背景
早上 9 点 34 分,系统监控发出 JVM 内存占用过高的报警。

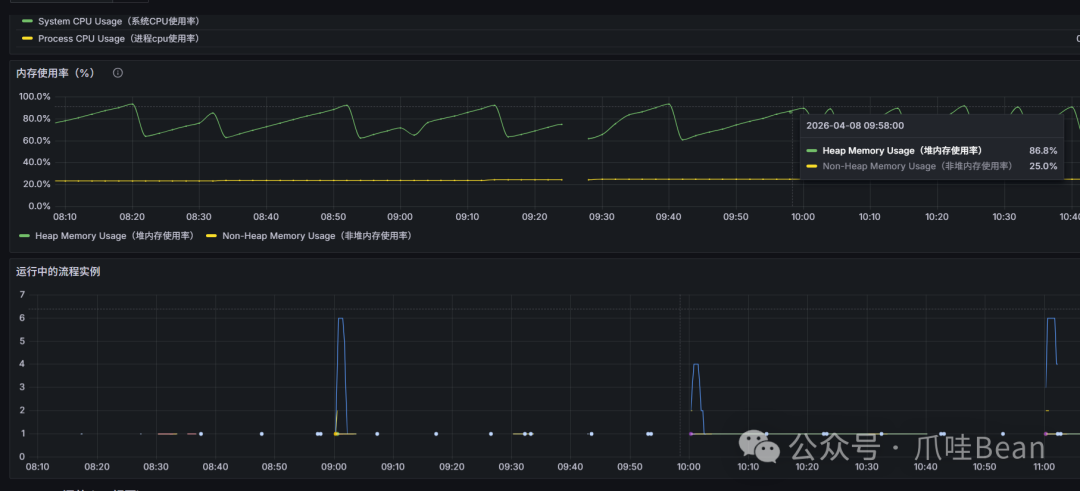
登录 Grafana 查看系统占用情况,发现从 9 点 35 分开始,没有任何业务进程在执行,但内存占用率居高不下,持续观察几分钟后情况依然没有变化。
开始排查
立刻登录服务器,开始对 JVM 内存的详细占用情况进行排查。
1. 查看内存中对象直方图
首先,使用 jmap -histo 命令快速查看堆内存中哪些对象占用了大量空间。
[jenkins@jt-kaifa-app ~]$ ps -ef | grep java # 查看8881 java进程号
[jenkins@jt-kaifa-app ~]$ cd /data/tools/jdk21/bin # cd 到 jdk bin 目录
[jenkins@jt-kaifa-app bin]$ ls
jar java javadoc jcmd jdb jdeps jhsdb jinfo jmap jpackage jrunscript jstack jstatd keytool serialver
jarsigner javac javap jconsole jdeprscan jfr jimage jlink jmod jps jshell jstat jwebserver rmiregistry
[jenkins@jt-kaifa-app bin]$ sudo ./jmap -histo 15848 | head -30
num #instances #bytes class name (module)
-------------------------------------------------------
1: 10757711 1191171128 [Ljava.lang.Object; (java.base@21.0.5)
2: 1231953 877362976 [I (java.base@21.0.5)
3: 378839 713984048 [Ljdk.internal.vm.FillerElement; (java.base@21.0.5)
4: 19113922 611645504 java.util.HashMap$Node (java.base@21.0.5)
5: 10574310 575414680 [J (java.base@21.0.5)
6: 4921585 504043712 [B (java.base@21.0.5)
7: 17108100 410594400 com.fasterxml.jackson.databind.type.ClassKey
8: 4731705 339114256 [Ljava.util.HashMap$Node; (java.base@21.0.5)
