大家最近注意到了吗?阿里云发布了一款采用国产芯片、带宽高达102.4T的NPO交换机。这款产品最早在去年的云栖大会上露面,最近阿里又公布了一些技术细节,引发了不少关注。

今天,我们就来深入剖析一下这款交换机,看看阿里这套方案到底“道行”有多深。
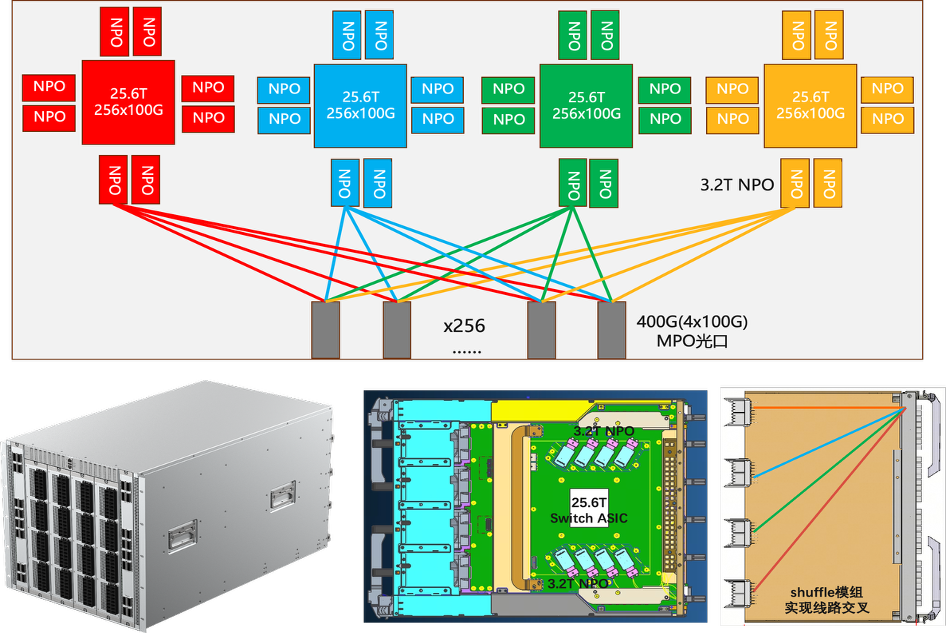
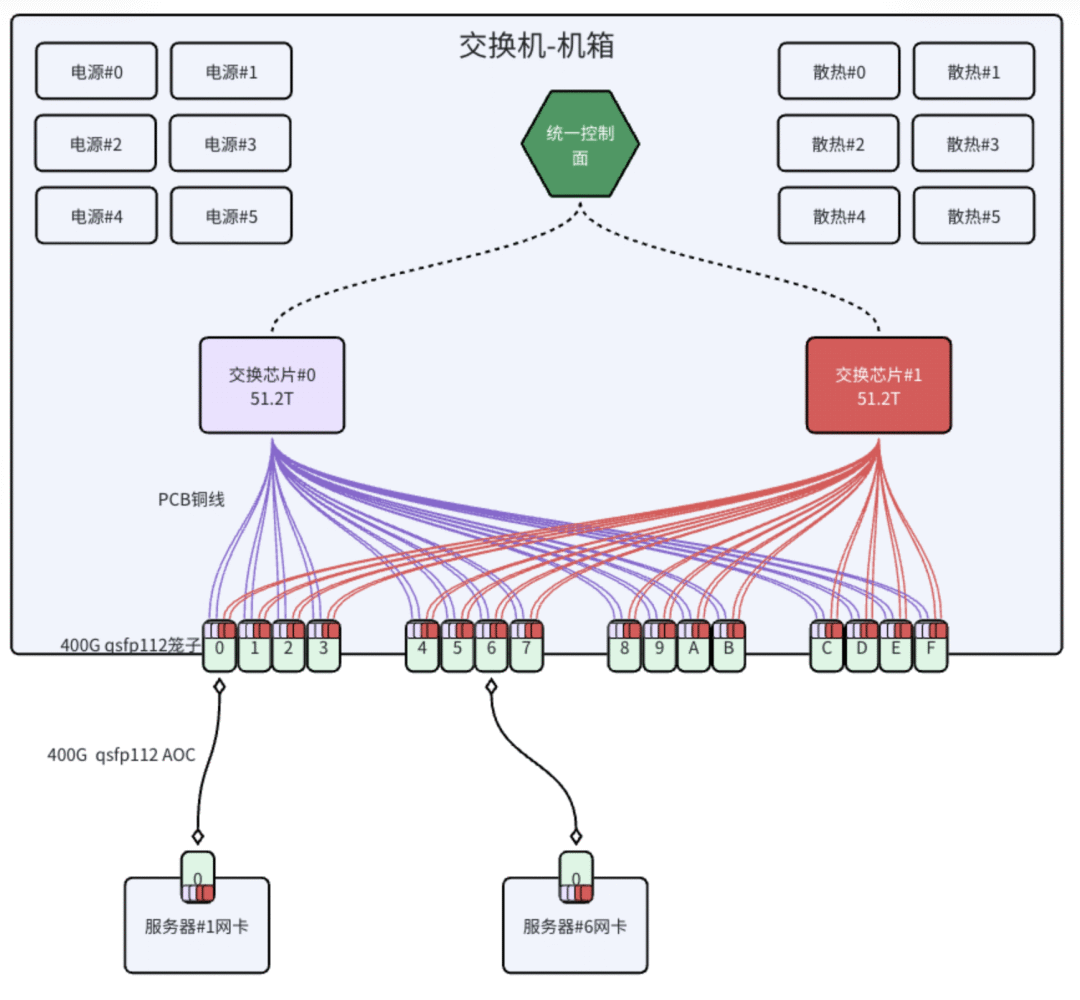
基于NPO的国产四芯片交换机硬件架构图

基于NPO的交换模组实物图
阿里这款102.4T NPO交换机的核心亮点可以总结为三点:
- 国产芯:由4颗25.6T的国产交换芯片组成,实现了102.4T的总交换带宽。
- NPO技术:即近封装光学技术(Near-Packaged Optics)。它将光模块从传统的“可插拔”形态,移到了距离交换芯片更近的位置。
- 内置shufflebox:这是一个光纤布线与映射管理部件,阿里将它直接内置在交换机内部,简化了外部布线。
为什么需要4颗国产芯片?
目前,国产交换芯片单芯片最大能力还停留在51.2T(还是某厂商自用),商用芯片市场的天花板是25.6T。这与海外厂商组合(Cisco, Nvidia, Marvell, Broadcom)已有单芯片102.4T方案相比,仍有差距。
