在 C++ 编程中,悬空引用是最令人头疼的问题之一。当一个对象的生命周期结束后,指向它的引用却依然存在,就会引发未定义行为。
为了缓解这一问题,C++ 标准提供了 临时对象生命周期扩展 的机制。理解其原理、适用场景以及背后的陷阱,对于编写安全且高效的 C++ 代码至关重要。本文将通过大量代码示例,为你深入剖析这一核心特性。
1. 生命周期扩展与临时对象存储
C++ 允许通过特定的引用类型来延长临时对象的生命周期。其本质是:当将一个临时对象绑定到特定的引用时,该临时对象的生命周期会被延长至与引用的生命周期相同。
为了清晰地展示整个过程,我们首先定义一个辅助类 Xray,它的构造函数和析构函数都会打印信息,方便我们追踪对象的生与死。
#include <iostream>
#include <string>
class Xray
{
public:
// 普通构造函数
Xray(std::string value) : mValue(std::move(value))
{
std::cout << "Xray constructor, value is " << mValue << std::endl;
}
// 移动构造函数
Xray(Xray&& other) : mValue(std::move(other.mValue))
{
std::cout << "Xray&& constructor, value is " << mValue << std::endl;
}
// 拷贝构造函数
Xray(const Xray& other) : mValue(other.mValue)
{
std::cout << "Xray const& constructor, value is " << mValue << std::endl;
}
// 拷贝赋值运算符
Xray& operator=(const Xray& other) {
if(this != &other) {
mValue = other.mValue;
std::cout << "Xray copy assignment, value is " << mValue << std::endl;
}
return *this;
}
// 移动赋值运算符
Xray& operator=(Xray&& other) noexcept {
if(this != &other) {
mValue = std::move(other.mValue);
std::cout << "Xray move assignment, value is " << mValue << std::endl;
}
return *this;
}
// 析构函数
~Xray()
{
std::cout << "~Xray destructor, value is " << mValue << std::endl;
}
std::string mValue;
};
// 辅助函数,利用编译器特定的宏打印T的完整类型
template <typename T>
void print_type(std::string_view name){
#if defined(__clang__) || defined(__GNUC__)
std::cout << name << " type = " << __PRETTY_FUNCTION__ << std::endl;
#elif defined(_MSC_VER)
std::cout << name << " type = " << __FUNCSIG__ << std::endl;
#endif
}
1.1 常量左值引用
这是自 C++03 以来就存在的机制。当使用 const T& 来接收一个临时对象时,该临时对象的生命周期会被延长。
int main(){
const Xray& xrayRef = Xray{"111"}; // 临时对象Xray{"111"}的生命周期被延长至xrayRef的作用域
std::cout << xrayRef.mValue << std::endl; // 安全:对象仍然存在
} // 此处xrayRef和临时对象Xray{"111"}一起被销毁
运行结果:
Xray constructor, value is 111
111
~Xray destructor, value is 111
底层原理:
编译器在背后为这个临时对象分配了存储空间(栈上),并将其“附着”在引用变量上。这个临时对象的析构调用点被延迟,从创建它的完整表达式末尾,推迟到绑定它的引用的作用域结束处。
需要注意的是,隐式类型转换也会触发这一机制,例如:const Xray& ref = std::string("hello");,编译器会创建一个临时的 Xray 对象并将其生命周期与 ref 绑定。
1.2 右值引用
C++11 引入了右值引用,并将其纳入生命周期扩展的规则中。使用 T&& 来接收一个临时对象,同样可以扩展其生命周期。
如下代码,Xray{"222"} 是一个临时对象(右值)。当它被用于初始化右值引用 xrayRef 时,其生命周期不再局限于创建它的完整表达式,而是被延长至 xrayRef 的作用域(即 main 函数结束)。因此,后续通过 xrayRef 访问其成员是安全的。
int main(){
Xray&& xrayRef = Xray{"222"}; // 临时对象Xray{"222"}的生命周期被延长至xrayRef的作用域
std::cout << xrayRef.mValue << std::endl; // 安全:对象仍然存在
}
运行结果:
Xray constructor, value is 222
222
~Xray destructor, value is 222
底层原理:
与常量左值引用类似。右值引用本身是一个左值(因为它有名字,即 xrayRef),但它初始化时所绑定的临时对象生命周期被延长。这为移动语义的使用提供了安全性保障,避免在移动操作发生前临时对象就被销毁。
反之,如果临时对象在移动操作完成前就被销毁,就会导致未定义行为,这个机制就没法工作了。简而言之,可以将这条规则理解为:当一个临时对象被绑定到一个右值引用上时,它就获得了与该引用同等的生存权。
1.3 按值存储
按值存储(如 Xray xray = Xray{"111"};)本身并不是严格意义上的生命周期扩展。它实际上是创建了一个新对象。
