2026年3月,Netflix公开了一个引人注目的优化案例:其推荐服务Ranker中有一个计算视频新鲜度的功能,需要对海量候选视频与用户历史记录进行余弦相似度计算。这个功能原本占据了单节点7.5%的CPU资源,而在使用JDK Vector API重写其计算内核后,CPU消耗骤降至1%左右。最终,整体CPU利用率下降了约7%,平均延迟也降低了约12%。
这一显著性能提升背后的关键技术,正是JDK Vector API。它允许Java代码直接利用CPU的SIMD指令集,将原本需要逐个执行的标量浮点运算,转变为批量并行处理。
本文将带你从原理到实战,全面拆解Vector API。文章包含两个可直接运行的完整实战案例,助你掌握这一高性能计算利器。
SIMD 与 Vector API:从被动到主动
SIMD,全称Single Instruction Multiple Data,即单指令多数据。它是一种并行处理技术,允许一条CPU指令同时对多个数据元素执行相同的操作。
在传统的标量计算中,4个浮点数相加需要4条独立的加法指令。而在SIMD模式下,CPU可以仅用一条指令就同时完成这4个(甚至是8个、16个)浮点数的加法运算。

现代CPU普遍支持SIMD指令集(如x86的SSE、AVX,ARM的NEON)。过去,Java程序要想利用SIMD,完全依赖于JIT编译器的“自动向量化”能力。JIT会尝试将简单的循环结构编译成SIMD指令,但这个过程对开发者是黑盒,且非常脆弱——循环结构稍复杂,JIT就可能放弃向量化。开发者很难在编码时确认自己的循环是否真的被优化,通常只能事后分析汇编代码来验证。
Vector API的出现彻底改变了这一局面。它提供了一套直观的Java API,允许开发者在代码中明确地表达数据并行的意图。JIT编译器在遇到这些API调用时,会将其映射到当前CPU所支持的最优SIMD指令上。
最大的优势在于:一次编写,自动适配。 你无需编写JNI代码,也无需处理任何平台相关的指令,一套Java代码即可在不同CPU架构上获得SIMD加速。Netflix在尝试BLAS库方案时就遇到了JNI开销和内存布局不匹配的问题,最终Vector API凭借其纯Java、高性能的特性胜出。
理解 Vector API 的四个核心概念
要熟练使用Vector API,首先要理解其四个核心概念:Species(向量种类)、Vector(向量)、Lane(通道)和Mask(掩码)。搞清它们之间的关系,后续的代码阅读与编写就会顺畅许多。

Species(向量种类)
Species定义了一个向量的两个基本属性:元素类型和位宽。例如,FloatVector.SPECIES_256 表示一个256位宽的float类型向量,可以容纳8个float值(每个float占32位,256 ÷ 32 = 8)。而 DoubleVector.SPECIES_256 则表示一个256位宽的double向量,能装下4个double值。
在实际开发中,推荐使用 SPECIES_PREFERRED,它会自动选择当前CPU硬件支持的最大向量宽度。例如,在支持AVX2的机器上,它等价于 SPECIES_256;在支持AVX-512的机器上,则等价于 SPECIES_512。
Vector(向量)
向量是一个承载多个同类型数据的容器。一个 FloatVector 对象内部包含多个float值。对这个向量执行加法操作,其内部所有的float值会同时参与运算。需要注意的是,Vector API中的向量对象是不可变的(immutable),每次运算都会返回一个新的向量。
Lane(通道)
向量中的每个数据元素占据一个“通道”。一个 SPECIES_256 的FloatVector拥有8个通道(编号0到7)。向量运算是按通道对齐进行的:两个向量相加,结果是通道0与通道0相加,通道1与通道1相加,依此类推。
Mask(掩码)
掩码用于控制向量中哪些通道参与运算。一个典型应用场景是处理数组尾部数据:当数组长度不是向量通道数的整数倍时,最后一批数据不足以填满整个向量,此时就可以用掩码来标记哪些通道的数据是有效的、哪些应该被忽略。
基础用法:从数组相加开始
让我们通过一个数组逐元素相加的简单例子,直观感受Vector API的代码形态。
首先,这是传统的标量版本:
static void addScalar(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i++) {
c[i] = a[i] + b[i];
}
}
接下来是使用Vector API的版本:
// 选择当前CPU支持的最优向量宽度
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