那怎么办呢?一颗不够,两颗也不够,只能拿4颗25.6T“组团”。但组团有学问,怎么连接这4颗芯片,形成高效的交换矩阵,这里面有好几种“阵法”。
1. CLOS扩展阵法
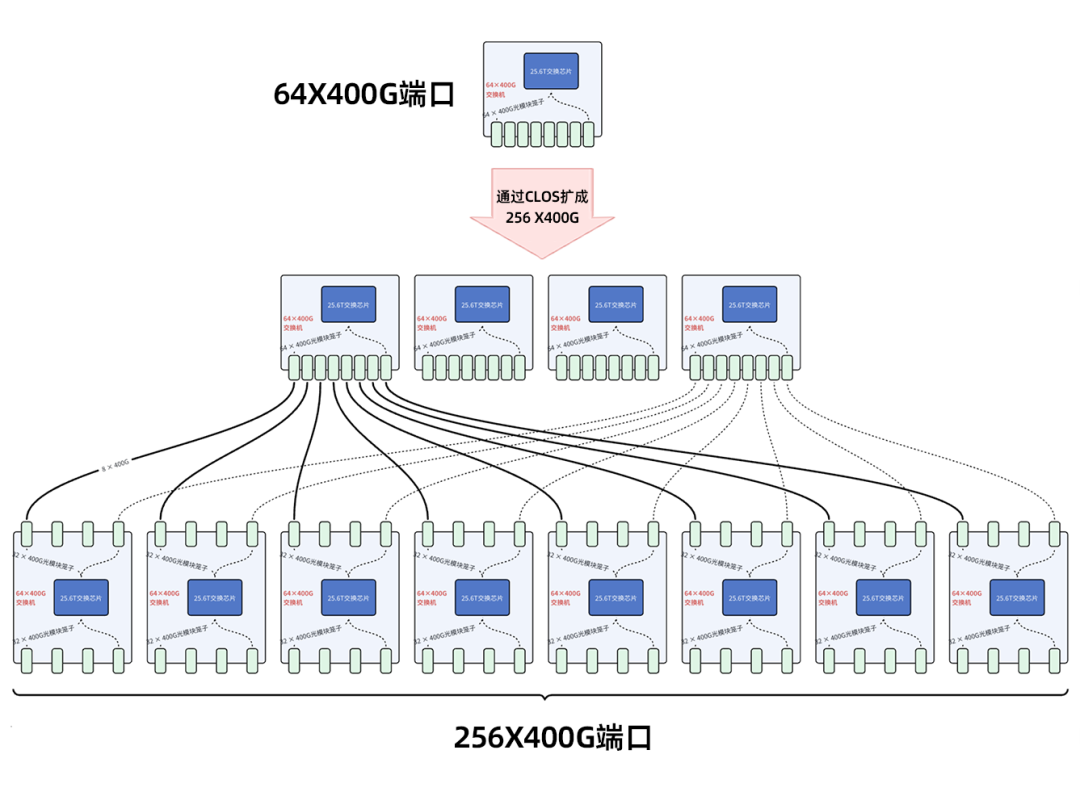
传统的CLOS方式无阻塞4倍扩容
传统的CLOS架构通过多层级、全互联的方式实现无阻塞交换。但从上图可以算出,用CLOS方式将端口扩展到4倍,所需芯片数量会膨胀到12倍,效率不高。如果用来做单体设备,成本会非常高,市场竞争力会很弱。
2. 平面扩展阵法
CLOS法的核心代价太高。而平面法是一种线性扩容方法。我们来看下面这个例子。
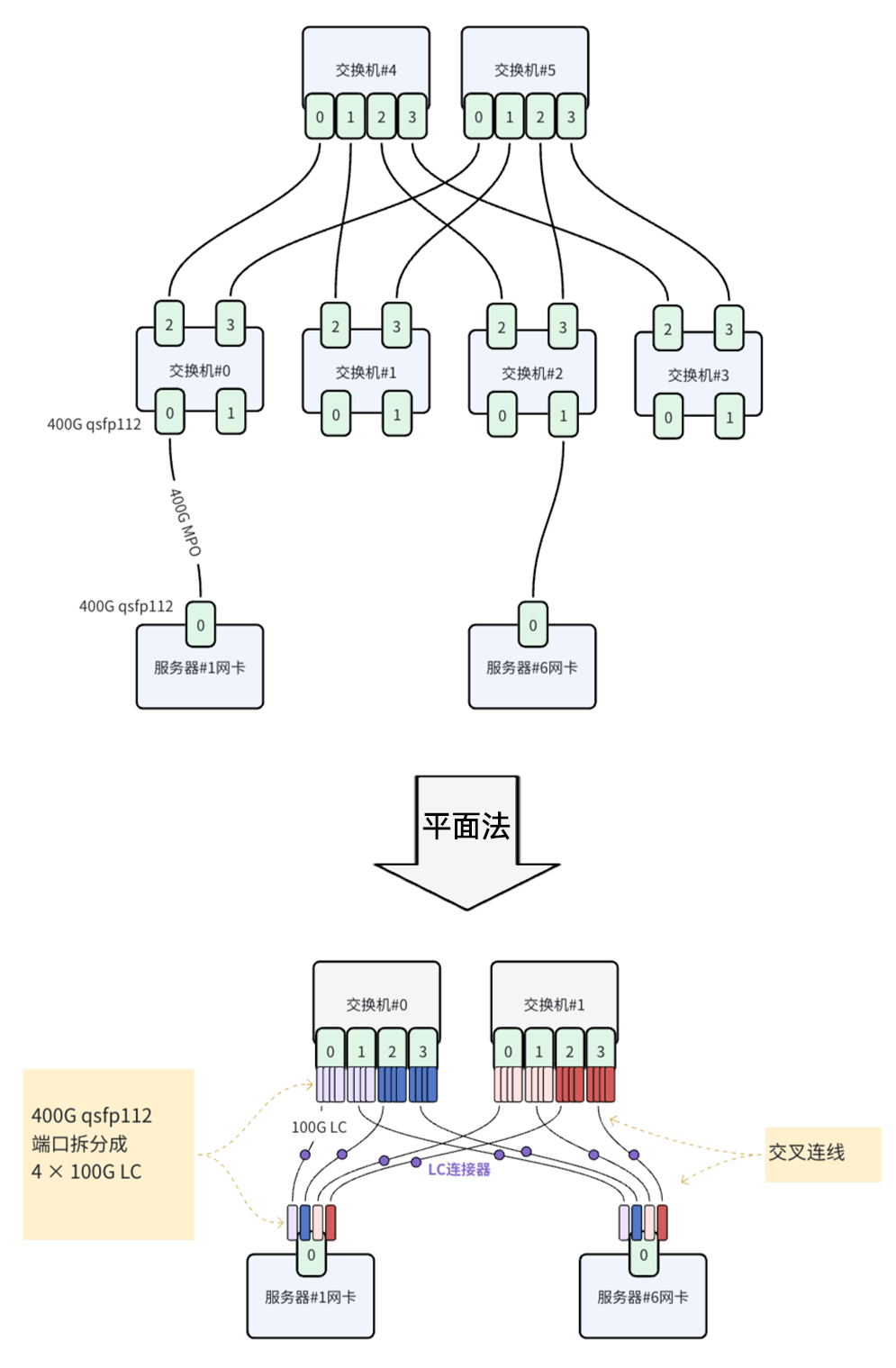
平行扩展法示意图
平面法只需2台交换机就实现了组网端口的翻倍,实现了线性扩容。但这种方法有个前提:互联端口必须可以拆分。本质上,它通过拆分端口让交换机具备更大的连接能力,从而拥有更多邻居。
然而,这带来了一个现实难题:光模块本身尺寸太小,无法在其上进行拆分操作。解决方案是在MPO线缆上做拆分。例如,一根400G的MPO线缆,可以拆分成4对1收1发的LC尾纤,每一对连接一个邻居。

400G MPO线缆拆分为4对LC尾纤示意图