9: 1369285 324619496 [Ljava.lang.String; (java.base@21.0.5)
10: 4570927 292539328 java.util.concurrent.ConcurrentHashMap (java.base@21.0.5)
11: 3421835 273746800 com.fasterxml.jackson.databind.util.internal.PrivateMaxEntriesMap
12: 3954296 221440576 java.nio.HeapCharBuffer (java.base@21.0.5)
13: 4133491 198407568 java.util.HashMap (java.base@21.0.5)
14: 6939909 166557816 java.util.concurrent.atomic.AtomicLong (java.base@21.0.5)
15: 4093315 156108688 [C (java.base@21.0.5)
16: 6230101 149522424 java.util.ArrayList (java.base@21.0.5)
17: 3599029 143961160 java.util.LinkedHashMap$Entry (java.base@21.0.5)
18: 4483728 143479296 java.util.concurrent.locks.ReentrantLock$NonfairSync (java.base@21.0.5)
19: 6843688 109499008 java.util.concurrent.atomic.AtomicLongArray (java.base@21.0.5)
20: 3328158 106501056 org.springframework.http.MediaType
21: 1265477 91114344 java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask (java.base@21.0.5)
22: 3732805 89587320 java.lang.String (java.base@21.0.5)
23: 1376234 88078976 java.util.LinkedHashMap (java.base@21.0.5)
24: 3612213 86693112 java.util.concurrent.ConcurrentLinkedQueue$Node (java.base@21.0.5)
