理解YashanDB,首先要分清两个核心概念:数据库(Database)与数据库实例(Instance)。
YashanDB分别支持单机(主备)、共享存储集群(以下简称共享集群)、分布式集群三种部署形态,在不同部署形态下的实例架构略有差异。本篇聚焦于单机实例架构,后续再分章节讨论另外两种部署形态。单机实例架构图如下:
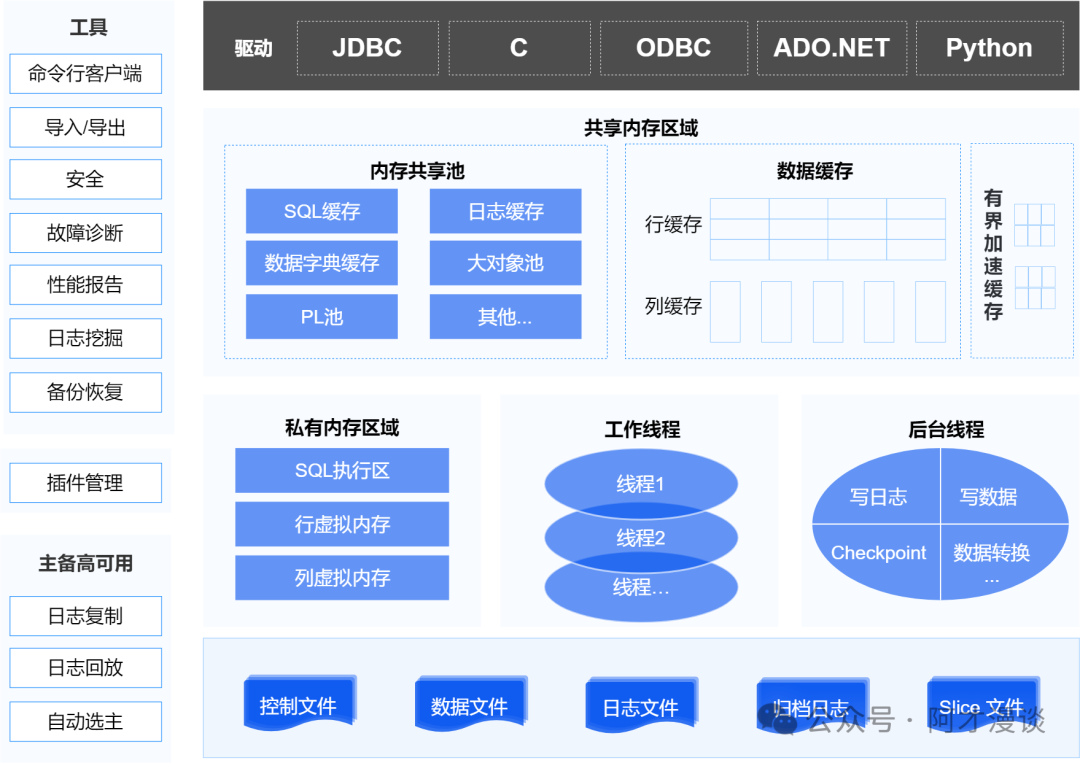
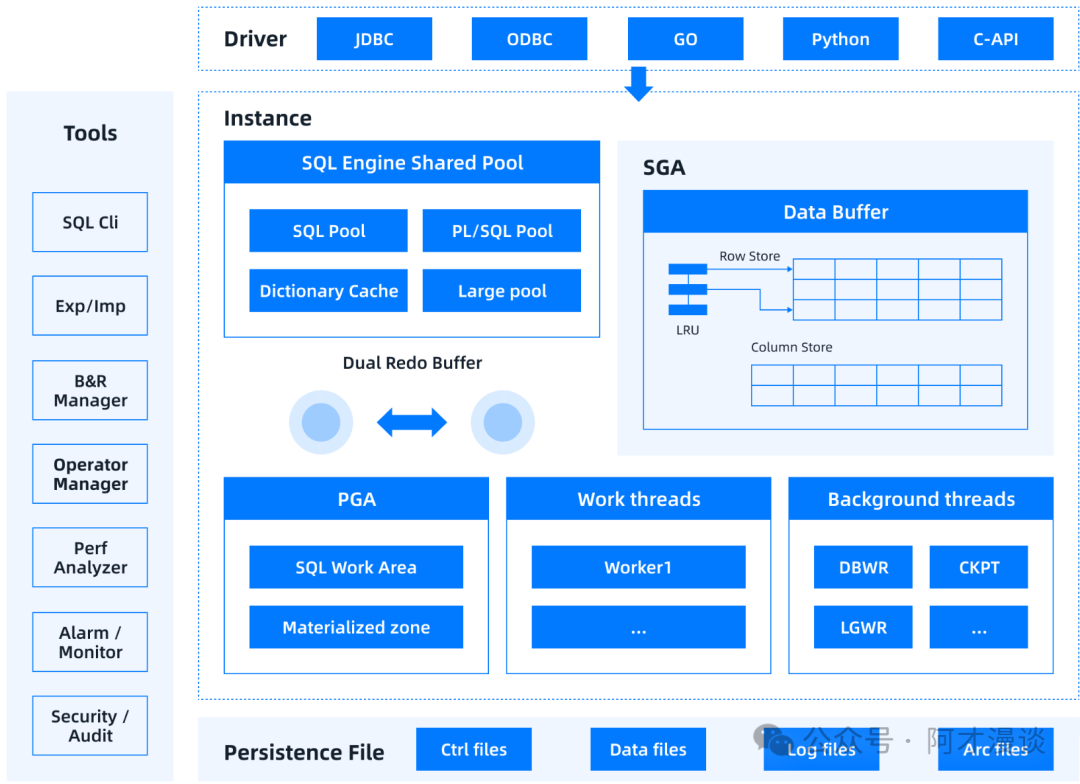
实例
如前所述,实例包括一组线程和内存空间。下面分别介绍YashanDB的内存和线程组成。
内存
YashanDB数据库包含多个内存区域,每个内存区域包含多个子组件。
- 共享内存区域(SGA,Shared Global Area)
共享内存区域是一组所有后台线程以及会话能够共享访问的内存结构,例如数据缓存、SQL缓存、数据字典缓存等。
- 私有内存区域(SPA,Session Private Area)
私有内存区域是会话独占和管理的内存区域,例如会话栈内存、会话堆内存。
共享内存区域(SGA,Shared Global Area)
共享内存区域一般共享给多个会话或线程使用,主要包括内存共享池(SHARE POOL)、数据缓存(DATA BUFFER)、有界加速缓存(AC BUFFER)。
- 内存共享池(SHARE POOL):内存共享池缓存多种类型的信息,例如SQL解析树、执行计划和数据字典缓存等。
- 数据缓存(DATA BUFFER):数据缓存用于对数据的访问加速,如果访问的数据块未在缓存中命中则需要先从磁盘读取到该缓存。当缓存占用过高时,一些不经常使用的数据块会被淘汰。
- 有界加速缓存(AC BUFFER):有界加速缓存类似于数据缓存,但缓存的对象不同,有界加速缓存只用于缓存AC对象。
这里特别说明下,虽然官方文档多在这里描述包括虚拟内存(VIRTUAL MEMORY),但经过相关咨询,虚拟内存(VIRTUAL MEMORY)划到了SPA区域,后面应该会修改官方文档。
内存共享池(SHARE POOL)
内存共享池包含多个内存区域,各区域描述如下:
- SQL缓存:保存SQL解析树和执行计划,SQL引擎在执行语句时,首先会匹配SQL缓存,如果存在相同语句则无需编译直接使用已编译的执行计划,从而避免硬解析,节省开销。
- 日志缓存:redo日志的缓存区,日志并发写入缓存区,批量刷盘,从而减少磁盘I/O和降低响应时延。
- PL池:存储过程、包、触发器等对象创建后会加载到PL池,以提高后续再次执行的效率。
