件大于可用的连续虚拟内存地址空间。对于32位应用程序来说,这是一个问题。
- 该文件位于可移动驱动器或网络驱动器上。
示例代码 (Objective-C / macOS/iOS)
//
// ViewController.m
// TestCode
//
// Created by zhangdasen on 2020/5/24.
// Copyright © 2020 zhangdasen. All rights reserved.
//
#import "ViewController.h"
#import <sys/mman.h> // 内存映射相关头文件
#import <sys/stat.h> // 文件状态相关头文件
@interface ViewController ()
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
// 1.构建测试文件路径:在应用沙盒主目录下创建test.data文件
NSString *path = [NSHomeDirectory() stringByAppendingPathComponent:@"test.data"];
NSLog(@"文件路径: %@", path);
// 2.向测试文件中写入初始字符串
NSString *str = @"test str2";
[str writeToFile:path atomically:YES encoding:NSUTF8StringEncoding error:nil];
// 3.调用ProcessFile函数处理文件(通过内存映射追加内容)
ProcessFile(path.UTF8String);
// 4.读取并打印处理后的文件内容
NSString *result = [NSString stringWithContentsOfFile:path encoding:NSUTF8StringEncoding error:nil];
NSLog(@"处理结果:%@", result);
}
/**
* @brief 将文件映射到内存空间
* @param inPathName 输入文件路径(C字符串格式)
* @param outDataPtr 输出参数:映射到内存的起始地址指针
* @param outDataLength 输出参数:原始文件的长度(映射后的大小=原始长度+追加长度)
* @param appendSize 需要追加的数据大小(字节数)
* @return int 错误码,0表示成功,非0为系统错误码(errno)
*/
int MapFile(const char * inPathName, void ** outDataPtr, size_t * outDataLength, size_t appendSize)
{
int outError; // 错误码存储变量
int fileDescriptor; // 文件描述符
struct stat statInfo; // 用于存储文件状态信息
// 初始化输出参数为安全值(出错时返回这些值)
outError = 0;
*outDataPtr = NULL;
*outDataLength = 0;
// Step1:以读写模式打开指定路径的文件,获取文件描述符
fileDescriptor = open(inPathName, O_RDWR, 0);
if(fileDescriptor < 0) { //打开失败的情况处理
outError = errno; //记录系统错误码
} else { //成功打开的情况
/* Step2:获取当前文件的详细状态信息 */
if(fstat(fileDescriptor, &statInfo) !=0 ) {
outError=errno;
} else {
/* Step3:扩展原文件的尺寸以便容纳要追加的内容 */
ftruncate(fileDescriptor , statInfo.st_size + appendSize);
fsync(fileDescriptor); /*确保数据同步到磁盘*/
/* Step4:建立内存映射区域 */
void* mappedPtr=mmap(NULL , /*由内核自动选择映射起始地址*/
statInfo.st_size+appendSize ,/*总映射大小=原大小+追加大小*/
PROT_READ|PROT_WRITE , /*可读可写权限*/
MAP_FILE|MAP_SHARED , /*基于文件的共享式映射*/
fileDescriptor , /*对应的已打开的文件描述符*/
0 ); /*从该文件的偏移量零处开始*/
if(mappedPtr==MAP_FAILED){
outError=errno ;
} else{
/*Step5 :设置正确的输出参数值 */
(*outDataPtr)=mappedPtr ;
(*outDataLength)=statInfo.st_size ;
}
}
close(fileDescriptor); /*关闭不再需要的原始fd(不影响已建立的mmap)*/
}
return(outError);
}
/**
*@brief 对指定路径下的文本型文档进行尾部内容添加操作。
*@param inPathName C风格字符串表示的待操作文档完整物理位置。
*/
void ProcessFile(const char*inPathName){
size_t originalLen ; /**<原始文档字节数**/
void* mappedAddr=NULL ; /**<被成功建立起来的虚拟地址空间首址**/
const char* appendContent=" append_key2"; /**<待附加至末尾处的固定串常量**/
const int appendBytes=(int)strlen(appendContent);
if(MapFile(inPathName,&mappedAddr,&originalLen,appendBytes)==SUCCESS){
char* targetPos=(char*)mappedAddr+originalLen;/**<计算得到应放置新内容的起始位置**/
memcpy(targetPos,appendContent,(size_t)appendBytes);/**执行实际复制动作**/
munmap(mappedAddr,(size_t)(originalLen+appendBytes));/**解除之前建立的整个区域与物理页面间联系*/
}
}
@end
/*补充说明:
1.mmap机制允许将普通磁盘上某个连续区间直接关联至进程虚拟地址空间中,
后续所有针对该段虚拟地址之读写均会由OS透明地转换为对应盘区I/O。
2.MAP_SHARED标志确保修改能同步回写到底层支撑介质,
并且其他进程若以同样方式同时挂载则可立即观察到变化。
3.munmap调用并非必须但建议显式执行以尽早释放占用的页表项资源;
否则将在本进程终止时由内核自动回收。
4.此示例展示了如何高效完成“原地扩展并修改”类任务而无需传统read/write循环带来的多次缓冲拷贝开销。
*/
7.4 解除映射的方法
使用mmap后,必须调用munmap来解除映射,释放分配的虚拟内存。其函数定义如下:int munmap(void *addr, size_t length);。
addr:要解除映射的内存区域的起始地址。length:要解除映射的大小。
返回值:成功返回0,失败返回-1。
 发表于 2026-1-26 04:55:59
|
查看: 187|
回复: 0
发表于 2026-1-26 04:55:59
|
查看: 187|
回复: 0
