前言
凌晨两点,手机突然震动。
监控报警:服务器响应延迟从 50ms 飙到 3 秒,CPU 告警。
你打开终端,面对一台“生病”的机器,脑子一片空白,不知道从哪里下手。
这种场景,几乎每个后端工程师都经历过。
这篇文章给你一套可以照着操作的排查流程,从收到报警到定位根因,覆盖 CPU、内存、磁盘 IO、网络四个维度,每步用什么命令、看什么指标,说清楚。
一、先建立全局视角:top / htop
收到报警第一件事,不是立刻猜哪里出问题,而是先看整体。
top
top 的输出很密,先只看这几个关键位置:
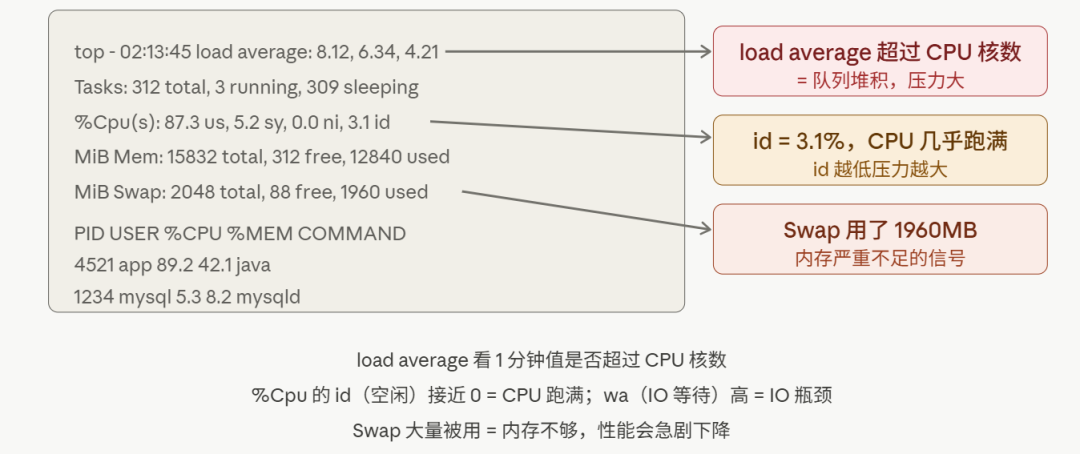
看完 top 的全局数据,接下来根据哪个维度异常进入对应的专项排查。四个方向,各自有一套命令链路。
二、CPU 异常排查
现象:CPU 使用率居高不下,或 load average 远超核数
第一步:找出耗 CPU 最多的进程
# top 里按 P 键(按 CPU 排序,默认就是)
top
# 或者 ps,精确到进程
ps aux --sort=-%cpu | head -10
第二步:确定是用户态还是内核态
top 里 %Cpu 那行:
us(user)高:业务逻辑 CPU 密集,或者有死循环sy(system)高:大量系统调用,可能是频繁 fork()、过多 IO 操作wa(iowait)高:CPU 在等磁盘,瓶颈在 IO 不在 CPU,跳到第四节排查
第三步:定位到具体线程
# 找出进程 4521 下哪个线程最耗 CPU
top -H -p 4521
# 把线程 TID 转成十六进制,对应 gdb/jstack 里的线程 ID
printf '%x\n' <TID>
第四步:用 strace 看它在干什么
strace -p 4521 -c # 统计模式,看哪个系统调用调用最频繁
上篇 strace 文章讲的用法,这里直接上场。
常见 CPU 高的根因:
- 死循环(某个 while 条件永远为真)
- 正则表达式灾难性回溯
- 频繁 GC(Java 程序 Old Gen 满了)
- 大量并发请求导致上下文切换过多
三、内存异常排查
现象:内存使用率持续上涨,或 OOM Killer 频繁杀进程
第一步:看内存整体情况
free -h
# 重点看 available(真正可用),不是 free
# Swap 有大量使用说明物理内存已经不够了
cat /proc/meminfo | grep -E "MemTotal|MemFree|MemAvailable|Cached|SwapUsed"
第二步:找内存占用最多的进程
ps aux --sort=-%mem | head -10
# 查看某进程的详细内存分布
cat /proc/<pid>/status | grep -E "VmRSS|VmSwap|VmSize"
第三步:判断是泄漏还是正常增长
# 持续观察进程内存,每2秒刷新一次
watch -n 2 'cat /proc/<pid>/status | grep VmRSS'
# 如果 VmRSS 一直涨,从不下降,基本就是内存泄漏
第四步:检查 OOM 记录
dmesg | grep -i "oom\|killed process" | tail -20
# 如果有 OOM 记录,说明已经有进程被内核杀过了
有了之前 OOM Killer 那篇的基础,看到这段日志就知道哪个进程的 oom_score 被打高了。
常见内存问题根因:
- C/C++ 程序内存泄漏(
malloc 了不 free)
- Java 堆内存配置过小,频繁触发 Full GC
- 内存碎片化严重(用
jemalloc 替换 ptmalloc 可缓解)
- 单个进程占用内存过大,挤压其他服务
四、磁盘 IO 异常排查
现象:服务响应慢,CPU 的 wa 指标偏高,磁盘读写告警
第一步:确认 IO 瓶颈