25: 3423544 82165056 java.util.concurrent.ConcurrentLinkedQueue (java.base@21.0.5)
26: 3421835 82124040 com.fasterxml.jackson.databind.util.LRUMap
27: 3421835 82124040 com.fasterxml.jackson.databind.util.internal.LinkedDeque
28: 4854878 77678048 java.util.concurrent.atomic.AtomicReference (java.base@21.0.5)
含义:查看内存中对象的直方图(统计前 30 行)
jmap -histo: 生成 Java 堆中对象的统计信息。它列出了每种特定类型的对象数量及所占用的字节数。- 作用: 快速判断哪些类占据了大部分内存。
- 分析输出:
[Ljava.lang.Object;: 这是对象数组,占用内存最高(约 1.19 GB)。java.util.HashMap$Node: HashMap 的节点,数量高达 1900 万个。com.fasterxml.jackson.databind.type.ClassKey: 这是 Jackson(JSON 处理库)相关的类。
- 关键点:
Jackson 相关的类(如 ClassKey, LRUMap, PrivateMaxEntriesMap)频繁出现且数量巨大(百万级)。这通常暗示 Jackson 的类型缓存或对象映射器(ObjectMapper)配置不当,导致了严重的内存积压。
2. 监控垃圾回收
接着,使用 jstat 命令查看实时的垃圾回收状态。
[jenkins@jt-kaifa-app bin]$ sudo ./jstat -gcutil 15848 1000 10
S0 S1 E O M CCS YGC YGCT FGC FGCT CGC CGCT GCT
- 97.08 30.48 94.02 98.99 95.65 2364 51.352 0 0.000 1446 6.743 58.095
- 97.08 30.65 94.02 98.99 95.65 2364 51.352 0 0.000 1446 6.743 58.095
- 97.08 30.81 94.02 98.99 95.65 2364 51.352 0 0.000 1446 6.743 58.095
- 97.08 30.81 94.02 98.99 95.65 2364 51.352 0 0.000 1446 6.743 58.095
- 97.08 30.81 94.02 98.99 95.65 2364 51.352 0 0.000 1446 6.743 58.095