- 数据字典缓存:数据字典包括数据库文件、表、索引、列、用户、权限和其它数据库对象的有关信息。在SQL解析和执行时,SQL引擎查看数据字典,核对和验证对象信息。数据字典是极为频繁使用的信息,通过缓存可极大地提升访问效率。
- 大对象池:分配大对象的区域,例如超大SQL文本。
- 全局缓存资源池:存放集群的数据块的全局资源元数据信息。
- 全局锁资源池:存放集群的全局锁相关的元数据信息。
- 全局队列资源池:存放集群的全局缓存和锁的排队管理信息。
- STREAM资源池:存放YStream解析时的元数据、LCR缓存、收发队列等信息。
内存共享池的总容量通过 SHARE_POOL_SIZE 参数配置。
数据缓存(DATA BUFFER)
数据缓存用于缓存当前或最近使用的从磁盘读取的数据块的拷贝,可优化数据库的I/O减少物理读/写。采用LRU算法管理,当缓存区域内存不足、需要回收内存以重用时,选择一些最长时间未使用的缓存块进行淘汰回收。
数据缓存分为行数据缓存和列数据缓存,行数据缓存用于存放行表相关的数据块拷贝,列数据缓存用于存放列表相关的数据块拷贝。
行数据缓存的容量通过 DATA_BUFFER_SIZE 参数配置。
有界加速缓存(AC BUFFER)
有界加速缓存类似于数据缓存,但缓存的对象不同,有界加速缓存只存放基于有界理论的AC对象。这里稍微解释以下AC对象。
AC 对象(Access Constraint Object,访问约束对象)是 YashanDB 数据库中特有的一种逻辑数据结构,其本质是基于源表(仅支持 LSC-Log-Structured Clustered表)预计算、预聚合并持久化存储的“有界数据子集”,用于实现查询加速。后面用专门的篇幅解释YashanDB特有的有界理论。
私有内存区域(SPA,Session Private Area)
私有内存区域是每个会话创建时分配的独占内存区域,与共享内存区域不同,此区域的内存由会话独占和管理,会话退出时释放,该内存区域主要是满足SQL执行时的各种内存空间需求。该区域主要包括:
- 虚拟内存(VIRTUAL MEMORY):即Materialize zone,虚拟内存主要为需要物化数据的SQL算子所用,且在物化对象过大时将磁盘作为虚拟内存使用。虚拟内存又分为行虚拟内存和列虚拟内存,相关SQL算子计算行存表数据时使用行虚拟内存,计算列存表数据时使用列虚拟内存。
如果虚拟内存不足时,需要通过将虚拟内存交换到SWAP表空间来释放内存,必要时再将内存从SWAP表空间换入。
大小受参数 VM_BUFFER_SIZE 控制。
- 会话栈内存:该区域一般用于存放会话执行过程中临时使用的局部变量等。
