在企业网络中,有一种故障非常典型,让人头疼不已:
- 网络没有完全断
- 但几乎无法使用
- 有人能上网,有人不能
- 系统时好时坏
很多人会抱怨:“网络又出问题了。”但从技术角度看,更准确的描述是:网络不是坏了,而是被流量“淹”没了。这种现象,通常只有一个名字:交换机泛洪。
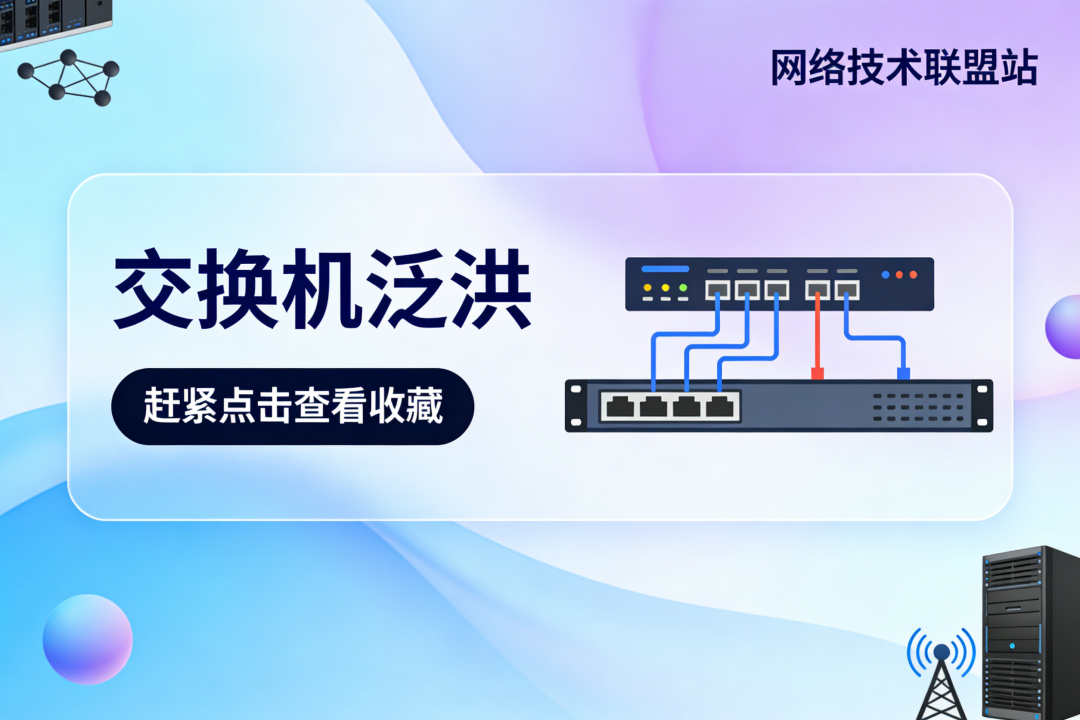
要理解泛洪,你必须站在交换机的角度思考。交换机的工作其实非常简单:1. 记录设备的MAC地址;2. 根据MAC地址转发数据。其内部有一张至关重要的表——MAC地址表(CAM表)。
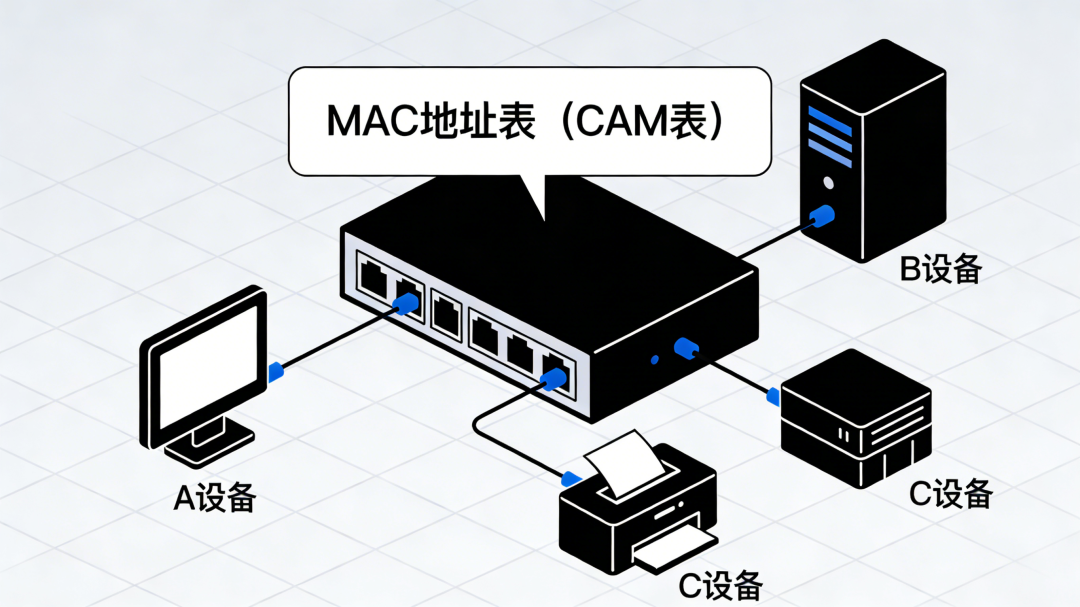
正常情况下,这张表会清晰记录:
- A设备 → 端口1
- B设备 → 端口2
