有时,IT领域的创新源自超大规模数据中心和云计算。但早在这些公司崛起之前,真正的创新往往来自电信和服务提供商行业,随后才被引入到数据处理领域。
新兴网络芯片公司 Eridu 便延续了这一传统。该公司近期正式结束隐身模式,并成功完成了超过2亿美元的A轮融资。其核心目标是为AI训练集群打造一种极高基数(Radix)的交换系统,旨在“扁平化”网络结构,从而降低延迟并削减网络成本——这部分成本通常占AI集群硬件总购置成本的20%以上。
无论是超大规模数据中心、云服务商还是高性能计算中心,都不希望看到网络成本超过分布式计算系统总成本的10%。而当这个比例上升到30%时,他们更是难以接受。这里的网络成本,既包括将GPU、XPU内存互连以组成机架级乃至未来行级系统的纵向扩展(Scale-up)网络,也包括使用为高性能计算开发的MPI协议变体,将成千上万个此类系统连接成更松散耦合集群的横向扩展(Scale-out)网络。
如果全面核算AI硬件的网络成本,企业还必须考虑连接应用程序与AI集群的前端网络。与构成AI集群核心互连的横向扩展网络相比,这些前端网络的速度通常要慢得多。
目前,Eridu 对其具体技术方案仍然守口如瓶。当我们反复追问是否在研发一款具有海量高速端口、超低延迟和超高带宽的以太网交换机时,公司创始人只是点头微笑,未予置评。
长期以来,业界对用于互连GPU的PCI-Express交换机端口数量不足(即低基数)以及单通道带宽有限的问题多有诟病。这导致总带宽难以支撑机架级系统,更不用说规模更大的行级系统了。
尽管新的UALink互连规范在传输速率上足以媲美英伟达为其GPU开发的NVSwitch内存架构,但尚未有厂商保证能制造出突破该规范极限、足以在内存架构领域与英伟达竞争的UALink交换机ASIC。理论上,UALink交换机能在单层网络下支持多达1024个GPU或XPU在共享内存域中协同工作,远超当前NVSwitch 3支持的72个GPU。当然,英伟达理论上也可通过多层NVSwitch 3架构支持多达288个GPU,但这并未得到商业支持,且会增加GPU间内存访问的延迟跳数。
在深入了解Eridu的技术之前,有必要先认识其三位创始人。他们的背景深厚,在电信和服务提供商领域取得过巨大成功,这为新理念的市场化潜力提供了有力背书。
Eridu的联合创始人Drew Perkins是一位拥有45年从业经验的连续创业者。他于1986年从卡内基梅隆大学毕业,参与了包括IP协议开发在内的多个早期互联网项目。1987年,他创立了Entelechy并设计了自认为的首款多端口以太网交换机,但产品未能商业化。
1990年,Perkins联合创立了早期网络附加存储供应商InterStream。一场由酒驾引发的严重车祸让他住院两年多。康复后,他加入了为早期商业互联网提供ATM骨干网的Fore Systems公司,担任首席架构师。1998年,他联合创立Lightera Networks并担任CTO,该公司开发的CoreDirector光交换机后被Ciena以5.5亿美元收购。此后,他还在OnFiber Communications和Infinera担任要职。据称,Infinera开发了世界上首款硅光子集成电路,该公司于2007年上市,并于2024年6月被诺基亚以23亿美元收购。