iostat -x 1 5
# -x 显示扩展指标,1秒刷新一次,共5次
重点看这几列:

第二步:找出哪个进程在猛读写磁盘
# 实时显示各进程的磁盘 IO 占用
iotop -o # -o 只显示有 IO 活动的进程
第三步:如果是日志/数据库写入导致的,检查 Page Cache
回忆上一篇 Page Cache 文章:write() 默认先写 Page Cache,内核异步刷盘。如果程序有大量 fsync(),每次都要等磁盘,await 就会飙高。
# 查看脏页数量,如果很大说明积压了大量待刷数据
cat /proc/meminfo | grep -i dirty
常见 IO 问题根因:
- 数据库没有走索引,全表扫描产生大量随机 IO
- 日志级别太低(DEBUG 级别),每条请求都写日志
- 没有正确配置
fsync 策略,每次写入都等磁盘
- SSD 写入放大,大量小块随机写(
fio 可以测试)
五、网络异常排查
现象:接口超时、连接数打满、TIME_WAIT 堆积
第一步:看整体网络连接状态
# 统计各状态的 TCP 连接数
ss -s
# 详细看当前所有连接
ss -tan | awk '{print $1}' | sort | uniq -c | sort -rn
输出大概长这样:
2341 TIME_WAIT ← 太多说明短连接频繁,之前 TIME_WAIT 篇讲过
512 ESTABLISHED ← 正常连接数
48 CLOSE_WAIT ← 多了说明有连接没有正常关闭,代码有 bug
3 LISTEN
CLOSE_WAIT 是一个特别值得关注的状态——它意味着对端已经关闭连接(发了 FIN),但本端还没有调用 close()。如果 CLOSE_WAIT 持续积累,通常是代码里没有正确关闭连接。
第二步:看端口连接和带宽
# 查看哪个端口连接最多
ss -tan | grep ESTABLISHED | awk '{print $5}' | cut -d: -f2 | sort | uniq -c | sort -rn
# 实时查看网络带宽使用
iftop -n # 按连接维度
nethogs # 按进程维度(哪个进程在吃带宽)
第三步:排查丢包和延迟
# 基本连通性和延迟
ping -c 10 <目标IP>
# 看路由路径,找延迟在哪一跳
traceroute <目标IP>
# 抓包,真正看数据在传什么
tcpdump -i eth0 -w /tmp/capture.pcap port 8080
# 然后用 Wireshark 打开分析
第四步:检查内核网络参数
# 查看连接队列是否有溢出(SYN flood 或并发过高时会满)
ss -lnt # 看 Send-Q 列,如果持续非0说明队列满了
netstat -s | grep -i "listen\|overflow\|drop"
常见网络问题根因:
- TIME_WAIT 过多导致端口耗尽(
SO_REUSEADDR 和连接池可解决)
- CLOSE_WAIT 积累(代码没有正确关闭连接)
- 带宽打满(大文件传输、日志采集等占满上行带宽)
- DNS 解析慢(每次请求都 DNS 查询且没有缓存)
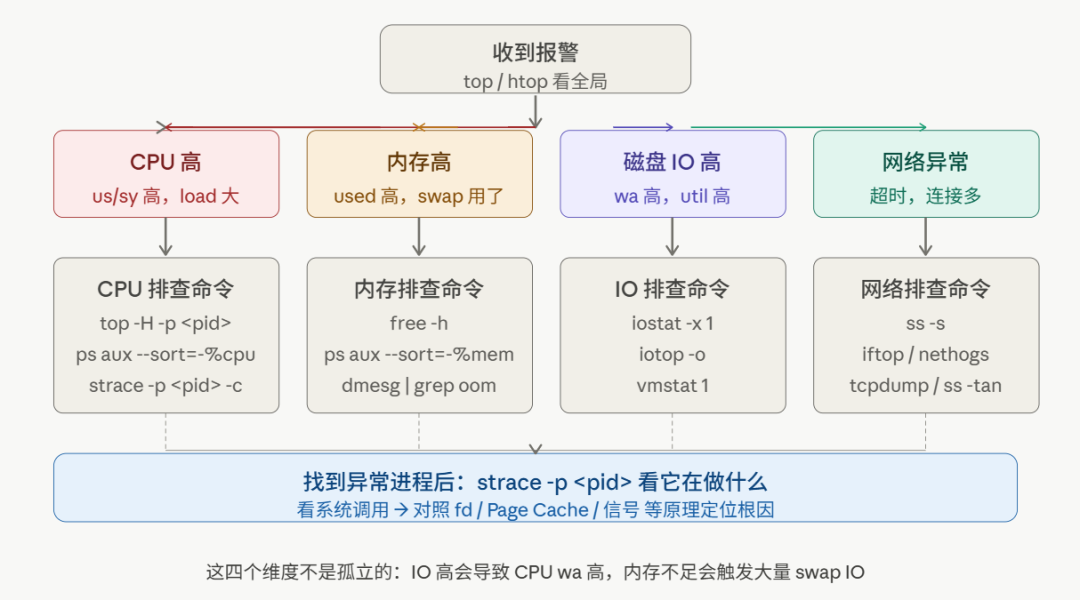
六、四维排查的完整决策图
把上面的流程整理成一张决策图,收到报警的时候对着查:
七、一个完整的真实排查案例
把上面的流程串一遍,看一个真实场景:
现象:下午 3 点接到报警,API 响应时间从 80ms 涨到 2 秒,CPU 告警。
第一步:top 看全局
load average: 12.3, 8.1, 5.2 ← 明显超过 CPU 核数(8核)
%Cpu: 42 us, 8 sy, 0 ni, 2 id, 45 wa ← wa=45%!IO 等待极高
MiB Mem: 15832 total, 892 free