- C设备 → 端口3
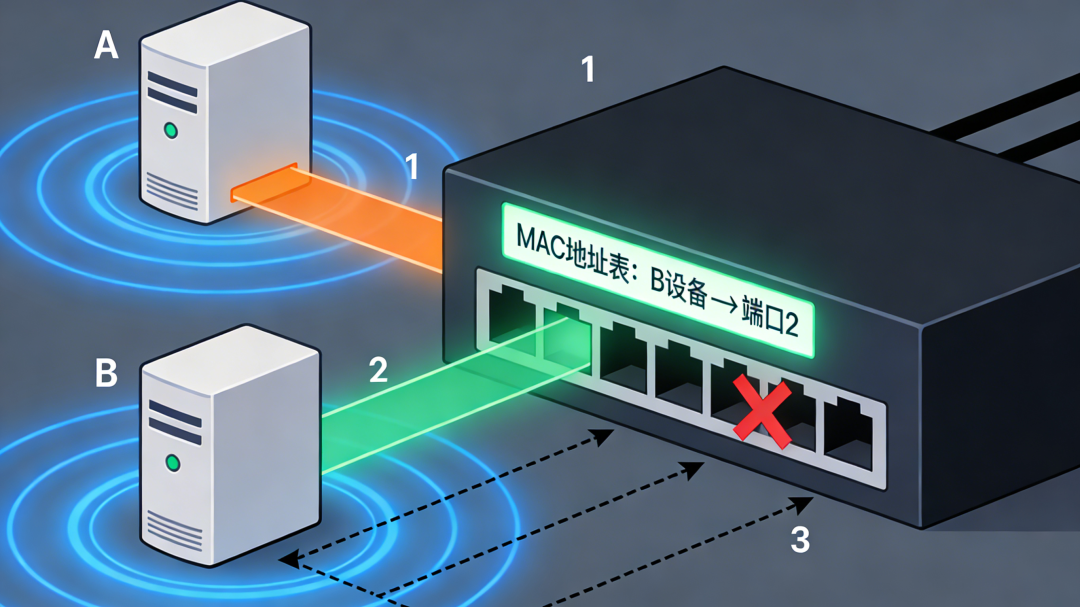
当A设备需要访问B设备时,交换机会精准地将数据只转发给端口2。然而,当交换机在MAC表中查不到目标设备的MAC地址(比如B设备)时,它就不知道数据该往哪个端口送。此时,交换机只能选择最“笨”但最安全的方式:把数据发给除了接收端口之外的所有其他端口。这种行为,就是“泛洪”。
泛洪的三种典型类型
很多人误以为泛洪只有一种,其实从技术角度看,常见的泛洪可分为三类。
广播泛洪(Broadcast Flooding)
典型场景:ARP请求、DHCP请求。
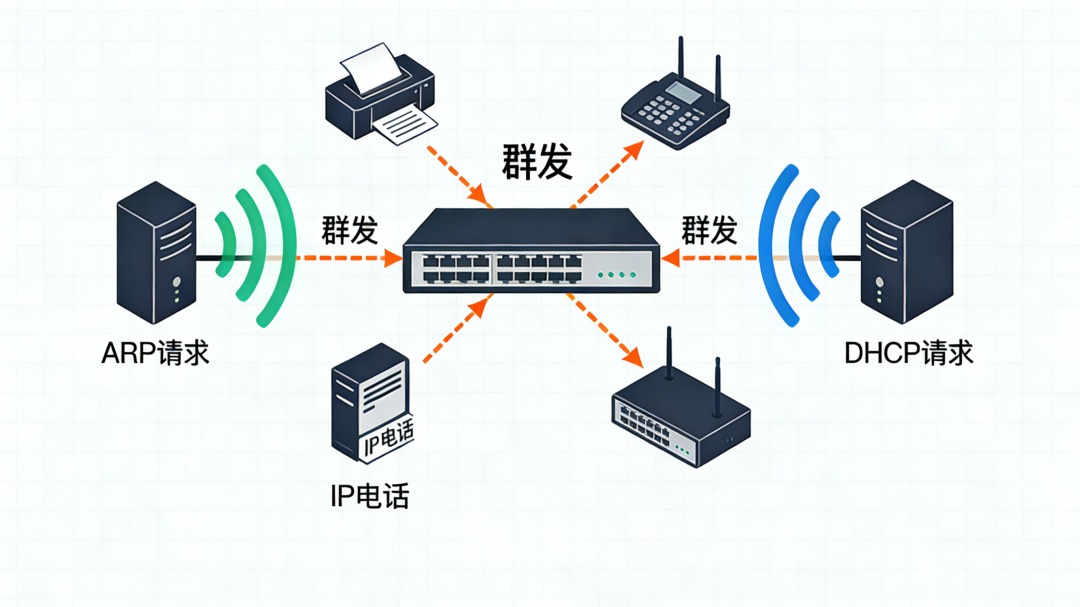