static void addVector(float[] a, float[] b, float[] c) {
int i = 0;
// loopBound计算出能被向量宽度整除的最大索引
int upperBound = SPECIES.loopBound(a.length);
// 每次循环处理一个向量宽度的数据
for (; i < upperBound; i += SPECIES.length()) {
FloatVector va = FloatVector.fromArray(SPECIES, a, i);
FloatVector vb = FloatVector.fromArray(SPECIES, b, i);
va.add(vb).intoArray(c, i);
}
// 处理尾部不足一个向量宽度的数据
for (; i < a.length; i++) {
c[i] = a[i] + b[i];
}
}
这段代码的结构可以分解为三步:
- 定义Species:使用
FloatVector.SPECIES_PREFERRED 让JVM自动选择最优宽度。如果CPU支持AVX2,SPECIES.length() 将返回8,意味着每次主循环能处理8个float。
- 主循环:
fromArray 从数组中加载一个向量宽度的数据,add 执行向量加法(8个float同时相加),intoArray 将结果写回数组。循环步长是 SPECIES.length(),每次跳过一个完整的向量宽度。
- 尾部处理:
loopBound 返回的是能被向量宽度整除的最大索引。例如,数组长度为35,向量宽度为8,则 loopBound 返回32。索引32到34的这3个元素,使用传统的标量循环处理。
你也可以选择使用掩码来处理尾部,从而省略额外的标量循环:
static void addVectorWithMask(float[] a, float[] b, float[] c) {
int i = 0;
for (; i < a.length; i += SPECIES.length()) {
// mask自动处理数组边界,超出范围的通道不参与运算
VectorMask<Float> mask = SPECIES.indexInRange(i, a.length);
FloatVector va = FloatVector.fromArray(SPECIES, a, i, mask);
FloatVector vb = FloatVector.fromArray(SPECIES, b, i, mask);
va.add(vb).intoArray(c, i, mask);
}
}
掩码版本的代码更简洁,但在主循环中会引入额外的掩码检查开销。在性能极其敏感的场景下,建议采用第一种“主循环无掩码 + 尾部标量处理”的方式。
实战一:向量相似度搜索(推荐系统核心)
在AI应用中,一个极其常见的需求是:给定一个查询向量,从一批候选向量中找出最相似的前K个(TopK)。无论是推荐系统、RAG检索还是以图搜图,底层核心都是这个计算。事实上,Lucene和Elasticsearch的向量搜索功能,内部也在使用Vector API来加速这类运算。
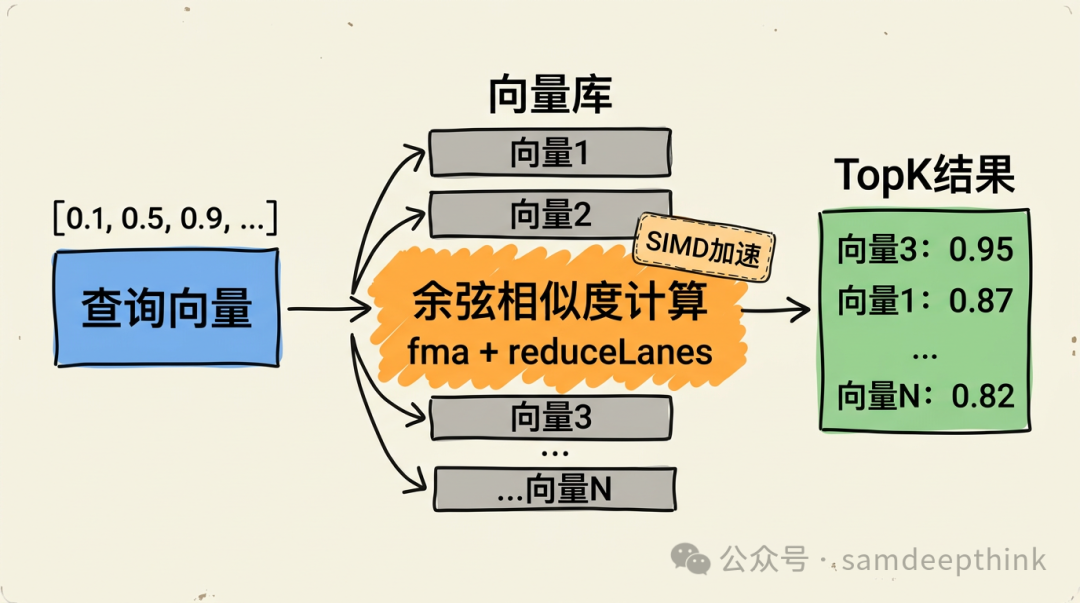
相似度计算通常采用余弦相似度。两个向量A和B的余弦相似度公式为:
cosine(A, B) = (A · B) / (|A| × |B|)
其中 A · B 是点积(内积),|A| 和 |B| 是各自的模长(欧几里得范数)。这个公式包含三个计算密集的部分:点积(逐元素相乘再求和)、两个模长(逐元素平方再求和再开方)。当向量维度高达128、256甚至768时,数据量一大,计算开销非常可观。
标量版本的余弦相似度
static float cosineSimilarityScalar(float[] a, float[] b) {
float dot = 0f;
float normA = 0f;
float normB = 0f;
for (int i = 0; i < a.length; i++) {
dot += a[i] * b[i];
normA += a[i] * a[i];
normB += b[i] * b[i];
}
return dot / (float) (Math.sqrt(normA) * Math.sqrt(normB));
}
每次循环需要进行3次乘法和3次加法。对于一个768维的向量,一次相似度计算就是2304次乘法和2304次加法。如果候选向量有10万个,总计算量将高达46亿次浮点运算。
Vector API版本的余弦相似度
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