- 97.08 30.81 94.02 98.99 95.65 2364 51.352 0 0.000 1446 6.743 58.095
- 97.08 30.97 94.02 98.99 95.65 2364 51.352 0 0.000 1446 6.743 58.095
- 97.08 31.13 94.02 98.99 95.65 2364 51.352 0 0.000 1446 6.743 58.095
- 97.08 31.13 94.02 98.99 95.65 2364 51.352 0 0.000 1446 6.743 58.095
- 97.08 31.29 94.02 98.99 95.65 2364 51.352 0 0.000 1446 6.743 58.095
含义:每秒监控一次垃圾回收(GC)状态,共执行 10 次
jstat -gcutil: 总结垃圾回收统计信息。- 参数:
1000 表示采样间隔 1000ms(1秒),10 表示采样 10 次。
- 列含义:
- S1: 幸存者 1 区占用 97.08%,非常满。
- E: 伊甸园区(Eden)占用约 31%,正在缓慢增长。
- O (Old): 老年代占用 94.02%。这是一个危险信号,说明大部分内存已经被占满,接近触发 Full GC 的边缘。
- M / CCS: 元空间占用约 98% / 95%,说明加载的类非常多。
- YGC: 已发生 2364 次轻量级 GC。
- CGC / CGCT: 现代垃圾回收器(如 G1 或 ZGC)的并发回收次数和时间。
- 结论: 内存压力极大,老年代几乎填满,系统可能存在内存泄漏或堆空间分配不足。
3. 统计线程总数
[jenkins@jt-kaifa-app bin]$ ps -Lf 15848 | wc -l
314
含义:统计该进程下的线程总数
ps -Lf: 列出指定进程的所有 LWP(轻量级进程,即线程)。wc -l: 统计行数。- 分析: 输出
314。对于一个中大型 Spring Boot 或微服务应用,314 个线程属于正常范围,目前看不出明显的线程泄露。
4. 转储Dump文件
为了进行更深入的分析,需要生成一个完整的堆转储文件。
[jenkins@jt-kaifa-app bin]$ sudo ./jmap -dump:live,format=b,file=8881heap.hprof 15848
Dumping heap to /data/tools/jdk21/bin/8881heap.hprof ...
Heap dump file created [14360374537 bytes in 52.589 secs]
含义:导出内存堆转储(Heap Dump)文件