特点:数据包的目的MAC地址就是广播地址(如FF:FF:FF:FF:FF:FF),本来就是设计给所有设备的“群发”消息。在可控范围内,这是网络正常运作的一部分。
未知单播泛洪(Unknown Unicast Flooding)
这是最危险、也最容易被忽视的类型。
发生条件:
- 目标MAC地址不在交换机的MAC地址表中
- MAC表因异常被清空或覆盖
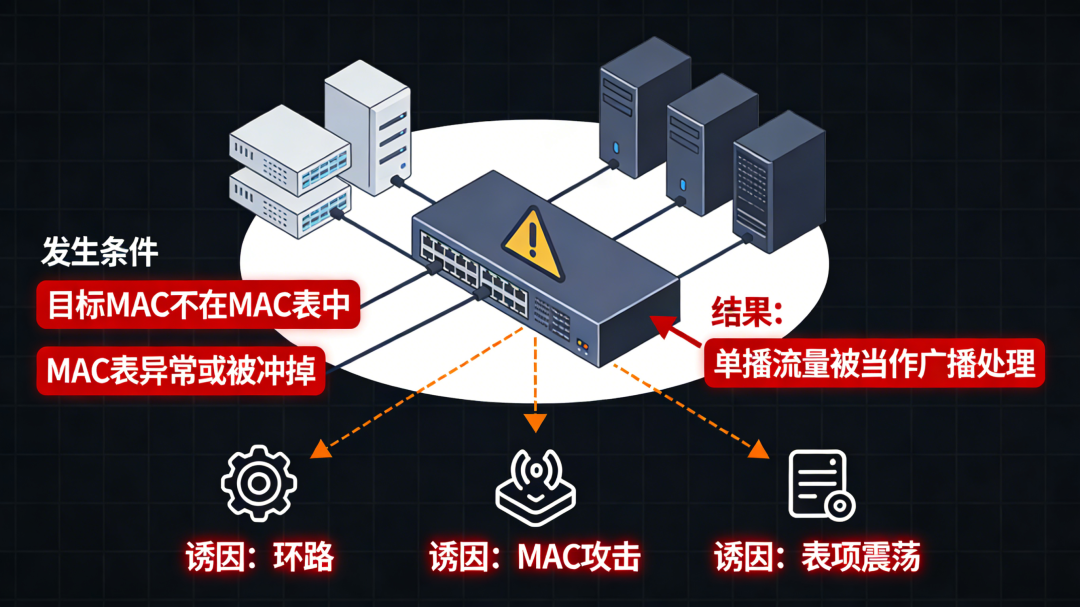
结果:本该精准送达的单播流量,被当成了广播处理,向所有端口泛滥。这类泛洪往往是二层环路、MAC地址攻击或MAC表项震荡等问题的直接后果。
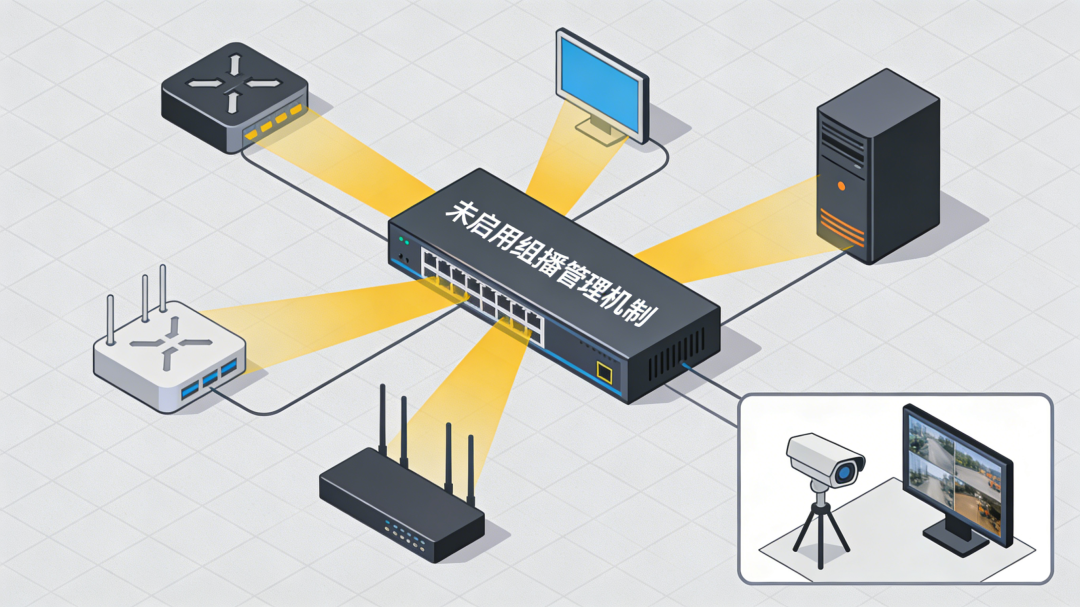
组播泛洪(Multicast Flooding)