static float cosineSimilarityVector(float[] a, float[] b) {
FloatVector sumDot = FloatVector.zero(SPECIES);
FloatVector sumNormA = FloatVector.zero(SPECIES);
FloatVector sumNormB = FloatVector.zero(SPECIES);
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
FloatVector va = FloatVector.fromArray(SPECIES, a, i);
FloatVector vb = FloatVector.fromArray(SPECIES, b, i);
// fma: fused multiply-add,一条指令完成乘加,即 va*vb + sumDot
sumDot = va.fma(vb, sumDot);
sumNormA = va.fma(va, sumNormA);
sumNormB = vb.fma(vb, sumNormB);
}
// 水平归约:把向量内所有通道的值加起来
float dot = sumDot.reduceLanes(VectorOperators.ADD);
float normA = sumNormA.reduceLanes(VectorOperators.ADD);
float normB = sumNormB.reduceLanes(VectorOperators.ADD);
// 处理尾部
for (; i < a.length; i++) {
dot += a[i] * b[i];
normA += a[i] * a[i];
normB += b[i] * b[i];
}
return dot / (float) (Math.sqrt(normA) * Math.sqrt(normB));
}
与标量版本相比,有两个关键优化:
- fma(融合乘加):
va.fma(vb, sumDot) 等价于 va * vb + sumDot,但它使用一条特殊的CPU指令同时完成乘法和加法。这不仅速度更快,而且减少了中间舍入次数,精度更高。Netflix在其优化中也大量使用了fma指令。
- reduceLanes(水平归约):主循环结束后,
sumDot 等向量中的每个通道都累积了部分和。reduceLanes(VectorOperators.ADD) 将这些部分和相加,得到最终结果。
在支持AVX2(向量宽度256位)的机器上,主循环每次迭代能处理8个float。对于768维的向量,标量版本需要循环768次,而Vector API版本仅需循环96次(768÷8),每次循环执行3条fma指令。总指令数从超过4600条大幅降至288条。
构建完整的向量搜索
有了高效的余弦相似度计算函数,构建一个向量搜索就简化为遍历所有候选向量、计算相似度、然后选取TopK:
static int[] searchTopK(float[][] vectors, float[] query, int k) {
float[] scores = new float[vectors.length];
for (int i = 0; i < vectors.length; i++) {
scores[i] = cosineSimilarityVector(vectors[i], query);
}
// 用一个小顶堆取TopK(此处用简单排序示意,生产环境建议用堆)
Integer[] indices = new Integer[vectors.length];
for (int i = 0; i < indices.length; i++) {
indices[i] = i;
}
Arrays.sort(indices, (a, b) -> Float.compare(scores[b], scores[a]));
int[] topK = new int[k];
for (int i = 0; i < k; i++) {
topK[i] = indices[i];
}
return topK;
}
这是一个暴力搜索(Brute-force),没有使用ANN索引(如HNSW、IVF)。实际的向量数据库会使用索引结构来减少需要计算相似度的候选向量数量,但在索引内部进行精确距离计算时,依然会依赖SIMD加速的点积或余弦相似度函数。Lucene的HNSW实现中,底层的距离计算就是用Vector API编写的。
性能提升技巧:预归一化