wa 高 → 不是 CPU 问题,是 IO 问题。CPU 在等磁盘。
第二步:iostat 确认 IO 瓶颈
iostat -x 1
# sda r/s=2 w/s=4800 await=120ms %util=98%
%util=98%,磁盘已经跑满。每秒 4800 次写入,await 高达 120ms。
第三步:iotop 找到是谁在写
PID DISK READ DISK WRITE COMMAND
4521 0.00 B/s 480 M/s java
Java 进程在疯狂写磁盘,每秒 480MB。
第四步:strace 看写的是什么
strace -p 4521 -e write 2>&1 | head -20
# write(3, "DEBUG 2024-03-15 ...", 256) = 256
# write(3, "DEBUG 2024-03-15 ...", 256) = 256
# ...无限循环...
全是 DEBUG 级别日志在写文件 fd=3。
根因:有人在生产环境打开了 DEBUG 日志,每个请求写十几条 DEBUG 日志,高峰期请求量一上来,直接把磁盘 IO 打满。
修复:关掉 DEBUG 日志,CPU wa 立刻从 45% 降到 2%,响应时间回到 80ms。
八、最常用命令速查表
收藏起来,下次遇到报警直接翻:
# ===== 全局 =====
top # 实时全貌,按 M 内存排序,按 P CPU排序
vmstat 1 # 每秒刷新,看 CPU/内存/IO 综合指标
uptime # 快速看 load average
# ===== CPU =====
ps aux --sort=-%cpu | head # CPU 占用 TOP 进程
top -H -p <pid> # 看进程内线程 CPU
perf top # 函数级 CPU 热点(高级)
# ===== 内存 =====
free -h # 内存概况
ps aux --sort=-%mem | head # 内存占用 TOP 进程
cat /proc/<pid>/status # 某进程内存详情
dmesg | grep oom # OOM 历史记录
# ===== IO =====
iostat -x 1 # 磁盘 IO 详情
iotop -o # 哪个进程在读写
lsof +D /path # 谁打开了某目录下的文件
# ===== 网络 =====
ss -s # TCP 连接状态统计
ss -tan | grep TIME_WAIT | wc -l # TIME_WAIT 数量
iftop -n # 实时网络流量(按连接)
nethogs # 实时网络流量(按进程)
tcpdump -i eth0 port 8080 # 抓包
# ===== 通用深挖 =====
strace -p <pid> # 看进程在做什么系统调用
lsof -p <pid> # 看进程打开了哪些文件/连接
写在最后
服务器排查从来不是运气,是一套系统化的思维方式:
先看全局(top)→ 判断哪个维度异常 → 找到异常的进程 → 用 strace / lsof 看它在做什么 → 结合内核原理理解根因。
这篇文章涉及的所有工具和原理,在之前的系列里都讲过:strace 怎么用、Page Cache 为什么影响 IO 性能、OOM Killer 为什么杀了意料之外的进程、TIME_WAIT 为什么会堆积……一篇一篇积累下来,排查的时候就能快速对号入座。
知识要用起来才算真正掌握。如果你也希望在真实的项目中打磨这些技术直觉,而不是停留在理论层面,不妨在云栈社区找找灵感,和更多同行交流实战踩坑经验。
 发表于 2026-5-7 20:36:46
|
查看: 137|
回复: 0
发表于 2026-5-7 20:36:46
|
查看: 137|
回复: 0