如果网络中没有启用IGMP Snooping等组播管理机制,交换机无法识别组播组成员。此时,组播流量会被当作广播流量处理,导致全网泛洪。这在视频会议、监控等大量使用组播的网络中尤为常见。
很多人容易把“泛洪”和“广播风暴”混为一谈,这是一个常见误区。我们来厘清几个关键概念:
| 概念 |
含义 |
| 泛洪 (Flooding) |
交换机无法定位目标MAC,被迫向所有端口转发单播/组播帧。 |
| 广播风暴 (Broadcast Storm) |
广播包在环路中大量循环传播,指数级占用带宽,导致网络瘫痪。 |
| 未知单播风暴 |
MAC表异常导致大量未知单播帧持续泛洪,效果类似广播风暴。 |
| 二层环路 |
网络中存在冗余物理路径且未启用防环路协议,是导致广播/未知单播无限循环的根本原因。 |
泛洪的根源:二层环路
许多泛洪问题,最终都可以追溯到一个核心原因:二层环路。
什么是环路?简单理解:两台交换机之间接了两条以上的网线,数据包可以在它们之间“绕圈”传输。
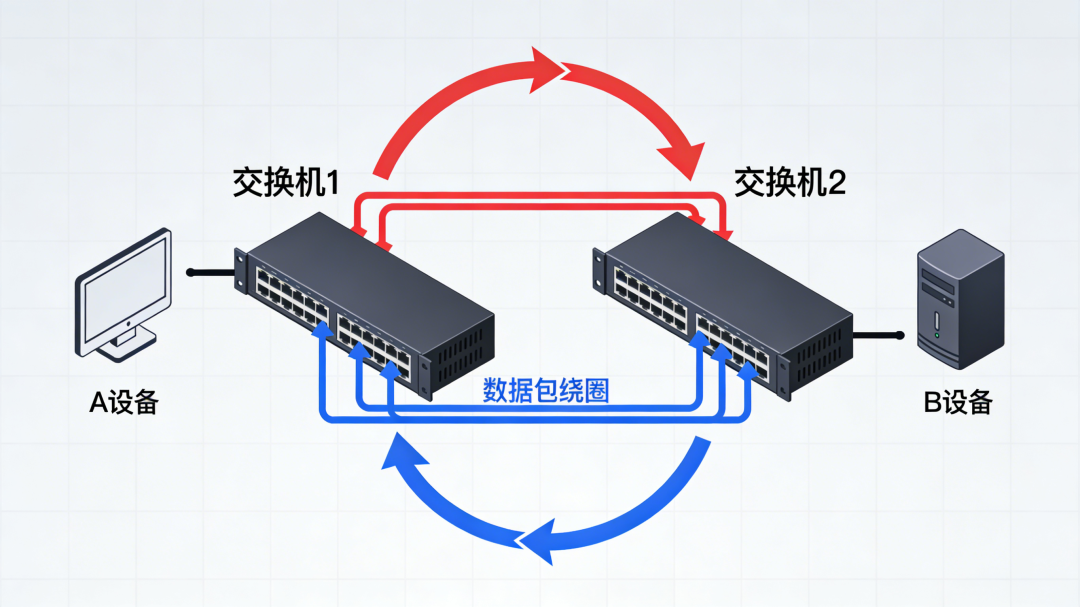
环路会带来什么?
当一个广播包(或未知单播包)进入这样一个环形网络:
- 被交换机A转发到B
- B又从另一条线路转发回A
- A再次转发给B
- 如此无限循环
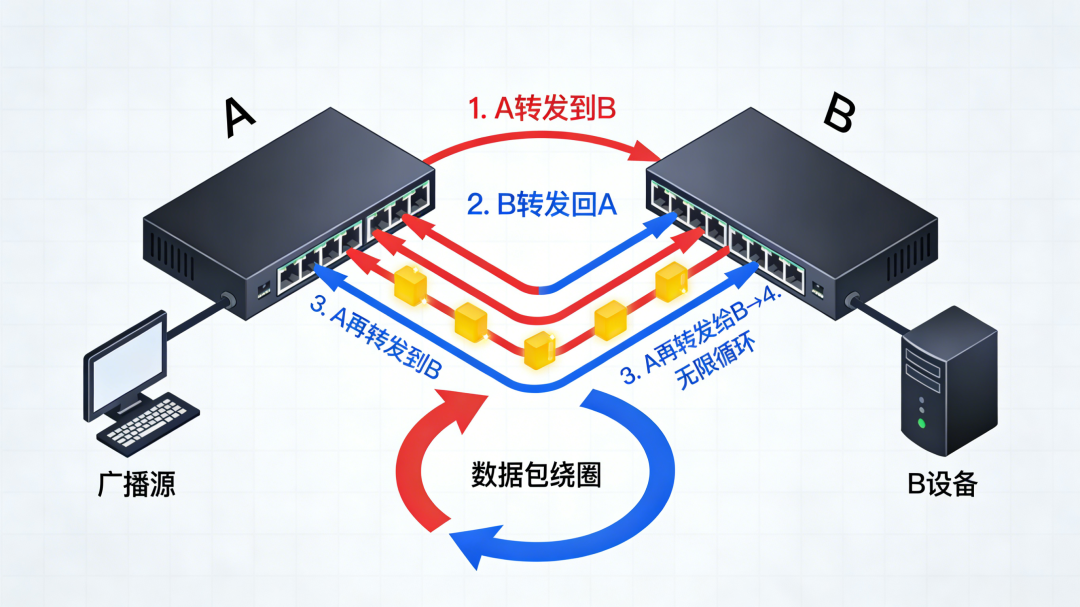
结果是灾难性的:
- 数据包数量指数级增长,迅速占满带宽
- 交换机MAC表因同一MAC地址在不同端口出现而频繁刷新(震荡)
- 交换机CPU因处理海量数据包而利用率飙高
- 最终引发全面的未知单播泛洪和广播风暴
可以说,环路是泛洪的最佳“加速器”。
实战:如何判断网络是否发生泛洪?