如果向量集合是固定的(例如一个已建好的向量库),我们可以在数据入库时,预先将每个向量归一化(缩放为单位向量,模长为1)。归一化后,余弦相似度计算简化为点积,直接省去了模长的计算:
// 预归一化:把向量缩放到模长为1
static void normalize(float[] v) {
float norm = 0f;
for (int i = 0; i < v.length; i++) {
norm += v[i] * v[i];
}
norm = (float) Math.sqrt(norm);
for (int i = 0; i < v.length; i++) {
v[i] /= norm;
}
}
// 归一化后,余弦相似度等于点积
static float dotProductVector(float[] a, float[] b) {
FloatVector sum = FloatVector.zero(SPECIES);
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
FloatVector va = FloatVector.fromArray(SPECIES, a, i);
FloatVector vb = FloatVector.fromArray(SPECIES, b, i);
sum = va.fma(vb, sum);
}
float result = sum.reduceLanes(VectorOperators.ADD);
for (; i < a.length; i++) {
result += a[i] * b[i];
}
return result;
}
Netflix在其优化中也采用了先归一化再进行矩阵乘法的策略。预归一化可以将每次相似度计算的fma调用次数从3次降至1次,内层循环的计算量直接减少为原来的三分之一。
实战二:批量特征评分(推荐/风控场景)
推荐系统和风控系统中常见另一类计算:使用一组固定的权重对大批用户的特征向量进行评分。每个用户有一个特征向量,用同一个权重向量做点积,得到一个分数。当需要对海量用户进行实时打分时,计算压力巨大。
标量版本:
static float[] batchScoreScalar(float[] weights, float[][] features) {
float[] scores = new float[features.length];
for (int i = 0; i < features.length; i++) {
float score = 0f;
for (int j = 0; j < weights.length; j++) {
score += weights[j] * features[i][j];
}
scores[i] = score;
}
return scores;
}
Vector API版本:
static float[] batchScoreVector(float[] weights, float[][] features) {
float[] scores = new float[features.length];
int upperBound = SPECIES.loopBound(weights.length);
for (int i = 0; i < features.length; i++) {
FloatVector sum = FloatVector.zero(SPECIES);
int j = 0;
for (; j < upperBound; j += SPECIES.length()) {
FloatVector vw = FloatVector.fromArray(SPECIES, weights, j);
FloatVector vf = FloatVector.fromArray(SPECIES, features[i], j);
sum = vw.fma(vf, sum);
}
float score = sum.reduceLanes(VectorOperators.ADD);
for (; j < weights.length; j++) {
score += weights[j] * features[i][j];
}
scores[i] = score;
}
return scores;
}
这里的内层循环模式与余弦相似度中的点积计算完全一致,都是 fromArray → fma → reduceLanes。Vector API的适用场景具有一个共同特征:对连续存储的float/double数组进行逐元素的算术运算,然后进行归约或写回。只要你的计算符合这个模式,就可以考虑引入Vector API进行加速。
