前两天有个刚毕业的学生半夜找我哭诉:“今天去面字节,二面面试官让我画C++程序的内存布局图,还问我为什么堆比栈慢,我支支吾吾半天没答上来,是不是凉了?”
我听完一点也不意外。很多学C++的同学写代码,变量随手就写,new完了全靠信仰,根本不知道这些数据在底层是怎么住进内存这栋大楼的。实际上,只要你做C++后台开发,哪怕只是写个极其简单的业务逻辑,不懂内存分区,你写出来的代码就是埋在服务器里的一颗定时炸弹。
我刚带团队那会儿,有个实习生在一个高并发的回调函数里疯狂 new 大数组,还忘了释放。结果周末服务器直接OOM(Out Of Memory)挂掉,公司损失惨重,我跟着熬了两个通宵抓Dump查内存泄漏。
1. 程序的五层大楼:内存布局全景图
当你的C++代码被编译成二进制可执行文件,并被操作系统加载到内存中跑起来时,它拥有的是一片虚拟内存空间。为了管理方便,操作系统把这片空间严丝合缝地划分成了五个区域。
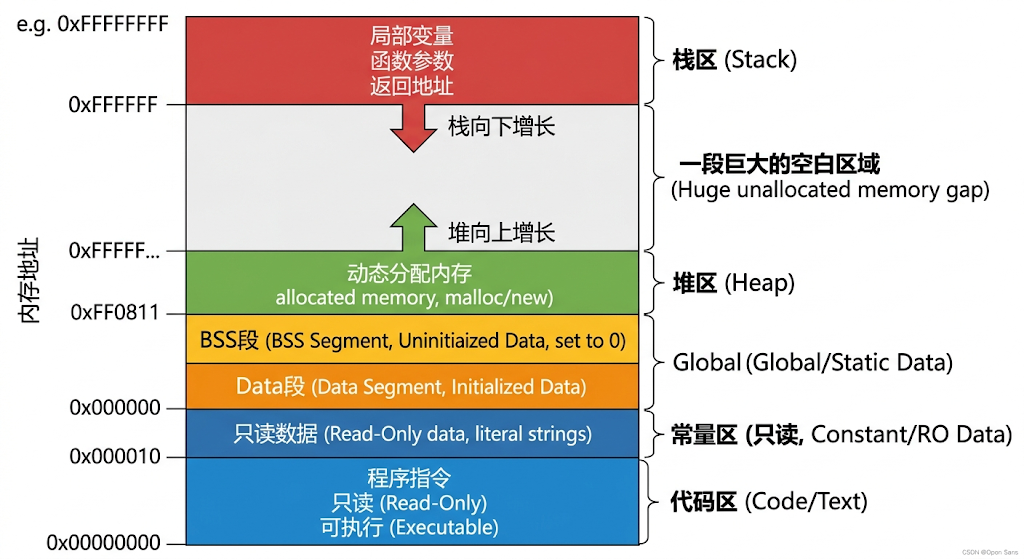
咱们从下往上(也就是从低地址到高地址),一层层往上爬:
第一层:代码区(Text Segment)
这里存放着你写的每一句代码翻译成的CPU机器指令。
- 特点: 绝对的只读。你的程序在跑的时候,总不能自己把自己的执行逻辑给改了吧?