-dump:live: 只导出存活的对象(在导出前会强制触发一次 Full GC,剔除可回收对象)。format=b: 以二进制格式导出。file=8881heap.hprof: 指定生成的文件名。- 分析: 文件大小为 14,360,374,537 字节(约 13.3 GB)。
5. 使用JProfiler深度分析
将生成的 hprof 文件下载到本地,使用专业的 Java 性能分析工具 JProfiler(可从 https://www.ej-technologies.com/jprofiler/download15 下载)进行深度分析。
使用激活码 S-J15-NEO_PENG#890808-1a6eo5gvl1w9v#b6bab 激活后,打开转储文件。
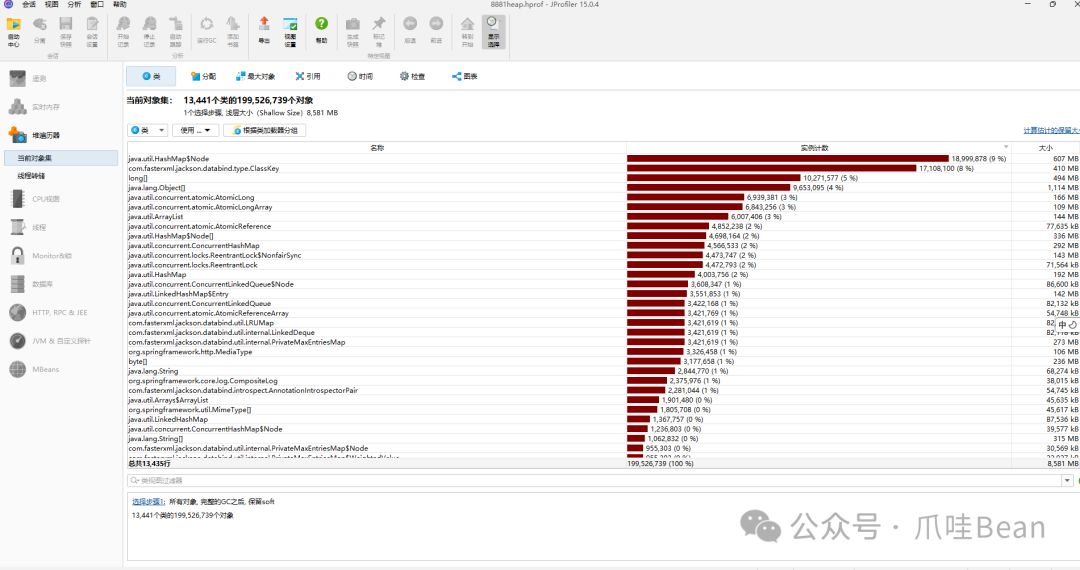
从概览中看到 java.util.HashMap$Node 和 com.fasterxml.jackson.databind.type.ClassKey 数量异常庞大。右键点击 HashMap$Node,选择“使用选定对象”进行进一步分析。
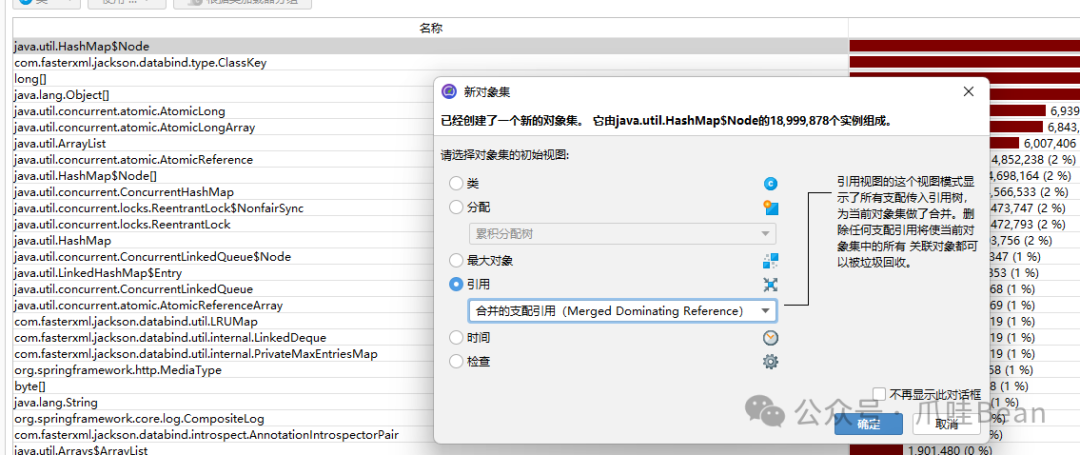
分析结果揭示了对象的引用链。
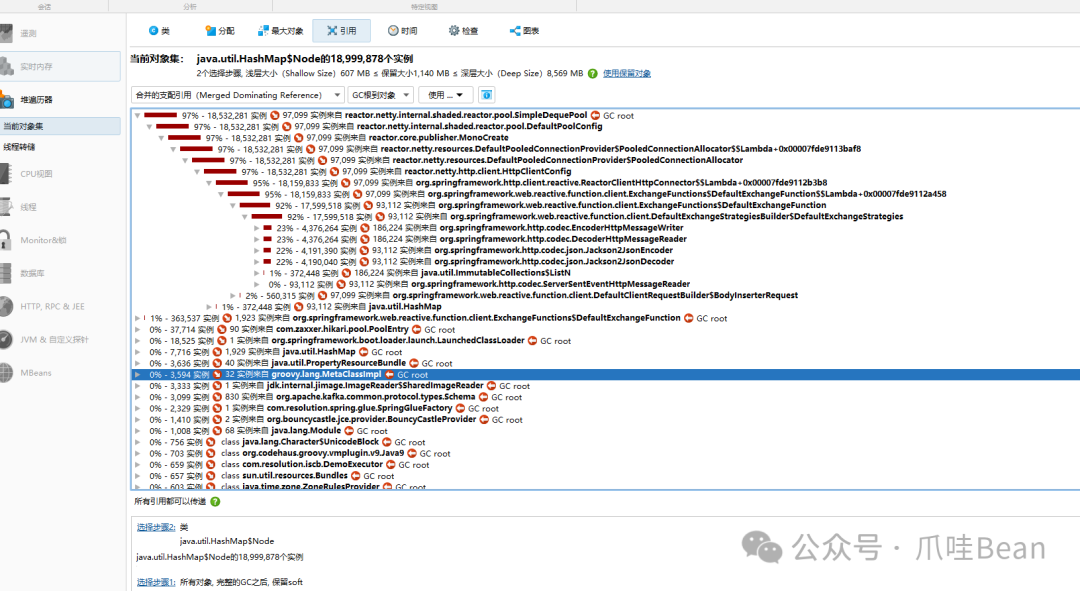
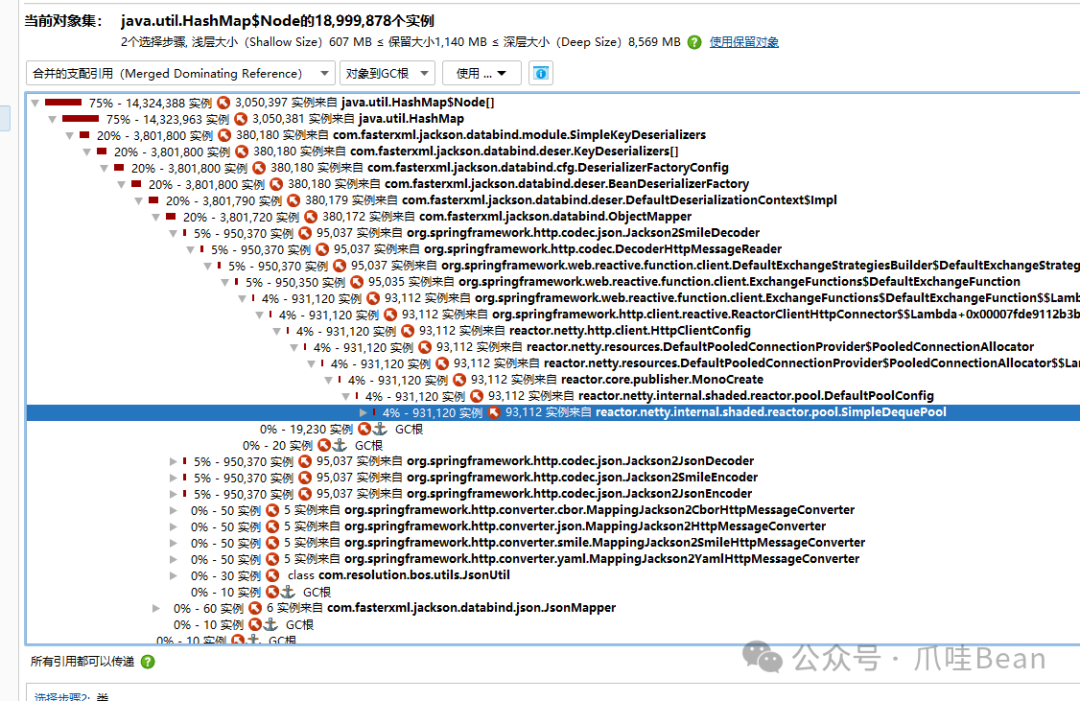
6. 初步定位与AI辅助分析
将 JProfiler 的分析截图提交给 AI 工具,请求其作为资深 Java 工程师帮助分析。
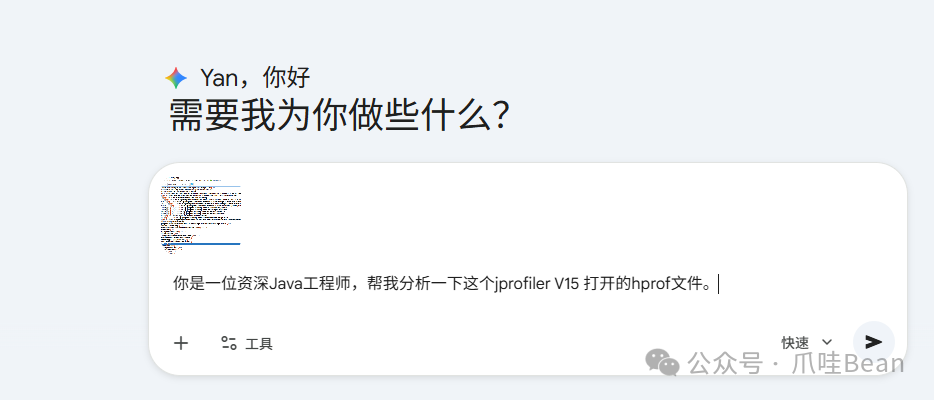
AI 分析后给出了初步诊断,指出问题很可能与 WebClient 的滥用、连接池泄漏或响应式流未终止有关。

7. 根因确认
根据 AI 的指向,检查相关代码。发现应用中的一个 ApiClient 类,为了实现动态超时配置,在 setTimeOut 方法中,一旦连接或响应超时参数发生变化,就会重新创建 WebClient 实例。
AI 进一步解释了这种做法的危害:频繁创建新的 WebClient 会导致旧的配置对象(包含 Lambda、ExchangeStrategies 和 Jackson 的 ObjectMapper)被底层 Netty 连接池“绑架”而无法释放,最终引发内存泄漏。
/**
* 同时设置连接超时和响应超时(立即生效)
*
* @param connectTimeoutSeconds 连接超时秒数
* @param responseTimeoutSeconds 响应超时秒数
*/
public void setTimeOut(int connectTimeoutSeconds, int responseTimeoutSeconds) {
Duration newConnectTimeout = Duration.ofSeconds(connectTimeoutSeconds);