Netflix的优化还提供了一个有价值的实践:他们将二维数组 float[][] “拍平”成一维的 float[],通过 i*D + k 这样的公式计算索引。连续的内存布局对CPU缓存更加友好,配合Vector API的 fromArray 从连续地址加载数据,可以显著减少缓存未命中。在对性能有极致要求的场景中,建议采用这种扁平化的数组布局。
性能对比实测
我们可以编写一段简单的测试代码,来直观对比标量版本与Vector API版本的性能差异:
public static void main(String[] args) {
int dim = 768;
int count = 100_000;
Random random = new Random(42);
// 准备数据
float[] query = randomVector(dim, random);
float[][] vectors = new float[count][];
for (int i = 0; i < count; i++) {
vectors[i] = randomVector(dim, random);
}
// 预热JIT
for (int i = 0; i < 1000; i++) {
cosineSimilarityScalar(vectors[i % count], query);
cosineSimilarityVector(vectors[i % count], query);
}
// 标量版本计时
long start = System.nanoTime();
for (int i = 0; i < count; i++) {
cosineSimilarityScalar(vectors[i], query);
}
long scalarTime = System.nanoTime() - start;
// Vector API版本计时
start = System.nanoTime();
for (int i = 0; i < count; i++) {
cosineSimilarityVector(vectors[i], query);
}
long vectorTime = System.nanoTime() - start;
System.out.printf("维度: %d, 向量数: %d%n", dim, count);
System.out.printf("标量版本: %d ms%n", scalarTime / 1_000_000);
System.out.printf("Vector API版本: %d ms%n", vectorTime / 1_000_000);
System.out.printf("加速比: %.2fx%n", (double) scalarTime / vectorTime);
}
在一台支持AVX2的机器上,对768维向量执行10万次余弦相似度计算,Vector API版本通常能获得2到4倍的加速比。在支持AVX-512的机器上,加速效果会更显著。具体数字取决于CPU型号、向量维度和JVM版本。
Netflix在生产环境报告的数据是:整体CPU利用率下降约7%,平均延迟下降约12%,CPU/RPS(每请求CPU消耗)改善了约10%。从函数级别看,热点计算的CPU占用从7.5%降到了1%左右。
注意:上述测试代码使用 System.nanoTime() 进行粗略计时,适合快速验证效果。要进行严格的性能基准测试,建议使用JMH(Java Microbenchmark Harness)框架,它能更好地处理JIT预热、GC干扰和统计误差等问题。
在项目中引入 Vector API:关键信息
以下是在实际项目中使用Vector API需要了解的关键点。
JDK版本要求
Vector API从JDK 16开始引入,并以孵化模块(jdk.incubator.vector)的形式提供。截至JDK 26(2026年3月发布),它仍然处于孵化状态,已经经历了11个孵化版本。尽管历经多轮,其API本身已基本保持稳定,没有重大的破坏性变更。
之所以孵化这么久,并非API不成熟,而是在等待“值类型”(Valhalla项目)相关特性的落地。值类型可以让Vector对象消除对象头的开销,实现真正的值语义,这对性能和内存布局至关重要。一旦Valhalla的相关特性成为预览版,Vector API预计将很快从孵化升级为预览,并最终成为正式API。
尽管尚在孵化,但像Netflix、Lucene/Elasticsearch这样的重量级项目早已将其用于生产环境。其API是稳定可靠的,可以放心使用,只是在升级JDK版本时需要留意是否有细微的API变动。
编译与运行参数
编译和运行时都需要显式添加模块声明:
# 编译
javac --add-modules jdk.incubator.vector YourClass.java
