Cloudflare又出事了。
不得不说,在历次重大互联网基础设施故障中,目前也只有Cloudflare的“又”字用得如此频繁,颇有些“改了再犯,犯了再改”的意味。
2026年2月20日17:48(UTC时间,即北京时间2月21日凌晨),全球知名的网络服务与安全公司Cloudflare遭遇了一次严重的逻辑故障。在长达6小时7分钟的时间里,一场由其内部系统错误触发的 BGP撤回风暴 席卷全球,导致其BYOIP服务中约四分之一的IP前缀从互联网路由表中消失。诸多依赖其服务的大型平台,包括 Uber Eats、Wikipedia、Steam、Microsoft 365 乃至Cloudflare自家的 1.1.1.1 DNS解析服务均受到不同程度的影响。
但凡有故障,90%是运维造成的,9%与运维有关,本次故障也不例外。
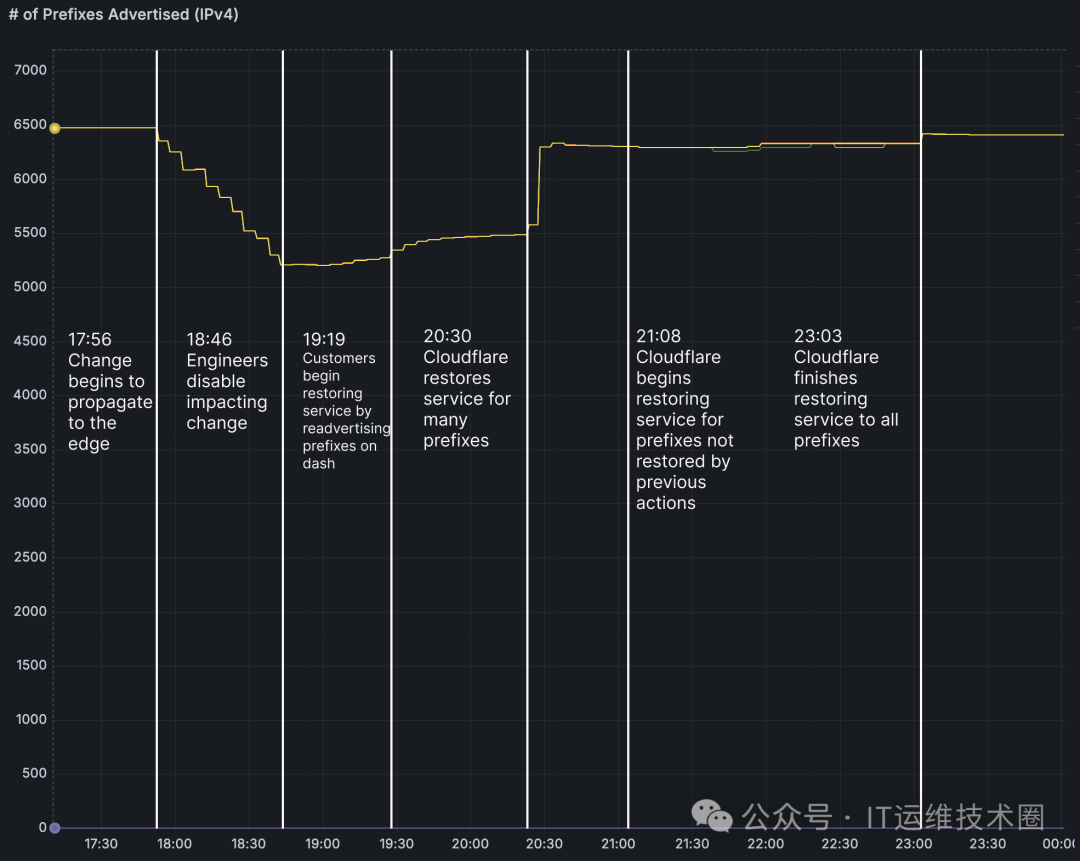
故障期间Cloudflare IPv4前缀广告数量的变化趋势图(来源:Cloudflare事件报告)
故障核心:一个“聪明”脚本的致命误解
这次事故的技术根源,指向Cloudflare内部一套名为 Addressing API 的系统。该API负责管理客户自带IP地址的广播与配置。
为了提高效率,工程师部署了一个用于清理“已废弃记录”子任务的自动化脚本。然而,这个脚本的逻辑中存在一个致命的缺陷:当API因故返回了空结果时,脚本并未执行“报错退出”的安全流程,而是错误地将“空结果”解读为“该账户下所有现有前缀都需要被删除”的指令。
这个逻辑漏洞可以类比为:你让扫地机器人清理房间里的垃圾,结果机器人因为没识别到任何垃圾,就判定需要把整栋房子拆掉。
连锁反应:BGP风暴与路由黑洞
就在这个错误指令被执行的几秒内,一场BGP撤回风暴瞬间形成。Cloudflare向全球的运营商网络广播了约 1,100个IP前缀的BGP Withdraw消息,这相当于其管理的BYOIP前缀总数的25%。顷刻间,互联网“地图”上出现了一个巨大的空洞。
全球网络随即陷入 BGP Path Hunting 状态。数据流量像无头苍蝇一样在残缺不全的网络路径中横冲直撞,试图寻找已经不存在的出口,最终导致大面积的连接超时和错误(如403、502状态码)。
雪上加霜:状态机锁死与自救无门
