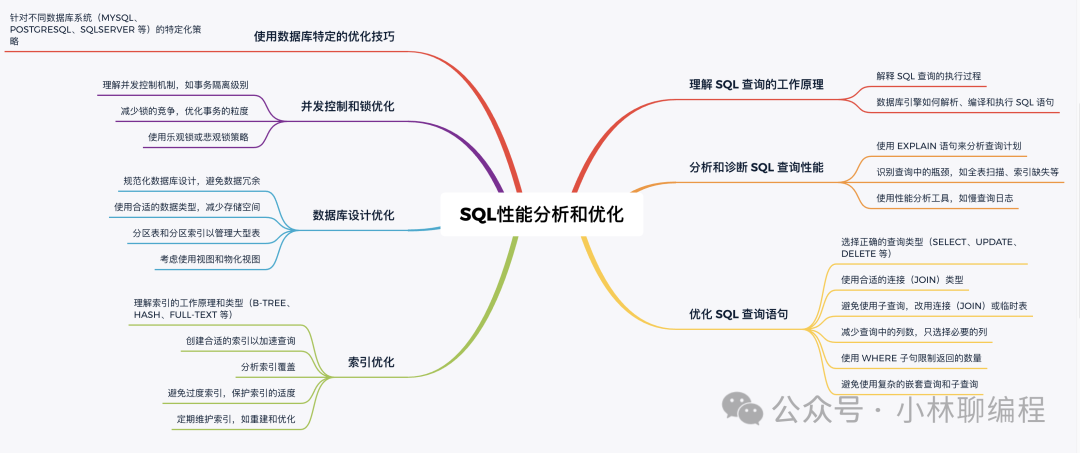
本文将系统梳理SQL性能优化的核心思路,内容涵盖SQL执行原理、性能诊断、语句优化、索引策略、设计优化及并发控制,旨在提供一套从理论到实践的完整优化方案。
理解 SQL 查询的工作原理
1. 解析(Parsing)
数据库引擎首先检查SQL语句的语法是否正确。如果语法无误,解析器会将其转换为内部表示形式以备后续处理。
SELECT * FROM employees WHERE department_id = 5;
若department_id列不存在或表名拼写错误,解析器将在此阶段报错。
2. 优化(Optimization)
优化器分析查询计划,确定最高效的执行方式,包括索引选择、是否进行全表扫描等决策。
SELECT first_name, last_name FROM employees WHERE first_name LIKE 'J%';
如果first_name列上建有索引,优化器很可能会利用该索引快速定位以‘J’开头的记录,而非扫描全表。
3. 执行(Execution)
执行器依据优化后的计划执行查询,包括从磁盘读取数据、应用WHERE条件、执行JOIN操作等。
SELECT employees.first_name, employees.last_name, departments.department_name
FROM employees
INNER JOIN departments ON employees.department_id = departments.department_id
WHERE employees.salary > 50000;
此语句执行了一个内连接,并筛选薪资超过50000的员工及其部门信息。
4. 结果返回(Result Retrieval)
执行器将最终结果返回给客户端,可能包含排序、分组、聚合等操作后的数据。
SELECT department_name, COUNT(*) as employee_count
FROM employees
GROUP BY department_name
ORDER BY employee_count DESC;
此查询按部门分组统计员工数,并依此降序排列返回。
理解上述原理是编写高效SQL的基础,例如合理使用索引可显著提升性能,而避免不必要的全表扫描和复杂子查询则能有效降低资源消耗。
分析和诊断 SQL 查询性能
1. 使用 EXPLAIN 命令
EXPLAIN命令是分析SQL执行计划的核心工具,能展示是否使用索引、访问类型等关键信息,是进行数据库性能分析的首要步骤。
EXPLAIN SELECT * FROM employees WHERE department_id = 5;
输出结果中的type、key、Extra等列揭示了查询的执行细节。
2. 分析执行计划
重点关注执行计划中的type列。ALL表示全表扫描,index表示索引扫描,而const或eq_ref通常代表高效的索引查找。
EXPLAIN SELECT * FROM employees WHERE id = 1;
理想情况下,此查询的type应为const。
3. 查看慢查询日志
启用并分析慢查询日志,有助于定位执行时间过长的查询。在MySQL中配置如下:
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1; -- 阈值设为1秒
SET GLOBAL slow_query_log_file = '/path/to/your/slow-query.log';
4. 使用性能分析工具
除数据库内置命令外,可借助PawSQL、Percona Toolkit等第三方工具进行更深层次的性能剖析。
5. 监控数据库状态变量
通过SHOW STATUS命令监控关键指标,了解数据库实时运行状态。
SHOW GLOBAL STATUS LIKE 'Com_select';
6. 分析查询执行频率
了解各类操作(SELECT, INSERT, UPDATE, DELETE)的频率,有助于确定优化优先级。
优化 SQL 查询语句
1. 避免使用SELECT *
仅查询需要的列,减少网络传输与内存处理的开销。
SELECT name, age FROM users WHERE id = 1;
2. 使用UNION ALL代替UNION
UNION ALL不会进行去重和排序,通常比UNION性能更好。
SELECT column1 FROM table1
UNION ALL
SELECT column1 FROM table2;
3. 小表驱动大表
在关联查询中,尽量让数据量小的表作为驱动表。
SELECT *
FROM large_table
WHERE large_table.id IN (SELECT id FROM small_table WHERE condition);
4. 批量操作
对于数据插入、更新或删除,采用批量操作能极大减少I/O次数和事务开销。
INSERT INTO table (column1, column2) VALUES (value1, value2), (value3, value4), ...;