由参数 WORK_AREA_STACK_SIZE 控制, 推荐使用默认值。
- 会话堆内存:该区域一般用于存放生命周期较长的运行期数据。
由参数 WORK_AREA_HEAP_SIZE 控制, 推荐使用默认值。
线程
服务端核心进程(YASDB)
YashanDB采用多线程架构,充分利用多核处理器的计算能力,提高系统的并发性和响应性。在多线程架构中,由一个主线程负责程序的初始化和协调工作,然后创建多个子线程来执行具体的任务。每个线程可以独立地执行特定的代码块,但它们共享进程的资源和内存空间。
YashanDB实例启动后,创建YASDB进程处理连接到数据库实例的客户端进程的请求。YASDB进程主要包含后台线程以及处理客户请求的工作线程。
工作线程
WORKER线程是YashanDB数据库专用模式下的会话主线程,主要负责当前会话业务执行的调度。
专用模式下客户端每创建一个连接,会在服务端创建一个WORKER线程,客户端连接退出时,WORKER线程退出。
会话连接的上限由参数 MAX_SESSIONS 控制。
后台线程
YashanDB有很多分工不同的后台线程,这里为了简化理解核心架构,只介绍几个主要的后台线程。其他线程请参照官方文档。
- 主线程(yasdb)
主线程的主要功能是在数据库启动时启动各个模块,以及处理shutdown、主备切换等操作。在数据库运行过程中,主线程也负责清理一些已经结束的线程资源。
- TCP监听线程(TCP_LSNR)
TCP监听线程的主要功能是监听指定的TCP端口,处理客户端的连接请求并创建出会话。该线程在数据库启动到NOMOUNT阶段时启动,生命周期与数据库实例一致。
- 系统监控线程(SMON)
SMON线程在数据库启动到NOMOUNT阶段时启动,生命周期与数据库一致。主要功能如下:
- 死锁检测
- undo定时均衡
- 异常退出事务后台回滚
- 后台undo与事务区自动扩展
- 后台统计信息刷新
- 回滚线程(ROLLBACK)
ROLLBACK线程的主要功能是在数据库重启后回滚残留事务,该线程在主实例启动到OPEN阶段时启动,回滚任务结束后退出。该线程只在主实例上启动,为了提高处理能力,可以设置启动为一组线程,线程数通过STARTUP_ROLLBACK_PARALLELISM参数配置,默认为2个。
- 检查点任务调度线程(CKPT)
CKPT线程的主要功能是调度全量和增量checkpoint的任务。该线程在数据库启动到NOMOUNT阶段时启动,生命周期与数据库实例一致。
- 数据脏块刷新线程(DBWR)