当你怀疑网络出现泛洪时,可以遵循以下逻辑进行排查。
① 看交换机关键状态
登录核心交换机,重点关注三个指标:
- CPU利用率:持续高于80%是高度可疑信号。
- 接口流量:查看是否所有端口流量都异常高。
- 广播/组播包比例:在接口计数中,如果广播包比例超过20%,网络已处于极度危险状态。
② 分析接口流量分布
泛洪通常不是均匀的,而是有“源头”的。问题往往集中在某几个端口或某个接入区域。使用命令查看流量概况:
show interface counters
show interface status
关注哪些端口的输入/输出流量(特别是广播、组播计数)异常高于其他端口。
③ 定位“异常端口”
最直接有效的方法是 “隔离法” 。在业务低峰期,逐个关闭疑似问题区域的接入端口,同时观察核心交换机CPU和整体网络流量变化。一旦关闭某个端口后网络立即恢复正常,问题源就找到了。这不是土办法,而是最高效的故障定位方法之一。
④ 确认问题根源设备
定位到具体端口后,检查其下联设备:
- 是否有人私接了小型交换机,并错误地连成了环路?
- 网线是否两头误插在同一台交换机的两个端口上?
- 终端设备(如服务器、IP摄像头)网卡或驱动是否有异常,疯狂发送广播包?
你会发现,许多引发大问题的根源,其实非常简单。
泛洪暴露的本质问题
表面看是流量问题,本质暴露的是网络架构与管理的缺陷:
- 网络结构过于扁平:大量设备处于同一广播域,缺乏VLAN隔离,一个点的故障容易扩散成面。
- 缺乏基础控制机制:未启用STP/RSTP防环路协议,没有配置广播风暴抑制,端口安全策略空白。
- 网络管理存在缺失:设备接入随意,物理拓扑不清晰,缺乏有效的网络流量监控告警。
低成本降低泛洪风险的实战建议
解决泛洪未必需要重构网络,实施以下几项措施就能极大提升网络韧性:
- 控制广播域规模:合理规划VLAN,避免单一VLAN内终端数量过多(通常建议不超过200个)。将不同部门、业务系统进行隔离。
- 启用基础防护功能:
- 务必启用STP(生成树协议):这是防止二层环路的底线。
- 配置广播风暴控制:在接入交换机端口上设置广播/组播流量抑制阈值。
- 配置端口安全:限制端口学习的MAC地址数量,防止MAC表攻击。
- 严格管理接入层:核心原则是不要让网络“随便被插”。规范布线,对不明接入设备保持警惕。
这里有一套排查口诀,方便你在实战中快速理清思路:
一看流量,二查端口
三断环路,四查STP
五看MAC,六查ARP
七控风暴,八改架构
如果你做过网络运维,定能体会一种无奈:故障发生时人人催促,解决后却无人知晓你付出的努力。只有你自己明白,一个简单的环路可能让整个业务停摆。交换机泛洪正是这类“隐形杀手”。
它不像服务器宕机那样显而易见,但一旦爆发,影响范围更广。很多时候,我们解决的并非高深的技术难题,而是在为“一个本可避免的低级错误”付出高昂的代价。
因此,一个真正成熟稳定的网络/系统,其价值不在于设备多么昂贵高级,而在于其具备“弹性”——即使出现了人为或意外的错误,也不会被一根接错的网线轻易拖垮整个体系。这,正是网络工程师的核心价值所在。
 发表于 2026-1-26 12:57:54
|
查看: 147|
回复: 0
发表于 2026-1-26 12:57:54
|
查看: 147|
回复: 0