5. 使用LIMIT
对于只需部分结果的查询,务必使用LIMIT限制返回行数。
SELECT * FROM table LIMIT 10;
6. 优化IN子句
当IN列表过长时,考虑改用连接查询或临时表。
SELECT * FROM table WHERE id IN (SELECT id FROM temp_table);
7. 增量查询
在数据同步场景下,使用增量查询避免全量扫描。
SELECT * FROM table WHERE id > last_id;
8. 高效的分页
对于深度分页,使用基于索引(如主键)的范围查询替代LIMIT offset, size。
SELECT * FROM table WHERE id BETWEEN last_id + 1 AND last_id + page_size;
9. 连接查询代替子查询
在多数情况下,连接查询(JOIN)的性能优于子查询。
SELECT a.*, b.*
FROM table_a a
INNER JOIN table_b b ON a.id = b.table_a_id;
10. 控制索引数量
索引并非越多越好,过多的索引会增加写操作的成本。只为高选择性的、常用于查询条件的列创建索引。
11. 选择合理的字段类型
使用最精确的数据类型,避免不必要的类型转换和存储空间浪费。
ALTER TABLE table MODIFY column VARCHAR(255);
12. 提升GROUP BY的效率
尽量在GROUP BY之前使用WHERE子句过滤掉无关数据,缩小分组操作的数据集。
SELECT column1, COUNT(*)
FROM table
WHERE condition
GROUP BY column1;
13. 索引优化
定期使用EXPLAIN分析查询计划,确保索引被有效利用。
EXPLAIN SELECT * FROM table WHERE column = 'value';
索引优化
1. B-tree 索引(B+树索引)
B+树是数据库最常用的索引结构,支持高效的范围查询和排序。所有数据存储在叶子节点,非叶子节点仅存放键值,降低了树的高度。
CREATE INDEX idx_name ON table_name(column_name);
2. Hash 索引
基于哈希表实现,等值查询极快,但不支持范围查询和排序。MySQL的Memory存储引擎默认使用Hash索引。
CREATE TABLE hash_table (id INT, name VARCHAR(255)) ENGINE=MEMORY;
3. Full-text 索引
专为文本搜索设计,通过倒排索引实现快速的全文匹配。
CREATE FULLTEXT INDEX idx_fulltext ON table_name(column_name);
4. R-tree 索引(空间索引)
用于高效查询空间数据(如GIS地理位置)。
CREATE SPATIAL INDEX idx_spatial ON table_name(geospatial_column);
5. 创建合适的索引
为高频出现在WHERE、ORDER BY、GROUP BY及JOIN条件中的列创建索引。
CREATE INDEX idx_name ON employees(name);
6. 使用复合索引
当多个列常作为组合条件出现时,创建复合索引。注意列的顺序应遵循“最左前缀原则”。
CREATE INDEX idx_name_age ON employees(name, age);
7. 避免过度索引
每个额外的索引都会增加插入、更新和删除操作的成本。需要平衡查询性能与写操作开销。
8. 使用覆盖索引
如果查询的所有字段都包含在某个索引中,数据库可以直接从索引中获取数据,避免回表,这是提升查询性能的关键技巧之一。
SELECT column1, column2 FROM table WHERE column1 = 'value';
-- 若存在(column1, column2)的复合索引,则形成覆盖索引
9. 考虑索引的选择性
为选择性高(不同值多)的列创建索引收益更大。像“性别”这种选择性低的列,创建索引通常意义不大。
10. 定期维护索引
对表进行大量更新后,使用OPTIMIZE TABLE或REINDEX来消除索引碎片。
OPTIMIZE TABLE orders;
11. 分析索引使用情况
通过EXPLAIN的Extra列查看是否Using index,判断索引是否被有效使用。
12. 考虑分区表
对于亿级以上的超大表,可以考虑使用分区将数据物理拆分,提升查询和维护效率。
CREATE TABLE orders (
id INT AUTO_INCREMENT PRIMARY KEY,
order_date DATE NOT NULL,
...
) PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p0 VALUES LESS THAN (2010),
PARTITION p1 VALUES LESS THAN (2011),
...