然而,由于编译器的 拷贝消除 优化,尤其是 C++17 强制要求的初始化对象消除,使得按值存储的语法,在效果上类似于生命周期扩展——没有发生额外的拷贝或移动操作。
int main(){
Xray xray = Xray{"111"}; // C++17起,保证只会调用一次构造函数,无拷贝/移动
std::cout << xray.mValue << std::endl; // 安全:对象仍然存在
} // 对象xray在此处销毁
运行结果:
Xray constructor, value is 111
111
~Xray destructor, value is 111
底层原理:
编译器直接将临时对象的构造,与目标对象的构造,合二为一。从语义上讲,这是两个对象,但优化后,它们占用同一块内存空间。这与引用绑定有本质区别:引用是另一个对象的别名,而按值存储是创建了一个独立的新对象。
2. 类型推导与生命周期扩展
现代 C++ 编程广泛使用类型推导。了解不同类型推导规则在生命周期扩展中的表现至关重要。
2.1 auto关键字推导
auto 的类型推导规则与模板类型推导(见2.4节)类似。
-
auto(按值):推导出的是值类型,不触发生命周期扩展。它创建对象的副本(或通过移动构造),但得益于拷贝消除,通常效率很高。
int main(){
auto xray = Xray{"111"}; // 类型为 Xray,按值存储
std::cout << xray.mValue << std::endl;
}
运行结果:bash
Xray constructor, value is 111
111
~Xray destructor, value is 111
-
const auto&:推导出常量引用类型,会触发生命周期扩展。
int main(){
const auto& xrayRef = Xray{"111"}; // 类型为 const Xray&,生命周期被扩展
std::cout << xrayRef.mValue << std::endl;
}
运行结果:
Xray constructor, value is 111
111
~Xray destructor, value is 111
-
auto&&(万能引用):这是最强大的方式。如果临时对象是右值,auto&& 会推导为右值引用,并扩展其生命周期。如果临时对象是左值,则推导为左值引用。
int main(){
auto&& rref = Xray{"111"}; // 类型为 Xray&&,生命周期被扩展
auto&& lref = rref; // 类型为 Xray&,注意:这不会再次扩展生命周期,只是创建一个指向已存在对象的左值引用。
std::cout << rref.mValue << std::endl;
std::cout << lref.mValue << std::endl;
}
运行结果:
Xray constructor, value is 111
111
111
~Xray destructor, value is 111
注意: 这里仍然只有 1 次构造,1 次析构。
补充按值存储的一些示例:
如果在变量类型推断过程中,不使用任何其他限定符,则 引用声明 以及 CV 类型限定符(const/volatile)将被忽略。在这种情况下,将按值存储变量。
// 按值存储 示例
int i = 0;
int& iRef = i;
const int& iConstRef = i;
volatile int& iVolatileRef = i;
const volatile int& iCVRef = i;
int* iPtr = &i;
auto _1 = i; // type = int
auto _2 = iRef; // type = int
auto _3 = iConstRef; // type = int
auto _4 = iVolatileRef;// type = int
auto _5 = iCVRef; // type = int
auto _6 = iPtr; // type = int*
补充万能引用的一些示例:
而如果使用 auto &&,则与完美转发非常相似,会推断出原始的类型。
// 万能引用 示例
int j = 0;
const int& jConstRef = j;
auto&& _7 = j; // type = int&
auto&& _8 = jConstRef; // type = const int&
auto&& _9 = 4; // type = int&&
2.2 decltype类型推导
自 C++11 引入 decltype 关键字以来,我们可以在编译时获取表达式的类型。
int i = 0;
const int& iConstRef = i;
int&& iRvalueRef = 1;
decltype(i) _1 = i; // type = int
decltype(iConstRef ) _2 = iConstRef; // type = const int&
decltype(iRvalueRef) _3 = std::move(iRvalueRef); // type = int&&
decltype(3) _4 = 3; // type = int
decltype 用于查询表达式的确切类型,包括引用和 CV 限定符(const/volatile)。它本身不参与对象的创建或生命周期管理,只是提供一个类型。如何使用这个类型来声明变量,决定了生命周期是否扩展。
int main(){
decltype(Xray{"111"}) xray = Xray{"111"}; // 类型是 Xray,按值存储。与 auto 类似。
std::cout << xray.mValue << std::endl;
}
运行结果:
Xray constructor, value is 111
111
~Xray destructor, value is 111
再回到 Xray 这个类,它没有默认构造函数,只有带参数的构造函数 Xray(std::string)。如果我们试图直接写 Xray xray;(无参构造),会编译错误。
然而,如果我们需要在模板或类型推导的上下文中,获取 Xray 类型的引用形式(例如为了进行类型匹配或模板参数推导),我们无法直接创建一个 Xray 对象(因为没有默认构造函数),也不能写成 Xray xray;,这时该怎么办?