Duration newResponseTimeout = Duration.ofSeconds(responseTimeoutSeconds);
// 只有当超时参数发生变化时才重新创建WebClient
if (!this.connectTimeout.equals(newConnectTimeout) || !this.responseTimeout.equals(newResponseTimeout)) {
this.connectTimeout = newConnectTimeout;
this.responseTimeout = newResponseTimeout;
this.webClient = createWebClient(); // 重新创建WebClient使配置生效
}
}


修改方案
定位到根本原因后,对代码进行如下重构:
-
不再动态重建 WebClient
移除/停用 setConnectTimeout、setResponseTimeout、setTimeout 这类会触发 createWebClient() 的方法,避免不断创建新的 ExchangeStrategies / ObjectMapper 链。
-
连接超时固定化
CONNECT_TIMEOUT_MILLIS 使用固定默认值(如 5s)在初始化时配置一次。连接超时属于 Netty 连接建立阶段参数,不适合按请求频繁动态切换。
-
响应超时请求级可传入
在 get / post / put / json 等方法中增加带 Duration responseTimeout 参数的重载版本。在内部请求执行逻辑中,使用 Mono.timeout(effectiveTimeout) 来实现单次请求级别的超时控制。
-
共享编解码策略
将 ExchangeStrategies 提升为 static final(例如 SHARED_STRATEGIES),这样整个应用复用同一套 Jackson 编解码器,从根本上避免 ObjectMapper 相关缓存对象的重复膨胀。
通过以上优化,系统内存使用迅速恢复正常。这个案例提醒我们,在使用 Spring WebClient 这类响应式客户端时,需要特别注意其生命周期与底层连接池的关系,避免因配置的动态变更导致不可预料的内存问题。
本文所涉及的 JVM 内存泄漏排查思路和分析工具,对于深入理解 Java 应用的运行时行为非常有帮助。如果你想了解更多类似的系统级诊断与架构设计实践,欢迎关注 云栈社区 的 后端 & 架构 板块,那里有更多来自一线工程师的深度分享。
 发表于 2026-4-9 04:13:44
|
查看: 108|
回复: 0
发表于 2026-4-9 04:13:44
|
查看: 108|
回复: 0