第二层:常量区(Read-Only Data)
专门用来存放常量,比如你写的字符串字面量 “Hello World” 或者被 const 修饰的全局常量。
- 特点: 也是只读的。如果你硬要搞个指针指过去,然后强行修改它的值,程序会直接报段错误(Segmentation Fault)当场死给你看。
第三层:全局/静态区(Global/Static Area)
这里住着全局变量和用 static 修饰的静态变量。这层楼在程序启动时就盖好了,直到程序结束才会被拆除。为了优化执行文件的大小,编译器把它细分成了两个单间:
- Data段(已初始化数据段): 存放那些在代码里已经明确给了初值的全局/静态变量(比如
int g_val = 10;)。
- BSS段(未初始化数据段): 存放没有给初值,或者初值为0的全局/静态变量。系统会在程序跑起来前,贴心地把这块区域全填上0。
第四层和第五层:堆(Heap)与栈(Stack)
这是咱们程序员日常打交道最多、也最容易翻车的两个区域。它们的空间是动态伸缩的,中间隔着一片巨大的无人区,堆底朝上增长,栈顶朝下增长,就像两支相向而行的施工队。
2. 冰与火之歌:栈(Stack) vs 堆(Heap)
面试官最爱抓着问的,就是这两者的区别。很多人只会背“栈是系统分配,堆是手动分配”,这就太浅了。咱们往深了剖析。
🚀 栈区(Stack):风驰电掣的“快餐店”
栈是给函数用来存放局部变量、函数参数、甚至返回地址的地方。
- 管理方式: 纯自动。函数一执行,系统立马在栈上划出一块地;函数一执行完,系统一脚把这块地踢走。
- 生长方向: 向下增长(从高地址向低地址蔓延)。
- 大小限制: 非常抠门!在Linux/Windows下,栈的默认大小通常只有1MB到8MB。
- 分配效率: 极致的快!栈的操作是由CPU的指令直接支持的,压栈(push)出栈(pop)只需要挪动一下栈顶寄存器的指针。
因为栈空间极小,千万不要在栈上开超级大的数组(比如 int arr[1000000];),也不要写那种没有底线的深度递归函数。否则,“砰”的一声,Stack Overflow(栈溢出),你的程序就灰飞烟灭了。
🐌 堆区(Heap):自由广阔但昂贵的“大卖场”
当你使用 new 或者 malloc 时,要的空间就是在堆上。
- 管理方式: 纯手动。你不仅要自己申请,还必须亲自调用
delete 或 free 释放。
- 生长方向: 向上增长(从低地址向高地址蔓延)。
- 大小限制: 财大气粗!理论上讲,在32位系统下堆能达到将近4GB,在64位系统下更是大到离谱,只要你物理内存和虚拟内存够,它就能给。
- 分配效率: 慢!非常慢!当你
new 一个对象时,底层(C库的内存分配器)要在堆那一大片乱糟糟的内存块里,通过遍历链表去寻找一块大小合适的空闲内存。如果找不到,还得向操作系统要。更别提频繁申请释放还会造成大量的“内存碎片”。
现在你明白为什么堆比栈慢了吗?栈的分配是硬件级别的指针移动,而堆的分配是一套复杂的软件逻辑,包含了查找、合并、系统调用等开销。在C++高性能编程中,这是一个必须理解的基础。
3. 致命杀手:内存泄漏(Memory Leak)
很多新手写代码,享受了堆带来的海量空间,却不想承担打扫战场的责任。这就引出了C++后台开发最臭名昭著的幽灵——内存泄漏。
咱们来看一段典型的“犯罪现场”代码:
#include <iostream>
void process_data() {
// 在堆上大手一挥,申请了大约 4MB 的内存
int* huge_data = new int[1024 * 1024];
// ... 假设这里有一堆复杂的业务处理 ...
// 完蛋!函数结束了,老哥忘了写 delete[] huge_data;
}
int main() {
for (int i = 0; i < 1000; ++i) {
process_data(); // 疯狂调用
}
std::cout << “业务处理完毕” << std::endl;
return 0;
}
在这个 process_data 函数里,huge_data 这个指针变量本身是存在栈上的。函数一旦执行完,栈被回收,指针变量 huge_data 随风消散了。 但是!它刚才用 new 在堆上开辟的那 4MB 的空间,操作系统可是认为是“已占用”状态。 现在好了,唯一记住这块堆内存地址的栈指针被销毁了。这就好比你租了一个仓库,把东西放进去之后,不小心把钥匙和地址全给烧了。这块仓库既不属于你,房东也不能租给别人,彻彻底底成了“死空间”。
在长连接的服务器程序里,这种函数如果被调用个几万次,几十个GB的内存就会被慢慢蚕食殆尽,最后直接OOM,导致服务崩溃。
正确的姿势是什么?
一定要保证 new 和 delete 成对出现。当然,实战中老司机早就不用这种裸指针来考验人性了,咱们现在的标准规范是全面拥抱智能指针(Smart Pointers, 如 std::unique_ptr),利用 RAII(资源获取即初始化)的特性,把堆内存的生命周期绑定到栈对象上。栈对象一销毁,自动触发析构函数帮你 delete 堆内存,从源头上杜绝了忘记释放的问题。
下次面试官再让你聊C++内存分区,你就把这幅五层大楼的图在脑海里过一遍,把堆栈的核心区别和性能差异给他分析得明明白白,最后再顺嘴提一句使用智能指针解决堆内存泄漏的实战经验。你的专业度绝对会让他印象深刻。
理解内存分区是写好健壮、高效C++代码的基石。自己写代码的时候,多在脑子里画画这五大区。如果你想系统性地与更多开发者交流这类底层技术问题,可以来云栈社区逛逛,那里有很多关于C++和后端架构的深度讨论。
 发表于 2026-3-20 12:15:39
|
查看: 77|
回复: 0
发表于 2026-3-20 12:15:39
|
查看: 77|
回复: 0