这时,std::declval 就派上用场了,它提供了一个不实际创建对象的“占位符”来参与类型推导。
int main(){
decltype(std::declval<Xray>()) xray = Xray{"111"}; // 类型是 Xray&&,会扩展生命周期。
std::cout << xray.mValue << std::endl;
}
运行结果:
Xray constructor, value is 111
111
~Xray destructor, value is 111
简单来说:
decltype 是一个编译期操作符。它用于推导表达式的类型,不执行任何代码。它在编译时确定类型,不涉及运行时调用。例如:在 decltype(2+2) 表达式中,加法 ( 2+2 ) 的结果不会被处理,因为编译器只看到该表达式的类型为:(int)+(int),所以结果是 int。declval<T>() 是一个在 <utility> 头文件中定义的工具函数模板。目的是在编译期提供一个类型 T 的左值引用或右值引用的占位符。同理,它本身在运行时不会被调用,也不会产生任何实际的对象实例。
综上所述,我们能看到,以这种方式使用 decltype 不是很方便:
- 存在一些冗余的信息和代码。如下所示,
Xray{"111"} 写了两遍。
decltype(Xray{"111"}) xray = Xray{"111"};
- 有时必须使用各种变通方法(例如
std::declval)来推断类型:
// Xray 没有默认构造函数
// 不能写 Xray xray; // 编译错误
// 需要使用 std::declval 来推导类型
decltype(std::declval<Xray>()) xray = Xray{"111"}; // type = Xray&&
这就是为什么在下一个标准中,decltype(C++11)被修改为 decltype(auto) (C++14) 的原因。
2.3 decltype(auto)推导
从 C++14 开始,我们可以将 auto 关键字作为参数传递给 decltype 函数。通过 decltype(auto),可以推断出与赋值表达式类型相同的类型,从而节省限定符和引用声明。
int i = 2;
const int& iConstRef = 0;
decltype(auto) _1 = 1; // type = int
decltype(auto) _2 = iConstRef; // type = const int&
decltype(auto) _3 = std::move(i); // type = int&&
推导规则详解:
decltype(auto) 结合了 auto 的便利性和 decltype 的精确性。它的推导规则严格遵循 decltype(expr) 的逻辑:
- 如果表达式
expr 是一个名字(id-expression),则推导为该名字声明的类型。
- 如果表达式
expr 不是一个名字(非id-expression):
- 如果表达式的结果是一个左值 (lvalue),推导为
T&。
- 如果表达式的结果是一个纯右值 (prvalue),推导为
T。
- 如果表达式的结果是一个将亡值 (xvalue),推导为
T&&。
decltype(auto)和auto的区别:
这二者在类型推导上有本质区别:
| 特性 |
auto |
decltype(auto) |
| 推导基础 |
根据初始化表达式推导 |
根据表达式本身推导 |
| 引用处理 |
默认剥离引用(除非显式指定) |
保留引用属性 |
| const 处理 |
可能丢弃顶层 const |
保留所有 cv 限定符 |
| 括号影响 |
不受括号影响 |
括号会改变推导结果 |
易出问题的点:
参考下面这 4 个容易让人迷惑的例子。特别注意其中带有括号的 2 个 case。
decltype(auto) x1 = Xray{"111"}; // 类型是 Xray,按值存储。