DBWR线程的主要功能是将脏数据块(Dirty Blocks)从数据库缓存区写回到磁盘上的数据文件。该线程在数据库启动到NOMOUNT阶段时启动,生命周期与数据库实例一致。DBWR数量默认为2个,最多为16个,线程数通过DBWR_COUNT参数配置。具体功能如下:
- 脏数据块刷新:DBWR线程定期或在特定条件下将脏数据块刷新到磁盘上的数据文件。
- 数据写回策略:DBWR线程根据一些策略来决定哪些脏数据块需要被写回磁盘。
- 写回优化:DBWR线程会尽量合并多个数据块的写回操作,以减少磁盘I/O操作的次数,提高写入性能。
- 检查点处理:DBWR线程在检查点(Checkpoint)发生时,会将所有脏数据块写回到磁盘,以确保数据库的一致性。
- redo刷盘线程(LOGW)
LOGW线程的主要功能是基于一定的策略(定期或redo数量达到阈值),将内存中的redo日志刷盘到redo日志文件。该线程只在主实例启动到OPEN阶段时启动,生命周期与数据库实例一致。
数据库
物理存储结构用于承载YashanDB在存储介质上持久化数据(包括用户数据以及数据库元数据),用户可以直接在操作系统层面查看物理储存结构相关的文件。
YashanDB物理存储结构主要包括以下文件:
- 数据存储文件:用于存储数据的物理文件,YashanDB支持段页式和分片式两种不同组织格式的数据文件。
- 临时文件:用于临时数据(临时表空间的数据)的存储或中间计算结果的换出(交换表空间的数据)。
- redo重做日志文件:用于记录数据库变更的物理日志,通常用于故障恢复或主备同步。
- 控制文件:用于持久化数据库基本元数据的文件,例如其他物理文件的信息,是加载数据库的入口。
- 双写文件:用于数据的多副本写入,解决因文件系统缓存导致的数据块半写问题。
- 闪回日志文件:用于支持数据库闪回技术的一种特殊日志文件,仅在启用了数据库全库闪回功能的环境中存在。
YashanDB支持将物理存储结构部署到不同的存储介质上,主要包括:
- 通用文件系统:YashanDB支持将物理存储结构部署到主流的文件系统上,例如ext4、XFS、ZFS、NFS等。
- 自研文件系统:YashanDB自研文件系统YFS除了基本的物理文件存储能力之外,还提供多实例共享存储的能力。
- 云存储:YashanDB支持将数据以对象存储的方式存储到远端,例如S3、OBS、BLOB等。
数据存储文件
YashanDB支持行式和列式两种不同的数据存储格式,对应段页式和切片式两种不同格式的数据存储文件,分别为数据文件(DataFile)和切片文件(SliceFile)。
数据文件