2014年,Perkins在植入人工晶体治疗白内障后,利用休假时间创立了致力于开发“智能隐形眼镜”的Mojo Vision公司。2023年3月,他卸任Mojo Vision CEO,创立了Eridu。
另外两位联合创始人分别是首席产品官Omar Hassen和首席业务拓展及市场营销官Mike Capuano。Hassen此前曾担任RISC-V服务器芯片制造商Ventana Systems的业务拓展高级副总裁,更早之前在Arm服务器芯片初创公司AppliedMicro负责产品开发。Capuano则拥有在瞻博网络(Juniper Networks)、思科系统(Cisco Systems)、Infinera以及后来被Arista Networks收购的Pluribus Networks等公司丰富的市场营销和销售经验。
以上是创始团队的背景。现在,来看看他们融了多少钱。
Perkins向媒体透露,公司迄今已筹集超过2亿美元。业内传言其种子轮约为3000万美元,A轮则超过2亿美元。这笔巨额资金对于挑战英伟达的NVSwitch和Spectrum-X网络技术,并与博通、思科系统、Marvell等为AI系统构建网络ASIC的巨头竞争而言,是必不可少的。
Eridu的A轮融资由Socratic Partners、知名投资人John Doerr、Hudson River Trading、Capricorn Investment Group和Matter Venture Partners领投。SBVA、Bosch Ventures、TDK Ventures、Eclipse Capital和VentureTech Alliance也参与了投资。
预计到2030年,人工智能硬件支出将达到数万亿美元。这意味着网络领域将蕴含着数千亿美元的巨大市场机遇。如此规模的市场足以驱动创新、促进竞争,并可能重塑英伟达目前在AI计算和网络领域的领先地位。
至于如何实现这种高基数交换,Perkins和Hassen依然不愿透露太多细节。但他们提供了一张展示其技术愿景的架构图:
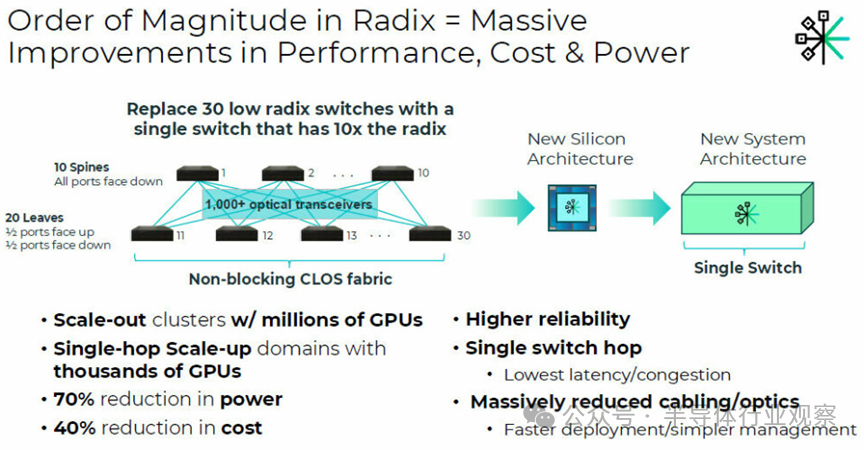
图中对比了现有低基数交换机组成的Clos网络与Eridu高基数单交换机方案。假设对比使用的是当前主流的51.2 Tb/s以太网交换机ASIC(而非即将面世的102.4 Tb/s设备),Eridu的方案展示了巨大优势:可扩展至支持百万GPU的集群,构建包含数千GPU的单跳扩展域,同时降低70%的功耗和40%的成本,并拥有更高可靠性、更低延迟以及更简化的布线与管理。
“GPU插槽的性能和功耗正以惊人的速度提升,但网络性能却没有跟上,” Perkins解释道。他补充说,这种提升涵盖了降低计算精度、优化软件栈和硬件等多个层面。“网络性能每两到三年才翻一番,这远远不够。Eridu的创立正是为了解决这个问题。”