decltype(auto) x2 = (Xray{"222"}); // 类型是 Xray,因为expr是纯右值
auto tmp = Xray{"333"};
decltype(auto) x3 = tmp; // 类型是 Xray,按值存储,同x1
decltype(auto) x4 = (tmp); // 类型是 Xray&,因为expr是一个左值
- x1分析: 这里
Xray{"111"} 是一个纯右值(prvalue),根据 decltype(auto) 规则,会推导出表达式的类型为 Xray。因此,x1 的类型是 Xray,临时对象按值传递给 x1。
- x2分析:
(Xray{"222"}) 是一个带括号的表达式。其中的 Xray{"222"} 是一个临时对象,属于纯右值 (prvalue)。即使加上了括号,并不会改变它是临时对象的本质。根据 C++ 的规则,给一个临时对象加括号依然是一个右值。 因此,根据 decltype(auto) 规则,x2 的类型是 Xray,按值存储。
- x3分析: 这个容易理解,就是按值存储,x3 的类型是
Xray。
- x4分析: 这个是最容易迷惑的地方。根据 C++ 的规则,任何带括号的表达式,其结果通常被视为一个左值(lvalue)。注意与 x2 的临时对象带括号进行区别。 根据 decltype(auto) 规则,x4 的类型是
Xray 的左值引用,即 Xray&。
注意: 从上面的 x2 和 x4 对比可以看出,使用 decltype(auto) 时需要特别小心,尤其是加上括号时,可能会意外地推导出引用类型。
2.4 模板类型推导
模板函数参数的类型推导规则,与 auto 推导基本是一致的。
-
按值传递(T):推导出值类型,临时对象被拷贝或移动。
template<typename T>
void foo(T param){}
foo(Xray{"1"}); // T 被推导为 Xray,按值传递
-
常量引用传递(const T&):会扩展临时对象的生命周期。
template<typename T>
void foo(const T& param){}
foo(Xray{"1"}); // param 是 const Xray&,生命周期被扩展
-
万能引用(T&&):对于纯右值的临时对象,T 被推导为 Xray,param 类型为 Xray&&,会扩展生命周期。这是完美转发的基础。对于左值,T 被推导为 Xray,param 类型为 Xray&
template<typename T>
void foo(T&& param){}
foo(Xray{"1"}); // param 是 Xray&&,生命周期被扩展
// 即纯右值推导
auto tmp = Xray{"222"};
foo(tmp); // param 是 Xray&
// 即左值推导
补充按值存储的一些示例:
// 无限定符,类似 '仅auto'
template<typename T>
void foo(T param){}
int i = 0;
int& iRef = i;
const int& iConstRef = i;
volatile int& iVolatileRef = i;
const volatile int& iCVRef = i;
int* iPtr = &i;
foo(i); // type = int
foo(iRef); // type = int
foo(iConstRef); // type = int
foo(iVolatileRef); // type = int
foo(iCVRef); // type = int
foo(iPtr); // type = int*
补充万能引用的一些示例:
使用 auto &&,会推断出原始的类型。
// 万能引用,类似 'auto &&'
template<typename T>
void foo(T&& param){}
int i = 0;
const int& iConstRef = i;
foo(i); // type = int&