拆分需要在两侧都进行,再通过LC连接器将两侧的尾纤对接起来。这种方式的弊端显而易见:布线工程量成倍增加(这里是4倍)。同时,由于互联中段存在开放的LC连接器,会增加信号插损,光纤端口受脏污的风险也增大了,给运维排障带来了更高的复杂度。
工程上可以引入无源光器件shufflebox来简化布线,但shufflebox作为一种固定交叉连接器,使用不灵活,依赖确定性的拆分方案。在快速变化的智算项目中,这点很难保证。而且,它同样无法避免开放连接器引入的问题。

描述光纤布线混乱的幽默插图
3. 阿里的NPO阵法
阿里的NPO方案,正是针对上述平面法中“拆分+开放连接”的弊端进行了优化。
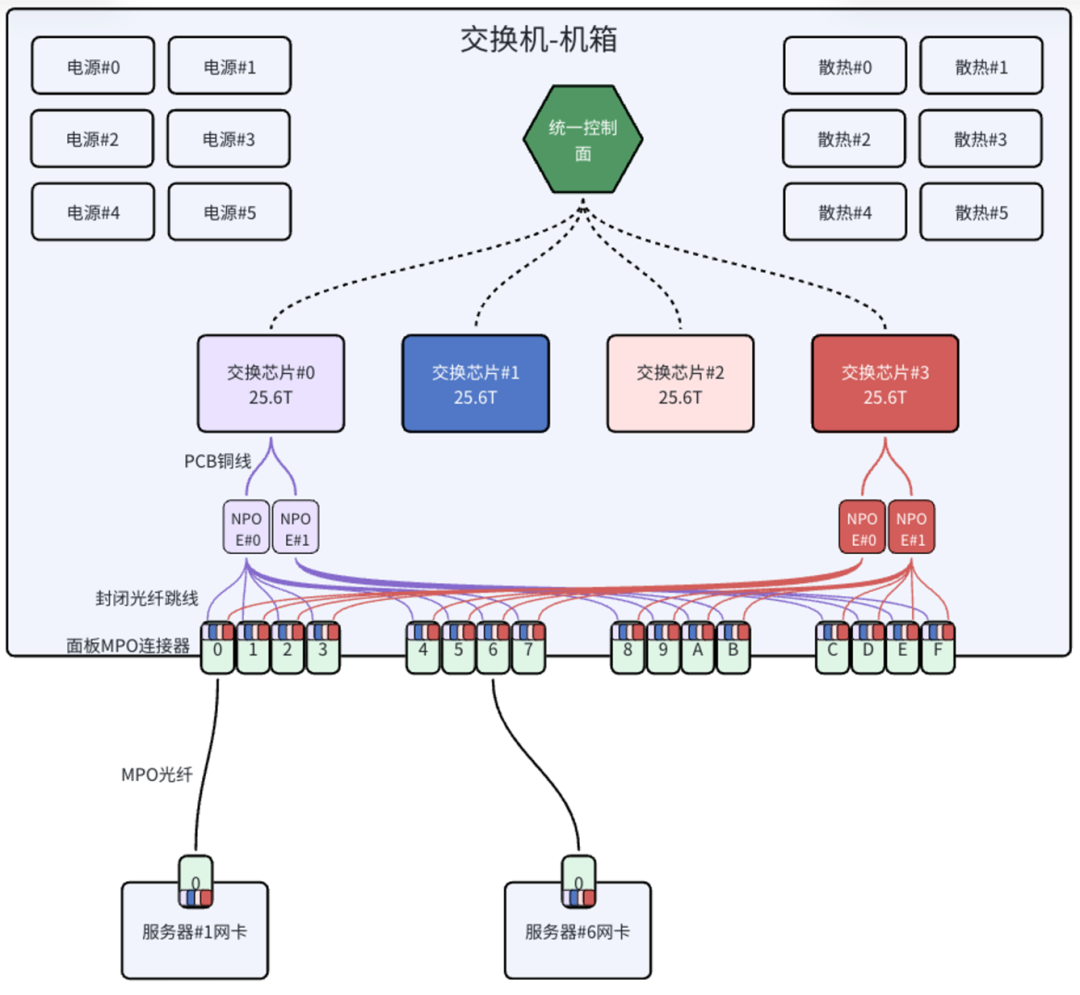
阿里的NPO方案架构图
这个方案在布线上的简化非常明显:
- 使用NPO模块代替了传统的可插拔光模块,并将其直接封装在交换机PCB板上。这样,电/光转换在交换机内部就完成了。
- NPO的光部分通过封闭的光纤跳线,按照固定规则交叉连接到交换机面板的MPO连接器。
- 所有内部连接都经过专用工艺封闭处理,彻底避免了开放连接带来的脏污问题,并将插损控制到最小。
- 服务器网卡与交换机的互联,又回到了我们熟悉的“一根MPO光纤”的简洁方式,无需在施工时进行复杂的拆分操作。
当然,阿里这个方案的核心价值在于战略意义:
- 战略意义1:能够用较小规格的国产交换芯片,以相对经济的代价,搭建出能与海外对标的大规格交换机。这次的4颗25.6T拼出102.4T就是一个例子。