更糟糕的是,Addressing API的内部状态机在处理删除任务时进入了“删除中”的挂起状态。这个状态无法被常规操作中断或终止。于是,即便那些受影响的顶级客户心急如焚地登录Cloudflare控制面板,他们看到的“恢复”按钮也处于灰色不可点击的状态。
这种 “前缀锁死” 的局面使得技术团队通过常规途径进行的自救变得极其困难。最终,Cloudflare工程师不得不采取非常手段——直接强制重置API后端数据库的状态,才在数小时后强行解锁了这些前缀,并重新推送了恢复广播指令。用更直白的话说,就是业务逻辑彻底卡死,最终靠直接修改底层数据库数据才解决了问题。
反思:为何“Fail Small”机制失效了?
颇具讽刺意味的是,Cloudflare在此次事件前不久,刚刚启动了一项名为 “Fail Small” 的计划。该计划的初衷正是通过架构隔离,将潜在故障的影响范围控制在局部,避免引发全局性瘫痪。
然而,本次的逻辑错误直接发生在最核心的中央API层,这个层面管理着所有客户的前缀。漏洞一经触发,便如心脏骤停般瞬间影响到所有关联服务,使得为“局部失败”设计的隔离机制完全失效。
从事故到经验:透明化的价值
此次事件中,Cloudflare值得肯定的一点是其事故报告的透明度与及时性。官方不仅迅速发布了详尽的技术复盘报告,还主动提供了包括日语、韩语、简体及繁体中文在内的多语言版本,面向全球用户解释故障根因与恢复过程。
这种将重大故障详细公之于众的做法,在互联网巨头中并不多见。它虽然意味着将自身错误暴露在所有人面前,供业界“笑话”或分析一次,但长远看,这种透明化对于建立技术公信力、推动整个行业对复杂系统脆弱性的认知,具有不可替代的价值。
每一次这样的事故报告,都是对整个互联网基础设施稳定性与可靠性的一次集体反思,相关从业者可以在像云栈社区这样的平台进行更深入的交流与学习。
(Cloudflare官方完整事件报告原文链接:https://mp.weixin.qq.com/s?__biz=MzU5NDg5MzM5NQ==&mid=2247512885&idx=1&sn=c79278838e097731debdb548fc4be66e&scene=21#wechat_redirect)
 发表于 2026-2-26 05:10:28
|
查看: 262|
回复: 0
发表于 2026-2-26 05:10:28
|
查看: 262|
回复: 0