);
数据库设计优化
1. 规范化(Normalization)
遵循数据库设计范式,减少数据冗余,确保数据一致性。这是关系型数据库设计的基石。
2. 反规范化(Denormalization)
在读多写少、对查询性能要求极高的场景下,可以适度反规范化,通过增加冗余字段来减少JOIN操作,这是一种以空间换时间的权衡。
3. 选择合适的数据类型
使用最精确、最小的数据类型。例如,存储年龄用TINYINT而非INT,存储定长字符串用CHAR而非VARCHAR。
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
age TINYINT UNSIGNED
);
4. 使用合适的索引
如前所述,根据查询模式精心设计索引。
5. 分区表(Partitioning)
对于海量表,分区能显著提升查询效率和管理便捷性。
6. 使用视图(Views)
将复杂的查询逻辑封装成视图,简化应用层代码并提高可维护性。
CREATE VIEW user_info AS
SELECT id, username, age FROM users;
7. 物化视图(Materialized Views)
用于存储复杂查询的结果,适合对实时性要求不高的报表类场景,能极大降低重复计算的开销。
8. 数据库缓存
合理配置查询缓存、缓冲池等缓存机制。但需注意,在写频繁的场景下,查询缓存可能弊大于利。
9. 数据库维护
定期执行如更新统计信息、重建索引等维护任务,保持数据库健康状态。
10. 选择合适的存储引擎
根据应用特性选择存储引擎。例如,需要事务支持选择InnoDB,只读或读多写少且不需要事务的考虑MyISAM(MySQL 5.5前)。
CREATE TABLE users (...) ENGINE=InnoDB;
并发控制和锁优化
1. 事务隔离级别(Transaction Isolation Levels)
根据业务对一致性和并发性的要求,选择合适的隔离级别。READ COMMITTED是平衡性较好的常用选择。
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
2. 锁的类型
InnoDB存储引擎实现了行级锁,大大提升了并发性能。表锁则粒度较粗,容易引发竞争。
SELECT * FROM table_name WHERE id = 1 FOR UPDATE; -- 获取行级排他锁
3. 锁的粒度
尽可能使用细粒度锁(如行锁)以减少锁竞争,提升系统并发能力。
4. 死锁检测和预防
数据库通常具备死锁检测与回滚机制。通过保持一致的资源访问顺序、减小事务粒度等方法可以预防死锁。
5. 锁提示(Lock Hints)
谨慎使用锁提示来影响数据库的锁策略,通常仅在明确知晓后果时使用。
SELECT * FROM table_name WHERE id = 1 LOCK IN SHARE MODE;
6. 批量操作
将多个操作合并到一个事务中执行,可以减少事务提交次数,从而降低锁竞争和日志刷盘开销。
7. 索引优化
合理的索引能令查询快速定位到所需行,减少需要锁定的数据范围,这是实现高效并发控制的重要前提。
8. 事务的粒度
避免长事务,将大事务拆分为多个小事务,缩短锁的持有时间。
9. 使用乐观锁
在冲突发生概率较低的场景,乐观锁通过版本号或时间戳实现无锁并发控制,性能更高。
BEGIN TRANSACTION;
UPDATE table_name SET column1 = value1, version = version + 1 WHERE id = 1 AND version = old_version;
COMMIT;
使用数据库特定的优化技巧
1. MySQL
- InnoDB引擎:关注缓冲池(innodb_buffer_pool_size)配置,它直接影响性能。
- 查询缓存:在MySQL 8.0中已被移除,在早期版本中需根据更新频率决定是否启用。
- 慢查询日志:是定位性能问题的必备工具。
2. PostgreSQL
- 索引多样性:支持B-tree, Hash, GIN, GiST等多种索引,根据数据类型和查询模式选择。
- MVCC:基于多版本并发控制,读写互不阻塞。
- 并行查询:对于复杂分析查询,可配置并行 workers 来加速。
3. Oracle
- 物化视图:功能强大,支持查询重写和自动刷新。
- 分区:对超大型表和索引的分区支持非常成熟。
- AWR/ADDM:自动负载信息库和诊断工具,提供深度性能洞察。
4. SQL Server
- 索引碎片整理:定期进行
ALTER INDEX ... REORGANIZE/REBUILD。
- 执行计划缓存:分析缓存的执行计划有助于理解优化器行为。
- 列存储索引:针对数据仓库场景的分析查询性能提升显著。
5. SQLite
- WAL模式:启用Write-Ahead Logging模式可大幅提升并发写入性能。
- 内存数据库:对于小型应用,
:memory:模式性能极致。
6. NoSQL 数据库
- 数据模型:根据访问模式选择文档、键值、列族或图模型。
- 分片:通过水平分片实现数据的分布式存储与扩展。
- 最终一致性:在可用性与一致性之间做出权衡。
数据库架构设计没有银弹,关键在于深刻理解业务需求、数据特性和各类数据库组件的原理,从而在具体的场景中做出最合适的技术选型与优化决策。
 发表于 2025-12-2 04:05:49
|
查看: 165|
回复: 0
发表于 2025-12-2 04:05:49
|
查看: 165|
回复: 0