- (当然,这技术并非独有,海外厂商也可以用,例如NVIDIA就用4颗102.4T的芯片搭出了409.6T的怪兽SN6800。)

NVIDIA SN6800交换机概念图
- 战略意义2:在从可插拔光模块到NPO/CPO(共封装光学)的技术演进道路上,做出了关键的工程验证。同时,NPO方案最大程度地保留了阿里在可插拔光模块领域培育多年的供应链生态,并使其得到进一步深化。
4. 华为的电Shuffle阵法
作为对比,我们看看“大厂”的方案。华为的XH9330-128EO使用了2颗51.2T的交换芯片组成了102.4T交换机。区别在于,它没有采用NPO,而是使用了PCB板上的电交叉式Shuffle。
华为的电Shuffle方案架构图
凭借强大的软硬件垂直整合能力,华为很可能做到了让两个芯片完全同步对齐工作(代价是实现复杂度极高)。这个方案的优点在于:
- 可以100%兼容现有的可插拔光模块生态;
- 完全兼容原有使用方式,无需任何端口拆分;
- 如果使用两端封闭的AOC线缆互联,可以避免任何开放的光纤端面,最大程度隔绝环境脏污。
代价是AOC线缆两头带着沉重的光模块,布线工程需要更仔细,成本会略有上升。但在国内,布线成本占比很低,这不会成为主要障碍。

华为XH9330-128EO交换机外观图