# 运行
java --add-modules jdk.incubator.vector YourClass
Maven配置
在 pom.xml 的Maven编译插件中添加相应参数:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<compilerArgs>
<arg>--add-modules</arg>
<arg>jdk.incubator.vector</arg>
</compilerArgs>
</configuration>
</plugin>
运行时同样需要在JVM启动参数中添加 --add-modules jdk.incubator.vector。
Fallback(降级)策略
由于Vector API仍在孵化,某些环境可能未启用或JDK版本过低。Netflix采用的做法是在应用启动时检测Vector API是否可用,并据此选择执行路径:
static final boolean VECTOR_API_AVAILABLE;
static {
boolean available = false;
try {
Class.forName("jdk.incubator.vector.FloatVector");
available = true;
} catch (ClassNotFoundException e) {
// Vector API不可用,使用标量回退
}
VECTOR_API_AVAILABLE = available;
}
static float dotProduct(float[] a, float[] b) {
if (VECTOR_API_AVAILABLE) {
return dotProductVector(a, b);
}
return dotProductScalar(a, b);
}
适用场景
Vector API适合加速的计算通常具有以下特征:
- 数据是连续存储的float或double数组。
- 计算主要是逐元素的算术运算(加、减、乘、除、fma)。
- 数据量足够大,能够覆盖SIMD并行带来的开销。
- 属于计算密集型任务,CPU时间主要消耗在数值运算上。
典型适用场景包括:向量相似度计算(推荐、搜索)、矩阵运算、信号处理、图像处理、科学计算、金融风控评分等。
不太适合的场景:数据量极小(如几十个元素)、计算中包含大量分支判断、数据存储不连续。
Species 选择指南
| Species |
位宽 |
float通道数 |
double通道数 |
适用场景 |
SPECIES_128 |
128位 |
4 |
2 |
所有x86和ARM处理器(基础支持) |
SPECIES_256 |
256位 |
8 |
4 |
支持AVX2的处理器 |
SPECIES_512 |
512位 |
16 |
8 |
支持AVX-512的处理器 |
SPECIES_PREFERRED |
自动 |
自动 |
自动 |
推荐使用,自动选择最优 |
生产环境建议统一使用 SPECIES_PREFERRED。如果硬编码指定 SPECIES_512,在不支持AVX-512的CPU上,JVM会回退到标量模式模拟执行,性能反而可能更差。
总结
Vector API在JDK孵化器中已历经11个版本,表面看似乎进展缓慢。但实际情况恰恰相反,它未能“毕业”并非因为不成熟,而是在等待Valhalla值类型特性的协同。其API本身早已稳定,并被Netflix、Lucene等顶级项目在生产环境中验证,带来了实实在在的性能收益。
对于Java开发者而言,Vector API的核心价值在于:当你需要极致的数值计算性能时,无需离开Java生态。 过去,这类需求要么忍受纯Java的性能瓶颈,要么引入JNI调用C/C++库,带来额外的复杂性和维护成本。Vector API提供了一条纯Java的高性能路径,代码可读性好、跨平台、且性能接近手写SIMD汇编。
Vector API的价值不在于抽象的“快了多少倍”,而在于这些性能提升是你在熟悉的Java环境中就能直接获得的。
如果你的服务中存在大量的向量运算、矩阵乘法、特征评分等计算密集型热点函数,强烈建议在测试环境中用Vector API版本进行基准测试。从Netflix的经验来看,对于这类任务,SIMD加速的收益是明确且可观的。
性能优化永无止境,从算法设计到硬件指令的每一层都蕴藏着潜力。希望这篇深入浅出的实战指南,能帮助你在探索Java高性能计算的道路上更进一步。欢迎在云栈社区交流讨论更多技术实践。
 发表于 2026-4-9 05:05:08
|
查看: 137|
回复: 0
发表于 2026-4-9 05:05:08
|
查看: 137|
回复: 0