数据文件在创建表空间时指定,每个表空间至少要包含一个数据文件。数据文件存储的数据不仅包括用户的数据,也包括数据库元数据(例如表的结构信息)、历史数据(undo数据)等。
虽然Linux稀疏文件(只更新元数据不实际占用存储空间)的方式可以极大程度的提高文件创建效率,但会出现数据库运行过程中因为实际存储空间不足导致的异常,因此YashanDB创建数据文件时会使用预占空间的方式,同时会初始化所有存储空间,并通过自适应并行技术来加速创建的过程。
YashanDB支持数据文件的各类运维SQL语句(包括创建、删除、属性修改、脱机等),但不允许从物理上直接操作数据文件(例如使用操作系统的rm、mv、chmod等命令),否则会导致数据库出现预期外的异常。
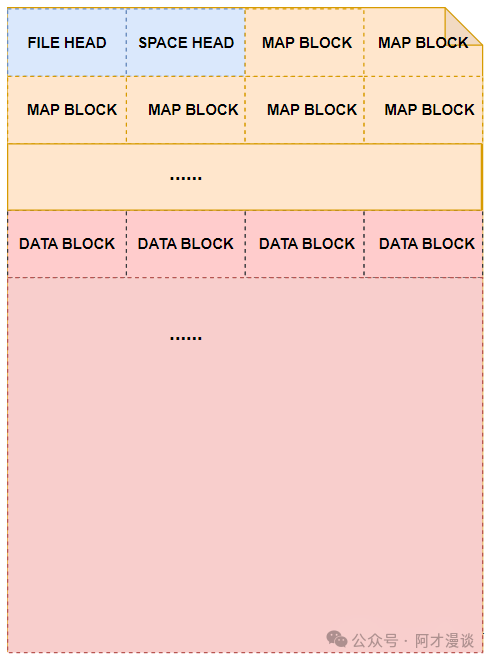
段页式空间管理依赖于基于数据文件的物理存储方式,因此数据文件在物理上也是被划分成了数据块,YashanDB支持的数据块大小8K、16K和32K。例如数据文件的大小为1M,数据块的大小为8K,那么这个数据文件就包括连续的128个数据块。
数据文件中存在多种不同用途的数据块,主要包括:
- 表空间头:用于记录所属表空间的相关信息。
- 数据文件头:用于记录当前数据文件的相关信息。
- 空间管理块:用于当前数据文件的空间管理,记录了每个数据块的使用情况。
- 数据块:实际用于存储数据的数据块。
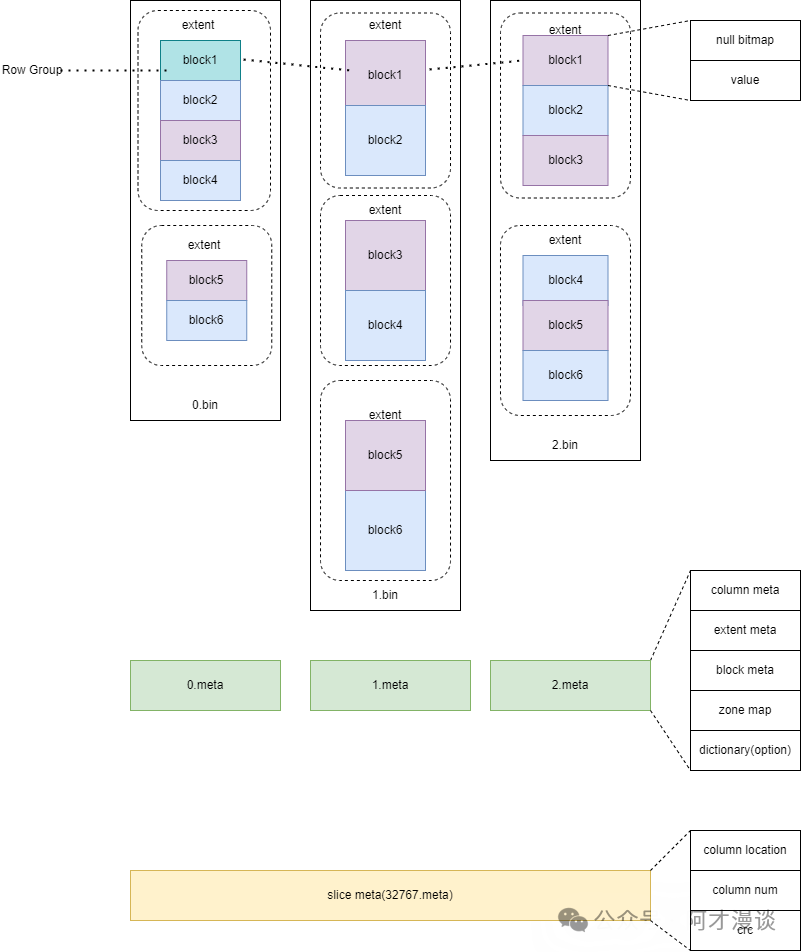
切片文件
切片文件用于存储LSC表的稳态切片数据,采用文件存储,用户可以指定存储在databucket中。切片文件由列数据文件、列元数据文件和切片元数据文件组成:
- 列数据文件:数据按固定行数,被分为多个block,多个block组成一个extent,每一列相同位置的block被称为RowGroup。
- 列元数据文件:存储block、extent的元数据,包含block最大最小值的zone map和一些其他的统计信息,若是字典编码,还会存储字典。
- 切片元数据文件:主要存储整个slice的列数量,crc列存储位置等信息。
临时文件
临时文件用于存储非持久化的数据(数据库重启后会丢失),存储结构与数据文件一致但临时文件的相关修改不会产生redo重做日志,也没有通过检查点机制刷盘。
临时文件存储的数据主要包括:
- 临时表空间数据:YashanDB将临时表、索引等非持久化对象存储到临时表空间,当临时内存不足时,会临时将此类对象信息写入临时文件,使用时再加载。
- 交换表空间数据:交换表空间用于计算中间结果的换入换出,例如排序、分组等中间结果。
redo重做日志文件