foo(4); // type = int&&
foo(std::move(i)); // type = int&&
foo(iConstRef); // type = const int&
3. 技巧与陷阱
深入理解了基础规则,我们来看看在实际编码中会遇到的典型技巧与陷阱。
3.1 A引用B之前,确保B引用没有指向临时对象
生命周期扩展只能发生一次,即临时对象第一次绑定到引用时。如果通过一个函数返回的引用 A,来初始化另一个引用 B,而返回的引用 A 本身指向一个临时对象,那么第二个引用 B 将成为悬空引用。这也是初学者常犯的错误——常常从函数返回对临时值/临时对象的引用。
const Xray& foo(){
return Xray{"1"};
}
// 以下所有情况都不正确。生命周期未扩展。
const Xray& _1 = foo(); // 悬空引用
auto _2 = foo(); // Xray类型。Xray::mValue中的值未定义
const auto& _3 = foo(); // const Xray&类型,悬空引用
auto&& _4 = foo(); // const Xray&类型,悬空引用
decltype(auto) _5 = foo(); // const Xray&类型,悬空引用
decltype(foo()) _6 = foo(); // const Xray&类型,悬空引用
在这种情况下,临时对象在函数退出时被销毁,因此返回的引用是悬空的。通常编译器发出警告:
warning: returning reference to local temporary object
如果忽略了这个警告,程序运行时可能就会出问题。
3.2 不要过度使用std::move,信任NRVO
1)NRVO介绍
NRVO(命名返回值优化)是拷贝消除的一种变体,避免函数返回的命名值进行额外的拷贝/移动。NRVO 是编译器的一项重要优化。对于按值返回的局部对象,编译器会直接在调用者的栈帧上构造它,避免拷贝。
如下代码,str 是一个命名值(因为它有一个 str 名称)。如果编译器能够使用 NRVO,对象直接放入 value 中,不需要额外的拷贝或移动:
std::string foo(){
std::string str;
// .. str change
return str;
}
std::string value = foo();
2)RVO介绍
还有另一种编译器优化 - RVO(返回值优化)。RVO 是一种更简化的优化方法,它还能避免为返回值创建名称。
如下代码,std::string{"1"} 不是一个命名值(与上面的 str 情况不同,它没有名称)。如果编译器能够使用 RVO,则不会执行拷贝或移动,因为对象直接放入 value 中:
std::string foo(){
return std::string{"1"};
}
std::string value = foo();
3)std::move易犯错误
为了优化性能,开发者可能会想到这样编码:
std::string&& foo(){
std::string str;
// .. str change
return std::move(str);
}
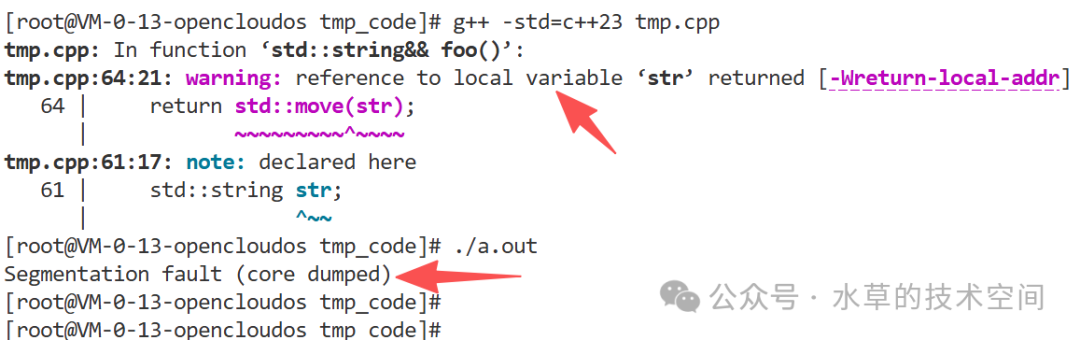
在上述情况下,返回的引用是悬空的,因为它指向一个在函数退出时被销毁的局部对象。通常,编译器会发出警告。强制运行程序会 core。如下图所示:
4)信任NRVO
// 正确做法:信任编译器
Xray goodFoo(){
Xray local_obj;
// ... 操作 local_obj
return local_obj; // 编译器会尝试应用NRVO
}
// 错误做法:画蛇添足
Xray badFoo(){
Xray local_obj;
// ... 操作 local_obj
return std::move(local_obj); // 阻止了NRVO,强制使用移动构造,可能更慢!