“我们希望将网络性能提升一个数量级,因为这些GPU必须被高效互连,” Perkins继续说道。“单个GPU能力有限,但当数量达到数十万甚至百万级时,你才拥有构建强大AI所需的海量算力。但网络速度必须足够快才能跟上计算节奏,否则GPU将有大量时间处于闲置状态,等待数据送达。”
我们尚不完全清楚Eridu的具体实现方案,但可以结合已有信息进行一些推测。
上图清晰地表明,Eridu旨在开发一种新的交换机ASIC架构和系统设计,以在纵向扩展网络中互连数千个GPU/XPU,并在横向扩展配置中支持数百万个计算引擎。
假设在一个典型的Clos叶脊网络架构中,交换机拥有64个端口,运行速度为800 Gb/s,那么该网络可以互连1280个GPU端口。实现单个设备支持1280个端口的一种传统方法是构建带有独立背板的模块化交换机,但这成本高昂。
另一种思路是制造一个超大型的交换机插槽。但这种方法存在“芯片周边I/O区域与核心处理区域”的矛盾:随着交换机数据包处理引擎面积的增大,能够部署SerDes(用于外部通信)的边缘区域与核心处理能力的比值会下降。此外,过大的芯片也会导致直通延迟增加。
对此,Hassen指出:“这只是次要问题。首要问题是,如果你通过拼接多个小芯片来构建大交换机,数据包就必须在芯片间穿越并被多次存储转发。因此,你必须从一张白纸开始,设计一个具有足够扩展性的交换架构。”
这让我们联想到晶圆级交换机ASIC的可能性,尽管Perkins和Hassen对此不置可否。使用芯粒(Chiplet)技术可以提高良率,但会增加芯粒间互连的功耗。要彻底解决带宽与处理能力的平衡问题,或许需要在晶圆级数据包处理引擎的边缘堆叠大量SerDes,或者使用大容量SRAM缓存来管理数据流。
该公司确认,其最终方案将基于以太网,并运行适用于内存架构和横向扩展网络的相应协议。从交流中判断,其技术路径可能不同于谷歌用于其TPU集群的光路交换机(Optical Circuit Switch)。
另一张提供的图表揭示了Eridu方案的性能目标:
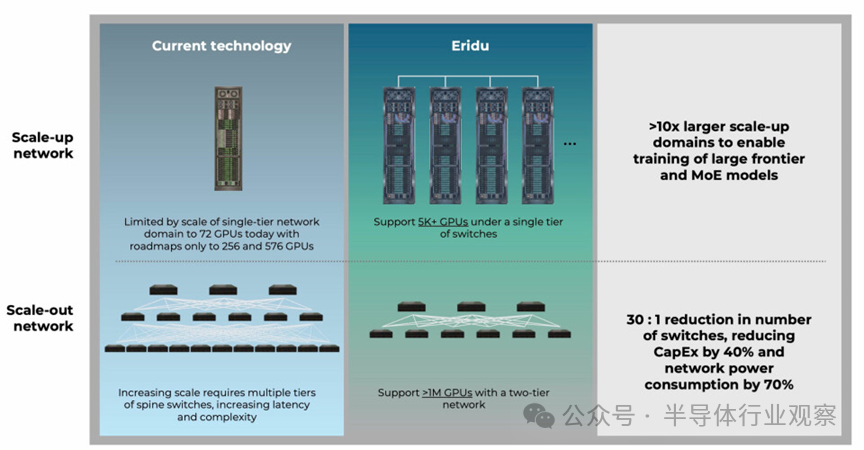
图表显示,Eridu的首个行级交换系统,其单层网络域可支持超过5000个GPU/XPU,而两层网络则可扩展至超过100万个计算引擎。作为对比,当前技术受限于单层网络,通常只能支持72个GPU(未来路线图规划至256或576个),要扩展规模就必须引入多层脊交换机,从而增加延迟和复杂性。
Eridu宣称可实现10倍以上的扩展域,以支持大型前沿模型和MoE模型的训练。同时,能将交换机数量减少30倍,从而降低40%的资本支出(CapEx)和70%的网络功耗。
这场针对AI时代网络瓶颈的挑战已经拉开序幕。Eridu能否兑现其颠覆性的承诺,我们或许需要等到今年的Hot Chips等行业大会才能窥见更多细节。对于关注高性能计算与网络架构演进和AI基础设施发展的工程师与决策者而言,这无疑是一个值得持续关注的方向。如果你想了解更多深度技术解析与行业动态,欢迎访问云栈社区进行交流与探讨。
 发表于 2026-3-14 09:03:43
|
查看: 226|
回复: 0
发表于 2026-3-14 09:03:43
|
查看: 226|
回复: 0