个人认为,该方案完全可以扩展为4×51.2T,直接做出204.8T的交换机,在国内做到“遥遥领先”。暂时没推出,可能是控制面尚不足以驾驭如此庞大的架构,也欢迎大家在云栈社区讨论这个问题。

写在最后:技术上限与运维下限
评估一个架构,不能只看正常运行时的性能上限,更要考虑运维场景中的故障处理下限。一个能大规模部署的产品,首先要保证下限足够高(稳定、易维护),其次才是追求上限。
很多技术宣传稿只讲美好的上限,就像汽车广告只讲百公里加速,却不谈日常维护成本一样。很多看似先进的技术,往往上限极高,但“下限”很低——或者说,很脆弱,不耐操。
作为一个经历过各种“脏活累活”的技术人,看问题就不能只按常规套路。我们来挑点小刺:这种高度集成化设计的交换机,一旦出现硬件故障,就很难沿用网络工程师“哪里坏了修哪里”的传统思路了。很可能需要像处理单芯片102.4T交换机一样,进行整机替换。
另外,端口经过拆分后数量变多,随之而来的IP地址分配管理、邻居状态监控、告警策略配置等运维能力都需要重新设计,绝不能套用老思路。
好了,今天的“吐槽”和解析就到这里。技术的进步总是在解决老问题的同时,带来新的挑战,而这正是其迷人之处。
 发表于 2026-3-10 12:21:06
|
查看: 608|
回复: 0
发表于 2026-3-10 12:21:06
|
查看: 608|
回复: 0