}
使用 std::move 返回会阻止 NRVO,因为 return std::move(local_obj) 不再是一个简单的返回局部对象,而是一个表达式,编译器必须执行移动构造。
3.3 确保被扩展生命周期的对象是纯右值
在 C++03 中,可以通过将临时对象保存到常量引用(const T&)来延长其生命周期。
const std::string& ref = getString(); // getString() 返回的临时 string 生命周期被延长至 ref 的作用域结束
从 C++11 开始,引入了 xvalue(亡值)这一值类别,其生命周期无法被延长。C++11 将表达式分为三类主要的值类别:prvalue(纯右值,即传统意义上的右值 rvalue)、lvalue(左值)和 xvalue(亡值)。xvalue 与 prvalue 在函数重载决议中行为相似,都会优先匹配接受右值引用 T&& 的重载版本。例如,当类定义了移动构造函数时,传递 xvalue 会调用移动构造函数,而传递 lvalue 则会调用拷贝构造函数。
Xray& lvalue();
Xray prvalue();
Xray&& xvalue();
Xray _1 = lvalue(); // Xray(Xray) 调用拷贝构造函数
Xray _2 = prvalue(); // 可能发生拷贝消除
Xray _3 = xvalue(); // Xray(Xray&&) 调用移动构造函数
需要注意的是:不能通过引用来延长 xvalue(或 lvalue)的生命周期,否则会导致悬空引用。只有将 prvalue 直接绑定到 const左值引用 或 右值引用 时,其生命周期才会被延长。
Xray const& _1 = prvalue(); // 正确:延长prvalue的生命周期
Xray&& _2 = prvalue(); // 正确:延长prvalue的生命周期
Xray& _3 = lvalue(); // 错误:悬空引用,不延长生命周期
const Xray& _4 = lvalue(); // 错误:悬空引用,不延长生命周期
Xray&& _5 = xvalue(); // 错误:悬空引用,不延长生命周期
const Xray& _6 = xvalue(); // 错误:悬空引用,不延长生命周期
3.4 妥善管理RAII对象的生命周期
RAII 对象(如锁、智能指针)的析构函数至关重要。必须将其存储在变量中,以确保其生命周期覆盖整个需要的作用域。
{
std::lock_guard<std::mutex> lock(g_mutex); // 正确:lock的生命周期覆盖整个作用域
// 安全的临界区
}
{
std::lock_guard<std::mutex>{g_mutex}; // 错误!临时锁对象在本行末尾立即被销毁。
// 此处已无锁保护,存在竞态条件!
}
即使构造函数和析构函数被内联,它们的语义(即加锁和解锁)也必须被保留。
3.5 警惕引用链导致的悬空引用
只能在第一次绑定到引用时,扩展临时对象的生命周期。当使用 T& A --指向--> T& B --指向--> 临时对象 时,它不会重复扩展生命周期,而是导致悬空引用和未定义行为。也就是引用链不能让生命周期也传递扩展。
template<class T>
const T& foo(const T& in){
return in;
}
const Xray& ref1 = Xray("111"); // 正确,生命周期扩展。
const Xray& ref2 = foo(Xray("222")); // 错误,生命周期未扩展,
// ref2 — 悬空引用。
std::cout << ref2.mValue; // 未定义行为
有趣的事实:即使是 C++ 标准库中的 std::min 或 std::max 也会遇到同样的问题。例如 const int& x = std::min(1, 2); 同样会导致 x 成为悬空引用。
3.6 不要通过三元操作符?:来扩展临时对象的生命周期
根据 C++ 标准,生命周期扩展不仅适用于简单的赋值,也适用于条件表达式(Conditional Expression)。标准规定,当使用 ?:运算符 的结果初始化一个引用时,只有被选中的那个操作数(无论是第二个还是第三个)中的临时对象会被扩展生命周期。虽然语法上合法,但逻辑复杂,容易混淆,不推荐在生产代码中依赖此特性。
Xray&& rvalRef = cond ? Xray{"1"} // 其中一个临时对象
: Xray{"2"}; // 将具有rvalRef的生命周期
const Xray& constLvalRef = cond ? Xray{"1"} // 其中一个临时对象
: Xray{"2"}; // 将具有constLvalRef的生命周期
3.7 避免在类成员中持有指向外部临时对象的引用
避免在类成员字段中使用引用(尤其是指向临时对象的引用),也不要试图利用 std::reference_wrapper 来延长临时对象的生命周期。
理由一:存在悬空引用风险