在线redo重做日志用于存储重做条目(又称为重做日志记录),存储数据库发生的更改(主要是数据文件的更改)。
redo重做日志的主要目的是恢复。当数据库异常退出后,redo重做日志可以恢复已提交但未写入数据文件的数据,从而避免数据丢失。
redo重做日志文件的结构
YashanDB的redo文件记录了数据库产生的物理日志,用于数据库宕机重演和主备复制。
redo文件的结构如图:
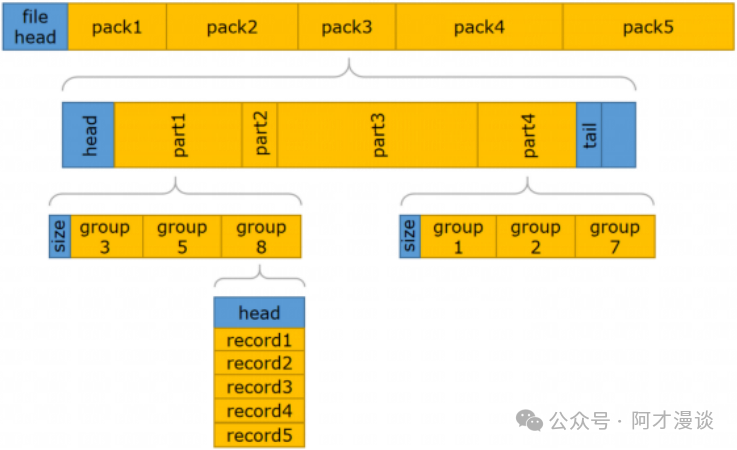
- redo head
记录元数据,包括序列号、块大小、时间等。
- redo pack
日志刷盘的基本单位,它内部包含若干个分区,每个分区内包含多个redo group。
- redo group:一个session执行业务产生的一批record集合。
- record:一条条具体的日志操作,例如insert,update等。
redo重做日志的写入
每个实例存在一个独立的redo重做日志写入线程(LGWR),当日志写到一定阈值时会触发该线程将重做条目写入redo文件中。
当业务量很大时,重做条目的产生速度很快,若整个REDO BUFFER被写满,用户SESSION也会主动将重做条目写入redo文件中。
YashanDB数据库要求至少并存三个redo重做日志文件。
redo重做日志切换
redo重做日志文件有如下4种状态:
- NEW:未使用过的文件。
- CURRENT:当前正在写入的文件。
- ACTIVE:该文件不可被复用。
- INACTIVE:该文件可复用。
数据库只能往一个redo重做日志文件中写入重做条目,正在写入的文件被称为CURRENT redo重做日志文件。
当数据库停止向一个重做文件中写入,开始向下一个文件写入时,则说明发生了日志切换,通常发生在CURRENT redo重做日志文件写满且要写入新的重做条目时。支持手动强制切换日志,手动切换时无需关注CURRENT的redo重做日志文件是否已写满。
redo重做日志切换时,只能选取重做文件状态为NEW或INACTIVE的文件作为下一个CURRENT redo重做日志。如果此时不存在NEW或INACTIVE的重做文件则无法切换,会出现“日志追尾”现象。
归档日志文件
归档日志文件是在线redo重做日志的副本,常用于备库的同步复制或恢复数据库至指定时间点,数据库处于归档模式才会产生归档日志。
在主备部署形态或需要生成备份集的情况下,必须打开归档使数据库处于归档模式。
控制文件
控制文件概述
控制文件是YashanDB的大脑,是数据库实例挂载数据库的入口。控制文件包含以下重要的信息:
- 数据库的基础元数据,包括数据库名称、数据库实例个数、时间戳信息(SCN)等。
- 数据库检查点信息,例如数据库回放起始点、回放一致性点等。
- 数据库各类物理文件的路径、大小等信息。
数据库在运行期间,会实时更新控制文件,例如创建数据文件的操作需要在控制文件中写入新数据库的信息、检查点机制需要定期更新控制文件中的恢复点。
控制文件损坏会导致数据库完全不可用,因此YashanDB采用多副本控制文件的机制,保证单一文件损坏不会导致数据库异常。
控制文件的信息由数据库自动维护,不允许手动操作控制文件,否则会导致数据库出现预期外的异常。
控制文件结构
控制文件内部通过划分不同区域(section)来存储不同的元数据,主要包括以下几类:
- 引导区:用于存储数据库的基础信息,例如版本、ID、角色、数据块大小、字符集等。
- 实例区:用于实例级的启动信息(共享集群形态中同一个数据库会包括多个实例),例如恢复点、SCN、一致性点等。
- 存储结构区:用于存储表空间、数据文件、redo重做日志、归档日志等存储结构信息。
双写文件
YashanDB的数据块规格大于主流文件系统的page size,因此,数据块无法进行原子写,在掉电等场景可能会出现半写的情况(partitial write),从而导致出现断裂页(fractured block)。
YashanDB通过双写技术解决数据块半写问题,在数据块落盘时,会先写入双写区。数据库启动时会通过双写区恢复异常退出导致的断裂页。
双写文件是双写区的存储载体,在建库时创建,用户可以独立指定双写文件的路径、大小等信息。
闪回日志文件
在开启全库闪回功能时,数据库会自动生成闪回日志文件。该类文件基于逻辑变更记录,以数据块为单元记录数据库修改前的信息,为数据库提供闪回恢复的依据,基于此可将数据库快速恢复到过去某个时间点。
闪回日志文件的信息由数据库闪回日志写入线程(RVWR)自动维护,采用异步写入机制,不允许手动操作该类文件,文件被人为篡改、损坏或丢失都可能导致无法成功闪回恢复。
总结
本文简要梳理了YashanDB的单机实例架构与核心存储原理。对于熟悉Oracle的DBA来说,这种架构设计会带来亲切感,更容易上手。但也要注意到,其在有界加速、混合存储等内部机制上的深层差异,值得我们进一步深入学习与实践探索。
如果在学习过程中有任何疑问或心得,欢迎来 云栈社区 的数据库/中间件/技术栈板块一起交流讨论,共同成长!
 发表于 2026-1-26 10:39:10
|
查看: 199|
回复: 0
发表于 2026-1-26 10:39:10
|
查看: 199|
回复: 0