在类成员中使用引用字段,尤其是当所引用的对象生命周期不受该类控制时,极易导致悬空引用。相比之下,按值存储(Pass-by-value)要安全得多。
理由二:生命周期延长机制极其不稳定
虽然 C++ 标准规定,如果一个临时对象拥有一个由另一个临时对象初始化的引用字段,生命周期延长理论上可以递归应用。
示例:聚合初始化(Aggregate Initialization)下的行为
struct X {
const int& lvalRef;
};
const X& lvalRef = X{1}; // 临时对象X和(int)1
// 将具有lvalRef的生命周期
X&& rvalRef = X{1}; // 临时对象X和(int)1
// 将具有rvalRef的生命周期
auto&& _1 = X{1}; // 也可以,类型是X&&
//(通过右值引用扩展)
decltype(auto) _2 = X{1}; // 也可以,类型是X
//(按值存储)
不过,这种机制高度依赖初始化方式。它通常仅在聚合初始化(如 X{1})或触发编译器拷贝消除(Copy Elision)时有效。一旦涉及构造函数,跨编译器的表现就会变得极不稳定:
struct X {
template<typename T>
X(T&& l) : val(l){ } // 使用构造函数
const int& val;
};
const X& lvalRef = X{1}; // 悬空引用,lvalRef.val值 == 0
X&& rvalRef = X{1}; // 悬空引用,rvalRef.val值 == 0
auto&& _1 = X{1}; // 悬空引用,_1.val值 == 0
decltype(auto) _2 = X{1}; // X类型(按值存储),
// MSVC正常,_2.val == 1,
// GCC则悬空,_2.val == 0
结论:
尽管标准中关于“初始化表达式用于初始化目标对象”的描述,逻辑上可能暗示生命周期应当延长,但各编译器的实现并不统一。这种描述晦涩、实现不一的特性属于“黑洞”领域,因此强烈建议不要在类字段中使用引用来绑定临时对象。
3.8 使用new时确保参数中的临时对象不被成员引用存储
传递给 new 表达式的临时参数,其生命周期仅持续到包含该 new 的完整表达式结束。如果 new 创建的对象的构造函数,将其参数使用引用存储到成员中,则该成员将立即成为悬空引用。
示例1:
struct S {
const int& ref;
S(const int& r) : ref(r) {}
};
S* p = new S(42); // 危险!构造函数参数`42`是临时对象。
// 在`new S(42)`这行代码结束后,临时对象`42`被销毁。
// 此时`p->ref`已经是悬空引用。
示例2:
struct S
{
int i;
const std::pair<int,int>& pair;
};
S a { 1, {2,3} }; // 理论上可以,但极其不推荐(见3.7节)
S* p = new S{ 1, {2,3} }; // 错误, p->pair是悬空引用
3.9 不要通过引用数组元素来扩展整个数组的生命周期
C++标准确实允许通过绑定临时数组的某个元素,来延长整个数组的生命周期。然而,语法晦涩,可读性极差,且在不同编译器上行为可能不一致。
// 一种理论上可行的但极其不推荐的写法
template<typename T>
using identity = T;
const int& elem = identity<int[3]>{1, 2, 3}[1]; // 整个临时数组的生命周期被延长至elem的作用域。
这种技巧几乎只存在于理论讨论中,在实际开发中应坚决避免。如果需要临时数组,使用 std::array 或 std::vector 并按值存储。
4. 结论
C++ 临时对象的生命周期扩展是一把双刃剑。正确使用时,它可以提升代码效率和简洁性;误用时,则直接导致悬空引用和未定义行为,是程序中难以追踪的 Bug 之源。
核心建议:
- 保持简单:优先考虑按值存储。现代 C++ 的移动语义和拷贝消除,使其性能开销通常很小。
- 明确意图:如果必须使用引用,清楚地区分是用于延长临时对象生命周期(
const auto& 或 auto&&),还是用于别名一个已存在的长生命周期对象(auto&)。
- 信任编译器:对于返回值,优先依赖 NRVO/RVO,而非手动
std::move。
- 保持警惕:牢记生命周期扩展的陷阱,尤其是“引用链”、亡值
xvalue、以及类成员引用。在代码审查中,对这些模式要格外关注。
遵循 KISS 原则,编写清晰、直接、易于理解的代码,远比依赖复杂且容易出错的语言边角特性更为重要。将生命周期扩展视为一个需要谨慎使用的工具,而非默认选择。希望本文的深入解析能帮助你在日常开发中更好地驾驭 C++ 的这一特性。如果你想了解更多 C++ 底层细节或讨论其他技术话题,欢迎在 云栈社区 的 C/C++ 板块 交流。
 发表于 2026-3-6 05:52:54
|
查看: 240|
回复: 0
发表于 2026-3-6 05:52:54
|
查看: 240|
回复: 0
